------- android培训、java培训、期待与您交流! ----------
Java IO流
1.流
在Java API中,可以从其中读入一个字节序列的对象称作输入流,而可以向其中写入一个字节序列的对象称作输出流。这些字节序列的来源和目的地可以是文件,而且通常都是文件,但是也可以是网络连接,甚至是内存块。抽象类InputStream和OutputStream构成了有层次结构的输入/输出(I/O)类的基础。
因为面向字节的流不便于处理以Unicode形式存储的信息,所以从抽象类Reader和Writer中继承出来的专门用于处理Unicode字符的类构成了一个单独的层次结构。这些类拥有的读入和写出操作都是基于两个字节的Unicode码元的,而不是基于单字节的字符。
1.1 读写字节
public abstract class InputStream
extends Object
implements Closeable
此抽象类是表示字节输入流的所有类的超类。
InputStream类有一个抽象方法:
public abstract int read()
从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。在设计具体输入流时,必须覆盖这个方法以提供适用的功能,例如,在FileInputStream类中,这个方法将从某个文件中读取一个字节,而System.in(这个是InputStream的一个子类的预定义对象)却是从键盘读入信息的。InputStream类还有若干个非抽象的方法,它们可以读入一个字节数组,或者跳过大量的字节。这些方法都要调用抽象的read()方法,因此,各个子类都只需要覆盖这一个方法。
public int read(byte[] b)
从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。
public int read(byte[] b, int off, int len)
将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。
public long skip(long n)
跳过和丢弃此输入流中数据的 n 个字节。
public int available()
返回在不阻塞的情况下可用的字节数。
public void close()
关闭此输入流并释放与该流关联的所有系统资源。
public void reset()
将此流重新定位到最后一次对此输入流调用 mark 方法时的位置。
public void mark(int readlimit)
在此输入流中标记当前的位置。对 reset 方法的后续调用会在最后标记的位置重新定位此流,以便后续读取重新读取相同的字节。但是,如果在调用 reset 之前可以从流中读取多于 readlimit 的字节,则不需要该流记录任何数据。
public boolean markSupported()
如果此输入流实例支持 mark 和 reset 方法,则返回 true;否则返回 false。
与此类似,Outputstream类定义了下面的抽象方法:
public abstract void write(int b)
将指定的字节写入此输出流。write 的常规协定是:向输出流写入一个字节。要写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略。
ublic void write(byte[] b)
将 b.length 个字节从指定的 byte 数组写入此输出流。
public void write(byte[] b, int off, int len)
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
public void flush()
刷新此输出流并强制写出所有缓冲的输出字节。
public void close()
关闭此输出流并释放与此流有关的所有系统资源。
read和write方法在执行时都将阻塞,直到字节确实被读入或写出。这就意味着如果流不能被立即访问(网络连接忙),那么当前的线程将被阻塞。这使得在这个方法等待指定的流变为可用的这段时间里,其他的线程就有机会去执行有用的工作。
available方法使我们可以去检查当前可用于读入的字节数量,这意味着使用检查之后的字节数量就不可能被阻塞:
InputStream in = new FileInputStream(new File("words.txt"));
int byteAvailable = in.available();
if (byteAvailable > 0) {
byte[] data = new byte[byteAvailable];
in.read(data);
}当完成对流的读写操作时,应该调用close()方法来关闭它,这个方法会释放掉系统资源。如果一个应用程序打开了过多的流而没有关闭它们,那么系统资源将被耗尽。关闭一个输出流的同时也就是在清空用于该输出流的缓冲区:所有被临时置于缓冲区中,以便用更大的包的形式传递的字符在关闭输出流时都将被送出。特别是,如果不关闭文件,那么写出字节的最后一个包可能将永远也得不到传送。当然,我们还可以用flush()方法来认为的清空。
即使某个流类提供了使用原生的read 和write功能来操作的某些具体方法,应用系统也很少使用到他们,因为大家感兴趣的数据可能是包含数字、字符串和对象,而不是原生字节。Java提供了很多从基本的InputStream和OutputStream类导出的类,这些类使我们可以处理那些以常用格式表示的数据,而不只是在字节级别上表示的数据。
1.2 完整的流家族
Java拥有一个包含各种类类型的流家族,其数量超过60个!如下图1和图2.
按照使用方法来划分,可以分成处理字节和字符的两个单独的层次结构。正如所见,InputStream和OutputStream类可以读写单个的字节或字节数组,这类构成了图1所示的层次结构的基础。要想读写字符串和数字,就需要功能更强大的子类,例如,DataInputStream和DataOutputStream可以以二进制格式读写所有的基本Java类型。还包含了很多功能独特的流,例如,ZipInputStream和ZIPOutputStream可以以常见的ZIP压缩格式读写文件。
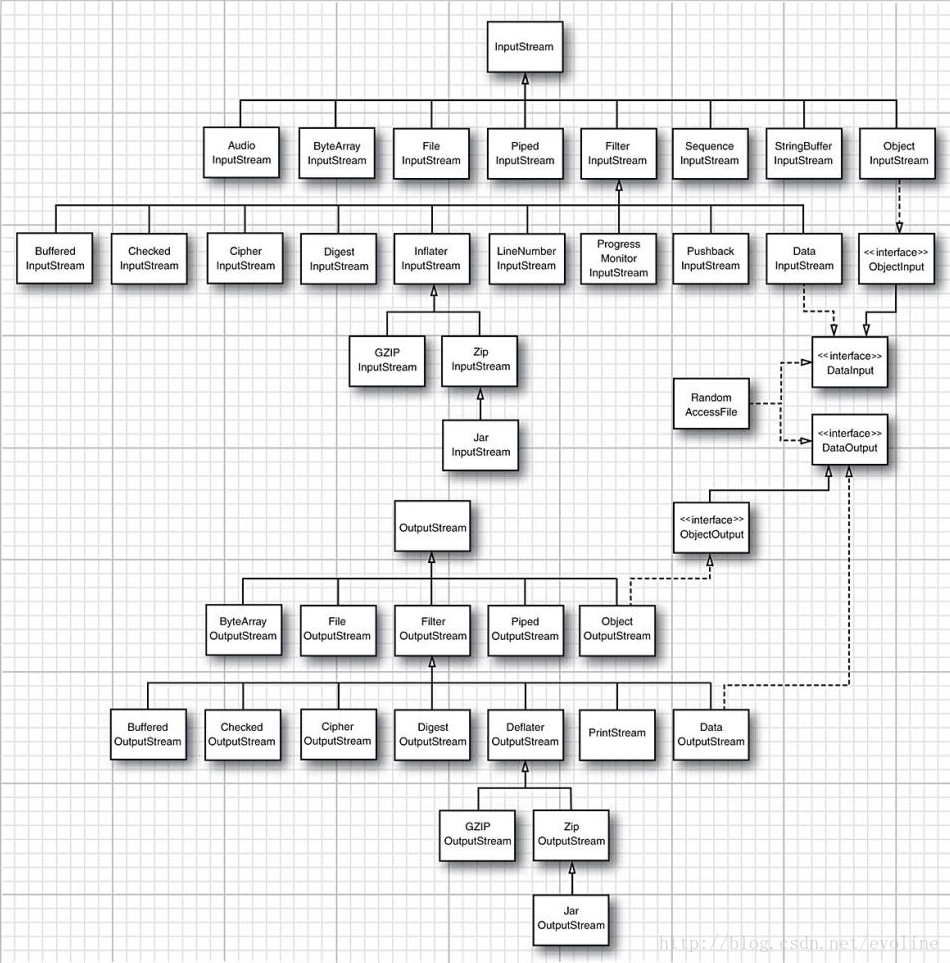
图1 输入流和输出流的层次结构
另一方面,对于Unicode文本,可以使用抽象类Reader和Writer的子类(图2),Reader和Writer类基本方法与InputStream和OutputStream中方法类似。
public abstract int read(char[] cbuf, int off, int len)
将字符读入数组的某一部分。
public abstract void write(char[] cbuf, int off, int len)
写入字符数组的某一部分。
public int read()
读取单个字符。作为整数读取的字符,范围在 0 到 65535 之间。
public void write(int c)
写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。
void write(String str)
写入字符串。
void write(String str, int off, int len)
写入字符串的某一部分。
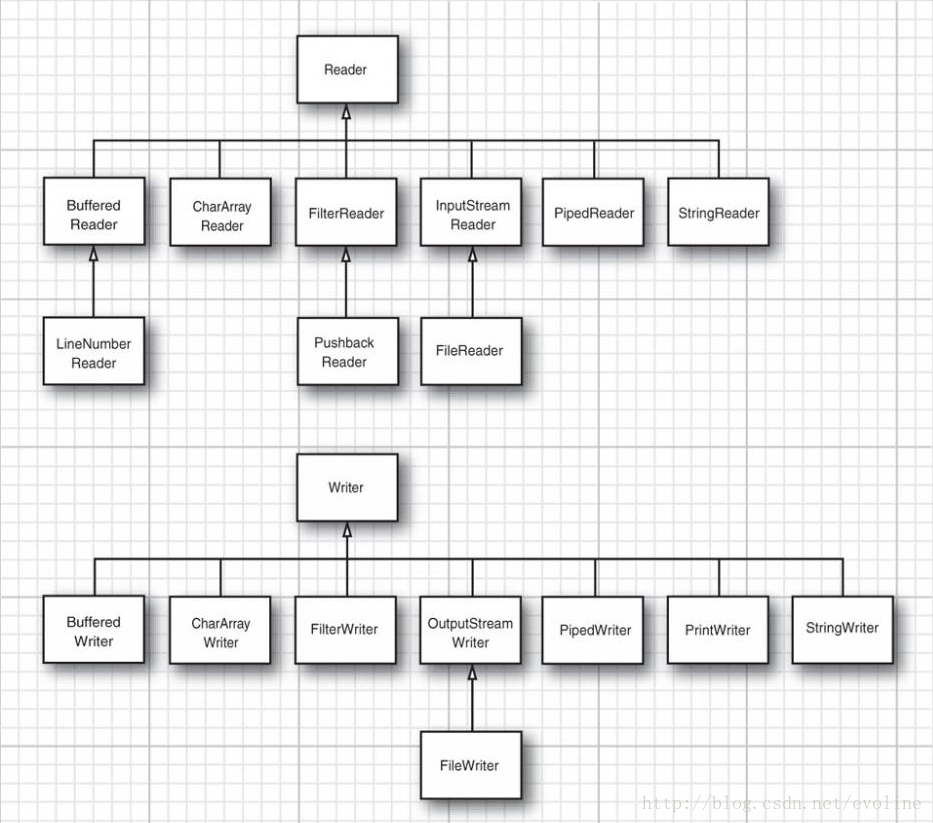
图2 Reader和Writer的层次结构
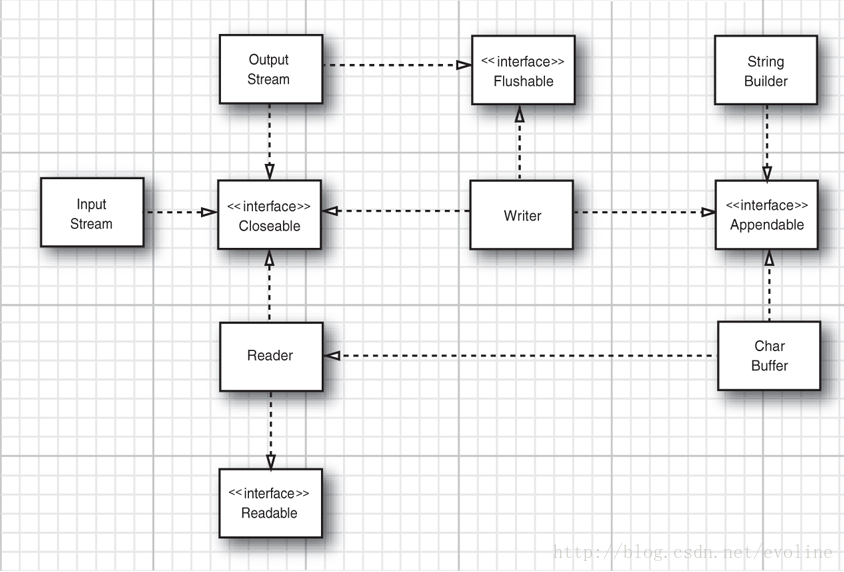
Java SE 5.0 引入了4个附加的接口:Closeable, Flushable, Appendable, Readable(图3)。前面两个接口非常简单,它们分别拥有下面的方法:
void close()
void flush()
InputStream、OutputStream、Reader和Writer都是实现了Closeable接口,而OutputStream和Writer还实现了Flushable接口。
