前 言
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。数据库有很多种类型,从最简单的存储有各种数据的表格到能够进行海量数据存储的大型数据库系统都在各个方面得到了广泛的应用。
数据库
1 定义
数据库,可以简单的解释为:高效的存储和处理数据的介质(主要分为磁盘和内存两种)。
2 分类
根据数据库存储介质的不同,可以将其分为两类,即:关系型数据库(SQL)和非关系型数据库(NoSQL,Not Only SQL)。
3 举例
关系型数据库:
-
大型:Oracle、DB2 等;
-
中型:SQL Server、MySQL 等;
-
小型:Access 等。
非关系型数据库:
-
Memcached、MongoDB 和 Redis 等。
4 区别
关系型数据库:
-
安全,其将数据保存到磁盘之中,基本不可能出现丢失数据的情况;
-
比较浪费空间,因为其用二维表的形式存储数据。
非关系型数据库:
-
存储数据的效率比较高;
-
不是特别安全,突然断电时会导致数据丢失。
关系型数据库
1 定义
关系型数据库,是一种建立在关系模型(数学模型)上的数据库。
至于关系模型,则是一种所谓建立在关系上的模型,其包含三个方面,分别为:
-
数据结构:数据存储的形式,二维表(行和列);
-
操作指令集合:所有的 SQL 语句;
-
完整性约束:表内数据约束(字段与字段)和表与表之间的约束(外键)。
2 设计
-
数据库:从需要存储的数据需求中分析,如果是一类数据(实体),则应该设计成二维表;
-
二维表:由表头(字段名,用来规定数据的名称)和数据(实际存储的内容)部分组成。
二维表示例:

在此处,如果表中对应的某个字段值为空,但是系统依然会为其分配存储空间,这也就是关系型数据库比较浪费空间的原因啦!
3 关键字说明
-
DB:Database,数据库;
-
DBMS:Database Management System,数据库管理系统;
-
DBS:Database System = DBMS + DB,数据库系统;
-
DBA:Database Administrator,数据库管理员。
-
行记录:rowrecord,本质都是指表中的一行(一条记录),行是从结构角度出发,记录则是从数据角度出发。
-
列字段:columnfield,本质都是指表中的一列(一个字段),列是从结构角度出发,字段则是从数据角度出发。
4 SQL
SQL:Structured Query Language,结构化查询语言(数据以查询为主,99% 都是在进行查询操作)。
SQL 主要分为三种:
-
DDL:Data Definition Language,数据定义语言,用来维护存储数据的结构(数据库、表),代表指令为create、drop和alter等。
-
DML:Data Manipulation Language,数据操作语言,用来对数据进行操作(表中的内容)代表指令为insert、delete和update等,不过在 DML 内部又单独进行了一个分类,即 DQL(Data Query Language),数据查询语言,代表指令为select.
-
DCL:Data Control Language,数据控制语言,主要是负责(用户)权限管理,代表指令为grant和revoke等。
SQL 是关系型数据库的操作指令,是一种约束,但不强制,类似于 W3C,因此这意味着:不同的数据库产品(如 Oracle 和 MySQL)内部可能会有一些细微的区别。
MySQL 数据库
MySQL 数据库是一种CS结构的软件,即分为:客户端和服务端。
若想访问服务器,则必须通过客户端;服务器应该一直运行,客户端则在需要使用的时候运行。
交互方式
-
客户端连接认证,即连接服务器,认证身份mysql.exe -hPup
-h,主机地址,本地为localhost,远程为IP地址
-P,端口号,用来找软件
-u,用户名
-p,密码
-
发送 SQL 指令;
-
服务器接受 SQL 指令,然后处理 SQL 指令并返回操作结果;
-
客户端接受结果并显示结果;
-
由于服务器并发限制,需要断开连接(三种指令,分别为:exit、quit和q),释放资源。
服务器对象
由于没办法完全了解服务器内部的结构,因此只能粗略的分析数据库服务器的内部结构。
一般来说,将 MySQL 数据库服务器的内部对象分为四层,分别为:数据管理系统(DBMS)–> 数据库(DB)–> 表(Table)–> 字段(Filed).
