语句之间存在延迟,编译器为了优化程序,尽量减少cpi,会对程序的执行顺序进行动态调整
比如下面这个程序
for (i = 999; i >= 0; i = i - 1)
x[i] = x[i] + s没有优化的时候执行是这样的:

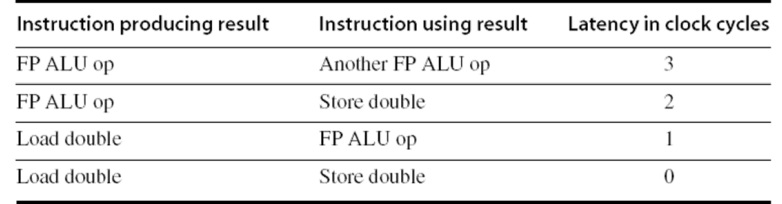
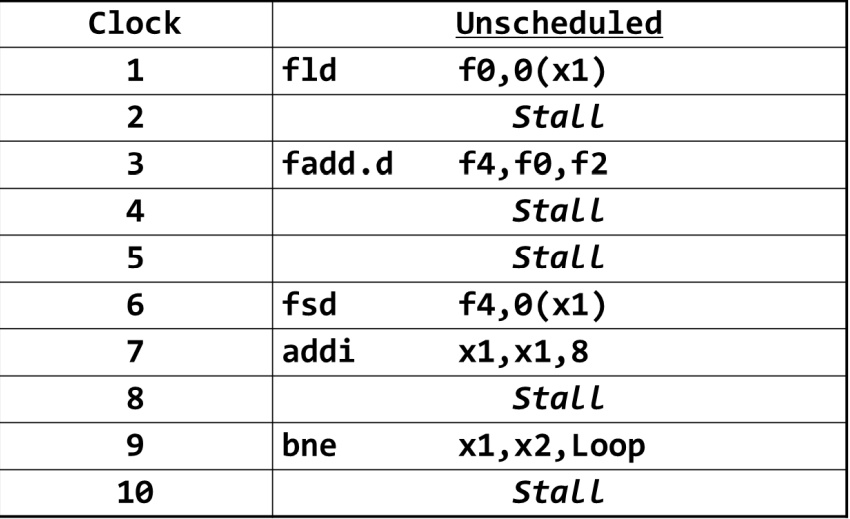
每个循环都需要10个clock,对其进行优化
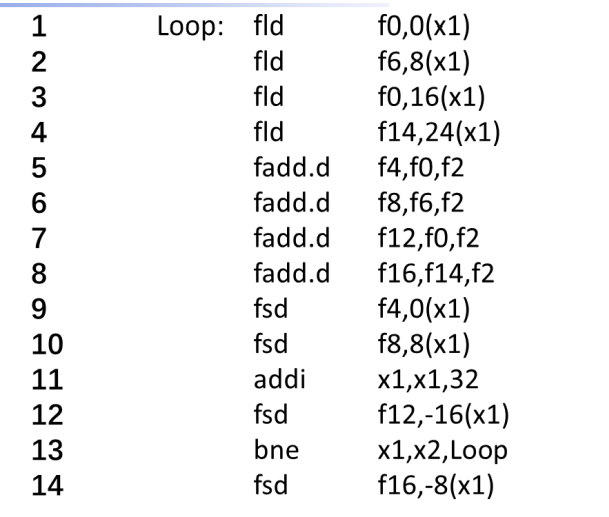
这个时候,每四个循环占用14个clock
代码如下(由于软件实现和硬件实现存在差异,软件实现的时候将addi和bne放到了指令的最后面):
#RISC-V
#小端模式
# 寄存器类
X_ = 0x00000033
Register = {
0b00000: 0x00000000,
0b00001: 0x00000000,
0b00010: 0x00000008,
0b00011: 0x00000000,
0b00100: 0x00000000,
0b00101: 0x00000000,
0b00110: 0x00000000,
0b00111: 0x00000000,
0b01000: 0x00000000,
0b01001: 0x00000000,
0b01010: 0x00000000,
0b01011: 0x00000000,
0b01100: 0x00000000,
0b01101: 0x00000000,
0b01110: 0x00000000,
0b01111: 0x00000000,
0b10000: 0x00000000,
0b10001: 0x00000000,
0b10010: 0x00000000,
0b10011: 0x00000000,
0b10100: 0x00000000,
0b10101: 0x00000000,
0b10110: 0x00000000,
0b10111: 0x00000000,
0b11000: 0x00000000,
0b11001: 0x00000000,
0b11010: 0x00000000,
0b11011: 0x00000000,
0b11100: 0x00000000,
0b11101: 0x00000000,
0b11110: 0x00000000,
0b11111: 0x00000000
}
pc = 0x00000000
# 储存器类
Memory = {
0x00000000: 0x00
}
# 初始化内存,大小为1KB
def init_Mem():
for i in range(2**20):
Memory[0x00000000 + i] = 0x00
# ISA指令
# ***************************Loads***************************
# 字节加载指令
def lb(rd, rs1, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm]
if a & 0b10000000 == 0b10000000:
a = a + 0b11111111111111111111111100000000
Register[rd] = a
pass
# 半字加载指令
def lh(rd, rs1, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm] + (Memory[Register[rs1] + imm + 1] << 8)
if a & 0b1000000000000000 == 0b1000000000000000:
a = a + 0b11111111111111110000000000000000
Register[rd] = a
pass
# 字加载指令
def lw(rd, rs1, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm] + (Memory[Register[rs1] + imm + 1] << 8) + (
Memory[Register[rs1] + imm + 2] << 16) + (Memory[Register[rs1] + imm + 3] << 24)
Register[rd] = a
pass
# 无符号字节加载指令
def lbu(rd, rs1, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm]
Register[rd] = a
pass
# 无符号半字加载指令
def lhu(rd, rs1, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm] + (Memory[Register[rs1] + imm + 1] << 8)
Register[rd] = a
pass
# ***************************Stores***************************
# 存字节指令
def sb(rs1, rs2, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
Memory[Register[rs1] + imm] = Register[rs2] & 0b11111111
pass