Readable接口只有一个方法:
int read(CharBuffer cb) 试图将字符读入指定的字符缓冲区。CharBuffer 类拥有按顺序和随机地进行读写访问的方法,它表示一个内存中的缓冲区或一个内存映射的文件。
在流类家族中,只有Writer实现了Appendable。Appendable接口有两个用于添加单个字符和字符序列的方法:
Appendable append(char c) 向此 Appendable 添加指定字符。
Appendable append(CharSequence csq) 向此 Appendable 添加指定的字符序列。
CharSequence 接口描述了一个char值序列的基本属性,它是用String、StringBuffer、StringBuilder和CharBuffer类实现的。
1.3 组合流过滤器
FileInputStream和FileOutputStream可以提供附着在一个磁盘文件上的输入流和输出流,而只需向其构造器提供文件名或文件的完整路径名。
FileInputStream(File file)
通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。
FileInputStream(FileDescriptor fdObj)
通过使用文件描述符 fdObj 创建一个 FileInputStream,该文件描述符表示到文件系统中某个实际文件的现有连接。
FileInputStream(String name)
通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。
FileOutputStream(File file)
创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
FileOutputStream(File file, boolean append)
创建一个向指定 File 对象表示的文件中写入数据的文件输出流。如果append为 true,则将字节追加写入文件末尾处,而不是写入文件开始处。
FileOutputStream(FileDescriptor fdObj)
创建一个向指定文件描述符处写入数据的输出文件流,该文件描述符表示一个到文件系统中的某个实际文件的现有连接。
FileOutputStream(String name)
创建一个向具有指定名称的文件中写入数据的输出文件流。
FileOutputStream(String name, boolean append)
创建一个向具有指定 name 的文件中写入数据的输出文件流。如果append为 true,则将字节追加写入文件末尾处,而不是写入文件开始处。
BufferedInputStream(InputStream in)
创建一个 BufferedInputStream 并保存其参数,为另一个输入流添加一些功能,即缓冲输入以及支持 mark 和 reset 方法的能力。
public BufferedOutputStream(OutputStream out)
创建一个新的缓冲输出流,以将数据写入指定的底层输出流。而不必针对每次字节写入调用底层系统。
示例:
InputStream in = new FileInputStream(new File("c:/code/words.txt"));
FileInputStream fin = new FileInputStream("code.txt");注意:因为在java.io中的类都将相对路径名解释为以用户工作目录开始,因此希望了解这个目录。可以通过调用System.getProperty("user.dir")来获得这个目录的信息。
与抽象类InputStream和OutputStream一样,这些支持在字节级别上的读写。因为就是说我们只能从fin对象中读入字节或字节数组。
byte b = (byte) in.read();
或
byte[] bytes = new byte[1024] ;
int read = fin.read(bytes);如果我们只有DataInputStream或DataOutputStream,那么我们就只能读入或写出数字类型:
DataInputStream din = new DataInputStream(in);
double d = din.readDouble();
DataOutputStream don = new DataOutputStream(new FileOutputStream("x"));
don.writeDouble(d);现在可以看出FileInputStream没有任何读入数字类型的方法,DataInputStream也没有任何从文件中获取的数据的方法。
Java使用了一种巧妙的机制来分离这两种职责。某些流(FileInputStream和URL类中的openStream)可以从文件和其他外部的位置上获取字节,而其他的流(DataInputStream和PrintWriter)可以将字节组装到更有用的数据类型中。我们就必须对二者进行组合。例如,为了从文件中读取数字,首先需要创建一个FileInputStream,然后将其传递给DataInputStream的构造器:
InputStream in = new FileInputStream(new File("c:/code/words.txt"));
DataInputStream din = new DataInputStream(in);
double d = din.readDouble();FilterInputStream和FilterOutputStream类的子类用于添加原生字节流。可以通过嵌套过滤器来添加多重功能。例如,流在默认情况下是不被缓冲区缓存的,也就是说,每个read的调用都会请求系统再分发一个字节。相比之下,请求一个数据块并将其置于缓冲区中会显得更加高效。如果我们想使用缓冲机制,以及用于文件的数据输入方法,那么就需要使用下面的构造器序列:
DataInputStream din = new DataInputStream(new BufferedInputStream(new FileInputStream("code.txt")));注意我们要把DataInputStream置于构造器链的最后,这是因为我们希望使用DataInputStream的方法,并且希望它们能够使用带缓冲机制的read方法。(包装设计模式)
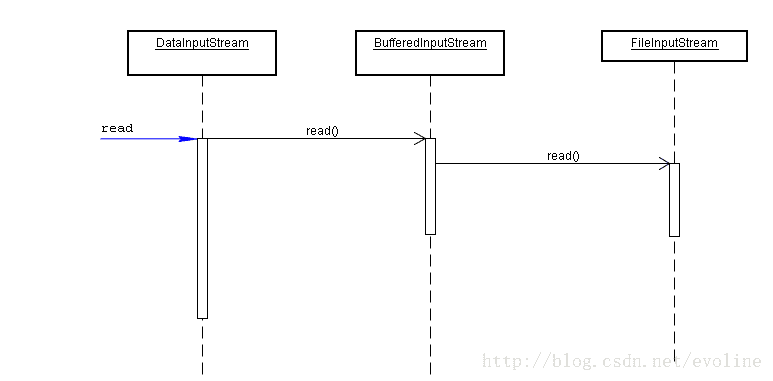
2. 文本输入与输出
在保存数据时,可以选择二进制或文本格式。例如,整数1234存储成二进制数时,它被写为由字节00 00 04 D2构成的序列(十六进制),而存储成文本格式时,它被存成了字符串“1234”.尽管二进制I/O高速且高效,但是它不适合我们阅读。
在存储文本字符串时,需要考虑字符编码方式问题。在UTF-16编码方式中,字符串“1234”编码为00 31 00 32 00 33 00 34(十六进制)。但是,许多程序都希望文本文件按照其他的编码方式编码。
OutputStreamWriter类将使用选定的字符编码方式,把Unicode字符流转换为字节流。相反地,InputStreamReader类将把包含字节(用某种字符编码方式表示的字符)的输入流转换为可以产生Unicode字符的输入流。例如,下面的代码就展示了如何从控制台接收键盘数据,并将其转换为Unicode:
InputStreamReader in = new InputStreamReader(System.in);这个输入流读入器会使用本地系统默认的字符编码方式,例如简体中文采用GBK。你可以通过在InputStreamReader的构造器中指定的方式来选择不同的编码方式。例如,
InputStreamReader in = new InputStreamReader(new FileInputStream("cad.dat"),"UTF-8");因为将读入器或写出器附着到文件上非常普遍,所以就提供了FileReader和FileWriter这一对使用方便的类来专门用于此目的。例如,