SQL 基本操作
基本操作:CURD,即增删改查。
根据操作对象的不同,咱们可以将 SQL 的基本操作分为三类,分别为:库操作、表(字段)操作和数据操作。
库操作
1 新增数据库
基本语法:create database + 数据库名称 + [库选项];
其中,库选项是用来约束数据库的,为可选项(有默认值),共有两种,分别为:
-
字符集设定:charset/ character set+ 具体字符集,用来表示数据存储的编码格式,常用的字符集包括GBK和UTF8等。
-
校对集设定:collate+ 具体校对集,表示数据比较的规则,其依赖字符集。
示例:create database TBL_ERROR_CODE charset utf8;
其中,数据库的名字不能用关键字(已经被占用的字符,例如 update 和 insert 等)或者保留字(将来可能会用的,例如 access 和 cast 等)。
如果非要使用数据库的关键字或者保留字作为数据库名称,那么必须用反引号将其括起来,例如:
create databaseaccesscharset utf8;
如果还想使用中文作为数据库的名称,那就得保证数据库能够识别中文(强烈建议不要用中文命名数据库的名称),例如:
-- 设置中文名称的方法,其中 gbk 为当前数据库的默认字符集set names gbk;create database 北京 charset gbk;123
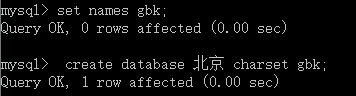
2 查询数据库
查看全部 –> 基本语法:show databases;
查看部分(模糊查询)–> 基本语法:show databases like 'pattern';
其中,pattern是匹配模式,有两种,分别为:
-
%:表示匹配多个字符;
-
_:表示匹配单个字符。
此外,在匹配含有下划线_的数据库名称的时候,需要在下划线前面加上反斜线_进行转义操作。
示例:show databases like 'TBL%';表示匹配所有TBL开头的数据库。
查看数据库的创建语句 –> 基本语法:show create database + 数据库名称;
在这里,查看的结果有可能与咱们书写的 SQL 语句不同,这是因为数据库在执行 SQL 语句之前会优化 SQL,系统保存的是优化后的结果。
3 更新数据库
在这里,需要注意:数据库的名字不可以修改。
数据库的修改仅限库选项,即字符集和校对集(校对集依赖字符集)。
基本语法:alter database + 数据库名称 + [库选项];
-
charset/character set[=] 字符集;
-
collate[=] 校对集;
示例:alter database TBL_ERROR_CODE charset gbk;表示修改此数据库的字符集为gbk.
4 删除数据库
基本语法:drop database + 数据库名称;
在这里,需要注意:在删除数据库之前,应该先进行备份操作,因为删除为不可逆操作,所以不要随意删除数据库。
表操作
1 新增表
基本语法:
create table [if not exists] + 表名( 字段名称 数据类型, …… 字段名称 数据类型 /* 最后后一行,不需要加逗号 */)[表选项];
其中,if not exists表示
如果表名不存在,就执行创建代码;如果表名存在,则不执行创建代码。
表选项则是用来控制表的表现形式的,共有三种,分别为:
-
字符集设定:charset/ character set+ 具体字符集,用来表示数据存储的编码格式,常用的字符集包括GBK和UTF8等。
-
校对集设定:collate+ 具体校对集,表示数据比较的规则,其依赖字符集。
-
存储引擎:engine+具体存储引擎,默认为InnoDB,常用的还有MyISAM.
由于任何表都归属于某个数据库,因此在创建表的时候,都必须先指定具体的数据库。在这里,指定数据库的方式有两种,分别为:
-
第 1 种:显式的指定表所属的数据库,示例
create table if not exists test.student( name varchar(10), age int, /* 整型不需要指定具体的长度 */ grade varchar(10) /* 最后后一行,不需要加逗号 */)charset utf8;
-
第 2 种:隐式的指定表所属的数据库,示例
use test; /* use + 数据库名称,表示切换到指定的数据库,这句命令其实不加分号也可以,但不建议这么做 */create table if not exists student( name varchar(10), age int, /* 整型不需要指定具体的长度 */ grade varchar(10) /* 最后后一行,不需要加逗号 */)charset utf8;
2 查询表
查看全部 –> 基本语法:show tables;
查看部分(模糊查询)–> 基本语法:show tables like 'pattern';
其中,pattern是匹配模式,有两种,分别为:
-
%:表示匹配多个字符;
-
_:表示匹配单个字符。
此外,在匹配含有下划线_的表名的时候,需要在下划线前面加上反斜线_进行转义操作。
示例:show tables like '%t';表示匹配所有以t结尾的表。
查看表的创建语句 –> 基本语法:show create table + 表名;
在这里,咱们也可以用g和G代替上述语句中的;分号,其中g等价于分号,G则在等价于分号的同时,将查的表结构旋转90度,变成纵向结构。
查看表中的字段信息 –> 基本语法:desc/describe/show columns from + 表名;
3 更新表
在这里,需要注意:表的修改,分为修改表本身和修改表中的字段。
第 1 类:修改表本身
-
修改表名,基本语法:rename table 旧表名 to 新表名;
-
修改表选项,基本语法:alter table + 表名 + 表选项[=] + 值;
第 2 类:修改表中的字段,新增、修改、重命名和删除
-
新增字段,基本语法:alter table + 表名 + add + [column] + 字段名 + 数据类型 + [列属性][位置];
其中,位置表示此字段存储的位置,分为first(第一个位置)和after + 字段名(指定的字段后,默认为最后一个位置).
