
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
大家好,我叫王磊,来自于字节跳动 Web Infra,今天由我给大家分享《字节跳动基于 Serverless 的前端研发模式升级》。

接下来将从以下 6 个方面介绍今天的内容,首先总结一下大前端时代下前端的职责和挑战。然后介绍字节跳动常见的业务形态,以及字节跳动传统的研发模式和挑战。之后介绍我们是如何基于 Serverless 对前端的研发模式进行升级的。为了保证稳定性,我们在监控运维方面也做了不少工作。最后简单做一下总结和展望。

首先让我们看下大前端时代下前端的职责和挑战,随着前端的演进,前端的职责在不断的变化。

PC 时代,我们的工作主要在于切图、写样式、写交互、兼容各种浏览器等,此外还会做一些组件化、前后端分离的事情,总体而言还是专注于浏览器领域。

随着移动设备的兴起,我们进入了移动互联网时代,整体工作分为跨端和工程 2 个方面。跨端主要做一些移动端 Web(H5)、React Native、Flutter 等工作;工程主要基于 Node 做一些方案。总体来看,这个阶段我们已经跨出了浏览器,迈向了 Android、iOS 和前端工程。

当下进入到 Serverless 时代,前端的工作变得更加丰富,包含 CSR、SSR、BFF、微前端等开发工作,从单端到多端,从 Client 端到服务器端,涉及的领域变得非常广,对前端要求变得更高,整体上是向着“前端全栈化”的方向发展。

在这种职责转变下,看下我们面临了哪些挑战。
可以从 2 个角度来看,一个是知识体系,一个是工作内容。
在知识体系上,除了传统前端知识 JS、CSS、Node,前端框架 React、Vue、打包工具 Webpack、Vite,微前端,跨端工程等。还会涉及后端领域,框架有大家熟悉的 Koa、Express;知识包含 Redis、消息中间件、文件存储、监控报警等。
从工作内容上来看,也分为 2 块,一块是偏向前端的工作,一块是偏向后端的工作。偏向前端的工作有 写组件、写页面、兼容、性能优化、跨端工程等;偏向后端的工作有写 BFF、写 SSR、监控运维、集群管理等。
整体上来看,前端向着全栈化的方向发展,涉及大量后端的知识和工作,对前端的挑战非常大。

在介绍完大前端时代下前端的职责和挑战后,让我们看下字节跳动有哪些常见的业务形态。
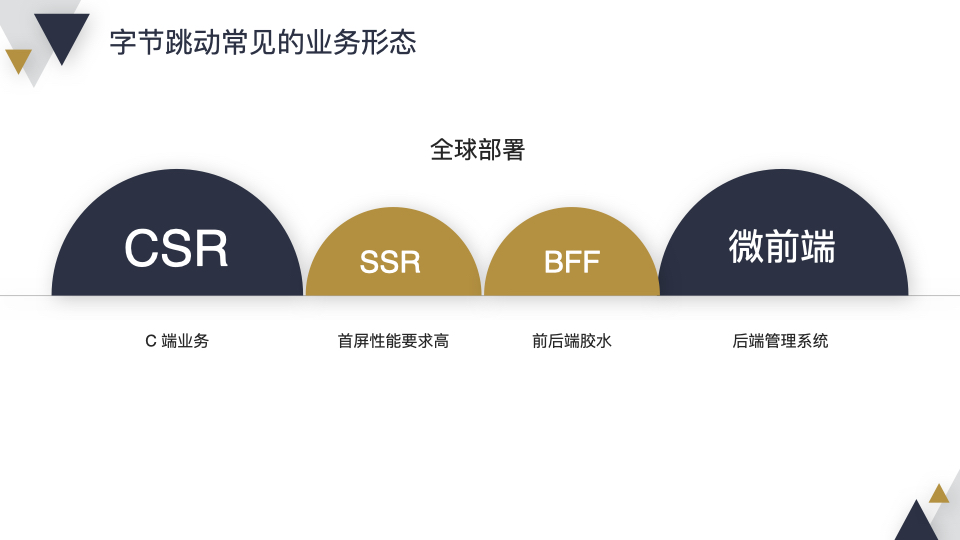
字节跳动常见的业务形态抽象成前端领域可以分为 4 个部分,其中 CSR 和微前端占大部分,CSR 是一些 C 端业务,微前端是一些中后台管理系统。此外还包含一些 SSR 页面和 BFF,SSR 是为了提升性能,解决首屏问题。BFF 主要解决前端 UI 模型和后端数据模型存在 Gap 的问题,主要写一些胶水代码。此外值得注意的是,字节跳动作为一家全球化的互联网公司,业务可能会部署到全球各地。

介绍完字节跳动常见的业务形态后,让我们看看字节跳动传统的研发模式以及遇到的问题。

拿一个包含 CSR + BFF 的项目举个例子。
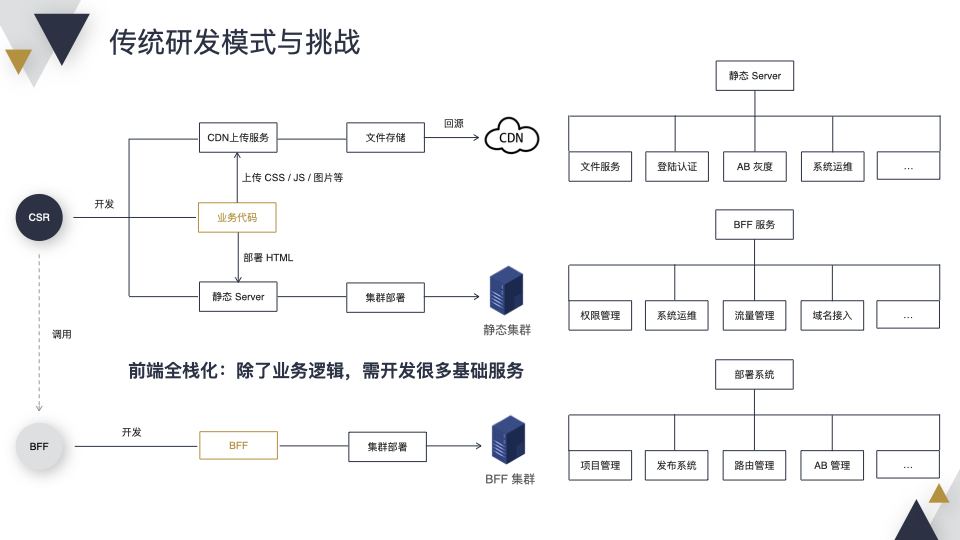
从 CSR 讲起,针对一个 CSR 页面,我们除了开发业务,生成 CSS、JS、图片等静态资源和 HTML 之外,想要把页面部署到线上稳定运行,还需要开发很多基础服务。
比如需要开发一个 CDN 上传服务,将静态资源上传到 CDN 上。此外还需要开发一个静态 Server 托管 HTML,静态 Server 可能包含文件服务、登陆认证、AB 灰度等功能。开发完毕后还不够,我们还需要申请机器和域名,把项目部署到集群里面,CSR 页面才能运行起来。
想使用 BFF,需要开发一个 BFF 服务,这个服务可能包含权限管理、系统运维、域名接入等各种功能。同样需要申请机器和域名,把项目部署到集群里面。
为了方便业务能够稳定上线,还需要开发一个部署系统,这个系统可能会包含 项目管理、发布系统、路由管理、AB 管理等功能。
从工作内容上来看,针对一个简单的 CSR + BFF 业务,除了关心黄色方框中和业务相关的内容,还需要开发各种基础服务,对于前端同学实在太难了。
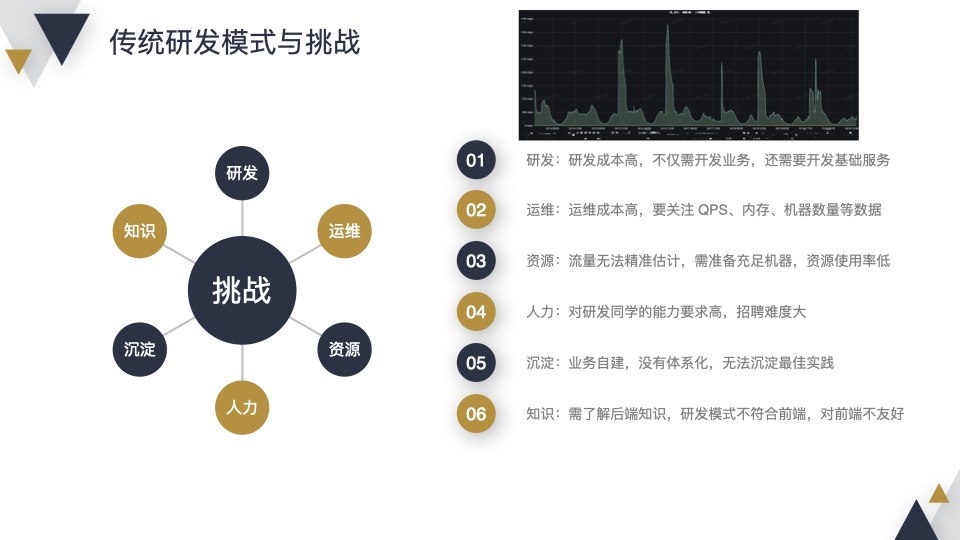
这种研发模式有什么问题呢?总结为以下 6 点:
第一:研发成本高,不仅需开发业务,还需要开发基础服务;
第二:运维成本高,需要关注 QPS、内存和机器数量等指标;
第三:流量无法精准估计的情况下,需要准备充足的机器,资源使用率低,举一个线上真实的案例,从图中可以看出流量有明显的波动,需要准备比流量高峰还要多的机器,低峰时机器不能很好的被利用;
第四:从人力上来看,对研发同学的能力要求会更高,由于招聘本身就很难,这样会进一步加大招聘的难度;
第五:由于各种基础服务都是业务自己建设,很难像工程团队那样进行体系化建设,无法沉淀最佳实践;
第六:这种研发模式不符合前端习惯,需要了解很多后端知识,对前端其实是非常不友好的。

