------<a href="http://www.itheima.com" target="blank">Java培训、Android培训、iOS培训、.Net培训</a>、期待与您交流! -------
兴趣是学习编程最好的老师
不积跬步,无以至千里
这辈子没办法做太多事情,所以每一件都要做到精彩绝伦。
<集合>
1.集合:集合可以理解为一种容器, 长度可变, 可以存储任意类型的对象。
2.集合的分类:
集合框架的构成及分类:
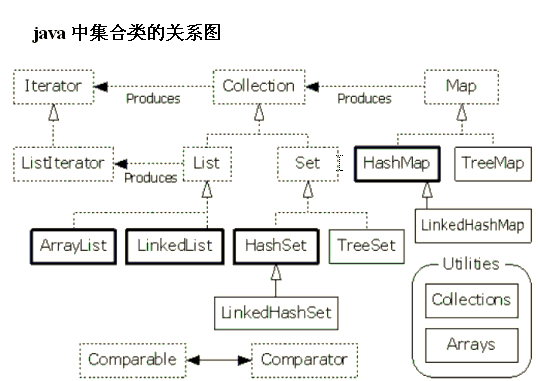
单列集合:Collection,双列集合:Map。
1).Collection有两个子接口分别是List、Set。
List: 可重复, 有存储顺序,有索引
ArrayList
LinkedList
Vector
Set: 不可重复, 没索引,存取无序
HashSet
TreeSet
LinkedHashSet HashSet的子类
2).Map双列集合
HashMap
TreeMap
Hashtable
LinkedHashMap
3.数组和集合的区别
1).数组既可以存储基本数据类型,也可以存储引用数据类型,存储基本数据类型存储值,存储引用数据类型存储的是地址值,集合只能存储引用数据类型。
2).数组的长度一旦初始化就不可以改变
集合的长度是可变的。
4.集合的常用方法
add(Object obj) 向集合中添加一个元素到最后的位置
get(int index) 获取集合中指定位置的元素
size() 获取集合的长度
add(int index, Object obj) 向集合中添加一个元素到指定位置
set(int index, Object obj) 把集合中指定位置的元素替换
remove(int index) 删除集合中指定位置的元素
remove(Object obj) 删除集合中包含的obj对象
<List>
1.List有三个子类:ArrayList,LinkedList,Vector。
1).ArrayList
底层数据结构是数组,查询和修改快,增删慢,线程不安全,效率高。
Vector
底层数据结构是数组,与ArrayList相比线程安全,效率低。
LinkedList
底层数据结构是链表,查询和修改慢,增删快,线程不安全,效率高。
LinkedList可以很方便的操作头和尾。
2.迭代集合
for循环: 从0循环到集合的size()-1, 每次获取其中一个
迭代器: 调用iterator()方法获取迭代器, 使用hasNext()判断是否包含下一个元素, 使用next()获取下一个元素
增强for循环: for (类型 变量名 : 容器) { 循环体 } 容器中有多少个元素就执行多少次循环体, 每次循环变量指向容器中不同的元素(1.5新特性)。
<span style="font-size:18px;">class Demo{ </span><span style="font-size:18px;">
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
for(int i=0;i<list.size();i++){</span><span style="font-size:18px;">
System.out.println(list.get(i));} </span><span style="font-size:18px;">
ListIterator lit = list.listIterator();
while(lit.hasNext()) {
System.out.println(lit.next());
}}</span><span style="font-size:18px;">
for(Object obj : list){</span><span style="font-size:18px;">
System.out.println(obj);}
}}</span>3.删除
public class Demo7_Delete {
/**
* @param args
*/
public static void main(String[] args) {
//demo1();
ArrayList list = new ArrayList();
list.add("a");
list.add("a");
list.add("b");
list.add("b");
list.add("c");
list.add("d");
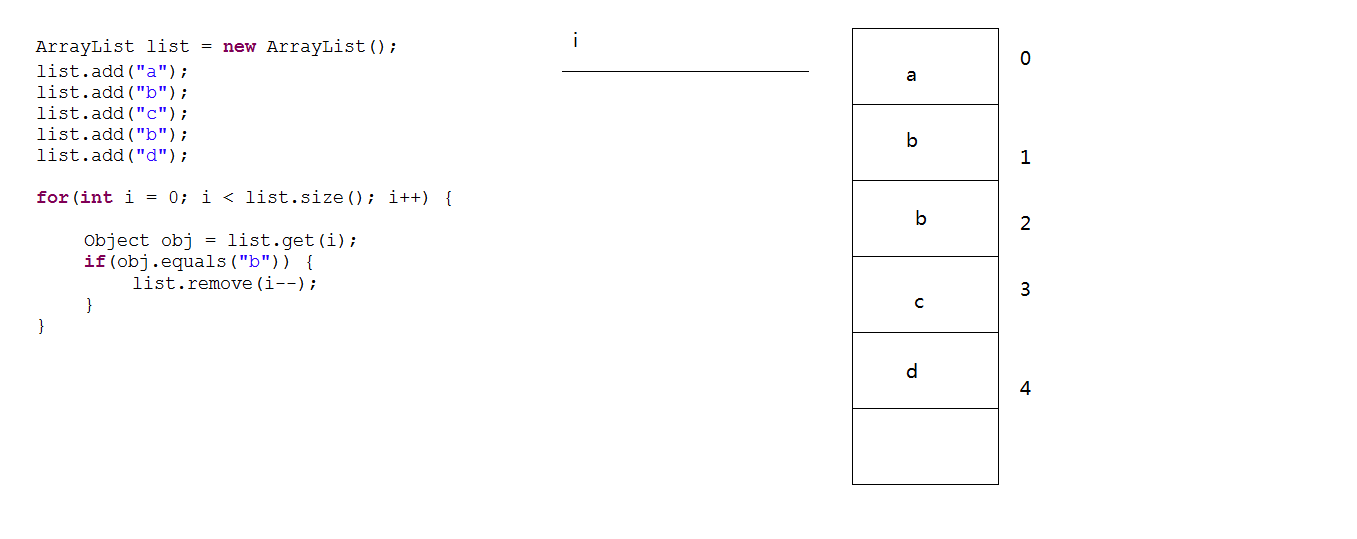
/*for(int i = 0; i < list.size(); i++) { //普通for循环可以删除,删除的时候索引要--
Object obj = list.get(i);
if(obj.equals("a")) {
list.remove(i--);
}
}*/
Iterator it = list.iterator();
while(it.hasNext()) {
//迭代可以删除,但是必须用迭代器的删除方法
Object obj = it.next();
//如果用集合的删除方法,会出现并发修改异常ConcurrentModificationException
if(obj.equals("b")) {
//list.remove("b");
//错误
it.remove();
}
}
}普通for删除
<泛型>(1.5版本的新特性)
1.泛型能将运行时期的错误,转移到了编译时期,去除黄色警告提示,但是只能放该类型或该类型的子类型对象,其他的都不允许放
public static void main(String[] args) {
demo1();
ArrayList<Integer> list = new ArrayList<>();
//1.7新特性,菱形泛型
list.add(123);