# 存半字指令
def sh(rs1, rs2, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
Memory[Register[rs1] + imm] = Register[rs2] & 0b11111111
Memory[Register[rs1] + imm + 1] = (Register[rs2] >> 8) & 0b11111111
pass
# 存字指令
def sw(rs1, rs2, imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
Memory[Register[rs1] + imm] = Register[rs2] & 0b11111111
Memory[Register[rs1] + imm + 1] = (Register[rs2] >> 8) & 0b11111111
Memory[Register[rs1] + imm + 2] = (Register[rs2] >> 16) & 0b11111111
Memory[Register[rs1] + imm + 3] = Register[rs2] >> 24
pass
# ***************************Shifts***************************
# 逻辑左移指令
def sll(rd, rs1, rs2):
Register[rd] = (Register[rs1] << (Register[rs2] & 0b11111)) & 0xffffffff
pass
# 立即数逻辑左移
def slli(rd, rs1, shamt):
if shamt < 0b100000:
Register[rd] = (Register[rs1] << shamt) & 0xffffffff
pass
# 逻辑右移指令
def srl(rd, rs1, rs2):
Register[rd] = Register[rs1] >> (Register[rs2] & 0b11111)
pass
# 立即数逻辑右移
def srli(rd, rs1, shamt):
if shamt < 0b100000:
Register[rd] = Register[rs1] >> shamt
pass
# 算数右移指令
def sra(rd, rs1, rs2):
Register[rd] = Register[rs1] >> (Register[rs2] & 0b11111)
if (Register[rs1] >> 31) == 1:
for i in range(0, Register[rs2] & 0b11111):
Register[rd] = Register[rd] + 2 ** (31 - i)
pass
# 立即数算数右移指令
def srai(rd, rs1, shamt):
Register[rd] = Register[rs1] >> (shamt & 0b11111)
if (Register[rs1] >> 31) == 1:
for i in range(0, shamt & 0b11111):
Register[rd] = Register[rd] + 2 ** (31 - i)
pass
# ***************************Arithmetic***************************
# 加指令
def add(rd, rs1, rs2):
Register[rd] = Register[rs1] + Register[rs2]
pass
# 加立即数指令
def addi(rd, rs1, imm):
pass
# 减指令
def sub(rd, rs1, rs2):
pass
# 高位立即数加载指令
def lui(rd, imm):
pass
# PC加立即数指令
def auipc(rd, imm):
pass
# ***************************Logical***************************
# 异或指令
def xor(rd, rs1, rs2):
pass
# 立即数异或指令
def xori(rd, rs1, imm):
pass
# 取或指令
def or_(rd, rs1, rs2):
pass
# 立即数取或指令
def ori(rd, rs1, imm):
pass
# 与指令
def and_(rd, rs1, rs2):
pass
# 与立即数指令
def andi(rd, rs1, imm):
Register[rd] = Register[rs1] + imm
pass
# ***************************Compare***************************
# 小于则置位指令
def slt(rd, rs1, rs2):
pass
# 小于立即数则置位指令
def slti(rd, rs1, imm):
pass
# 无符号小于则置位指令
def sltu(rd, rs1, rs2):
pass
# 无符号小于立即数则置位指令
def sltiu(rd, rs1, imm):
pass
# ***************************Branches***************************
# 相等时分支指令
def beq(rs1, rs2, imm):