FileWriter writer = new FileWriter("output.txt");
等同于
FileWriter out = new FileWriter(new FileOutputStream("output.txt"));
2.1 如何写入文本输出
public abstract class Writer
extends Object
implements Appendable, Closeable, Flushable
写入字符流的抽象类。
public class PrintWriter extends Writer
向文本输出流打印对象的格式化表示形式。
PrintWriter(File file)
使用指定文件创建不具有自动行刷新的新 PrintWriter。
PrintWriter(File file, String csn)
创建具有指定文件和字符集且不带自动刷行新的新 PrintWriter。
PrintWriter(OutputStream out)
根据现有的 OutputStream 创建不带自动行刷新的新 PrintWriter。
PrintWriter(OutputStream out, boolean autoFlush)
通过现有的 OutputStream 创建带自动行刷新的新的 PrintWriter。
PrintWriter(String fileName)
创建具有指定文件名称且不带自动行刷新的新 PrintWriter。
PrintWriter(String fileName, String csn)
创建具有指定文件名称和字符集且不带自动行刷新的新 PrintWriter。
PrintWriter(Writer out)
创建不带自动行刷新的新 PrintWriter。
PrintWriter(Writer out, boolean autoFlush)
创建带自动行刷新的新 PrintWriter。
对于文本输出,可以使用PrintWriter类,这个类拥有以文本格式打印字符串和数字的方法,它甚至还有一个将PrintWriter链接到FileWriter的方便方法。下面语句:
PrintWriter out = new PrintWriter("output.txt");
等同于
PrintWriter out = new PrintWriter(new FileWriter("output.txt"));为了写出到打印写出器,需要使用与使用System.out时相同的方法print、println和printf。可以用这些方法拉里打印数字(int,short,long,float,double)、字符、boolean值、字符串和对象。
PrintWriter out = new PrintWriter("output.txt");
String name = "zhangsan";
double salary = 7500;
out.print(name);
out.print(' ');
out.print(salary);
out.close();写入到文件的字符串:zhangsan 7500.0
写出到写出器out,之后这些字符将会被转换成字节并最终保存到“output.txt”文件。
println方法在行中添加了对目标系统来说恰当的行结束符“n”,也就是通过调用System.getProperty("file.separator")而获得的字符串。如果写出器设置为自动清空模式[写入器(reader)和写出器(writer)],那么只要调用println,缓冲区的所有字符都会被发送到它们的目的地(打印写出器总是带有缓冲区的)。在默认情况下,自动清空机制是不能使用的。可以通过使用PrintWriter(Writer out , Boolean autoFlush)来使用或禁用自动清空机制:
PrintWriter out = new PrintWriter(new FileWriter("output.txt"),true);// autoFlush
2.2 如何读入文本输入
public abstract class Reader
extends Object
implements Readable, Closeable
用于读取字符流的抽象类。
public class BufferedReader extends Reader
从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
public String readLine()
读取一个文本行。通过下列字符之一即可认为某行已终止:换行 ('n')、回车 ('r') 或回车后直接跟着换行。
public class FileReader extends InputStreamReader
用来读取字符文件的便捷类。
据上文本输出,以二进制格式写出数据,需要使用DataOutputStream。以文本格式写出数据,需要使用PrintWriter。因此我们可能认为存在着与DataInputStream类似的类允许我们以文本格式读入数据,但是在Java SE 5.0之前,处理文本输入的唯一方式就是通过BufferedReader类,它拥有一个readLine()方法,使得我们可以读入一行文本(只将回车、换行看作输入结束标记)。需要将带缓冲区的读入器与输入源组合起来:
BufferedReader in = new BufferedReader(new FileReader("words.txt"));readLine()方法在没有输入时返回null。下面是一个典型输入循环结构:
String line;
while (null != (line = in.readLine())) {
System.out.println(line);
}但是BufferedReader类没有任何用于读入数字的方法,这就用到Scanner类来读入文本输入。【java.util.Scanner类】
2.3 以文本格式存储对象
下面有个Employee类,将一个Employee记录数组存储成一个文本文件,其中每个实例记录保存在单独的一行中,而成员变量彼此之间用分隔符分离开(|)。如下面格式:
class Employee{
private String name;
private double salary;
private Date hireDay;
public Employee() { }
public Employee(String n, double s, int year, int month, int day) {
name = n;
salary = s;
GregorianCalendar calendar = new GregorianCalendar(year, month - 1, day);
hireDay = calendar.getTime();
}
public String getName() { return name; }
public double getSalary() { return salary;}
public Date getHireDay() { return hireDay;}
public void raiseSalary(double byPercent) {
salary += salary * byPercent / 100;
}
public String toString() {
return getClass().getName() + "[name=" + name + ",salary=" + salary
+ ",hireDay=" + hireDay + "]";
}
}Carl Cracker|75000.0|1987|12|15
Harry Hacker|50000.0|1989|10|1
Tony Tester|40000.0|1990|3|15
记录相当简单,我们只需要写出到一个文本文件中,所以我们使用PrintWriter类。在Employee类中添加wirteData方法:
/**
* Writes employee data to a print writer
*