System.out.println(list);
}
private static void demo1() {
ArrayList<Person> list = new ArrayList<Person>();
list.add("a");
list.add(123);
Iterator<Person> it = list.iterator();
while(it.hasNext()) {
Person p = it.next();
System.out.println(p.getName() + "..." + p.getAge());
}
}
}
<Set>
1.Set 不可重复, 没索引,无序
HashSet 使用哈希算法去重复, 效率高, 但元素无序
TreeSet TreeSet是用排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
LinkedHashSet HashSet的子类, 原理相同, 除了去重复之外还能保留存储顺序
2.HashSet(LinkedHashSet)
1).HashSet原理
我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数。当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象。如果没有哈希值相同的对象就直接存入集合。 如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存。
2).将自定义类的对象存入HashSet去重复
类中必须重写hashCode()和equals()方法。hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)。 equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储。
ublic class Person implements Comparable<Person> {
//往TreeSet集合添加自定义类,自定义类需实现Comparable接口
private String name;
private int age;
public Person(){
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
//重写hashCode的方法
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
//重写equals的方法
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int compareTo(Person o){
//重写compareTo方法
int num=this.age-o.age;
return num==0?this.name.compareTo(o.name):num;
}
3).迭代
调用iterator()方法得到Iterator, 使用hasNext()和next()方法
增强for循环, 只要可以使用Iterator的类都可以用
class Demo{
public static void main(System[] args){
HashSet<Person> hs = new HashSet<>()
hs.add(new Person("张三"),23);
hs.add(new Person("李四"),24);
hs.add(new Person("王五"),25);
hs.add(new Person("赵六"),26);
Iterator<Person> it = hs.iterator();
while(it.hasNext()){
System.out.println(it.next());}
}
}
for(Person p : hs){
//增强for循环
System.out.println(p);
}
4.TreeSet
1).TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列.
2).使用方式
自然顺序(Comparable)
TreeSet类的add()方法中会把存入的对象提升为Comparable类型,调用对象的compareTo()方法和集合中的对象比较,根据compareTo()方法返回的结果进行存储。
比较器顺序(Comparator)
创建TreeSet的时候可以制定 一个Comparator,如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
add()方法内部会自动调用Comparator接口中compare()方法排序
两种方式的区别
TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序,TreeSet如果传入Comparator, 就优先按照Comparator
class Demo{
TreeSet<Person> ts = new TreeSet<>(new Comparator(){
public int compare(Person p1 , Person p2){
int num = p1.name.compare(p2.namm);
return num==0?p1.age-p2.age:num}});
ts.add("张三",23);
ts.add("李四",24);
ts.add("王五",25);
ts.add("赵六",26);
System.out.println(ts);}
最后
以上就是壮观花卷最近收集整理的关于黑马程序员——集合——List、Set、泛型的全部内容,更多相关黑马程序员——集合——List、Set、泛型内容请搜索靠谱客的其他文章。








发表评论 取消回复