pass
# 不等式分支指令
def bne(rs1, rs2, imm):
global pc
if (Register[rs1] != Register[rs2]):
pc += (imm * 4)
pass
# 小于时分支指令
def blt(rs1, rs2, imm):
pass
# 大于等于时分支指令
def bge(rs1, rs2, imm):
pass
# 无符号小于时分支指令
def bltu(rs1, rs2, imm):
pass
# 无符号大于等于时分支指令
def bgeu(rs1, rs2, imm):
pass
def jalr(rd,rs1,imm):
pass
def ecall(rd,rs1,imm):
pass
def ebreak(rd,rs1,imm):
pass
# ***************************Supplement***************************
#浮点加载双字
def fld(rd,rs1,imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
a = Memory[Register[rs1] + imm] + (Memory[Register[rs1] + imm + 1] << 8) + (
Memory[Register[rs1] + imm + 2] << 16) + (Memory[Register[rs1] + imm + 3] << 24)
Register[rd] = a
imm=imm+4
rd=rd+1
a = Memory[Register[rs1] + imm] + (Memory[Register[rs1] + imm + 1] << 8) + (
Memory[Register[rs1] + imm + 2] << 16) + (Memory[Register[rs1] + imm + 3] << 24)
Register[rd] = a
pass
#双精度浮点加
def fadd_d(rd,rs1,rs2):
tag1=Register[rs1+1]>>31
index1=((Register[rs1+1]>>20)&0b11111111111)-1023
mantissa1=1+((Register[rs1+1]&0xfffff)*(2**32)+Register[rs1])*(2**(-52))
tag2=Register[rs2+1]>>31
index2=((Register[rs2+1]>>20)&0b11111111111)-1023
mantissa2=1+((Register[rs2+1]&0xfffff)*(2**32)+Register[rs2])*(2**(-52))
a=((-1)**tag1)*mantissa1*(2**index1)+((-1)**tag2)*mantissa2*(2**index2)
if a>=0:
tag3=0
else:
tag3=1
a=a*(-1)
print(a)
index3=1023
while a>=2:
a=a/2
index3=index3+1
mantissa3=(int)((a-1)*(2**52))
print(bin(mantissa3))
Register[rd]=mantissa3&0xffffffff
Register[rd+1]=tag3*(2**31)+index3*(2**20)+mantissa3>>32
pass
'''Register[0]=0
Register[1]=0b01000000000010110110000000000000
Register[2]=0
Register[3]=0b11000000001001011000000000000000
Register[4]=0
Register[5]=0
fadd_d(4,0,2)
print(bin(Register[4]),bin(Register[5]))
print((0b11011011-0b1010110000)/(2**6),(0b111010101)/64)'''
#双精度浮点存储
def fsd(rs1,rs2,imm):
if imm & 0b100000000000 == 0b100000000000:
imm = imm + 0b11111111111111111111000000000000
Memory[Register[rs1] + imm] = Register[rs2] & 0b11111111
Memory[Register[rs1] + imm + 1] = (Register[rs2] >> 8) & 0b11111111
Memory[Register[rs1] + imm + 2] = (Register[rs2] >> 16) & 0b11111111
Memory[Register[rs1] + imm + 3] = Register[rs2] >> 24
rs2=rs2+1
imm=imm+4
Memory[Register[rs1] + imm] = Register[rs2] & 0b11111111
Memory[Register[rs1] + imm + 1] = (Register[rs2] >> 8) & 0b11111111
Memory[Register[rs1] + imm + 2] = (Register[rs2] >> 16) & 0b11111111