为了解决这些问题,我们基于 Serverless 来对前端的研发模式进行了一次升级。

接下来将从以下 3 个方面去介绍,首先讲一下策略和架构。
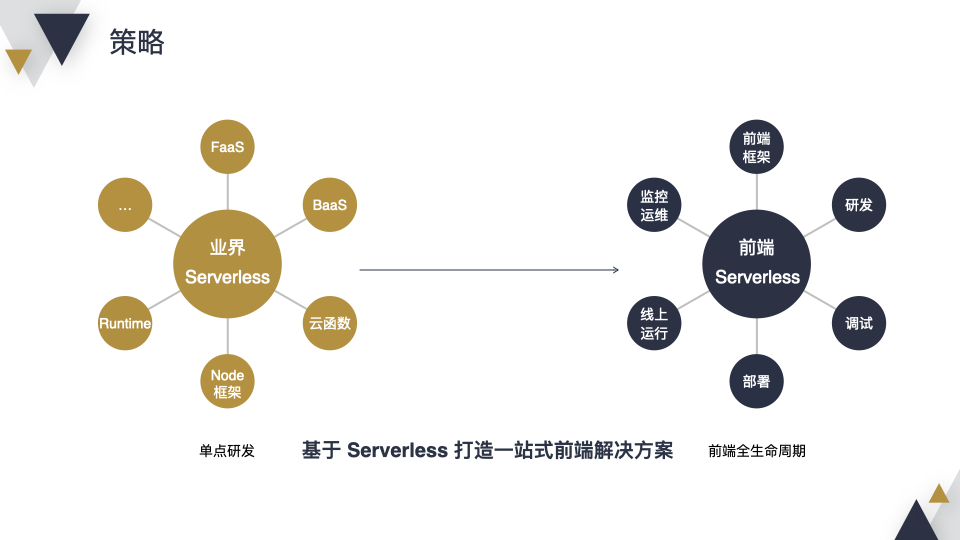
在介绍我们的策略之前,先看下业界前辈们在 Serverless 方面做了哪些工作:首先是基础 FaaS 的建设,比如调度、冷启动等;然后是将现有 BaaS 服务和 FaaS 结合在一起,打造更好的生态;此外还有云函数、Node 框架、Runtime 等。综上所诉,可以发现前辈们主要还是在解决 Serverless 下的一些单点问题。
在这些单点研究的基础上,我们的目标是围绕着前端的整个生命周期,构造前端 Serverless ,包含前端框架、研发流程、调试、部署、线上运行、监控运维等各个环节。用一句话来总结的话:基于 Serverless 打造一站式前端解决方案。

