1、Kubernetes网络模型和CNI插件
在Kubernetes中设计了一种网络模型,要求无论容器运行在集群中的哪个节点,所有容器都能通过一个扁平的网络平面进行通信,即在同一IP网络中。需要注意的是:在K8S集群中,IP地址分配是以Pod对象为单位,而非容器,同一Pod内的所有容器共享同一网络名称空间。
1.1Docker网络模型
了解Docker的友友们都应该清楚,Docker容器的原生网络模型主要有4种:Host(主机)、Container、Bridge(桥接)、none。
- host模式:容器和宿主机共享Network namespace。
- container模式:容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。
- none模式:容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。
- bridge模式:(默认为该模式)
#配置
[root@localhost ~]# docker run -it --network=模式名 镜像名
例:使用nginx镜像启动一个容器,网络模型为host
[root@localhost ~]# docker run -it --network=host nginxhost模式
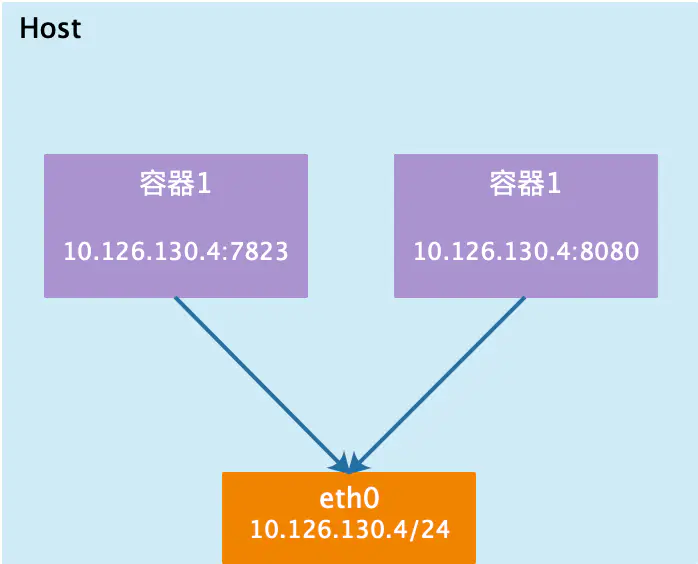
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好。
Host模式如下图所示:
container模式
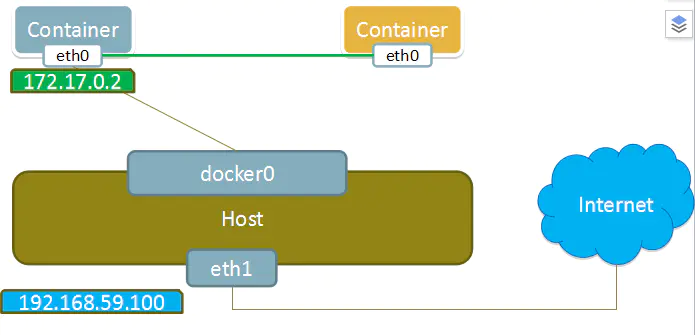
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
Container模式示意图:
none模式
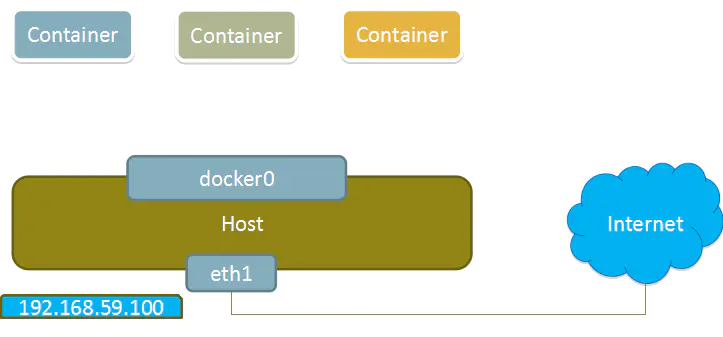
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
None模式示意图:
bridge模式
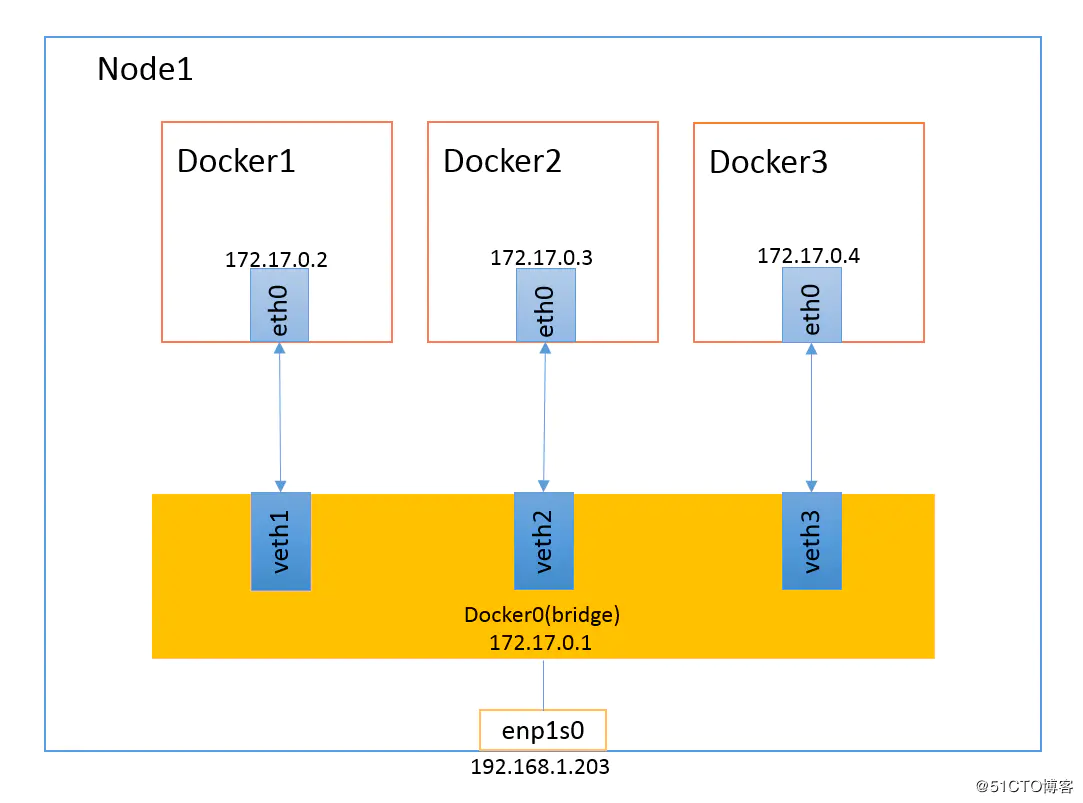
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。
bridge模式是docker的默认网络模式,不写--net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
bridge模式如下图所示:
2、Kubernetes网络模型
我们知道的是,在K8S上的网络通信包含以下几类:
- 容器间的通信:同一个Pod内的多个容器间的通信,它们之间通过lo网卡进行通信
- Pod之间的通信:通过Pod IP地址进行通信
- Pod和Service之间的通信:Pod IP地址和Service IP进行通信,两者并不属于同一网络,实现方式是通过IPVS或iptables规则转发
- Service和集群外部客户端的通信,实现方式:Ingress、NodePort、Loadbalance
k8s网络实现不是集群内部自己实现,而是依赖于第三方网络插件---(CNI:Container Network Interface)。
flannel、calico、canel等是目前比较流行的第三方网络插件。这三种的网络插件需要实现Pod网络方案的方式通常有以下几种:虚拟网桥、多路复用(MacVLAN)、硬件交换(SR-IOV)
无论是上面的哪种方式在容器当中实现,都需要大量的操作步骤,而K8S支持CNI插件进行编排网络,以实现Pod和集群网络管理功能的自动化。每次Pod被初始化或删除,kubelet都会调用默认的CNI插件去创建一个虚拟设备接口附加到相关的底层网络,为Pod去配置IP地址、路由信息并映射到Pod对象的网络名称空间。
CNI的主要核心是:在创建容器时,先创建好网络名称空间(netns),然后调用CNI插件为这个netns配置网络,最后在启动容器内的进程。
2.1、Flannel网络插件
Flannel是一种基于overlay网络的跨主机容器网络解决方案,也就是将TCP数据包封装在另一种网络包里面进行路由转发和通信。
工作原理
Flannel会为k8s集群中每个node端的host分配一个网段,Pod从这个网段中分配IP,这些IP可以在host间路由,Pod间无需使用nat和端口映射即可实现跨主机通信。如host1被分配的网段为172.17.1.0/16,host2被分配的网段为172.17.2.0/16。已分配 的subnet、host的IP等网络配置会被存放在ETCD中。