Memory[Register[rs1] + imm + 3] = Register[rs2] >> 24
pass
#指令集
class ISA:
def __init__(self):
instruction = self.defInstr()
self.tellFormat(instruction)
def defInstr(self): # 传入参数为指令在内存的地址
instru = 0x00000000
for i in range(4):
# print(hex(addr + i))
# print(hex(Memory[addr + i]))
instru += Memory[pc + i] * (256 ** i)
# print(hex(instru))
return instru
instruFormat = {
0b0110011 : 'RFormat', #运算
0b0010011 : 'IFormat', #运算
0b0000011 : 'IFormat', #load
0b0100011 : 'SFormat', #store
0b1100011 : 'SBFormat', #branch
0b1101111 : 'UJFormat', #jump(大立即数跳转)
0b1100111 : 'IFormat', #jump
0b0110111 : 'UFormat', #rd = imm << 12
0b0010111 : 'UFormat', #rd = pc + (imm << 12)
0b1110011 : 'IFormat', #transfer control
}
def getopfromins(self, instruction):
return instruction & 0b1111111
def tellFormat(self, instruction):
opcode = self.getopfromins(instruction)
switch = {
0b0110011: 'RFormat', # 运算
0b0010011: 'IFormat', # 运算
0b0000011: 'IFormat', # load
0b0100011: 'SFormat', # store
0b1100011: 'SBFormat', # branch
0b1101111: 'UJFormat', # jump(大立即数跳转)
0b1100111: 'IFormat', # jump
0b0110111: 'UFormat', # rd = imm << 12
0b0010111: 'UFormat', # rd = pc + (imm << 12)
0b1110011: 'IFormat', # transfer control
}
Format = switch.get(opcode, 'Invalid')
global pc
pc += 4
if (Format == 'Invalid'):
return False
elif (Format == 'RFormat'):
return self.decodeRFormat(instruction)
elif (Format == 'IFormat'):
return self.decodeIFormat(instruction)
elif (Format == 'SFormat'):
return self.decodeSFormat(instruction)
elif (Format == 'SBFormat'):
return self.decodeSBFormat(instruction)
elif (Format == 'UFormat'):
return self.decodeUFormat(instruction)
elif (Format == 'UJFormat'):
return self.decodeUJFormat(instruction)
return False
def decodeRFormat(self, instruction):
funct7 = instruction >> 25
rs2 = instruction >> 20 & 0b11111
rs1 = instruction >> 15 & 0b11111
funct3 = instruction >> 12 & 0b111
rd = instruction >> 7 & 0b11111
if (funct7 == 0x00):
if (funct3 == 0x0):
return add(rd, rs1, rs2)
elif (funct3 == 0x4):
return xor(rd, rs1, rs2)
elif (funct3 == 0x6):
return or_(rd, rs1, rs2)
elif (funct3 == 0x7):
return and_(rd, rs1, rs2)
elif (funct3 == 0x1):
return sll(rd, rs1, rs2)
elif (funct3 == 0x5):
return srl(rd, rs1, rs2)
elif (funct3 == 0x2):
return slt(rd, rs1, rs2)
elif(funct3 == 0x3):
return sltu(rd, rs1, rs2)
elif (funct7 == 0x20):