基于 Serverless 打造一站式前端解决方案有 2 个目标。
第一:基础能力平台化,业务再也不需要关注前端基础服务的开发,平台提供,开箱即用,简单配置即可;
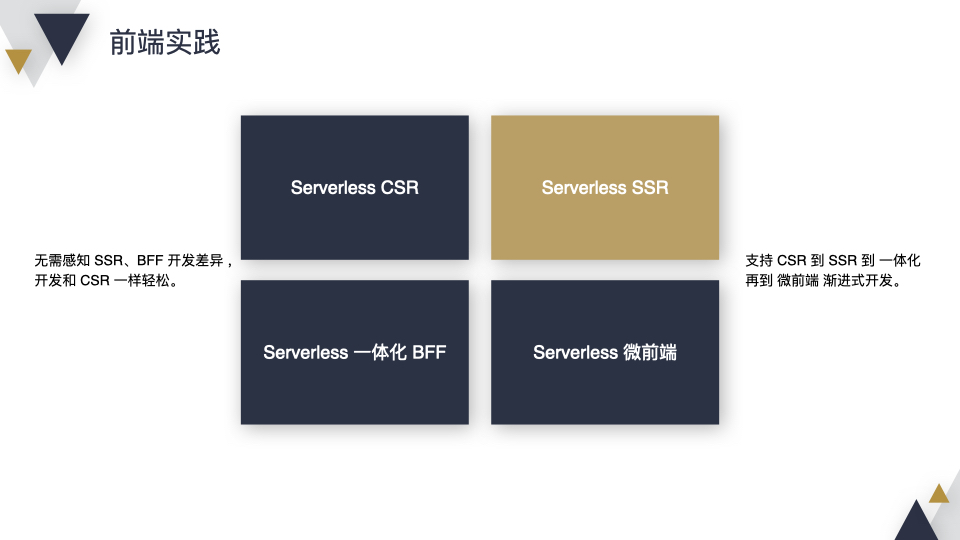
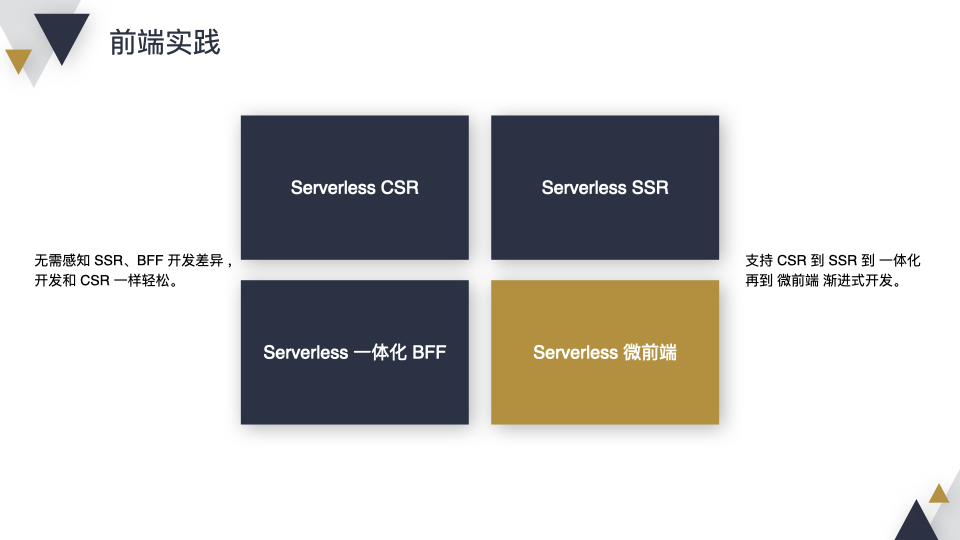
第二:友好的开发体验,用户在开发 SSR 和 BFF 的过程中无需感知到差异性,和开发 CSR 一样轻松;此外支持 CSR 到 SSR、SSR 到 一体化 BFF、一体化 BFF 到微前端的渐进式开发。
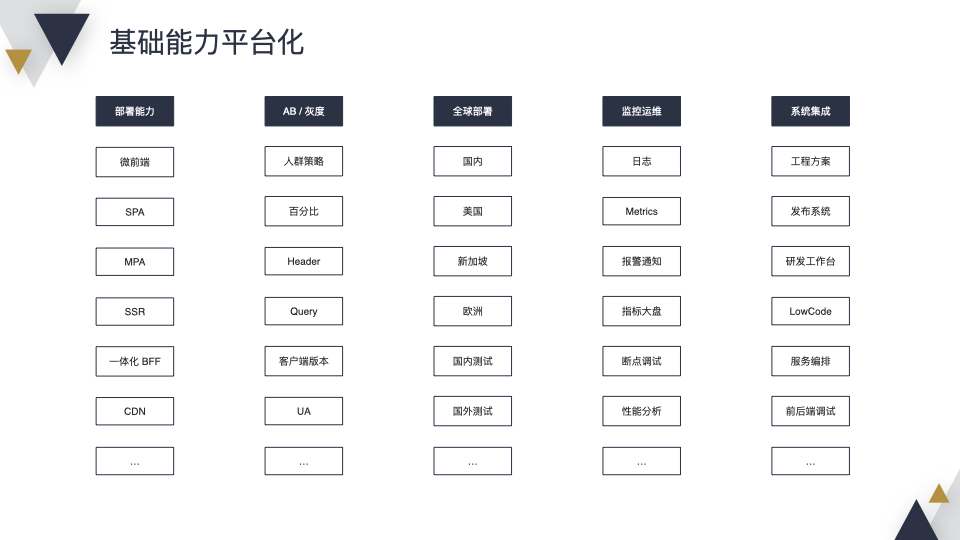
首先介绍一下基础能力平台化,基础能力包含 5 个方面的内容。第一部署能力,支持微前端、SPA、MPA、SSR、一体化 BFF 、CDN 的部署。第二 提供 AB/灰度能力,帮助前端进行上线前的验证和检测,帮助业务进行产品上的实验,这里有人群、百分比、客户端版本等策略。由于字节跳动是一家全球化的互联性公司,我们的业务需要支持全球化部署,比如国内、美国、新加坡等。出于稳定性的考虑,我们需要拥有完善的监控运维系统,包含日志、Metrics 打点、报警通知、指标大盘等。在前 4 个能力的基础上,为了提供更好的用户体验,需要和公司内部各个系统进行集成,比如工程方案、发布系统、一站式研发工作台等。
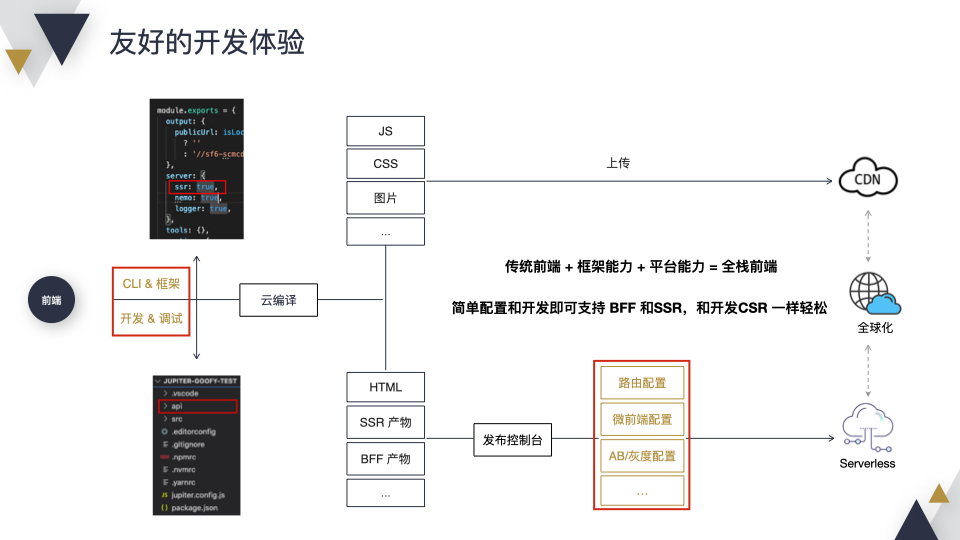
接下来介绍一下用户体验,想要支持 SSR 和 BFF,只需要简单配置和开发即可,在开发上和 CSR 没啥区别。比如用户想要支持 SSR,只需要开启一个配置;想要支持 BFF,添加一个 API 目录,写一写就行了。然后经过云编译,静态资源会自动上传到 CDN。HTML、SSR 、BFF 等产物经过发布控制台,简单配置一下即可上线。从研发流程来看,用户只需要关注红框框中的部分。用一句话来总结,我们希望传统前端 + 框架能力 + 平台能力 = 全栈前端。
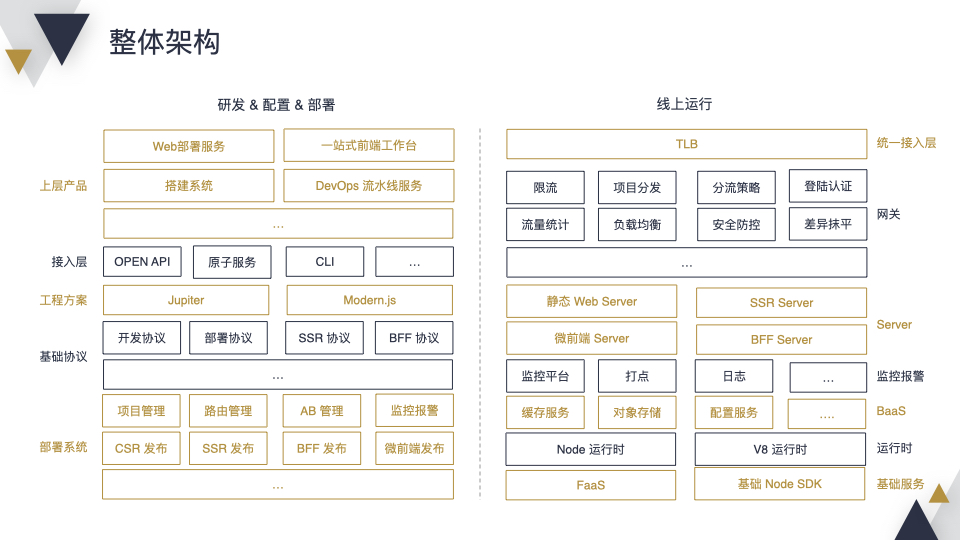
为了实现这些目标,我们需要做很多工作,具体分为 2 部分:“研发 & 配置 & 部署”和“线上运行”。
先说第一个,左边部分,从下到上来介绍。最底层提供了一个部署系统,包含项目管理、路由管理、AB管理、监控报警等功能,支持 CSR、SSR、BFF 和微前端的发布。在上层我们有各种协议,比如开发协议、部署协议、SSR 协议、BFF 协议。在协议的基础上我们对接了公司内部的工程方案,比如 Jupiter 和 Modern.js。为了和公司内部各个系统更好的结合,我们抽象了接入层,里面提供 OPEN API、服务编排的原子服务、CLI 等。最后基于接入层打造上层产品,比如 Web 部署服务、一站式前端工作台、搭建系统或 DevOps 流水线服务等。
接下来让我们介绍一下线上运行部分,这个我们从上到下进行介绍。当发起一个 HTTP 请求,首先会经过 统一接入层 到达我们的网关,这里我们会做限流、项目分发、AB 分流等相关的工作。经过网关会到底层各个服务,比如 静态 Web Server、SSR Server、BFF Server、微前端 Server 等。为了保障稳定性,我们提供了完备的监控报警,比如日志、打点等。下面是各种 BaaS 服务和 运行时,比如 Node 运行时,V8 运行时。最后是 FaaS 和 Node 基础 SDK。

在介绍完策略和架构之后,我们介绍一下 CI/CD,这块我也做了不少工作。

这是一个简单的例子,当我们开发完代码后,首先会进行编译,之后经过一个代码检查,看看是否会有一些代码问题,比如是否符合 Lint,或者含有安全漏洞等。
接下来通过 “线下、AB 或者灰度进行测试”,测试完毕之后需要经过一个人工卡点,确定没问题,会进行一些线上检查,比如 Lighthouse 的性能检查,这里也会有一个人工卡点。当确定没问题,就会把项目部署上线。
由于这个是一个服务编排,用户可以按照自己的诉求进行个性化定制。