Flannel数据包在主机间转发是由backend实现的,目前已经支持UDP、VxLAN、host-gw等多种backend。
- VxLAN:使用内核中的VxLAN模块进行封装报文。也是flannel推荐的方式
- host-gw:即Host GateWay,通过在节点上创建目标容器地址的路由直接完成报文转发,要求各节点必须在同一个2层网络,对报文转发性能要求较高的场景使用
- UDP:使用普通的UDP报文封装完成隧道转发
2.1.1、VxLAN后端和direct routing
VxLAN(Virtual extensible Local Area Network)虚拟可扩展局域网,采用MAC in UDP封装方式,具体的实现方式为:
- 1、将虚拟网络的数据帧添加到VxLAN首部,封装在物理网络的UDP报文中
- 2、以传统网络的通信方式传送该UDP报文
- 3、到达目的主机后,去掉物理网络报文的头部信息以及VxLAN首部,并交付给目的终端
跨节点的Pod之间的通信就是以上的一个过程,整个过程中通信双方对物理网络是没有感知的。如下网络图:
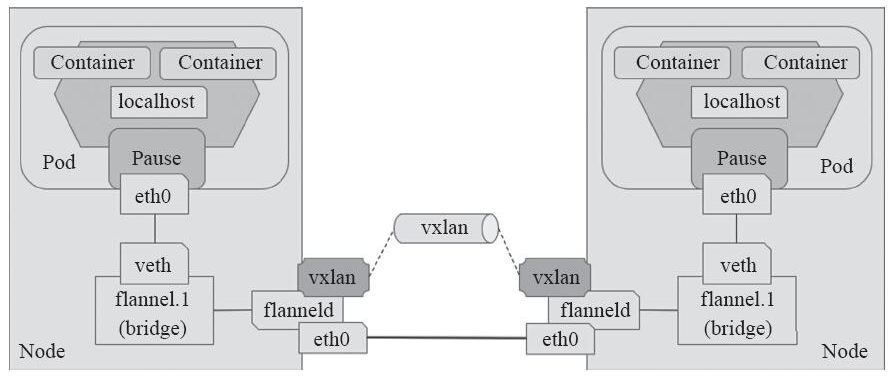
VxLAN模式配置:
在master端操作:
[root@master ~] # etcdctl set /atomic.io/network/config '{"Network": "172.17.0.0/16", "SubnetLen": 24, "SubnetMin": "172.17.1.0","SubnetMax": "172.17.20.0", "Backend": {"Type": "vxlan"}}'
#Network:用于指定Flannel地址池
#SubnetLen:用于指定分配给单个宿主机的docker0的ip段的子网掩码的长度
#SubnetMin:用于指定最小能够分配的ip段
#SudbnetMax:用于指定最大能够分配的ip段,在上面的示例中,表示每个宿主机可以分配一个24位掩码长度的子网,可以分配的子网从10.0.1.0/24到10.0.20.0/24,也就意味着在这个网段中,最多只能有20台宿主机
#Backend:用于指定数据包以什么方式转发,默认为udp模式,host-gw模式性能最好,但不能跨宿主机网络由于VXLAN由于额外的封包解包,导致其性能较差,所以Flannel就有了host-gw模式,即把宿主机当作网关,除了本地路由之外没有额外开销,性能和calico差不多,由于没有叠加来实现报文转发,这样会导致路由表庞大。因为一个节点对应一个网络,也就对应一条路由条目。
host-gw虽然VXLAN网络性能要强很多。,但是种方式有个缺陷:要求各物理节点必须在同一个二层网络中。物理节点必须在同一网段中。这样会使得一个网段中的主机量会非常多,万一发一个广播报文就会产生干扰。在私有云场景下,宿主机不在同一网段是很常见的状态,所以就不能使用host-gw了。
VXLAN还有另外一种功能,VXLAN也支持类似host-gw的玩法,如果两个节点在同一网段时使用host-gw通信,如果不在同一网段中,即 当前pod所在节点与目标pod所在节点中间有路由器,就使用VXLAN这种方式,使用叠加网络。 结合了Host-gw和VXLAN,这就是VXLAN的Direct routing模式
Direct routing模式配置
master端配置:
[root@master ~] # etcdctl set /atomic.io/network/config '{"Network": "172.17.0.0/16", "SubnetLen": 24, "SubnetMin": "172.17.1.0","SubnetMax": "172.17.20.0", "Backend": {"Type": "vxlan","Directrouting":true}}'
#增加"Directrouting":true2.1.2、Host-gw后端
Flannel除了上面2种数据传输的方式以外,还有一种是host-gw的方式,host-gw后端是通过添加必要的路由信息使用节点的二层网络直接发送Pod的通信报文。它的工作方式类似于Directrouting的功能,但是其并不具备VxLan的隧道转发能力。
工作模式流程图如下:
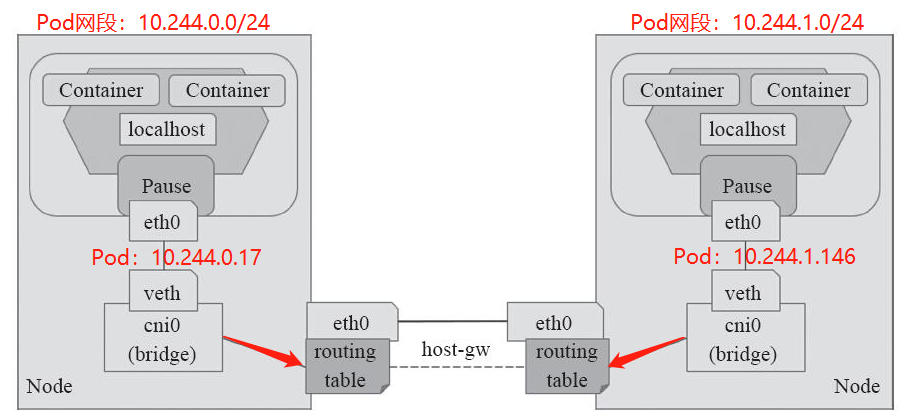