if (funct3 == 0x0):
return sub(rd, rs1, rs2)
elif (funct3 == 0x5):
return sra(rd, rs1, rs2)
elif (funct3 == 0x1):
return fadd_d(rd, rs1, rs2)
return False
def decodeIFormat(self, instruction):
imm = instruction >> 20
immTemp = 0b000000000000
# 这里的imm是十二位的二进制补码,需要将其转换为机器数
if (imm >> 11 == 1):
for i in range(11):
immTemp += (1 - (imm >> i & 1)) * (2 ** i)
immTemp += 1
imm = 0 - immTemp
rs1 = instruction >> 15 & 0b11111
funct3 = instruction >> 12 & 0b111
rd = instruction >> 7 & 0b11111
opcode = instruction & 0b1111111
if (opcode == 0b0010011):
if (funct3 == 0x0):
return addi(rd,rs1,imm)
elif (funct3 == 0x4):
return xori(rd,rs1,imm)
elif (funct3 == 0x6):
return ori(rd,rs1,imm)
elif (funct3 == 0x7):
return andi(rd,rs1,imm)
elif (funct3 == 0x1):
return slti(rd,rs1,imm)
elif (funct3 == 0x5):
if (instruction >> 25 == 0b0000000):
return srli(rd,rs1,imm)
elif (instruction >> 25 == 0b0100000):
return srai(rd,rs1,imm)
elif (funct3 == 0x2):
return slti(rd,rs1,imm)
elif (funct3 == 0x3):
return sltiu(rd,rs1,imm)
elif (opcode == 0b0000011):
if (funct3 == 0x0):
return lb(rd,rs1,imm)
elif (funct3 == 0x1):
return lh(rd,rs1,imm)
elif (funct3 == 0x2):
return lw(rd,rs1,imm)
elif (funct3 == 0x4):
return lbu(rd,rs1,imm)
elif (funct3 == 0x5):
return lhu(rd,rs1,imm)
elif (funct3 == 0x6):
return fld(rd, rs1, imm)
elif (opcode == 0b1100111):
if (funct3 == 0x0):
return jalr(rd,rs1,imm)
elif (opcode == 0b1110011):
if (funct3 == 0x0 and imm == 0x0):
return ecall(rd,rs1,imm)
elif (funct3 == 0x0 and imm == 0x1):
return ebreak(rd,rs1,imm)
return False
def decodeSFormat(self, instruction):
imm = (instruction >> 7) & 0b11111 + (instruction >> 25) * 0b100000
immTemp = 0b000000000000
# 这里的imm是十二位的二进制补码,需要将其转换为机器数
if (imm >> 11 == 1):
for i in range(11):
immTemp += (1 - (imm >> i & 1)) * (2 ** i)
immTemp += 1
imm = 0 - immTemp
funct3 = (instruction >> 12) & 0b111
rs1 = (instruction >> 15) & 0b11111
rs2 = (instruction >> 20) & 0b11111
if funct3 == 0x0:
return sb(rs1, rs2, imm)
elif funct3 == 0x1:
return sh(rs1, rs2, imm)
elif funct3 == 0x2:
return sw(rs1, rs2, imm)
elif funct3 == 0x3:
return fsd(rs1, rs2, imm)
return False
def decodeSBFormat(self, instruction):
a = (instruction >> 7) & 0b11111
c = ((instruction >> 25) & 0b1111111) << 5
imm = a + c
immTemp = 0b000000000000
# 这里的imm是十二位的二进制补码,需要将其转换为机器数
if (imm >> 11 == 1):
for i in range(11):
