1、获取第二高的薪水
- 表(emp) & 列 (empno,salary)
select nvl(salary,null)
from(
select e.salary
desc_rank()over(order by e.salary desc) as rank
from emp e
)t1
where t1.rank = 2
2、分数排名(名词之间不能有间隔)
- 表(scores) & 列 (id,score)
select score,desc_rank(over score desc) as rank
from Scores
order by rank
3、查询表中连续至少连续登录三天的用户
- 表(player) & 列 (id,last_day)
(1)分析函数将登陆日期排序
select id,last_dat,row_number()over(partition by id over by last_day) as rank_num
from palyer
(2)计算用户不同登录日期之间的时间差
select id,;last_day,date_sub(last_day - rank_num) as last_num_day
from (
select id,last_dat,row_number()over(partition by id over by last_day) as rank_num
from palyer
) t1
(3)对id,last_num_id进行分组获取连续登陆天数
select id,last_num_by,count(1) as days
from (
select id,;last_day,date_sub(last_day - rank_num) as last_num_day
from (
select id,last_dat,row_number()over(partition by id over by last_day) as rank_num
from palyer
) t1
) tt1
group by id,last_num_by
| 时间 | 排名 |
|---|---|
| 2021-11-11 | 1 |
| 2021-11-12 | 2 |
| 2021-11-13 | 3 |
| 2021-12-11 | 4 |
| 2021-12-15 | 5 |
(4)进行筛选过滤,获取连续登录三天的用户id
select id
from (
select id,last_num_by,count(1) as days
from (
select id,;last_day,date_sub(last_day - rank_num) as last_num_day
from (
select id,last_dat,row_number()over(partition by id over by last_day) as rank_num
from palyer
) t1
) tt1
group by id,last_num_by
)
where days = 3
4、获取每一个学生中分数最高的分数及科目
- 表(score)& 列(id,course,score)
(1)分组获取学生成绩
select id, max(score) as max_score
from Scores
group by id
(2)通过表连接获取学生科目
select
id,course,score
from Scores s1
left join (
select id, max(score) as max_score
from Scores
group by id
) s2
on s1.id = s2.id and s1.score = s2.score
日期:20211116
5、部门工资最高的员工
- 表(emp) | 列 (id,name,salary,departmentid)
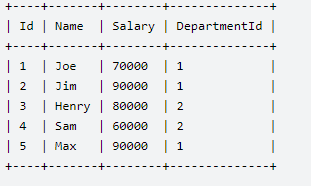
select name
from
(
select name,rank()over(partition by departmentid over salary desc) as rank
from emp) t1
where t1.rank = 1
6、部门前三高的所有员工信息
- 表(emp) | 列(id,name,Salary,Departmentid)
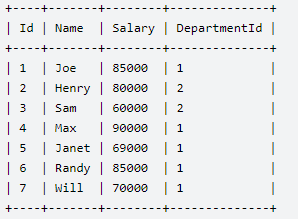
select *
from emp tt1 left join
(select id
from(
select id,desc_rank()over(partition by departmentid order by salary desc) as rank
from emp ) t1
where t1.rank <= 3) tt2
on tt1.id = tt2.id
7、hive行转列
-
源表
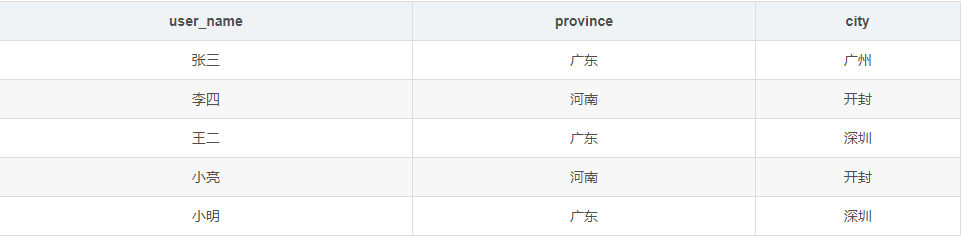
-
目标表

-
代码实战
(1)将省份和城市连接起来,作为临时表
select name,concat(provice,city) as address
from user_info
(2)使用子查询,查询第一步的结果,并按照连接后的省份城市字段进行group by排序,然后查出的多个结果使用collect_set进行去重汇总,并使用concat_ws按照“|”进行连接,把查询结果输出即可
select
tui1.place place,
concat_ws('|', collect_set(tui1.user_name)) users
from
(select
user_name,
concat(province, ",", city) place
from
user_info) tui1
group by
tui1.place;
- COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