示例:alter table student add column id int first;
-
修改字段,基本语法:alter table + 表名 + modify + 字段名 + 数据类型 + [列属性][位置];
其中,位置表示此字段存储的位置,分为first(第一个位置)和after + 字段名(指定的字段后,默认为最后一个位置).
示例:alter table student modify name char(10) after id;
-
重命名字段,基本语法:alter table + 表名 + change + 旧字段名 + 新字段名 + 数据类型 + [列属性][位置];
其中,位置表示此字段存储的位置,分为first(第一个位置)和after + 字段名(指定的字段后,默认为最后一个位置).
示例:alter table student change grade class varchar(10);
-
删除字段,基本语法:alter table + 表名 + drop+ 字段名;
示例:alter table student drop age;
注意:如果表中已经存在数据,那么删除该字段会清空该字段的所有数据,而且不可逆,慎用。
4 删除表
基本语法:
/** 可以一次删除多张表 */drop table + 表1, 表2 ... ;
在这里,需要注意:此删除为不可逆操作,希望大家谨慎使用。
数据操作
1 新增数据
对于数据的新增操作,有两种方法。
第 1 种:给全表字段插入数据,不需要指定字段列表,但要求数据的值出现的顺序必须与表中的字段出现的顺序一致,并且凡是非数值数据,都需要用引号(建议使用单引号)括起来。
基本语法:insert into + 表名 + values(值列表)[,(值列表)];
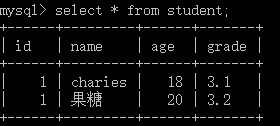
示例:insert into test valus('charies',18,'3.1');
第 2 种:给部分字段插入数据,需要选定字段列表,字段列表中字段出现的顺序与表中字段的顺序无关,但值列表中字段值的顺序必须与字段列表中的顺序保持一致。
基本语法:insert into + 表名(字段列表) + values(值列表)[,(值列表)];
示例:insert into test(age,name) valus(18,'guo');
2 查询数据
查看全部 –> 基本语法:select * from + 表名 + [where 条件];
示例:select * from test;
查看部分 –> 基本语法:select + 字段名称[,字段名称] + from + 表名 + [where 条件];
示例:select name,age,grade from test where age = '18';
3 更新数据
基本语法:update + 表名 + set + 字段 = 值 + [where 条件];
示例:update test set age = 20 where name = 'guo';
在这里,建议尽量加上where条件,否则的话,操作的就是全表数据。