Host-gw模式配置
master端配置:
[root@master ~] # etcdctl set /atomic.io/network/config '{"Network": "172.17.0.0/16", "SubnetLen": 24, "SubnetMin": "172.17.1.0","SubnetMax": "172.17.20.0", "Backend": {"Type": "host-gw"}}'3、网络策略
网络策略(Network Policy )是 Kubernetes 的一种资源。Network Policy 通过 Label 选择 Pod,并指定其他 Pod 或外界如何与这些 Pod 通信。
Pod的网络流量包含流入(Ingress)和流出(Egress)两种方向。默认情况下,所有 Pod 是非隔离的,即任何来源的网络流量都能够访问 Pod,没有任何限制。当为 Pod 定义了 Network Policy,只有 Policy 允许的流量才能访问 Pod。
Kubernetes的网络策略功能也是由第三方的网络插件实现的,因此,只有支持网络策略功能的网络插件才能进行配置网络策略,比如Calico、Canal、kube-router等等。
PS:Kubernetes自1.8版本才支持Egress网络策略,在该版本之前仅支持Ingress网络策略。
3.1、部署Canal提供网络策略功能
Calico可以独立地为Kubernetes提供网络解决方案和网络策略,也可以和flannel相结合,由flannel提供网络解决方案,Calico仅用于提供网络策略,此时将Calico称为Canal。结合flannel工作时,Calico提供的默认配置清单式以flannel默认使用的10.244.0.0/16为Pod网络,因此在集群中kube-controller-manager启动时就需要通过--cluster-cidr选项进行设置使用该网络地址,并且---allocate-node-cidrs的值应设置为true。
#设置RBAC
[root@master ~]# kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/rbac.yaml
#部署Canal提供网络策略
[root@master ~]# kubectl apply -f https://docs.projectcalico.org/v3.2/getting-started/kubernetes/installation/hosted/canal/canal.yaml
[root@k8s-master ~]# kubectl get ds canal -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
canal 3 3 0 3 0 beta.kubernetes.io/os=linux 2m
部署canal需要的镜像,建议先拉取镜像,避免耗死资源:
quay.io/calico/node:v3.2.6
quay.io/calico/cni:v3.2.6
quay.io/coreos/flannel:v0.9.1
[root@master ~]# kubectl get pods -n kube-system -o wide |grep canal
canal-2hqwt 3/3 Running 0 1h 192.168.56.11 k8s-master
canal-c5pxr 3/3 Running 0 1h 192.168.56.13 k8s-node02
canal-kr662 3/3 Running 6 1h 192.168.56.12 k8s-node01
*****************************************************************************************************
Canal作为DaemonSet部署到每个节点,属于kube-system这个名称空间。
需要注意的是,Canal只是直接使用了Calico和flannel项目,代码本身没有修改,Canal只是一种部署的模式,用于安装和配置项目。