讲了这么多,可能会比较抽象,接下来举一些实际的例子来说明。
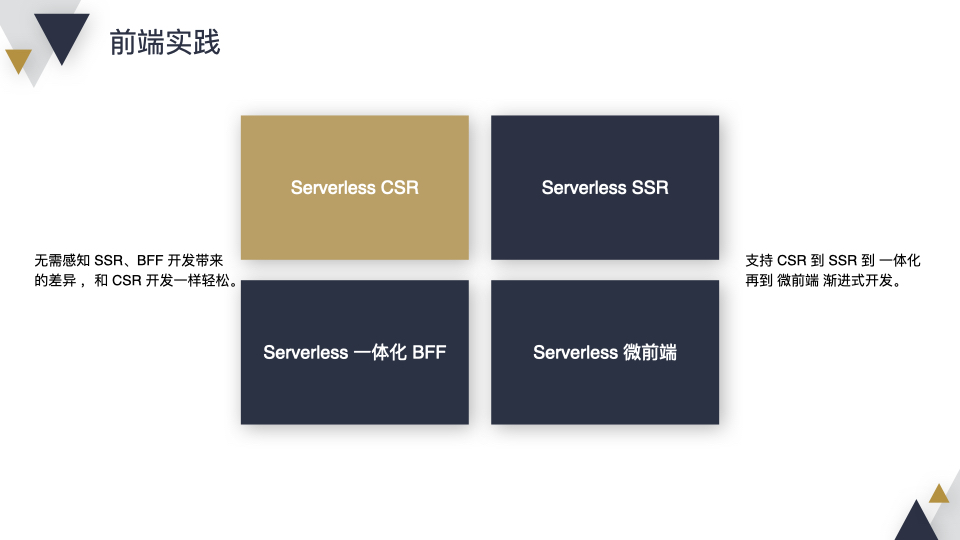
会从 CSR、SSR、一体化 BFF、微前端 4 个方面来讲,这里会重点突出 2 点。第一,无需感知 SSR、BFF 开发带来的差异 ,和 CSR 开发一样轻松;第二,支持 CSR 到 SSR 到一体化 BFF 再到微前端的渐进式开发。
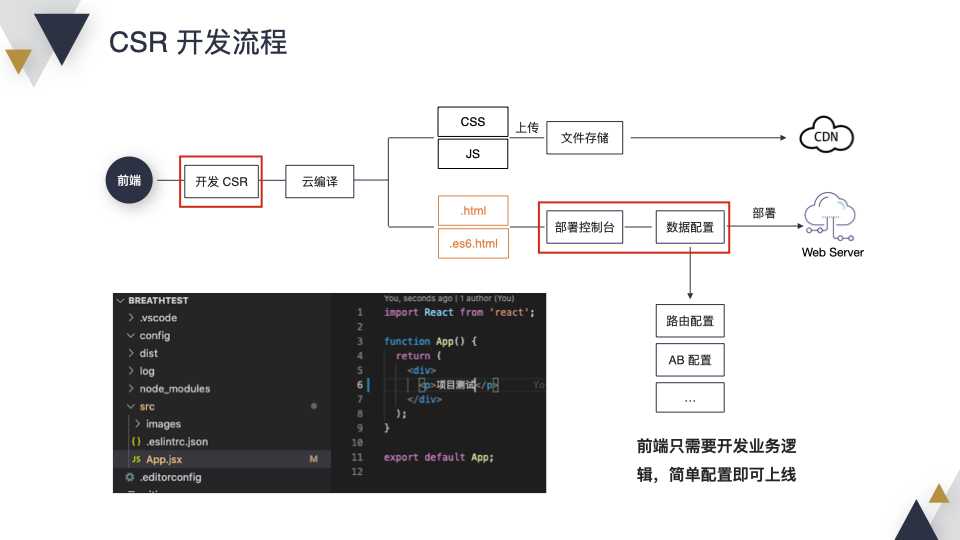
先从 CSR 开始,左下角是一个很简单的例子,前端开发完,经过云编译,生成 CSS、JS 等静态文件上传到 CDN;此外会生成 2 份 HTML,一份是 ES5 的,一份是 ES6 的,通过部署控制台,经过简单配置就可以把代码发布上线了,整个过程用户只关注开发和配置就可以了。
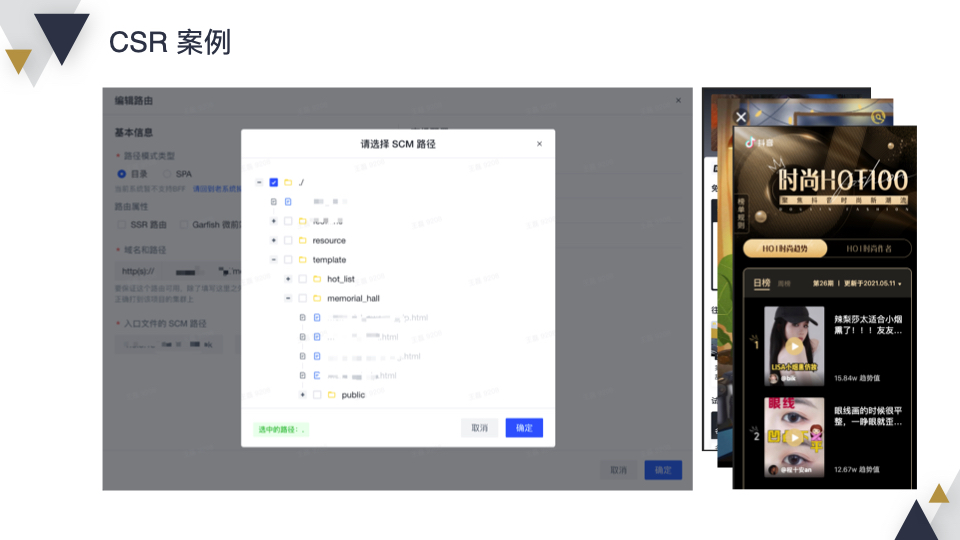
这是我们的一个案例,左边是我们的系统,上线前只需要配置域名,指定某个项目下某个文件就可以了,然后点击“确定”,发布一下,就会生效。CSR 的项目在我们的系统上有很多,比如 “懂车帝”、“西瓜活动页”、“抖音活动页”等。
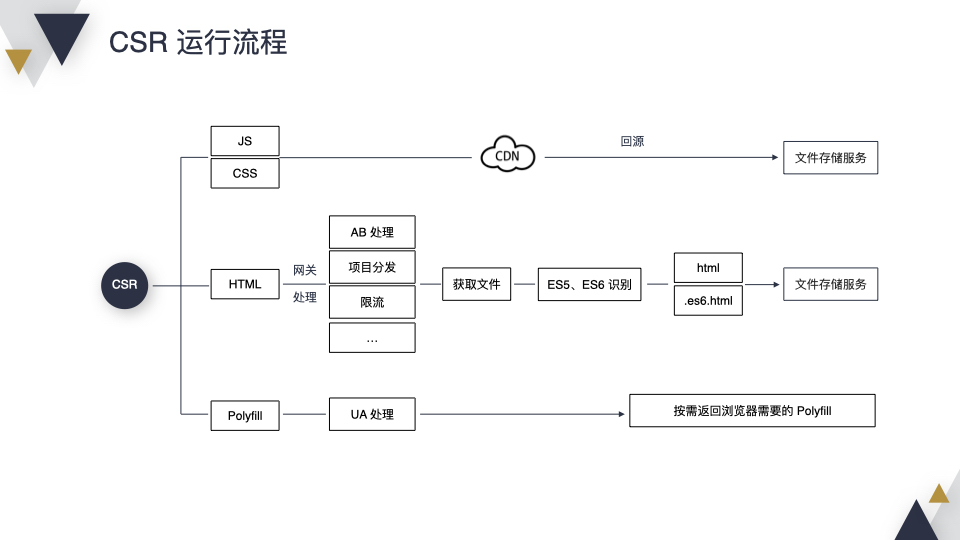
接下来介绍一下线上运行流程,分为 3 块。第一个是静态资源,直接访问 CDN 就可以了;第二个是 HTML,首先会进入到网关,进行 AB,项目分发,限流等处理,这时我们会知道访问的是哪个项目的哪个版本下的哪个文件,再经过 ES5、ES6 的识别,就可以访问到不同的 HTML 了。第三块有点特殊,浏览器的 Polyfill,我们这边提供了一个动态 Polyfill 服务,按需返回浏览器的 Polyfill,减少内容的大小,优化页面的性能。
CSR 介绍完了,让我们来看下 SSR。
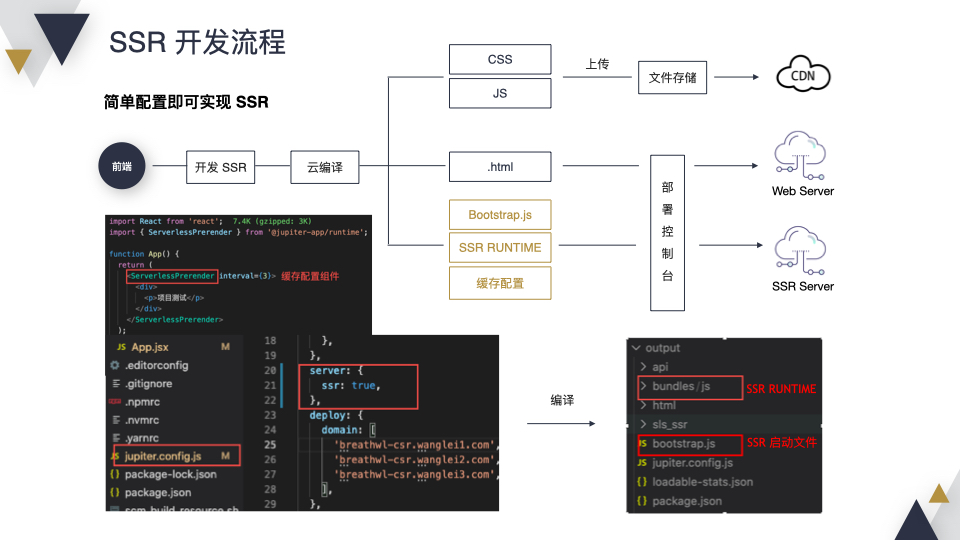