* @param out
* the print writer
*/
public void writeData(PrintWriter out) {
GregorianCalendar calendar = new GregorianCalendar();
calendar.setTime(hireDay);
out.println(name + "|"
+ salary + "|"
+ calendar.get(Calendar.YEAR)+ "|"
+ (calendar.get(Calendar.MONTH) + 1) + "|"
+ calendar.get(Calendar.DAY_OF_MONTH));
}为了读入记录,每次读入一行,然后分离所有的域。使用一个Scanner扫描器来读入一行,然后用String.split方法将这一行分割成一组标记(“\|”)。竖线在正则表达式中具有特殊含义,因此它需要用 字符来表示转义,而这个 又需要另一个 来转义。
/**
* Reads employee data from a buffered reader
*
* @param in
* the scanner
*/
public void readData(Scanner in) {
String line = in.nextLine();
String[] tokens = line.split("\|");
name = tokens[0];
salary = Double.parseDouble(tokens[1]);
int y = Integer.parseInt(tokens[2]);
int m = Integer.parseInt(tokens[3]);
int d = Integer.parseInt(tokens[4]);
GregorianCalendar calendar = new GregorianCalendar(y, m - 1, d);
hireDay = calendar.getTime();
}
/**
* Writes all employees in an array to a print writer
* @param employees an array of employees
* @param out a print writer
*/
private static void writeData(Employee[] employees, PrintWriter out) throws IOException
{
// write number of employees
out.println(employees.length);
for (Employee e : employees)
e.writeData(out);
}
例题:有五个学生,每个学生有3门课(语文、数学、英语)的成绩,写一个程序接收从键盘输入学生的信息,输入格式为:name,30,30,30(姓名,三门课成绩),然后把输入的学生信息按总分从高到低的顺序写入到一个名称"stu.txt"文件中。要求:stu.txt文件的格式要比较直观,打开这个文件,就可以很清楚的看到学生的信息。
2.4 字符集
Java SE 1.4 中引入的java.nio包引入的Charset类统一了对字符集的转换。Charset类使用的是由IANA字符集注册中心标准化的字符集名字。可以通过调用静态的forName方法来获得一个Charset,只需要向这个方法传递一个官方名字或者是它的某个别名:
Charset cset = Charset.forName("ISO-8859-1");字符集名字大小写不敏感,为了兼容其他的命名惯例,每个字符集可以拥有许多别名。例如,
ISO-8859-1的别名有:
csISOLatin1
IBM-819
iso-ir-100
8859_1
ISO_8859-1
l1
ISO8859-1
ISO_8859_1
cp819
ISO8859_1
latin1
ISO_8859-1:1987
819
IBM819
方法aliases可以返回由别名构成的set对象。
Charset cset = Charset.forName("ISO-8859-1");
Set<String> aliases = cset.aliases();
for (String alias : aliases) {
System.out.println(alias);
}为了确定在某个特定实现中那些字符集可用的,可以调用静态的availableCharsets方法。
Map<String, Charset> charsets = Charset.availableCharsets();
for(String name :charsets.keySet()){
System.out.println(name);
}一旦有了字符集,就可以使用它将Unicode字符串转换成编码而成的字节序列,下面是如何编码Unicode字符串的代码:
String str = "Hello";
ByteBuffer buffer = cset.encode(str);
byte[] bytes = buffer.array();与之相反,要想解码字节序列,需要有字节缓冲区。使用ByteBuffer数组的静态方法wrap可以将一个字节数组转换成一个字节缓冲区。Decode方法的结果是一个CharBuffer,调用它的toString方法可以获得一个字符串。
String str = "Hello";
ByteBuffer buffer = cset.encode(str);
byte[] bytes = buffer.array();
ByteBuffer bbuf = ByteBuffer.wrap(bytes, 0, bytes.length);
CharBuffer cbuf = cset.decode(bbuf);
String s = cbuf.toString();
System.out.println(s);
3. 读写二进制数据
DataInput 接口用于从二进制流中读取字节,并根据所有 Java 基本类型数据进行重构。同时还提供根据 UTF-8 修改版格式的数据重构 String 的工具。
DataOutput 接口用于将数据从任意 Java 基本类型转换为一系列字节,并将这些字节写入二进制流。同时还提供了一个将 String 转换成 UTF-8 修改版格式并写入所得到的系列字节的工具。
DataOutput接口定义了用于二进制格式写数组、字符、boolean值和字符串的方法:
void writeBoolean(boolean v)
将一个 boolean 值写入输出流。
void writeByte(int v)
将参数 v 的八个低位写入输出流。
void writeBytes(String s)
将一个字符串写入输出流。
void writeChar(int v)
将一个 char 值写入输出流,该值由两个字节组成。
void writeChars(String s)
将字符串 s 中的所有字符按顺序写入输出流,每个字符用两个字节表示。
void writeDouble(double v)
将一个 double 值写入输出流,该值由八个字节组成。
void writeFloat(float v)
将一个 float 值写入输出流,该值由四个字节组成。
void writeInt(int v)
将一个 int 值写入输出流,该值由四个字节组成。
void writeLong(long v)
将一个 long 值写入输出流,该值由八个字节组成。
void writeShort(int v)
将两个字节写入输出流,用它们表示参数值。
void writeUTF(String s)
将表示长度信息的两个字节写入输出流,后跟字符串 s 中每个字符的 UTF-8 修改版表示形式。
例如,writeInt总是将一个整数写出为4个字节的二进制数量值,而不管它有多少位,writeDouble总是将一个double值写出为8个字节的二进制数量值。wirteUTF方法使用修订版的8位Unicode转换格式写出字符串,与直接使用标准的UTF-8编码方法不同,字符型字符串首先用UTF-16表示,其结果之后使用UTF-8规则进行编码。