*****************************************************************************************************3.2、配置网络策略
在Kubernetes系统中,报文的流入和流出的核心组件是Pod资源,它们也是网络策略功能的主要应用对象。NetworkPolicy对象通过podSelector选择 一组Pod资源作为控制对象。NetworkPolicy是定义在一组Pod资源之上用于管理入站流量,或出站流量的一组规则,有可以是出入站规则一起生效,规则的生效模式通常由spec.policyTypes进行 定义。如下图:
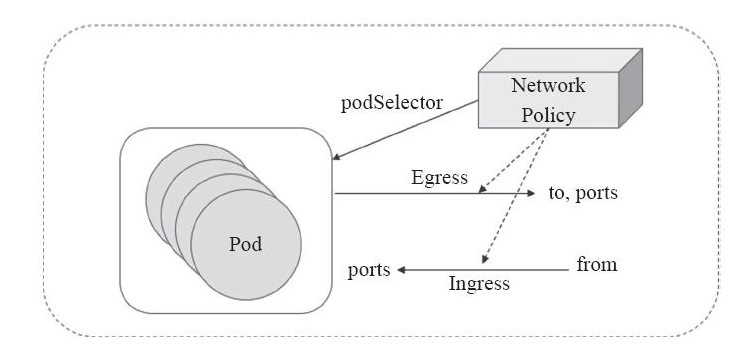
默认情况下,Pod对象的流量控制是为空的,报文可以自由出入。在附加网络策略之后,Pod对象会因为NetworkPolicy而被隔离,一旦名称空间中有任何NetworkPolicy对象匹配了某特定的Pod对象,则该Pod将拒绝NetworkPolicy规则中不允许的所有连接请求,但是那些未被匹配到的Pod对象依旧可以接受所有流量。
就特定的Pod集合来说,入站和出站流量默认是放行状态,除非有规则可以进行匹配。还有一点需要注意的是,在spec.policyTypes中指定了生效的规则类型,但是在networkpolicy.spec字段中嵌套定义了没有任何规则的Ingress或Egress时,则表示拒绝入站或出站的一切流量。定义网络策略的基本格式如下:
apiVersion: networking.k8s.io/v1 #定义API版本
kind: NetworkPolicy #定义资源类型
metadata:
name: allow-myapp-ingress #定义NetwokPolicy的名字
namespace: default
spec: #NetworkPolicy规则定义
podSelector: #匹配拥有标签app:myapp的Pod资源
matchLabels:
app: myapp
policyTypes ["Ingress"] #NetworkPolicy类型,可以是Ingress,Egress,或者两者共存
ingress: #定义入站规则
- from:
- ipBlock: #定义可以访问的网段
cidr: 10.244.0.0/16
except: #排除的网段
- 10.244.3.0/24
- podSelector: #选定当前default名称空间,标签为app:myapp可以入站
matchLabels:
app: myapp
ports: #开放的协议和端口定义
- protocol: TCP
port: 80
*****************************************************************************************************
该网络策略就是将default名称空间中拥有标签"app=myapp"的Pod资源开放80/TCP端口给10.244.0.0/16网段,
并排除10.244.3.0/24网段的访问,并且也开放给标签为app=myapp的所有Pod资源进行访问。
******************************************************************************************************为了看出Network Policy的效果,先部署一个httpd的应用。配置清单文件如下:
[root@master ~]# mkdir network-policy-demo
[root@master ~]# cd network-policy-demo/
[root@master network-policy-demo]# vim httpd.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: httpd
spec:
replicas: 3
template:
metadata:
labels:
run: httpd
spec:
containers:
- name: httpd
image: httpd:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: httpd-svc
spec:
type: NodePort
selector:
run: httpd
ports:
- protocol: TCP
nodePort: 30000
port: 8080
targetPort: 80创建三个副本,通过NodePort类型的Service对外方服务,部署应用:
[root@master network-policy-demo]# kubectl apply -f httpd.yaml