假设我们已经有了一个 CSR 项目,想要支持 SSR,我们只需要经过一个简单配置就可以了,把 Server SSR 设为 true,在编译的时候会生成 SSR Runtime 和启动文件。如果我们的项目不是一个千人千面的项目,可以接受缓存,我们还可以在代码添加一个缓存组件,这时在编译产物中会多一个缓存配置。此外相较于 CSR,SSR 的项目在部署后会多一个 SSR Server。
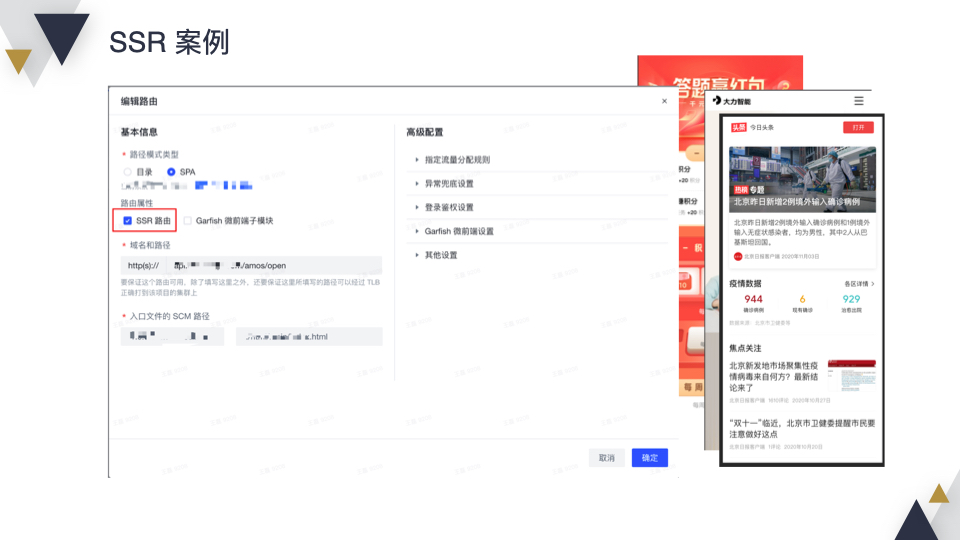
同样,我们看下上线前的配置,很简单,把路由标记成 SSR 就可以了。SSR 项目有“广告的答题赢红包”、“大力智能神灯”和“头条热榜”等业务。
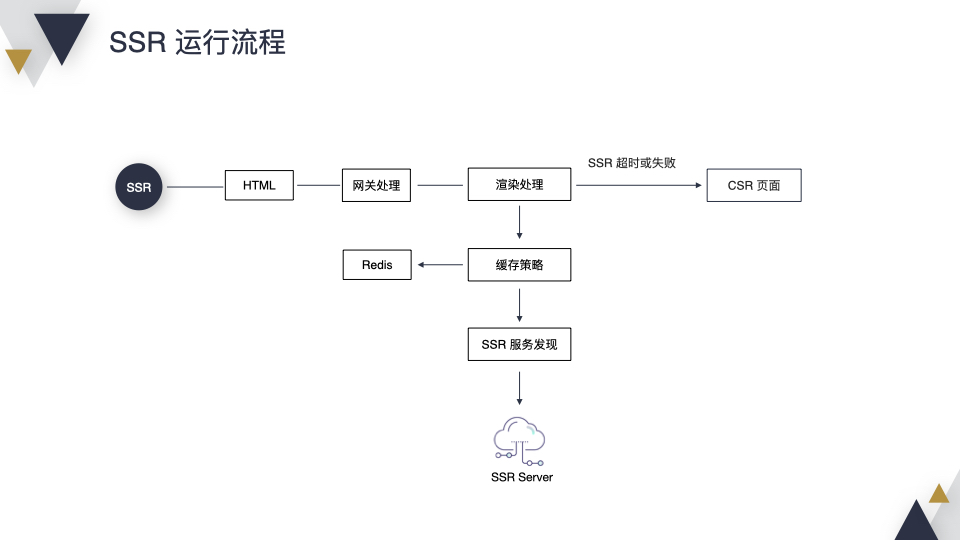
看下线上运行流程,访问 SSR,本质上是获取 HTML,请求会经过网关处理,到达“渲染处理”,这个时候看下缓存策略,如果可以缓存,看下 Redis 是否有缓存,有就直接返回,没有的话,通过服务发现访问 SSR Server。在异常或者超时的情况,会兜底到 Web Server 上获取 CSR 页面。
Ok,假设我们已经有了一个 SSR 项目,想支持 BFF,那么我们该怎么办呢?这就是我们接下来要介绍的一体化 BFF。
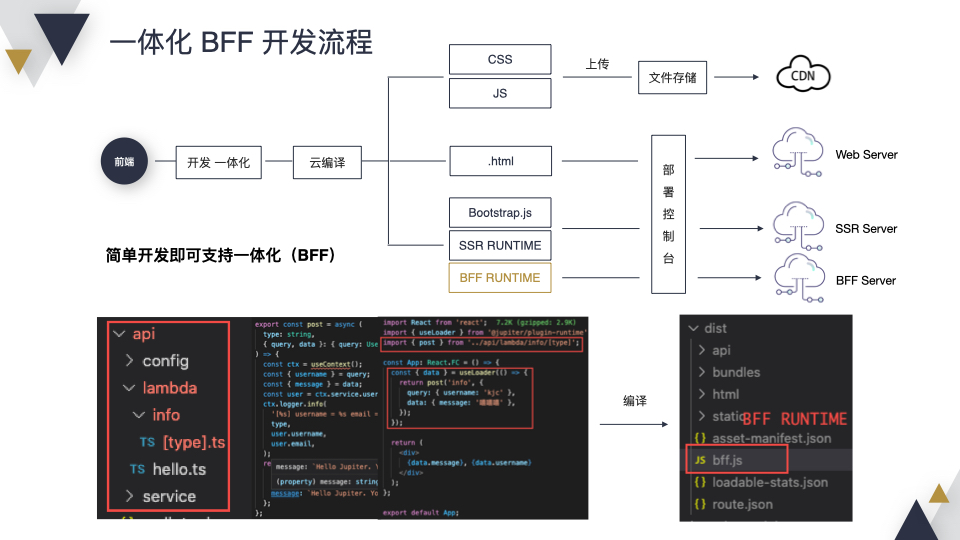
开发的时候,只需要在项目中添加一个 API 目录,把业务逻辑写好,使用的时候和前端开发一样,直接通过 import 将方法引入,调用就可以了。相较于 SSR,一体化项目在编译后会生成一个 BFF 的 Runtime,在部署后会多一个 BFF Server。
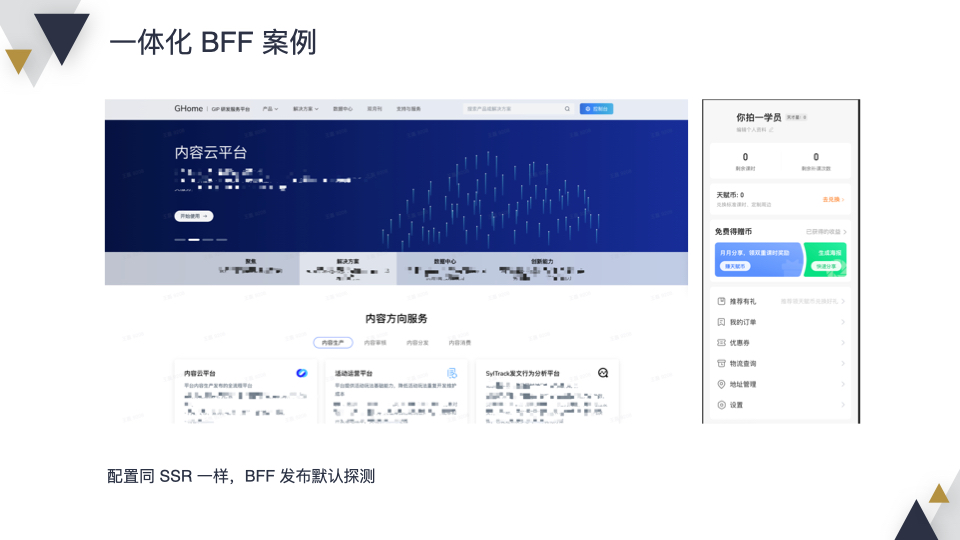
看一下例子,公司内部的一个“研发工作台”和我们的一个教育平台“你拍一”就是典型的案例。在配置上,前后端一体化项目和 SSR 是一样的,BFF Server 的发布是通过默认探测实现的。
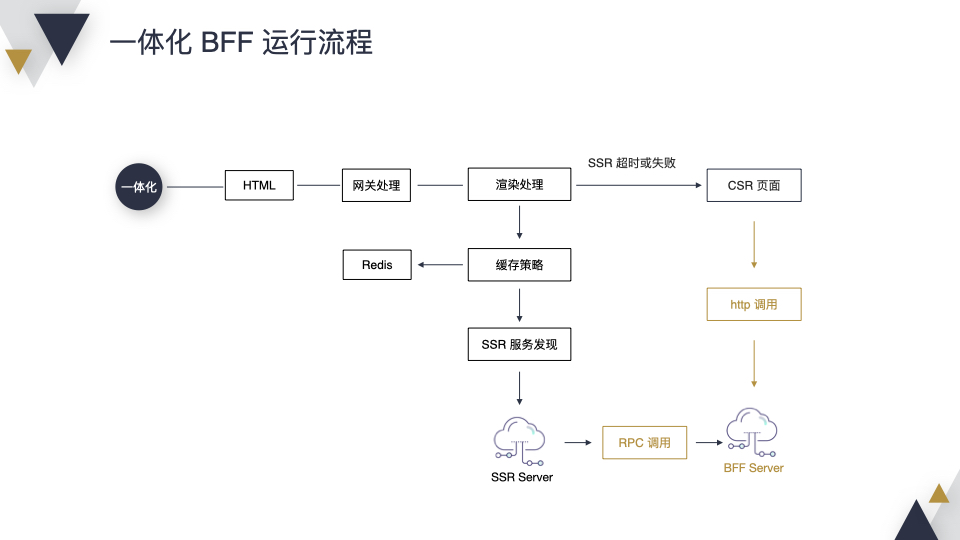
运行时,相较于 SSR,一体化 BFF 多了 一个 BFF Server,在 SSR 的时候,我们会通过 RPC 进行调用,在 CSR 的时候会通过 HTTP 方式进行调用。
介绍完了前面的 CSR、SSR 和一体化 BFF 项目,最后介绍一下微前端。