为了读回数据,可以使用接口DataInput中定义的方法:
boolean readBoolean()
读取一个输入字节,如果该字节不是零,则返回 true,如果是零,则返回 false。
byte readByte()
读取并返回一个输入字节。
char readChar()
读取两个输入字节并返回一个 char 值。
double readDouble()
读取八个输入字节并返回一个 double 值。
float readFloat()
读取四个输入字节并返回一个 float 值。
int readInt()
读取四个输入字节并返回一个 int 值。
long readLong()
读取八个输入字节并返回一个 long 值。
short readShort()
读取两个输入字节并返回一个 short 值。
String readUTF()
读入一个已使用 UTF-8 修改版格式编码的字符串。
DataInputStream类实现了DataInput接口,要想从文件中读取二进制数据,需要将DataInputStream与某个字节源相组合:
DataInputStream in = new DataInputStream(new FileImageInputStream("temp.dat"));
随机访问文件(RandomAccessFile)
public class RandomAccessFile
extends Object
implements DataOutput, DataInput, Closeable
public RandomAccessFile(File file, String mode)
mode 参数指定用以打开文件的访问模式。允许的值及其含意为:
| "r" | 以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException。 |
| "rw" | 打开以便读取和写入。如果该文件尚不存在,则尝试创建该文件。 |
| "rws" | 打开以便读取和写入,对于 "rw",还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备。 |
| "rwd" | 打开以便读取和写入,对于 "rw",还要求对文件内容的每个更新都同步写入到底层存储设备。 |
RandomAccessFile类可以在文件中的任意位置查找或写入数据。磁盘文件都是随机访问的,但是从网络而来的数据却不是。可以打开一个随机访问文件,只用于读入或同时用于读写,通过字符串“r”(用于读入访问)或“rw”(用于读写)作为构造器的第二个参数。
RandomAccessFile in = new RandomAccessFile("temp.dat", "r");
RandomAccessFile inOut = new RandomAccessFile("temp.dat", "rw");随机访问文件有一个表示下一个将被读入或写出的字节所在处位置的文件指针,seek方法可以将这个文件指针设置到文件内部的任意字节位置(偏移量),seek的参数是一个long类型的整数,它的值是位于0到文件按照字节来度量的长度之间。
public void seek(long pos)
设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。
参数:pos - 从文件开头以字节为单位测量的偏移量位置,在该位置设置文件指针。
long getFilePointer()
返回此文件中的当前偏移量。到此文件开头的偏移量(以字节为单位),在该位置发生下一个读取或写入操作。
RandomAccessFile类同时实现了DataInput和DataOutput接口。为了读写随机访问文件,可以使用readInt/writeInt、readChar/writeChar等之类的方法。
import java.io.*;
import java.util.*;
public class RandomFileTest {
public static void main(String[] args) {
Employee[] staff = new Employee[3];
staff[0] = new Employee("Carl Cracker", 75000, 1987, 12, 15);
staff[1] = new Employee("Harry Hacker", 50000, 1989, 10, 1);
staff[2] = new Employee("Tony Tester", 40000, 1990, 3, 15);
try {
// save all employee records to the file employee.dat
DataOutputStream out = new DataOutputStream(new FileOutputStream("employee.dat"));
for (Employee e : staff)
e.writeData(out);
out.close();
// retrieve all records into a new array
RandomAccessFile in = new RandomAccessFile("employee.dat", "r");
// compute the array size
int n = (int) (in.length() / Employee.RECORD_SIZE);
Employee[] newStaff = new Employee[n];
// read employees in reverse order
for (int i = n - 1; i >= 0; i--) {
newStaff[i] = new Employee();
in.seek(i * Employee.RECORD_SIZE);
newStaff[i].readData(in);
}
in.close();
// print the newly read employee records
for (Employee e : newStaff)
System.out.println(e);
} catch (IOException e) {
e.printStackTrace();
}
}
}
class Employee {
public Employee() {
}
public Employee(String n, double s, int year, int month, int day) {
name = n;
salary = s;
GregorianCalendar calendar = new GregorianCalendar(year, month - 1, day);
hireDay = calendar.getTime();
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public Date getHireDay() {
return hireDay;
}
/**
* Raises the salary of this employee.
*
* @byPercent the percentage of the raise
*/
public void raiseSalary(double byPercent) {
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString() {
return getClass().getName() + "[name=" + name + ",salary=" + salary
+ ",hireDay=" + hireDay + "]";
}
/**
* Writes employee data to a data output(固定大小)
* @param out the data output
* @throws IOException
*/
public void writeData(DataOutput out) throws IOException {