deployment.apps/httpd unchanged
service/httpd-svc created
[root@master network-policy-demo]# kubectl get pods -o wide |grep httpd
httpd-75f655479d-882hz 1/1 Running 0 4m 10.244.0.2 k8s-master
httpd-75f655479d-h7lrr 1/1 Running 0 4m 10.244.2.2 k8s-node02
httpd-75f655479d-kzr5g 1/1 Running 0 4m 10.244.1.2 k8s-node01
[root@master network-policy-demo]# kubectl get svc httpd-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpd-svc NodePort 10.99.222.179 <none> 8080:30000/TCP 4m当前没有定义任何Network Policy,验证应用的访问:
#启动一个busybox Pod,可以访问Service,也可以ping副本的Pod
[root@master ~]# kubectl run busybox --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # ping -c 2 10.244.1.2
PING 10.244.1.2 (10.244.1.2): 56 data bytes
64 bytes from 10.244.1.2: seq=0 ttl=63 time=0.507 ms
64 bytes from 10.244.1.2: seq=1 ttl=63 time=0.228 ms
--- 10.244.1.2 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.228/0.367/0.507 ms
#集群节点也可以访问Sevice和ping通副本Pod
[root@node01 ~]# curl 10.99.222.179:8080
<html><body><h1>It works!</h1></body></html>
[root@k8s-node01 ~]# ping -c 2 10.244.2.2
PING 10.244.2.2 (10.244.2.2) 56(84) bytes of data.
64 bytes from 10.244.2.2: icmp_seq=1 ttl=63 time=0.931 ms
64 bytes from 10.244.2.2: icmp_seq=2 ttl=63 time=0.812 ms
--- 10.244.2.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.812/0.871/0.931/0.066 ms
#集群外部访问192.168.56.11:30000也是通的
[root@localhost ~]# curl 192.168.56.11:30000
<html><body><h1>It works!</h1></body></html>那么下面再去设置不同的Network Policy来管控Pod的访问。
3.3、管控入站流量
NetworkPolicy资源属于名称空间级别,它的作用范围为其所属的名称空间。
3.3.1、设置默认的Ingress策略
用户可以创建一个NetworkPolicy来为名称空间设置一个默认的隔离策略,该策略选择所有的Pod对象,然后允许或拒绝任何到达这些Pod的入站流量,如下:
[root@master network-policy-demo]# vim policy-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {}
policyTypes: ["Ingress"]
#指明了Ingress生效规则,但不定义任何Ingress字段,因此不能匹配任何源端点,从而拒绝所有的入站流量
[root@master network-policy-demo]# kubectl apply -f policy-demo.yaml
networkpolicy.networking.k8s.io/deny-all-ingress created