此外,判断更新操作是否成功,并不是看 SQL 语句是否执行成功,而是看是否有记录受到影响,即affected的数量大于1时,才是真正的更新成功。
4 删除数据
基本语法:drop from + 表名 + [where 条件];
示例:drop from test where grade = '3.1';
在这里,需要注意:此删除为不可逆操作,希望大家谨慎使用。
中文数据问题
中文数据问题的本质就是字符集的问题。
由于计算机仅识别二进制数据,而且人类则更倾向于识别字符(符号),因此就需要一个二进制与字符的对应关系,也就是字符集。
在咱们通过 MySQL 数据库的客户端向服务器插入中文数据的时候,有可能失败,原因则可能是客户端和服务器的字符集设置不同导致的,例如:
-
客户端的字符集为gbk,则一个中文字符,对应两个字节;
-
服务器的字符集为utf8,则一个中文字符,对应三个字节。
这样显然会在编码转换的过程中出现问题,从而导致插入中文数据失败。
由于所有的数据库服务器表现的一些特性都是通过服务器端的变量来保持的,因此系统会先读取自己的变量,看看具体的表现形式。这样的话,咱们就可以通过以下语句查看服务器到底识别哪些字符集:
-- 查看服务器识别的全部字符集show character set;
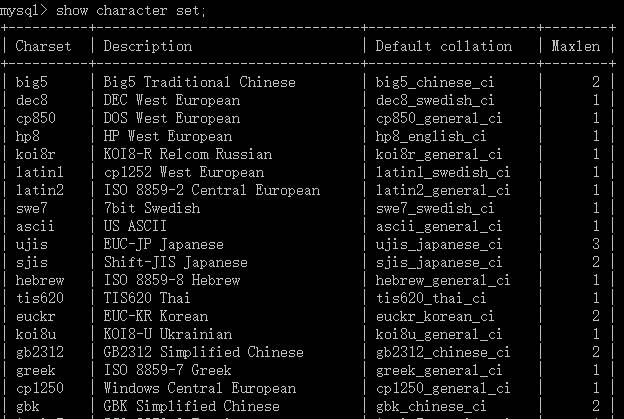
通过以上查询,咱们会发现:服务器是万能的,其支持所有字符集。
既然服务器支持这么多字符集,总会有一种是服务器默认的和客户端打交道的字符集。因此,咱们可以通过以下语句查看服务器默认的对外处理的字符集:
-- 查看服务器默认的对外处理的字符集show variables like 'character_set%';
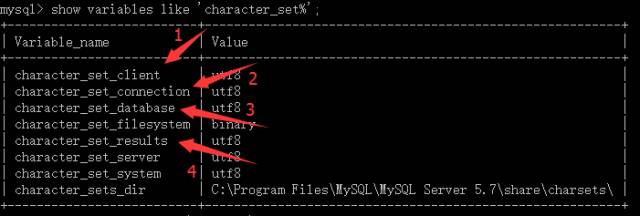
-
标注1:服务器默认的客户端传来的数据字符集为utf8;
-
标注2:连接层字符集为utf8;
-
标注3:当前数据库的字符集为utf8;
-
标注4:服务器默认的对外处理的字符集utf8.
通过以上查询,咱们会发现:服务器默认的对外处理的字符集是utf8.
那么反过来,咱们在通过客户端的属性查看客户端支持的字符集:
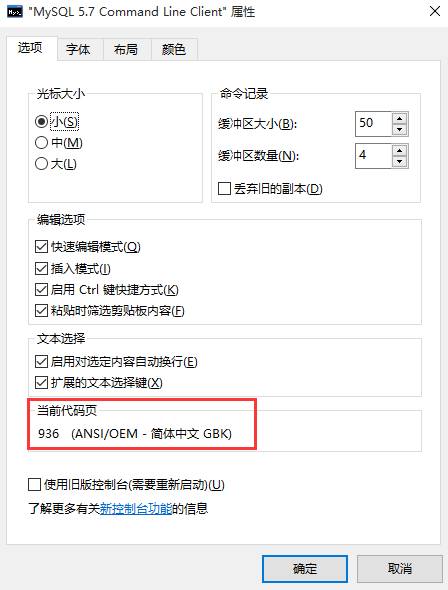
显然,咱们已经找到了问题的根源,确实是:客户端支持的字符集为gbk,而服务器默认的对外处理的字符集为utf8,因此产生矛盾。
既然问题已经找到了,那么解决方案就是:修改服务器默认接收的字符集为gbk.
-- 修改服务器默认接收的字符集为 GBK(不区分大小写)set character_set_client = gbk;
这样的话,咱们再插入中文数据的时候,就会插入成功啦!But,在咱们查看数据的时候,又发现了一个问题,就是之前咱们插入的中文数据显示乱码啦!不过这也正常,因为查询的时候,数据的来源是服务器(utf8),解析数据的是客户端,而客户端仅识别gbk格式的数据,显示乱码也就在意料之中啦!
因此,解决方案就是:修改服务器给客户端的数据字符集为gbk.
-- 修改服务器给客户端的数据字符集为 GBK(不区分大小写)set character_set_results = gbk;
如上图所示,向服务器插入中文数据的问题已经解决啦!