DataIO.writeFixedString(name, NAME_SIZE, out);
out.writeDouble(salary);
GregorianCalendar calendar = new GregorianCalendar();
calendar.setTime(hireDay);
out.writeInt(calendar.get(Calendar.YEAR));
out.writeInt(calendar.get(Calendar.MONTH) + 1);
out.writeInt(calendar.get(Calendar.DAY_OF_MONTH));
}
/**
* Reads employee data from a data input
* (每条记录大小一样)
* @param in
* the data input
*/
public void readData(DataInput in) throws IOException {
name = DataIO.readFixedString(NAME_SIZE, in);
salary = in.readDouble();
int y = in.readInt();
int m = in.readInt();
int d = in.readInt();
GregorianCalendar calendar = new GregorianCalendar(y, m - 1, d);
hireDay = calendar.getTime();
}
/*
* 使用40个字符来表示名字字符串,所以每条记录是100字节
* 40字符 = 80字节(名字)
* 1 double = 8字节(薪水)
* 3 int = 12字节(日期)
*/
public static final int NAME_SIZE = 40;
public static final int RECORD_SIZE = 2 * NAME_SIZE + 8 + 4 + 4 + 4;//(String,double,int,int,int)
private String name;
private double salary;
private Date hireDay;
}
class DataIO {
/**
* 从输入流中读入字符
* @param size 长度
* @param in
* @return
* @throws IOException
*/
public static String readFixedString(int size, DataInput in)
throws IOException {
StringBuilder b = new StringBuilder(size);
int i = 0;
boolean more = true;
while (more && i < size) {
char ch = in.readChar();
i++;
if (ch == 0)
more = false;
else
b.append(ch);
}
in.skipBytes(2 * (size - i));
return b.toString();
}
/**
* 读写具有固定大小的字符串
* @param s
* @param size
* @param out
* @throws IOException
*/
public static void writeFixedString(String s, int size, DataOutput out)
throws IOException {
for (int i = 0; i < size; i++) {
char ch = 0;
if (i < s.length())
ch = s.charAt(i);
out.writeChar(ch);
}
}
}
4. ZIP文档
ZIP文档通常以压缩格式存储了一个或多个文件,每个ZIP文档都有一个包含诸如文件名字和使用的压缩方法等信息的头。在Java中,可以使用ZipInputStream来读入ZIP文档。如果需要浏览文档中每个单独的项,getNextEntry方法就可以返回一个描述这些项的ZipEntry类型对象。ZipInputStream的read方法被修改为在碰到当前条目的结尾时返回-1(而不是到达ZIP文件的结尾),所以必须要调用closeEntry()来读入下一项。
ZipInputStream zin = new ZipInputStream(new FileInputStream("c:/code/v1ch13.zip"));
ZipEntry entry ;
while (null != (entry=zin.getNextEntry())) {
if (!entry.isDirectory()) {
System.out.println(entry.getName()+" ,size:"+entry.getSize());
}
zin.closeEntry();
}
zin.close();当希望读入某个ZIP项的内容时,我们可能并不想使用原生的read方法,通常使用某个更能胜任的流过滤器的方法。
ZipInputStream zin = new ZipInputStream(new FileInputStream("c:/code/v1ch13.zip"));
ZipEntry entry;
while (null != (entry=zin.getNextEntry())) {
if (!entry.isDirectory() && entry.getName().endsWith(".java")) {
Scanner sc = new Scanner(zin);
while(sc.hasNext()){
String nextLine = sc.nextLine();
System.out.println(nextLine);
}
}
zin.closeEntry();
}
zin.close();要写出到ZIP文件,可以使用ZipOutputStream,对于希望放入到ZIP文件中的每一项都应该创建一个ZipEntry对象,并将文件名传递给ZipEntry的构造器,它将设置其他文件日期和解压缩方法等参数。然后,需要调用ZipOutputStream的putNtextEntry()方法来开始写出新文件,并将文件数据发送到ZIP流中。当完成时,需要调用closeEntry。然后,要对存储的文件都重复此过程。
// 把code下所有java文件压缩到test.zip文件中
File file = new File("c:/code");
// 所有java文件的集合
File[] files = file.listFiles(new FileFilter() {
@Override
public boolean accept(File fileName) {
if (fileName.isFile() && fileName.getName().endsWith(".java")) {
return true;
}
return false;
}
});
FileInputStream fis = null;
ZipOutputStream zout = new ZipOutputStream(new FileOutputStream("c:/code/test.zip"));
for (File f : files) {
ZipEntry ze = new ZipEntry(f.getName());
zout.putNextEntry(ze);
fis = new FileInputStream(f);
byte[] buf = new byte[1024];
int readLength ;
while (-1 != (readLength = fis.read(buf))) {
zout.write(buf, 0, readLength);
}
zout.closeEntry();
}
fis.close();
zout.close();ZIP流是一个能够展示流的抽象化的强大之处的实例。当我们读入以压缩格式存储的数据时,不必操心边请求边解压数据。而且ZIP格式的字节源并非必须是文件,也可以是来自网络连接的ZIP数据。