[root@k8s-master network-policy-demo]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
deny-all-ingress <none> 11s
#此时再去访问测试,是无法ping通,无法访问的
[root@master ~]# kubectl run busybox --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
wget: can't connect to remote host (10.99.222.179): Connection timed out如果要将默认策略设置为允许所有入站流量,只需要定义Ingress字段,并将这个字段设置为空,以匹配所有源端点,但本身不设定网络策略,就已经是默认允许所有入站流量访问的,下面给出一个定义的格式:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-ingress
spec:
podSelector: {}
policyTypes: ["Ingress"]
ingress:
- {}实践中,通常将默认的网络策略设置为拒绝所有入站流量,然后再放行允许的源端点的入站流量。
3.3.2、放行特定的入站流量
[root@master network-policy-demo]# vim policy-demo.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-httpd
spec:
podSelector:
matchLabels:
run: httpd
policyTypes: ["Ingress"]
ingress:
- from:
- ipBlock:
cidr: 10.244.0.0/16
except:
- 10.244.2.0/24
- 10.244.1.0/24
- podSelector:
matchLabels:
access: "true"
ports:
- protocol: TCP
port: 80
[root@master network-policy-demo]# kubectl apply -f policy-demo.yaml
networkpolicy.networking.k8s.io/access-httpd created
[root@master network-policy-demo]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
access-httpd run=httpd 6s验证NetworkPolicy的有效性:
#创建带有标签的busybox pod访问,是可以正常访问的,但是因为仅开放了TCP协议,所以PING是无法ping通的
[root@master ~]# kubectl run busybox --rm -it --labels="access=true" --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # ping -c 3 10.244.0.2
PING 10.244.0.2 (10.244.0.2): 56 data bytes
--- 10.244.0.2 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
3.4、管控出站流量
通常,出站的流量默认策略应该是允许通过的,但是当有精细化需求,仅放行那些有对外请求需要的Pod对象的出站流量,也可以先为名称空间设置“禁止所有”的默认策略,再细化制定准许的策略。networkpolicy.spec中嵌套的Egress字段用来定义出站流量规则。
3.4.1、设定默认Egress策略
和Igress一样,只需要通过policyTypes字段指明生效的Egress类型规则,然后不去定义Egress字段,就不会去匹配到任何目标端点,从而拒绝所有的出站流量。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-egress
spec:
podSelector: {}
policyTypes: ["Egress"]实践中,需要进行严格隔离的环境通常将默认的策略设置为拒绝所有出站流量,再去细化配置允许到达的目标端点的出站流量。
3.4.2、放行特定的出站流量
下面举个例子定义一个Egress规则,对标签run=httpd的Pod对象,到达标签为access=true的Pod对象的80端口的流量进行放行。
