除了加锁外,其实还有一种方式可以防止并发修改异常,这就是将读写分离技术(不是数据库上的)。
先回顾一下一个常识:
1、JAVA中“=”操作只是将引用和某个对象关联,假如同时有一个线程将引用指向另外一个对象,一个线程获取这个引用指向的对象,那么他们之间不会发生ConcurrentModificationException,他们是在虚拟机层面阻塞的,而且速度非常快,几乎不需要CPU时间。
2、JAVA中两个不同的引用指向同一个对象,当第一个引用指向另外一个对象时,第二个引用还将保持原来的对象。
基于上面这个常识,我们再来探讨下面这个问题:
在CopyOnWriteArrayList里处理写操作(包括add、remove、set等)是先将原始的数据通过JDK1.6的Arrays.copyof()来生成一份新的数组,然后在新的数据对象上进行写,写完后再将原来的引用指向到当前这个数据对象(这里应用了常识1),这样保证了每次写都是在新的对象上(因为要保证写的一致性,这里要对各种写操作要加一把锁,JDK1.6在这里用了重入锁),然后读的时候就是在引用的当前对象上进行读(包括get,iterator等),不存在加锁和阻塞,针对iterator使用了一个叫COWIterator的阉割版迭代器,因为不支持写操作,当获取CopyOnWriteArrayList的迭代器时,是将迭代器里的数据引用指向当前引用指向的数据对象,无论未来发生什么写操作,都不会再更改迭代器里的数据对象引用,所以迭代器也很安全(这里应用了常识2)。
CopyOnWriteArrayList中写操作需要大面积复制数组,所以性能肯定很差,但是读操作因为操作的对象和写操作不是同一个对象,读之间也不需要加锁,读和写之间的同步处理只是在写完后通过一个简单的“=”将引用指向新的数组对象上来,这个几乎不需要时间,这样读操作就很快很安全,适合在多线程里使用,绝对不会发生ConcurrentModificationException,所以最后得出结论:CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWriteArrayList的实现原理
在使用CopyOnWriteArrayList之前,我们先阅读其源码了解下它是如何实现的。以下代码是向ArrayList里添加元素,可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
public booleanadd(T e) {
finalReentrantLock lock = this.lock;
lock.lock();
try{
Object[] elements = getArray();
intlen = elements.length;
// 复制出新数组
Object[] newElements = Arrays.copyOf(elements, len +1);
// 把新元素添加到新数组里
newElements[len] = e;
// 把原数组引用指向新数组
setArray(newElements);
returntrue;
} finally {
lock.unlock();
}
}
final voidsetArray(Object[] a) {
array = a;
}读的时候不需要加锁,如果读的时候有多个线程正在向ArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的ArrayList。
public E get(intindex) {
returnget(getArray(), index);
}JDK中并没有提供CopyOnWriteMap,我们可以参考CopyOnWriteArrayList来实现一个,基本代码如下:
import java.util.Collection;
import java.util.Map;
import java.util.Set;
public classCopyOnWriteMap<K, V> implementsMap<K, V>, Cloneable {
privatevolatile Map<K, V> internalMap;
publicCopyOnWriteMap() {
internalMap =new HashMap<K, V>();
}
publicV put(K key, V value) {
synchronized(this) {
Map<K, V> newMap =new HashMap<K, V>(internalMap);
V val = newMap.put(key, value);
internalMap = newMap;
returnval;
}
}
publicV get(Object key) {
returninternalMap.get(key);
}
publicvoid putAll(Map<? extendsK, ? extends V> newData) {
synchronized(this) {
Map<K, V> newMap =new HashMap<K, V>(internalMap);
newMap.putAll(newData);
internalMap = newMap;
}
}
}实现很简单,只要了解了CopyOnWrite机制,我们可以实现各种CopyOnWrite容器,并且在不同的应用场景中使用。
CopyOnWrite的应用场景
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。实现代码如下:
package com.ifeve.book;
import java.util.Map;
import com.ifeve.book.forkjoin.CopyOnWriteMap;
/**
* 黑名单服务
*
* @author fangtengfei
*
*/
public classBlackListServiceImpl {
privatestatic CopyOnWriteMap<String, Boolean> blackListMap =new CopyOnWriteMap<String, Boolean>(
1000);
publicstatic boolean isBlackList(String id) {
returnblackListMap.get(id) == null? false : true;
}
publicstatic void addBlackList(String id) {
blackListMap.put(id, Boolean.TRUE);
}
/**
* 批量添加黑名单
*
* @param ids
*/
publicstatic void addBlackList(Map<String,Boolean> ids) {
blackListMap.putAll(ids);
}
}代码很简单,但是使用CopyOnWriteMap需要注意两件事情:
1. 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
2. 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
CopyOnWrite的缺点
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
关于C++的STL中,曾经也有过Copy-On-Write的玩法,参见陈皓的《C++ STL String类中的Copy-On-Write》,后来,因为有很多线程安全上的事,就被去掉了。
CopyOnWriteArrayList
一、 核心思想:
CopyOnWriteArrayList的核心思想是利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
二、类图预览:
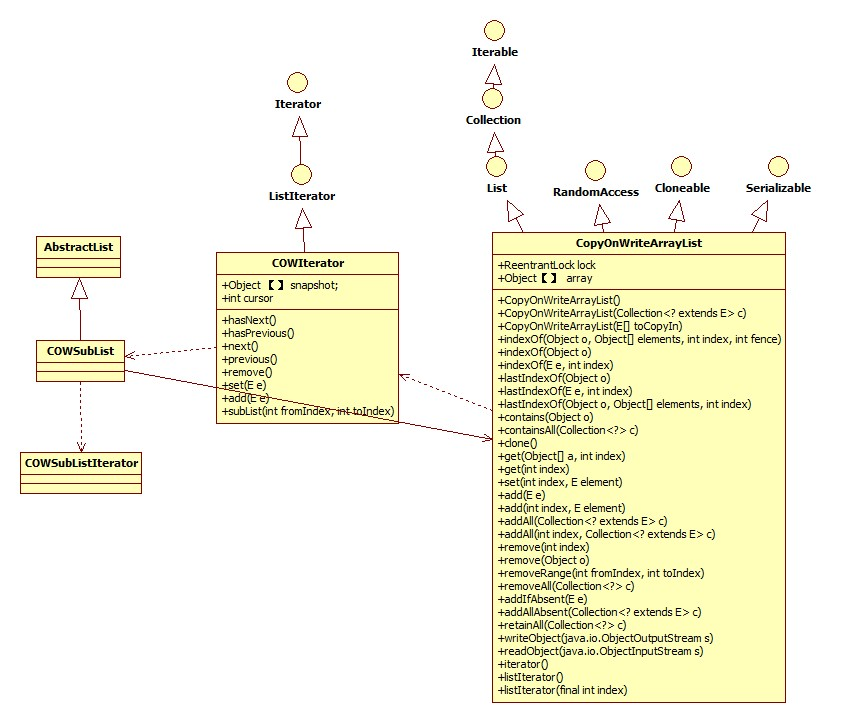
方法基本分为CopyOnWriteArrayList、indexOf、contains、get、set、add、remove、addIfAbsent和iterator几类:
1、CopyOnWriteArrayList 构造方法:
基本使用Arrays.copyOf 方法,将参数的集合类设置到array属性上。
2、indexOf方法:
简单的通过循环,对比找到所在的位置,核心代码:

- for (int i = index; i < fence; i++)
- if (o.equals(elements[i]))
- return i;
值得注意有两点,一是支持NULL对象、二是lastIndexOf从后面往前,提高性能
3、 contains方法:
该方法使用indexOf方法,避免代码重复。containsAll方法也是简单的循环判断是否包含单个元素。
4、get方法:
直接返回对应下标元素
5、set方法:
- public E set(int index, E element) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- Object[] elements = getArray();
- E oldValue = get(elements, index);
- if (oldValue != element) {
- int len = elements.length;
- Object[] newElements = Arrays.copyOf(elements, len);
- newElements[index] = element;
- setArray(newElements);
- } else {
- // Not quite a no-op; ensures volatile write semantics
- setArray(elements);
- }
- return oldValue;
- } finally {
- lock.unlock();
- }
- }
可以看到该法使用ReentrantLock锁, Arrays.copyOf创建一个新的数组是核心思想体现,oldValue != element这个判断更是尽可能的提高性能的努力。
而在esle里面,明明没有任何修改,为什么还要条用set方法,并且在addAllAbsent 方法里面有没有使用,以及那句注释(Not quite a no-op; ensures volatile write semantics),有几封邮件讨论这个问题。
大意是说:为了确保 voliatile 的语义,任何一个读操作都应该是写操作的结构,所以尽管写操作没有改变数据,还是调用set方法,当然这仅仅是语义的说明,去掉也是可以的。而对于 addIfAbsent方法为什么没有使用set方法,那是因为该方法本身的语义就是写或者不写,不写故不需要保持语义。
参考如下:
http://cs.oswego.edu/pipermail/concurrency-interest/2010-February/006886.html
http://cs.oswego.edu/pipermail/concurrency-interest/2010-February/006887.html
http://cs.oswego.edu/pipermail/concurrency-interest/2010-February/006888.html
http://en.usenet.digipedia.org/thread/13652/1242/
6、add方法:
- public boolean add(E e) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- Object[] elements = getArray();
- int len = elements.length;
- Object[] newElements = Arrays.copyOf(elements, len + 1);
- newElements[len] = e;
- setArray(newElements);
- return true;
- } finally {
- lock.unlock();
- }
- }
同样很简单,遵循,使用锁,Arrays.copyOf copy新数组、新增一个元素、set回去步骤。
另外一个重载的指定位置add元素的核心代码如下:
- newElements = new Object[len + 1];
- System.arraycopy(elements, 0, newElements, 0, index);
- System.arraycopy(elements, index, newElements, index + 1, numMoved);
主要使用System.arraycopy方法copy到一个新的数组
7、remove方法:
- public E remove(int index) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- Object[] elements = getArray();
- int len = elements.length;
- E oldValue = get(elements, index);
- int numMoved = len - index - 1;
- if (numMoved == 0)
- setArray(Arrays.copyOf(elements, len - 1));
- else {
- Object[] newElements = new Object[len - 1];
- System.arraycopy(elements, 0, newElements, 0, index);
- System.arraycopy(elements, index + 1, newElements, index,
- numMoved);
- setArray(newElements);
- }
- return oldValue;
- } finally {
- lock.unlock();
- }
- }
同样很简单,使用 System.arraycopy、Arrays.copyOf移动元素
移除指定元素方法的核心代码:通过双重循环,比较移动。
- for (int i = 0; i < newlen; ++i) {
- if (eq(o, elements[i])) {
- // found one; copy remaining and exit
- for (int k = i + 1; k < len; ++k)
- newElements[k-1] = elements[k];
- setArray(newElements);
- return true;
- } else
- newElements[i] = elements[i];
移除指定集合内方法核心代码:
- for (int i = 0; i < len; ++i) {
- Object element = elements[i];
- if (!c.contains(element))
- temp[newlen++] = element;
- }
- if (newlen != len) {
- setArray(Arrays.copyOf(temp, newlen));
- return true;
- }
8、addIfAbsent 方法:
- public boolean addIfAbsent(E e) {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- // Copy while checking if already present.