immTemp += (1 - (imm >> i & 1)) * (2 ** i)
immTemp += 1
imm = 0 - immTemp
funct3 = (instruction >> 12) & 0b111
rs1 = (instruction >> 15) & 0b11111
rs2 = (instruction >> 20) & 0b11111
if funct3 == 0x0:
return beq(rs1, rs2, imm)
elif funct3 == 0x1:
return bne(rs1, rs2, imm)
elif funct3 == 0x4:
return blt(rs1, rs2, imm)
elif funct3 == 0x5:
return bge(rs1, rs2, imm)
elif funct3 == 0x6:
return bltu(rs1, rs2, imm)
elif funct3 == 0x7:
return bgeu(rs1, rs2, imm)
return False
def decodeUFormat(self, instruction):
opcode = instruction & 0b1111111
rd = (instruction >> 7) & 0b11111
imm = instruction >> 12
immTemp = 0b000000000000
# 这里的imm是十二位的二进制补码,需要将其转换为机器数
if (imm >> 11 == 1):
for i in range(11):
immTemp += (1 - (imm >> i & 1)) * (2 ** i)
immTemp += 1
imm = 0 - immTemp
if opcode == 0b0110111:
return lui(rd, imm)
elif opcode == 0b0010111:
return auipc(rd, imm)
return False
def decodeUJFormat(self, instruction):
return False
def main():
init_Mem()
#初始化寄存器
Register[0b00001] = 0x00000001 # 1,2寄存器用来存储常量s
Register[0b00010] = 0x00000001 #
Register[0b00011] = 0x00001F20 # 用来存储x1,即999,这里令其为996*8
Register[0b00100] = 0x00000000 # 用来存储x2,即0
#需要变址寄存器用来找到load和store指令中的内存地址,每四条指令使用同一个变址寄存器,通过改变立即数的大小来决定内存地址的变换
Register[0b00101] = 0x00000000 # 用来表示load或者store指令的变址寄存器
#其余的寄存器用来存储加载的数字以及计算结果,其初始值都是零
#内存中的指令数据
#1 fld
# load two word指令,立即数为0x38,转化为二进制为0011 1000
# imm[11:0] rs1 110 rd 0000011
# 000000111000 00011 110 00110 0000011
# EA = A + (rs1)
# 0x 03 81 E3 03
Memory[0x00000000] = 0x03
Memory[0x00000001] = 0xE3
Memory[0x00000002] = 0x81
Memory[0x00000003] = 0x03
#2 fld
# load two word指令,立即数为0x38向后移动8个存储单元,即0x40,转化为二进制为0100 0000
# imm[11:0] rs1 110 rd 0000011
# 000001000000 00011 110 01000 0000011
# EA = A + (rs1)
# 0x 04 01 E4 03
Memory[0x00000004] = 0x03
Memory[0x00000005] = 0xE4
Memory[0x00000006] = 0x01
Memory[0x00000007] = 0x04
#3 fld
# load two word指令,立即数为0x38向后移动16个存储单元,即0x48,转化为二进制为0100 1000
# imm[11:0] rs1 110 rd 0000011
# 000001001000 00011 110 01010 0000011
# EA = A + (rs1)
# 0x 04 81 E5 03
Memory[0x00000008] = 0x03
Memory[0x00000009] = 0xE5
Memory[0x0000000A] = 0x81
Memory[0x0000000B] = 0x04
#4 fld
# load two word指令,立即数为0x38向后移动24个存储单元,即0x50,转化为二进制为0101 0000
# imm[11:0] rs1 110 rd 0000011
# 000001010000 00011 110 01100 0000011
# EA = A + (rs1)
# 0x 05 01 E6 03
Memory[0x0000000C] = 0x03
Memory[0x0000000D] = 0xE6
Memory[0x0000000E] = 0x01
Memory[0x0000000F] = 0x05