假设我们已经有了一些项目,开始只有 1 - 2 个同学维护,随着业务的不断发展,项目变得越来越复杂,需要 10 个乃至上百个同学、甚至跨团队开发,不同团队使用的技术体系可能还不一样。这样一个原本的小项目就变成了一个巨石应用,开发和维护的成本就变得非常高,那我们该怎么去解决现有问题?
微前端会是一种比较好的选择,我们团队提供了一套解决方案 —— Garfish,它解决了跨团队协作难、技术体系多样化、复杂度日益上升等问题。从架构层面出发可以将多个独立交付的前端应用组成一个整体,这些前端应用能够 “独立开发”、“独立测试”、“独立部署”,但在终端用户来看却是一个内聚的产品。目前 Garfish 已经开源了,大家有兴趣可以去了解一下 https://github.com/bytedance/garfish。
那么我们如何把现有项目,变成一个微前端呢?只需要开发一个主工程,注册子工程信息,在运行时交给框架即可。
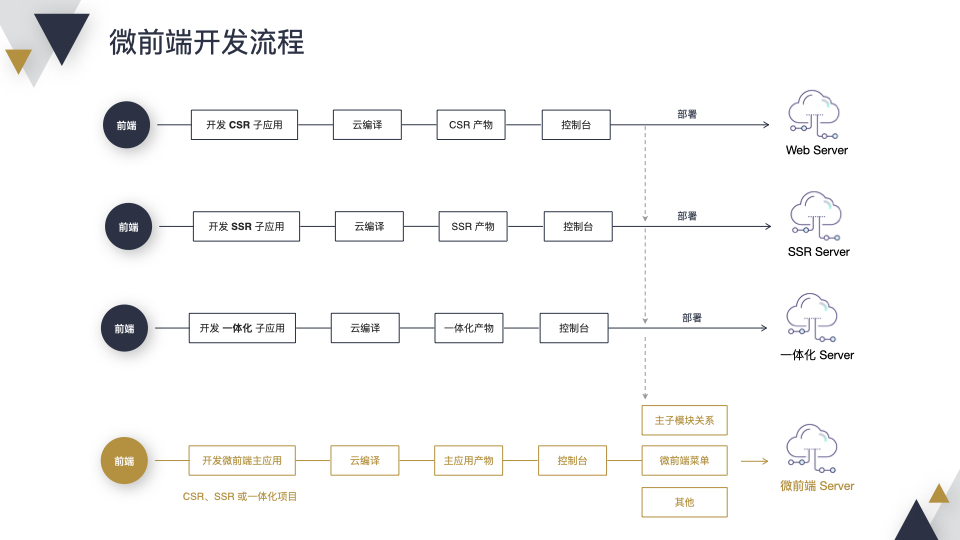
让我们看一下开发流程啊,由于是微前端,需要分为主工程和子工程,子工程可以是前面介绍的 CSR、SSR、一体化 BFF 项目的任何一种。主工程也可以是 CSR、SSR、一体化 BFF 项目的任何一种,开发流程和前面介绍的一样,唯一不同的是,在发布控制台需要配置“主子模块关系”和“微前端菜单”等。
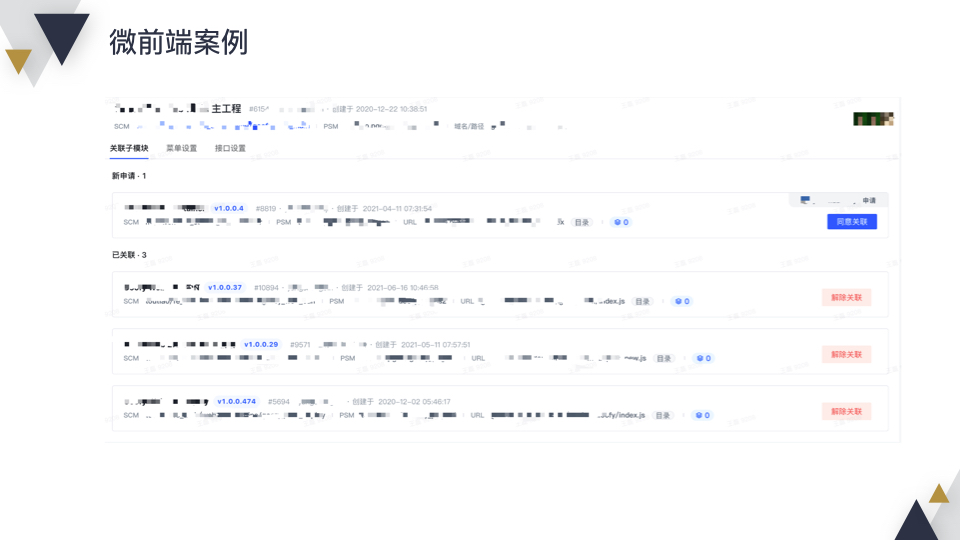
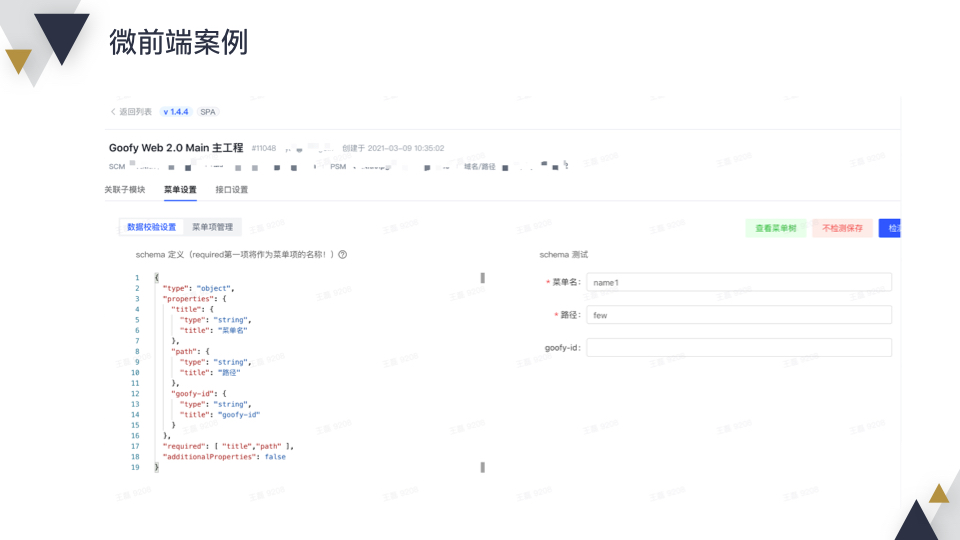
看下配置界面,这是一个主工程,下面挂载了 3 个子工程,然后可以配置主工程的菜单。
看一些正式的案例,比如幸福里的后台管理系统,我们公司的 toB 项目,火山引擎等。
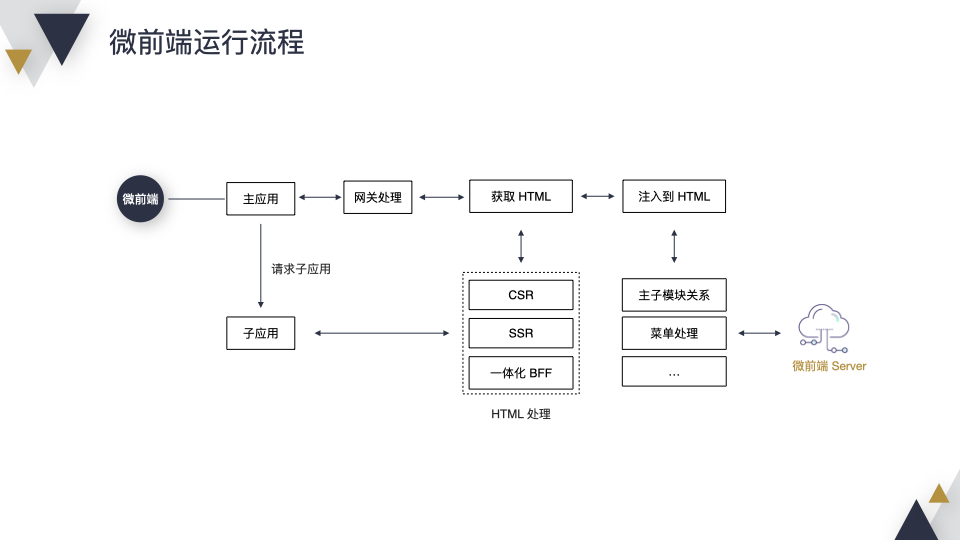
运行过程也比较简单,当请求进来的时候,先是主应用,进入网关处理,获取 HTML。与此同时请求微前端 Server 获取“主子模块关系”和菜单等,获取后注入到 HTML,避免在浏览器多发一次 HTTP 请求,优化一下性能。返回到浏览器后,判断当前需要访问哪个子应用,获取即可。