--需求:统计每个城市有哪些人
select city,collect_set(user_name) from user_info group by city;
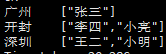
8、列转行
- 源表

- 目标表
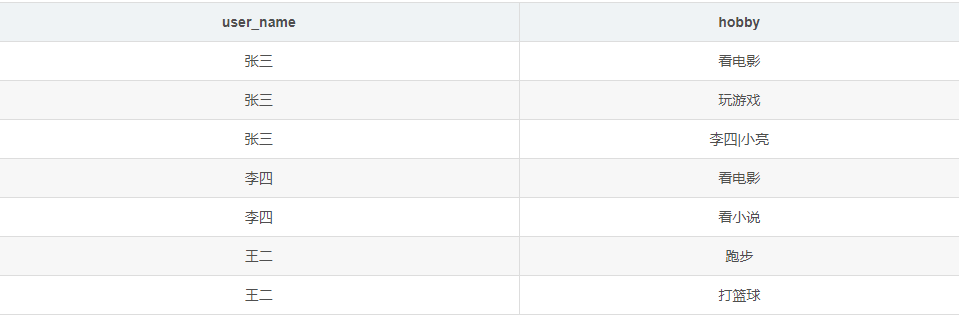
select
user_name,
hobby
from
user_hobby_info
lateral view explode(hobbies) hobby_tmp as hobby;
- 具体详解
(1)explode(hobbies):把user_hobby_info表里定义的array类型的hobbies字段进行拆分;
(2)lateral view explode(hobbies) hobby_tmp:将拆分后的字段定义为临时表,即视图
(3)lateral view explode(hobbies) hobby_tmp as hobby:把虚拟表里的字段名定义为hobby;
(4)两表做笛卡尔积连接
from
user_hobby_info
lateral view explode(hobbies) hobby_tmp as hobby
(5)查询连接结果
select
user_name,
hobby
from
user_hobby_info
lateral view explode(hobbies) hobby_tmp as hobby;
20211117
9、取出最近三次的价格并单独做拉链
(1)需求分析
- 源表如下
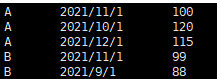
- 目标表如下

- 建表语句如下
create table Price(
name string
,buy_date string
,price int
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;
INSERT INTO Price VALUES
('A','2021/11/1',100),
('A','2021/10/1',120),
('A','2021/12/1',115),
('B','2021/11/1',99),
('B','2021/9/1',88)
(2)代码如下
①单独生成一列排名,作为子查询
select
name
,price
,row_number()over(partition by name order by buy_date) as rank
from Price
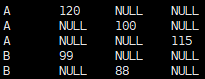
②分别查询出前三并单独命名做另外一列
select name
,case when rank = 1 then price end as price
,case when rank = 2 then price end as price1
,case when rank = 3 then price end as price2
from (select
name
,price
,row_number()over(partition by name order by buy_date) as rank
from Price) t1
③根据name进行分组,取每一列的最大值命名
select name
,max(price) as price
,max(price1) as price1
,max(price2) as price2
from(
select name
,case when rank = 1 then price end as price
,case when rank = 2 then price end as price1
,case when rank = 3 then price end as price2
from (select
name
,price
,row_number()over(partition by name order by buy_date) as rank
from Price) t1) tt1
group by name
20211118
10、多表联合主键连接 & 判空
(1)需求
- 三张源表(T1110A,T1110B,T1110C)
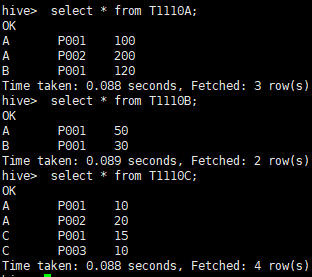
- 目标表
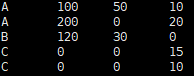
- 建表语句
CREATE TABLE T1110A
(WAREHOUSE string,
ITEM string,
QTY int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
INSERT INTO T1110A VALUES ('A','P001',100),('A','P002',200),('B','P001',120 );
CREATE TABLE T1110B
(WAREHOUSE string,
ITEM string,
QTY int
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
INSERT INTO T1110B VALUES ('A','P001',50),('B','P001',30);
CREATE TABLE T1110C
(WAREHOUSE string,
ITEM string,
QTY int
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
INSERT INTO T1110C VALUES ('A','P001',10),('A','P002',20),('C','P001',15),('C','P003',10);
(2)代码如下
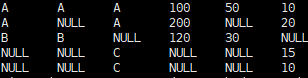
①首先进行多表连接