#5 fadd_d
# 这里rd(1415)的地址为:0b01110,rs1(6、7数组中的元素)的地址为:0b00110,r2(1/2,常量s)的地址为:0b00001
# funct7 rs2 rs1 funct3 rd opcode
# 0100000 00001 00110 001 01110 0110011
# 其中funct7和funct3的组合表示浮点加法运算
# 16进制表示为0x 40 13 17 33
Memory[0x00000010] = 0x33
Memory[0x00000011] = 0x17
Memory[0x00000012] = 0x13
Memory[0x00000013] = 0x40
#6 fadd_d
# 这里rd(1617)的地址为:0b10000,rs1(8、9数组中的元素)的地址为:0b01000,r2(1/2,常量s)的地址为:0b00001
# funct7 rs2 rs1 funct3 rd opcode
# 0100000 00001 01000 001 10000 0110011
# 其中funct7和funct3的组合表示浮点加法运算
# 16进制表示为0x 40 14 18 33
Memory[0x00000014] = 0x33
Memory[0x00000015] = 0x18
Memory[0x00000016] = 0x14
Memory[0x00000017] = 0x40
#7 fadd_d
# 这里rd(1819)的地址为:0b10010,rs1(10、11数组中的元素)的地址为:0b01010,r2(1/2,常量s)的地址为:0b00001
# funct7 rs2 rs1 funct3 rd opcode
# 0100000 00001 01010 001 10010 0110011
# 其中funct7和funct3的组合表示浮点加法运算
# 16进制表示为0x 40 15 19 33
Memory[0x00000018] = 0x33
Memory[0x00000019] = 0x19
Memory[0x0000001A] = 0x15
Memory[0x0000001B] = 0x40
#8 fadd_d
# 这里rd(20、21)的地址为:0b10100,rs1(12、13数组中的元素)的地址为:0b01100,r2(1/2,常量s)的地址为:0b00001
# funct7 rs2 rs1 funct3 rd opcode
# 0100000 00001 01100 001 10100 0110011
# 其中funct7和funct3的组合表示浮点加法运算
# 16进制表示为0x 40 16 1A 33
Memory[0x0000001C] = 0x33
Memory[0x0000001D] = 0x1A
Memory[0x0000001E] = 0x16
Memory[0x0000001F] = 0x40
#9 fsd
# 和第一条load指令相对应
# 内存中的指令数据
# 1 fld
# load two word指令,立即数为0x38,转化为二进制为0011 1000
# imm[11:0] rs1 110 rd 0000011
# 000000111000 00101 110 00110 0000011
# rs2需要存储的数据
# rs1基址寄存器
# imm[11:5] rs2 rs1 func3 imm[4:0] opcode
# 0000001 01110 00011 011 11000 0100011
# 这里的立即数和load指令中的立即数具有相同的作用,即数组在内存中的开始地址
# 其十六进制表示为0x02 E1 BC 23
Memory[0x00000020] = 0x23
Memory[0x00000021] = 0xBC
Memory[0x00000022] = 0xE1
Memory[0x00000023] = 0x02
#10 fsd
# load two word指令,立即数为0x38向后移动8个存储单元,即0x40,转化为二进制为0100 0000
# imm[11:0] rs1 110 rd 0000011
# 000001000000 00101 110 01000 0000011
# EA = A + (rs1)
# 0x 04 02 E4 03
# 和第二条load命令的立即数相同
# rs2需要存储的数据
# rs1基址寄存器
# imm[11:5] rs2 rs1 func3 imm[4:0] opcode
# 0000010 10000 00011 011 00000 0100011
# 这里的立即数和load指令中的立即数具有相同的作用,即数组在内存中的开始地址
# 其十六进制表示为0x05 01 B0 23
Memory[0x00000024] = 0x23
Memory[0x00000025] = 0xB0
Memory[0x00000026] = 0x01
Memory[0x00000027] = 0x05
#11 addi
# x1是存储在第一条load指令的基址寄存器和imm产生的内存地址,初始值为996*4,最后的值为0
# imm为-32
# imm[11:0] rs1 111 rd 0010011
# 111111100000 00011 111 00011 0010011
# 十六进制表示为0x FE 01 F1 93
Memory[0x00000030] = 0x93