5. 对象流与序列化
当需要存储相同类型的数据时,使用固定长度的记录格式是一个不错的选择。但是,在面向对象程序中创建的对象很少全部都具有相同的类型。例如,一个staff的数组,它名义上是一个Employee记录数组,但实际上却包含诸如Manager这样的子类实例。
Java提供了一种非常通用的机制称为对象序列化(Object Serialization),它可以将任何对象写入到流中,并在之后将其读回。但是在对象流中存储或恢复的所有类都必须实现Serializable接口。
为了保存对象数据,需要开启一个ObjectOutputStream对象:
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.dat"));
Employee harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
Manager carl = new Manager("Carl Cracker", 80000, 1987, 12, 15);
out.writeObject(harry);
out.writeObject(carl);为了读回这些对象数据,需要打开一个ObjectInputStream对象,然后用readObject方法以这些对象被写出时顺序来获得它们:
ObjectInputStream in = new ObjectInputStream(new FileInputStream("employee.dat"));
Employee harry_r = (Employee) in.readObject();
Manager carl_r = (Manager) in.readObject();
5.1 理解对象序列化的文件格式
一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记。有了这个标记的Class就能被序列化机制处理。
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class TestSerial implements Serializable {
private static final long serialVersionUID = 1L;
public byte version = 100;
public byte count = 0;
public static void main(String[] args) throws Exception {
FileOutputStream fos = new FileOutputStream("c:/code/temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
TestSerial ts = new TestSerial();
oos.writeObject(ts);
oos.flush();
oos.close();
}
}如果要从持久的文件中读取Bytes重建对象,我们可以使用ObjectInputStream。
FileInputStream fis = new FileInputStream("c:/code/temp.out");
ObjectInputStream oin = new ObjectInputStream(fis);
TestSerial ts = (TestSerial) oin.readObject();
System.out.println("version=" + ts.version);
fis.close();
oin.close();执行结果为:
version=100将一个对象序列化后是什么样子呢?打开刚才我们将对象序列化输出的temp.out文件,以16进制方式显示。内容应该如下:
0000000: aced 0005 7372 0027 636f 6d2e 6576 6f6c ....sr.'com.evol
0000010: 696e 652e 696f 2e73 6572 6961 6c69 7a61 ine.io.serializa
0000020: 7469 6f6e 2e54 6573 7453 6572 6961 6c3d tion.TestSerial=
0000030: ebe8 423b 0883 8702 0002 4200 0563 6f75 ..B;......B..cou
0000040: 6e74 4200 0776 6572 7369 6f6e 7870 0064 ntB..versionxp.d
0000050: 0d0a
这一坨字节就是用来描述序列化以后的TestSerial对象的,我们注意到TestSerial类中只有两个域:
public byte version = 100;
public byte count = 0;
且都是byte型,理论上存储这两个域只需要2个byte,但是实际上temp.out占据空间为80bytes,也就是说除了数据以外,还包括了对序列化对象的其他描述。
Java的序列化算法
序列化算法一般会按步骤做如下事情:
◆将对象实例相关的类元数据输出。
◆递归地输出类的超类描述直到不再有超类。
◆类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
◆从上至下递归输出实例的数据
我们用另一个更完整覆盖所有可能出现的情况的例子来说明:
class parent implements Serializable {
int parentVersion = 10;
}
class contain implements Serializable {
int containVersion = 11;
}
public class TestSerial2 extends parent implements Serializable {
int version = 66;
contain con = new contain();
public int getVersion() {
return version;
}
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
TestSerial2 st = new TestSerial2();
oos.writeObject(st);
oos.flush();
oos.close();
}
}这个例子是相当的直白啦。SerialTest类实现了Parent超类,内部还持有一个Container对象。
5.2 修改默认的序列化机制
在程序中某些数据域不应该被序列化,例如,只对本地访问有意义的存储文件句柄或窗口句柄的整数值,这种信息在稍后重新加载对象或将其传送到机器上时都是没有用处的。事实上,这种域的值如果不恰当还会引起本地方法崩溃。Java拥有一种很简单的机制来防止这种域被序列化,那就是将它们标记成是transient的。如果这些域属于不可序列化的类,也需要将它们标记成transient的。瞬时的域在对象被序列化时总是被跳过的。
序列化机制为单个的类提供了一种方法,去向默认的读写写为添加验证或任何其他想要的行为。
private void writeObject(java.io.ObjectOutputStream out) throws IOException
private void readObject(java.io.ObjectInputStream in) throws IOException;此时的数据域就不再会被自动序列化,而是调用这些方法。
示例1:在java.awt.geom包中有大量的类都是不可序列化的,例如Point2D.Double。现在假设你想要序列化一个LabeledPoint类,它存储了一个String和一个Point2D.Double。首先,需要将Point2D.Double标记成transient,以避免抛出NotSerializableException。
public class LabeledPoint implements Serializable
{
// ...