select t1.WAREHOUSE as t1w,t2.WAREHOUSE as t2w,t3.WAREHOUSE as t3w,t1.QTY as t1Q,t2.QTY as T2Q,t3.QTY as T3Q from T1110A t1 full join T1110B t2 on t1.WAREHOUSE = t2.WAREHOUSE and t1.item = t2.item
full join T1110C t3 on t1.WAREHOUSE = t3.WAREHOUSE and t1.item = t3.item
- 运行结果
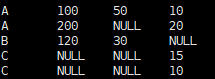
②将连接后的表作为临时表,对WAREHOUSE进行ifnull判断
select coalesce(t1w,t2w,t3w),t1Q,t2Q,t3Q from
(
select t1.WAREHOUSE as t1w,t2.WAREHOUSE as t2w,t3.WAREHOUSE as t3w,t1.QTY as t1Q,t2.QTY as T2Q,t3.QTY as T3Q from T1110A t1 full join T1110B t2 on t1.WAREHOUSE = t2.WAREHOUSE and t1.item = t2.item
full join T1110C t3 on t1.WAREHOUSE = t3.WAREHOUSE and t1.item = t3.item
) tt1
- 运行结果
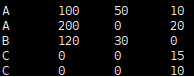
③分别对其余三列进行if判空
select coalesce(t1w,t2w,t3w),if(t1Q is null,0,t1Q),if(t2Q is null,0,t2Q),if(t3Q is null,0,t3Q) from
(
select t1.WAREHOUSE as t1w,t2.WAREHOUSE as t2w,t3.WAREHOUSE as t3w,t1.QTY as t1Q,t2.QTY as T2Q,t3.QTY as T3Q from T1110A t1 full join T1110B t2 on t1.WAREHOUSE = t2.WAREHOUSE and t1.item = t2.item
full join T1110C t3 on t1.WAREHOUSE = t3.WAREHOUSE and t1.item = t3.item
) tt1
- 运行结果
20211123
11、工资部门汇总表
(1)需求
- 源表
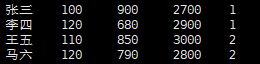
- 目标表
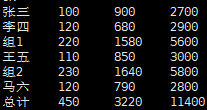
- 建表语句&数据
create table money_sum(
name string
,day_money int
,week_money int
,month_money int
,department string
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
INSERT INTO money_sum VALUES('张三',100,900,2700,1),('李四',120,680,2900,1),('王五',110,850,3000,2),('马六',120,790,2800,2);
(2)代码实现
①先union all获取所有数据
select * from(
select "总计" as name,sum(day_money) as day_money,sum(week_money) as week_money,sum(month_money) as money_sum, from money_sum
union
select concat(department,"组") as name,sum(day_money) as day_money,sum(week_money) as week_money,sum(month_money),department as money_sum from money_sum group by department
union
select name,day_money,week_money,month_money,department from money_sum) as tmp
- 运行结果
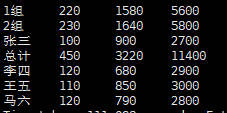
(2)将数据进行排序
select * from(
select "总计" as name,sum(day_money) as day_money,sum(week_money) as week_money,sum(month_money) as money_sum,'9999' as department from money_sum
union
select concat(department,"组") as name,sum(day_money) as day_money,sum(week_money) as week_money,sum(month_money),department as money_sum from money_sum group by department
union
select name,day_money,week_money,month_money,department from money_sum) as tmp
order by department,name desc
- 运行结果
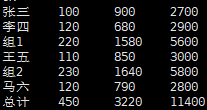
最后
以上就是野性灯泡最近收集整理的关于HQL笔试题总结(持续更新中)日期:202111162021111720211118的全部内容,更多相关HQL笔试题总结(持续更新中)日期内容请搜索靠谱客的其他文章。








发表评论 取消回复