- // This wins in the most common case where it is not present
- Object[] elements = getArray();
- int len = elements.length;
- Object[] newElements = new Object[len + 1];
- for (int i = 0; i < len; ++i) {
- if (eq(e, elements[i]))
- return false; // exit, throwing away copy
- else
- newElements[i] = elements[i];
- }
- newElements[len] = e;
- setArray(newElements);
- return true;
- } finally {
- lock.unlock();
- }
- }
这里可以看到没有又相同的元素之间return了,没有调用set方法;
9、retainAll 方法:
- Object[] temp = new Object[len];
- for (int i = 0; i < len; ++i) {
- Object element = elements[i];
- if (c.contains(element))
- temp[newlen++] = element;
- }
基本是removeAll的翻版,只是 if (c.contains(element)) 这个是否定罢了。
10、writeObject、readObject方法:
- private void writeObject(java.io.ObjectOutputStream s)
- throws java.io.IOException{
- s.defaultWriteObject();
- Object[] elements = getArray();
- // Write out array length
- s.writeInt(elements.length);
- // Write out all elements in the proper order.
- for (Object element : elements)
- s.writeObject(element);
- }
- private void readObject(java.io.ObjectInputStream s)
- throws java.io.IOException, ClassNotFoundException {
- s.defaultReadObject();
- // bind to new lock
- resetLock();
- // Read in array length and allocate array
- int len = s.readInt();
- Object[] elements = new Object[len];
- // Read in all elements in the proper order.
- for (int i = 0; i < len; i++)
- elements[i] = s.readObject();
- setArray(elements);
- }
虽然CopyOnWriteArrayList 类实现了 序列化接口,但是变量数组确有transient关键字通过实现这两个方法。将快照序列化
11、iterator 方法:
- public void remove() {
- throw new UnsupportedOperationException();
- }
针对iterator使用了一个叫COWIterator的阉割版迭代器,因为不支持写操作 ,如上面add、set、remove都会跑出异常,当获取CopyOnWriteArrayList的迭代器时,是将迭代器里的数据引用指向当前引用指向的数据对象,无论未来发生什么写操作,都不会再更改迭代器里的数据对象引用,所以迭代器也很安全。
综上:
在CopyOnWriteArrayList里处理写操作(包括add、remove、set等)是先将原始的数据通过Arrays.copyof()来生成一份新的数组,然后在新的数据对象上进行写,写完后再将原来的引用指向到当前这个数据对象,并且加锁。
读操作是在引用的当前对象上进行读(包括get,iterator等),不存在加锁和阻塞。
因为每次使用CopyOnWriteArrayList.add都要引起数组拷贝, 所以应该避免在循环中使用CopyOnWriteArrayList.add。可以在初始化完成后设置到CopyOnWriteArrayList中,或者使用CopyOnWriteArrayList.addAll方法
CopyOnWriteArrayList采用“写入时复制”策略,对容器的写操作将导致的容器中基本数组的复制,性能开销较大。所以在有写操作的情况下,CopyOnWriteArrayList性能不佳,而且如果容器容量较大的话容易造成溢出。
转:http://ifeve.com/java-copy-on-write/
http://www.cnblogs.com/sunwei2012/archive/2010/10/08/1845656.html
源码分析详见:
http://www.molotang.com/articles/558.html
http://blog.itpub.net/28912557/viewspace-1133900/
最后
以上就是愤怒冰棍最近收集整理的关于Copy-On-Write容器与CopyOnWriteArrayList理解一、 核心思想:二、类图预览:的全部内容,更多相关Copy-On-Write容器与CopyOnWriteArrayList理解一、内容请搜索靠谱客的其他文章。








发表评论 取消回复