功能实现了,稳定性这块也是非常重要的,这块我们也做了很多的工作,主要在监控运维方面。

这块分为 3 个部分,第一部分是业务需要关注的,后面 2 个是我们系统维护者需要关注的。
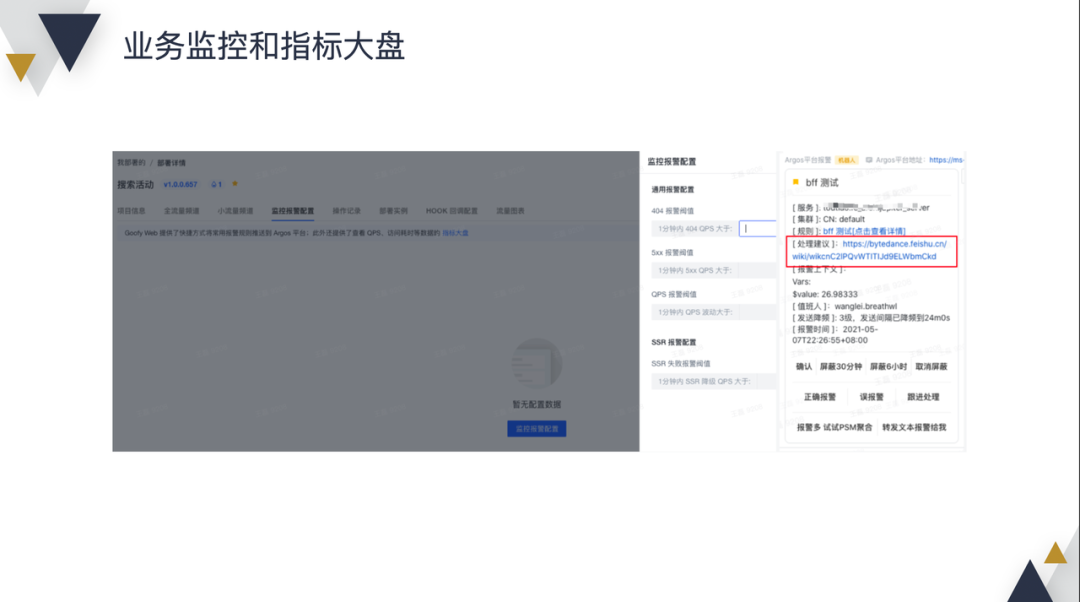
用户可以在系统内进行一些简单的配置,比如 404、5xx、SSR 降级的 QPS 阈值,超过阈值后就会在飞书(打个广告,飞书体验&功能超赞)上收到报警通知,并提供了文档,帮助用户排查问题。
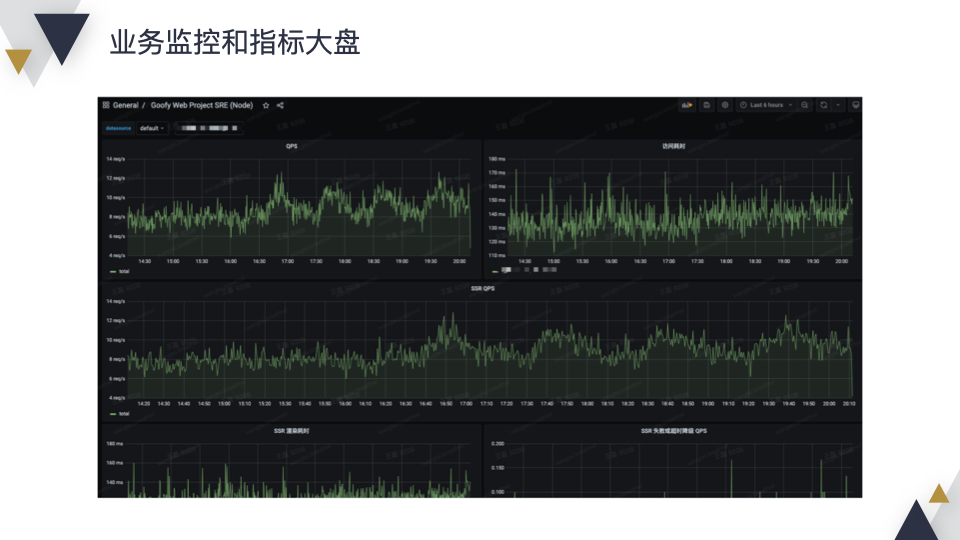
另外我们提供了一个业务指标大盘,这里可以看到项目的 QPS,访问耗时,SSR 渲染耗时等数据。