private String label;
private transient Point2D.Double point;
}在writeObject方法中,首先通过调用defaultWriteObject方法写出对象描述符和String域及其状态,(defaultWriteObject源码)这是ObjectOutputStream类中的一个特殊方法,它只能在可序列化类的writeObject方法中被调用。
在writeObject方法中,首先通过调用defaultWriteObject方法写出对象描述符和String域及其状态,(defaultWriteObject源码)这是ObjectOutputStream类中的一个特殊方法,它只能在可序列化类的writeObject方法中被调用。
/**
* Write the non-static and non-transient fields of the current class to
* this stream.
*/
public void defaultWriteObject() throws IOException {
if (curContext == null) {
throw new NotActiveException("not in call to writeObject");
}
Object curObj = curContext.getObj();
ObjectStreamClass curDesc = curContext.getDesc();
bout.setBlockDataMode(false);
defaultWriteFields(curObj, curDesc);
bout.setBlockDataMode(true);
}使用标准的DataOutput调用写出点的坐标:
private void writeObject(ObjectOutputStream out) throws IOException{
out.defaultWriteObject();
out.writeDoble(point.getX());
out.writeDoble(point.getY());
}
private void readObject(ObjectInputStream in) throws IOException{
out.defaultReadObject();
double x = in.readDouble();
double y = in.readDouble();
point = new Point2D.Double(x,y);
}示例2:java.util.Date类,它提供了自己的readObject和writeObject方法,这些方法将日期写出为从纪元(UTC时间1970年1月1日0点)开始的毫秒数。Date类有一个复杂的内部表示,为了便于查询,它存储了一个Calendar对象和一个毫秒计数值。Calendar状态时冗余的,因此不需要保存。readObject和writeObject方法只需要保存和加载它们的数据域,而不需要关心超类数据和任何其他类的信息。除了让序列化机制来保存和恢复对象数据,类还可以定义自己的机制。为了做到这一点,这个类必须要实现Externalizable接口,这需要它定义两个方法:
package java.io;
import java.io.ObjectOutput;
import java.io.ObjectInput;
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out)
throws IOException
void readExternal(ObjectInput in)
throws IOException, ClassNotFoundException
}与readObject和writeObject不同,这些方法对包括超类数据在内的整个对象的存储和恢复负全责,而序列化机制在流中仅仅只是记录该对象所属的类。在读入可外部化的类时,对象流将用默认的构造器创建一个对象,然后调用readExternal方法。下面是Employee类实现这些方法:
@Override
public void writeExternal(ObjectOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(name);
out.writeDouble(salary);
out.writeLong(hireDay.getTime());
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
// TODO Auto-generated method stub
name = in.readUTF();
salary = in.readDouble();
hireDay = new Date(in.readLong());
}注意:readObject和writeObject方法是私有的,并且只能被序列化机制调用。与此不同的是,readExternal和writeExternal方法是公共的。特别是,readExternal还潜在地允许修改现有对象的状态。
5.3 为克隆使用序列化
序列化机制还有一种有趣的用法:它提供了一种克隆对象的渐变途径,只要对应的类是可序列化的即可。其做法很简单:直接将对象序列化到输出流中,然后将其读回。这样产生的新对象是对现有对象的一个深拷贝(deep copy)。在此过程中,我们不必将对象写出到文件中,因为可以用ByteArrayOutputStream将数据保存到字节数组中。
要想得到clone,只需扩展SerialCloneable类即可。但是它通常会比显式地构建新对象并复制或克隆数据域的克隆方法慢得多。
import java.io.*;
import java.util.*;
public class SerialCloneTest {
public static void main(String[] args) {
Employee harry = new Employee("Harry Hacker", 35000, 1989, 10, 1);
// clone harry
Employee harry2 = (Employee) harry.clone();
// mutate harry
harry.raiseSalary(10);
// now harry and the clone are different
System.out.println(harry);
System.out.println(harry2);
}
}
/**
* A class whose clone method uses serialization.
*/
class SerialCloneable implements Cloneable, Serializable {
public Object clone() {
try {
// save the object to a byte array
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bout);
out.writeObject(this);
out.close();
// read a clone of the object from the byte array
ByteArrayInputStream bin = new ByteArrayInputStream(
bout.toByteArray());
ObjectInputStream in = new ObjectInputStream(bin);
Object ret = in.readObject();
in.close();
return ret;
} catch (Exception e) {
return null;
}
}
}
/**
* The familiar Employee class, redefined to extend the SerialCloneable class.
*/
class Employee extends SerialCloneable {
public Employee(String n, double s, int year, int month, int day) {
name = n;
salary = s;
GregorianCalendar calendar = new GregorianCalendar(year, month - 1, day);
hireDay = calendar.getTime();
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public Date getHireDay() {
return hireDay;
}
public void raiseSalary(double byPercent) {
double raise = salary * byPercent / 100;
salary += raise;
}
public String toString() {
return getClass().getName() + "[name=" + name + ",salary=" + salary
+ ",hireDay=" + hireDay + "]";
}
private String name;
private double salary;
private Date hireDay;
}
------- android培训、java培训、期待与您交流! ----------
最后
以上就是尊敬悟空最近收集整理的关于黑马程序员——Java IO流Java IO流的全部内容,更多相关黑马程序员——Java内容请搜索靠谱客的其他文章。








发表评论 取消回复