[root@master network-policy-demo]# vim egress-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: httpd-egress
spec:
podSelector:
matchLabels:
run: httpd
policyTypes: ["Egress"]
egress:
- to:
- podSelector:
matchLabels:
access: "true"
ports:
- protocol: TCP
port: 80
#NetworkPolicy检测,一个带有access=true标签,一个不带
[root@master ~]# kubectl run busybox --rm -it --labels="access=true" --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
index.html 100% |*********************************************************************************************| 45 0:00:00 ETA
/ # exit
Session ended, resume using 'kubectl attach busybox-686cb649b6-6j4qx -c busybox -i -t' command when the pod is running
deployment.apps "busybox" deleted
[root@master ~]# kubectl run busybox2 --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # wget httpd-svc:8080
Connecting to httpd-svc:8080 (10.99.222.179:8080)
wget: can't connect to remote host (10.99.222.179): Connection timed out从上面的检测结果可以看到,带有标签access=true的Pod才能访问到httpd-svc,说明上面配置的Network Policy已经生效。
3.5、隔离名称空间
实践中,通常需要彼此隔离所有的名称空间,但是又需要允许它们可以和kube-system名称空间中的Pod资源进行流量交换,以实现监控和名称解析等各种管理功能。下面的配置清单示例在default名称空间定义相关规则,在出站和入站都默认均为拒绝的情况下,它用于放行名称空间内部的各Pod对象之间的通信,以及和kube-system名称空间内各Pod间的通信。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-deny-all
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: namespace-allow
namespace: default
spec:
policyTypes: ["Ingress","Egress"]
podSelector: {}
ingress:
- from:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]
egress:
- to:
- namespaceSelector:
matchExpressions:
- key: name
operator: In
values: ["default","kube-system"]需要注意的是,有一些额外的系统附件可能会单独部署到独有的名称空间中,比如将prometheus监控系统部署到prom名称空间等,这类具有管理功能的附件所在的名称空间和每一个特定的名称空间的出入流量也是需要被放行的。
参考文章:
https://www.cnblogs.com/linuxk/p/10517055.html
https://www.jianshu.com/p/22a7032bb7bd
最后
以上就是刻苦手套最近收集整理的关于K8s的网络模型和网络策略1、Kubernetes网络模型和CNI插件2、Kubernetes网络模型3、网络策略的全部内容,更多相关K8s内容请搜索靠谱客的其他文章。








发表评论 取消回复