此外,咱们之前使用的 SQL 语句:
-- 修改的只是会话级别,即当前客户端当次连接有效,关闭后失效set 变量 = 值;
这样的话,每当咱们重启客户端的时候,都要依次重新进行设置,比较麻烦,因此咱们可以使用快捷的设置方式,即:
set names 字符集;
例如,
/*** 恒等于 set character_set_client = gbk;* 恒等于 set character_set_results = gbk;* 恒等于 set character_set_connection = gbk;*/set names gbk;
表示上述一条语句,将同时改变三个变量的值。其中,connection为连接层,是字符集转换的中间者,如果其和client和results的字符集一致,则效率更高,不一致也没有关系。
校对集问题
校对集,其实就是数据的比较方式。
校对集,共有三种,分别为:
-
_bin:binary,二进制比较,区分大小写;
-
_cs:case sensitive,大小写敏感,区分大小写;
-
_ci:case insensitive,大小写不敏感,不区分大小写。
查看(全部)校对集 –> 基本语法:show collation;
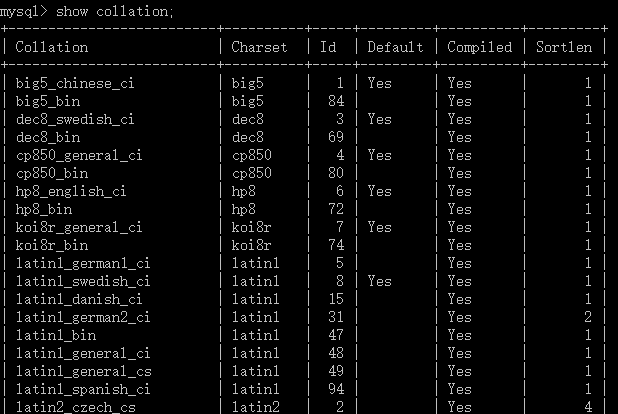
如上图所示,MySQL 数据库支持百多种校对集。
接下来,咱们在一起看看校对集的应用,因为只有当数据进行比较的时候,校对集才会生效。在这里,咱们用utf8的_bin和_ci两种校对集进行比较:
-- 创建两张使用不同校对集的表create table my_collate_bin( name char(10))charset utf8 collate utf8_bin;create table my_collate_ci( name char(10))charset utf8 collate utf8_general_ci;
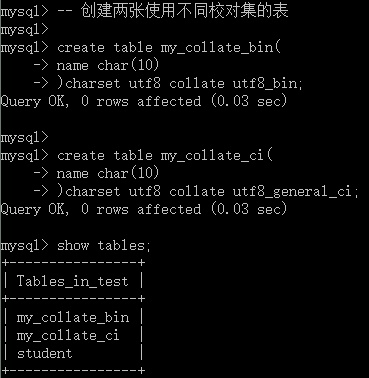
如上图所示,咱们创建了两张表,分别为my_collate_bin和my_collate_ci,其校对集分别为_bin和_ci. 然后,分别向这两张表中添加数据:
-- 向表中添加数据insert into my_collate_bin values ('a'),('A'),('B'),('b');insert into my_collate_ci values ('a'),('A'),('B'),('b');
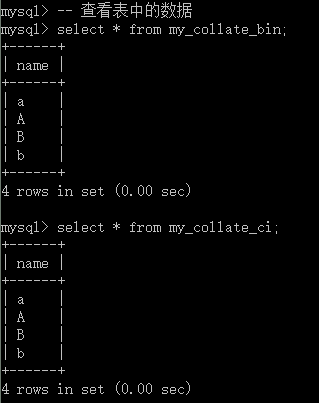
再分别查看两张表中的数据:
-- 查看表中的数据select * from my_collate_bin;select * from my_collate_ci;
下面,咱们根据表中的某个字段(在这里my_collate_bin和my_collate_ci都仅有一个字段)进行排序,其基本语法为:
order by + 字段名 + [asc/desc];
其中,asc表示升序,desc表示降序,默认为升序。执行如下 SQL 语句:
-- 排序比较select * from my_collate_bin order by name;select * from my_collate_ci order by name;
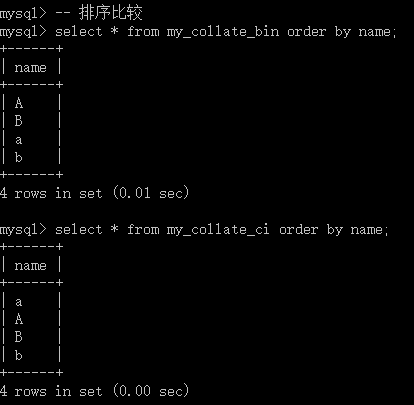
如上图所示,显然校对集生效啦!
此外,咱们需要特别注意的是: 校对集必须在没有数据之前声明好,如果有了数据之后,再进行校对集的修改,则修改无效。
最后为方便大家学习测试,特意给大家准备了一份13G的超实用干货学习资源,涉及的内容非常全面。
包括,软件学习路线图,50多天的上课视频、16个突击实战项目,80余个软件测试用软件,37份测试文档,70个软件测试相关问题,40篇测试经验级文章,上千份测试真题分享,还有2021软件测试面试宝典,还有软件测试求职的各类精选简历,希望对大家有所帮助……
关注我公众号:【程序员二黑】即可获取这份资料了!
最后
以上就是矮小睫毛膏最近收集整理的关于史上最简单的MySQL 教程,看完不会你来找我!的全部内容,更多相关史上最简单的MySQL内容请搜索靠谱客的其他文章。








发表评论 取消回复