接下来介绍一下日志系统。
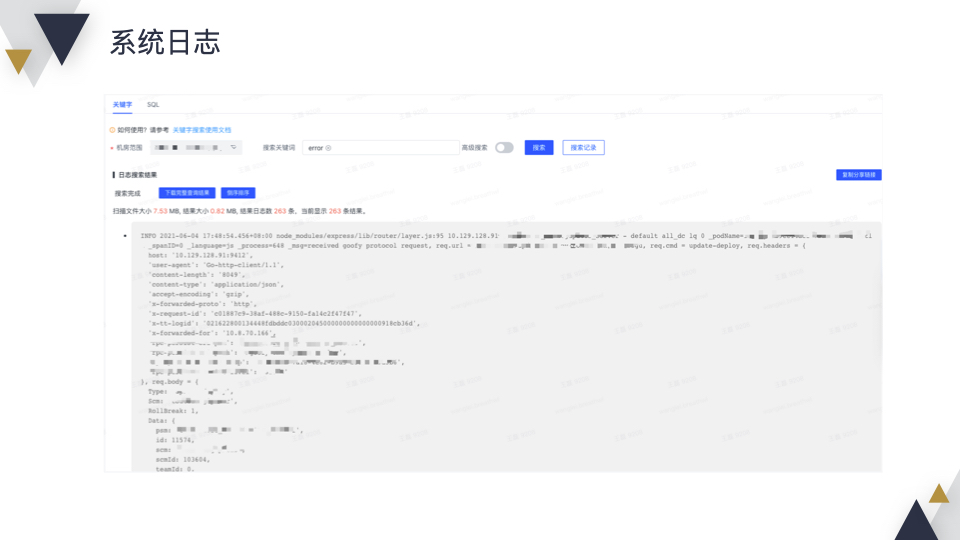
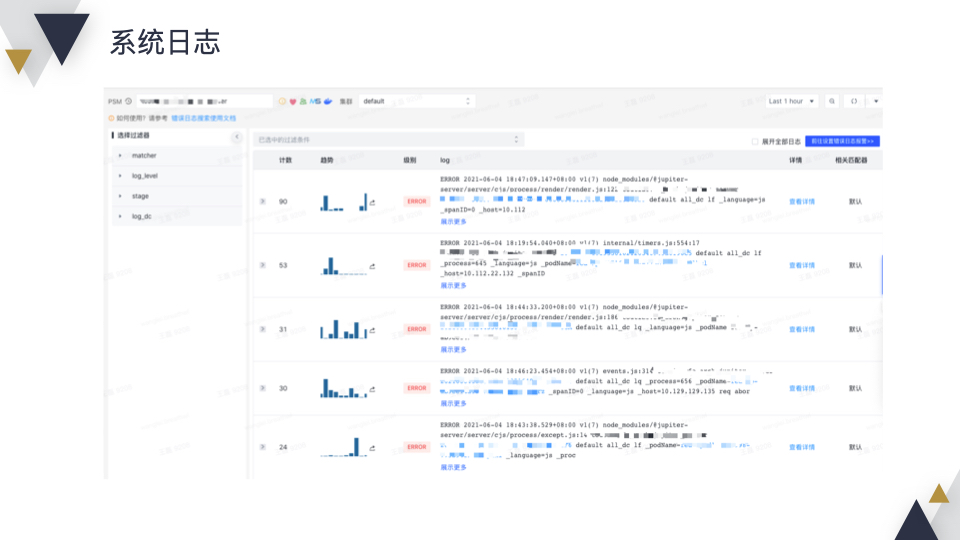
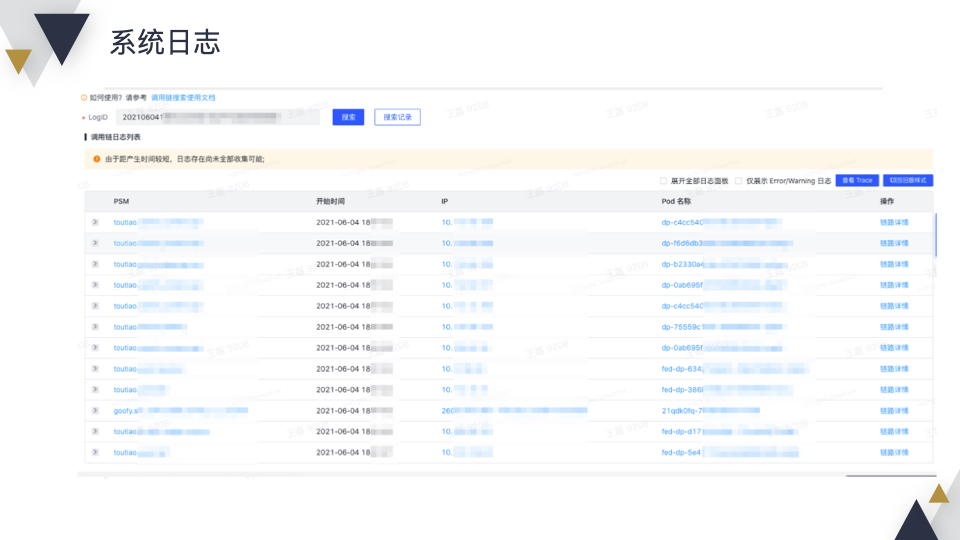
为了帮助排查问题,和公司内部的日志系统打通,可以通过关键字查询,对日志进行聚类分析,也可以调查某次调用过程中整条链路上的日志。

最后对于服务的运行时监控和调试,我们也做了不少工作。
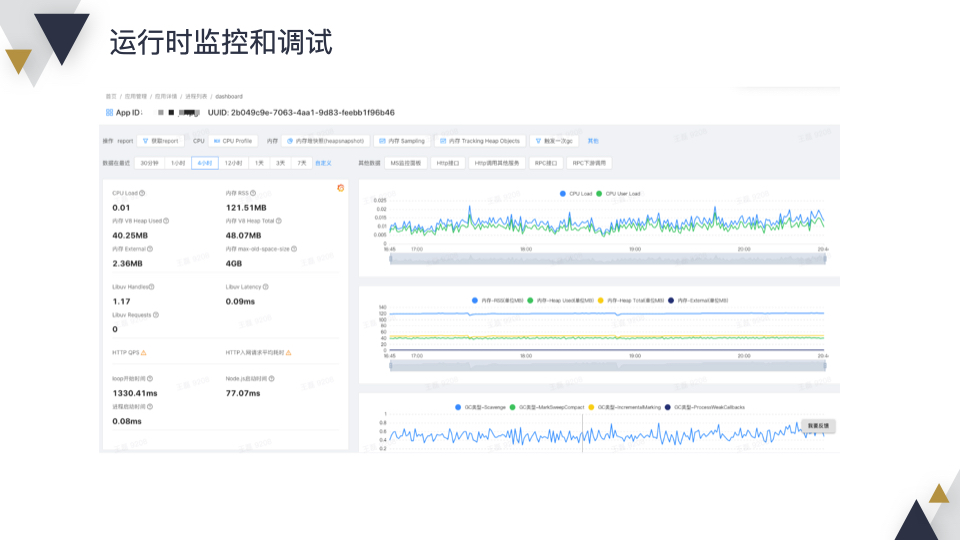
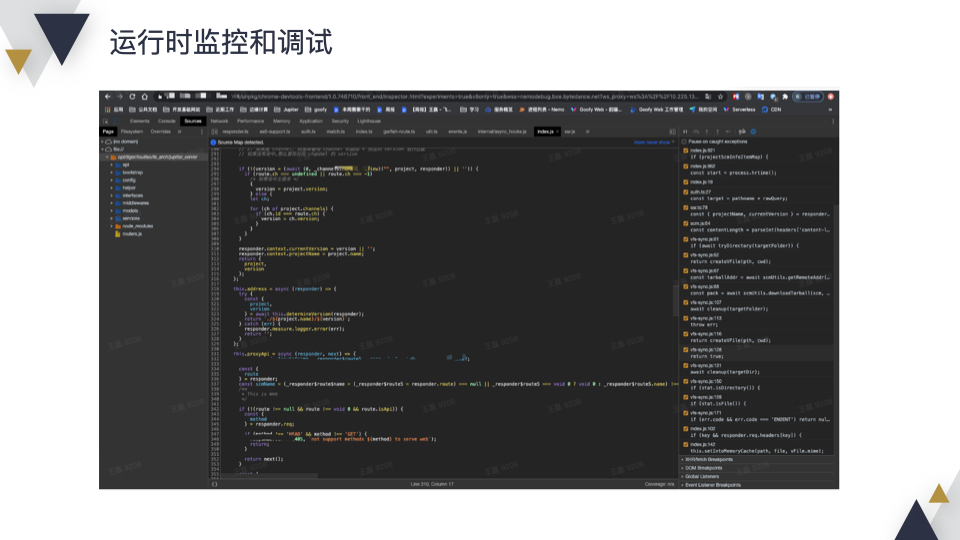
团队内做了一个类似 alinode 的产品,这里可以查看 Node 运行时的各种指标数据,比如内存、CPU、GC 情况等;此外如果通过日志排查问题比较困难,可以通过断点调试的方式进行调查;如果发现有内存泄漏或者性能问题,可以通过 Snapshot 或者 CPU Profile 进行分析。

最后做一个简单的总结和展望。

对于 Serverless 方向,个人觉得将来会朝着 3 个方向去发展,第一个是 Runtime 部分,这块主要解决 FaaS 冷启问题,更好应对突发流量问题;第二是 FaaS + BaaS,更好的完善 Serverless 的生态;第三是 Serverless+,在 FaaS + BasS 的基础上,构建各种从框架 - 开发 - 部署 - 线上运行的应用视角的一站式研发平台。

最后我们来做一个总结,今天主要介绍了我们字节跳动是如何基于 Serverless 进行前端研发模式升级的,希望这次分享能够对大家有所帮助,在自己的业务场景中遇到了类似的问题,有所启发。非常感谢。
如果觉得这篇文章还不错
点击下面卡片关注我
来个【分享、点赞、在看】三连支持一下吧

“分享、点赞、在看” 支持一波
最后
以上就是霸气小懒猪最近收集整理的关于GMTC 2021 演讲 《字节跳动基于 Serverless 的前端研发模式升级》的全部内容,更多相关GMTC内容请搜索靠谱客的其他文章。








发表评论 取消回复