Memory[0x00000031] = 0xF1
Memory[0x00000032] = 0x01
Memory[0x00000033] = 0xFE
#12 fsd
#和第三条load指令的立即数相同
# load two word指令,立即数为0x38向后移动16个存储单元,即0x48,转化为二进制为0100 1000
# imm[11:0] rs1 110 rd 0000011
# 000001001000 00101 110 01010 0000011
# EA = A + (rs1)
# 0x 04 82 E5 03
# rs2需要存储的数据
# rs1基址寄存器
# imm[11:5] rs2 rs1 func3 imm[4:0] opcode
# 0000010 10010 00011 011 01000 0100011
# 这里的立即数和load指令中的立即数具有相同的作用,即数组在内存中的开始地址
# 其十六进制表示为0x05 21 B4 23
Memory[0x00000028] = 0x23
Memory[0x00000029] = 0xB4
Memory[0x0000002A] = 0x21
Memory[0x0000002B] = 0x05
#13 bne
# 若x1和x2里面的内容不相等则进行分支转移
# 分支转移中的立即数,令其为-14
# imm[12|10:5] rs2 rs1 func3 imm[4:1|11] opcode
# x1 x2
# 1111111 00011 00100 001 10011 1100011
# 16进制表示为0x FE 32 19 E3
Memory[0x00000034] = 0xE3
Memory[0x00000035] = 0x19
Memory[0x00000036] = 0x32
Memory[0x00000037] = 0xFE
#14 fsd
# 和第四条load指令的立即数相同
# load two word指令,立即数为0x38向后移动24个存储单元,即0x50,转化为二进制为0101 0000
# imm[11:0] rs1 110 rd 0000011
# 000001010000 00101 110 01100 0000011
# EA = A + (rs1)
# 0x 05 02 E6 03
# rs2需要存储的数据
# rs1基址寄存器
# imm[11:5] rs2 rs1 func3 imm[4:0] opcode
# 0000010 10100 00011 011 10000 0100011
# 这里的立即数和load指令中的立即数具有相同的作用,即数组在内存中的开始地址
# 其十六进制表示为0x05 41 B8 23
Memory[0x0000002C] = 0x23
Memory[0x0000002D] = 0xB8
Memory[0x0000002E] = 0x41
Memory[0x0000002F] = 0x05
#指令后面的位置用来存储数组数据,从十进制56开始即0x38
for i in range(1000):
Memory[0x00000038 + i * 8] = 0x01
Memory[0x00000038 + i * 8 + 1] = 0x01
Memory[0x00000038 + i * 8 + 2] = 0x01
Memory[0x00000038 + i * 8 + 3] = 0x01
Memory[0x00000038 + i * 8 + 4] = 0x01
Memory[0x00000038 + i * 8 + 5] = 0x01
Memory[0x00000038 + i * 8 + 6] = 0x01
Memory[0x00000038 + i * 8 + 7] = 0x01
while (1):
ISA()
print("Memory 4019 is: ", Memory[4019])
print("Memory 4018 is: ", Memory[4018])
print("Memory 4017 is: ", Memory[4017])
print("Memory 4016 is: ", Memory[4016])
print("Memory 4015 is: ",Memory[4015])
print("Memory 4014 is: ",Memory[4014])
print("Memory 4013 is: ", Memory[4013])
print("Memory 4012 is: ", Memory[4012])
print("Register 0b00011 is: ",Register[0b00011])
if Register[0b00011] == 0x00000000:
break
pass
main()
最后
以上就是善良外套最近收集整理的关于python模拟硬件优化for循环的全部内容,更多相关python模拟硬件优化for循环内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![[python入门学习]9、列表推导式1、基本语法及应用:2、列表推导式与循环的区别:3、列表推导式的应用:4、有if分句的列表推导式5、嵌套的列表推导式:6、列表推导式终极语法:](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)
发表评论 取消回复