前言
pytorch加载数据需要使用torch.utiles.data包中的的两个类:DataSet,DataLoader。(可能你在其他资料还会看到DataLoaderIter。这里我们不提及此类。)还有torchvision的transforms类和PIL的Image类。如果你对这些类都不了解,那么你在需要一边看我的博客,一边去百度哦:)
数据加载
数据加载顾名思义就是将RGB的图像数据变成可以计算的tensor。需要的步骤有:
- 定义一个图片转tensor的转换器(transform)
- 定义一个继承自Dataset的myDataSet类,在此类的__getitem__(self, index)中完成一张图片变成一个tensor的转换
- 生成一个DataLoader对象,并将一个myDataSet对象传入DataLoader构造器。
- 通过语句for batch_x,batch_y in dataLoader:... 进行数据的加载
第零步:看一下我们要加载的东西
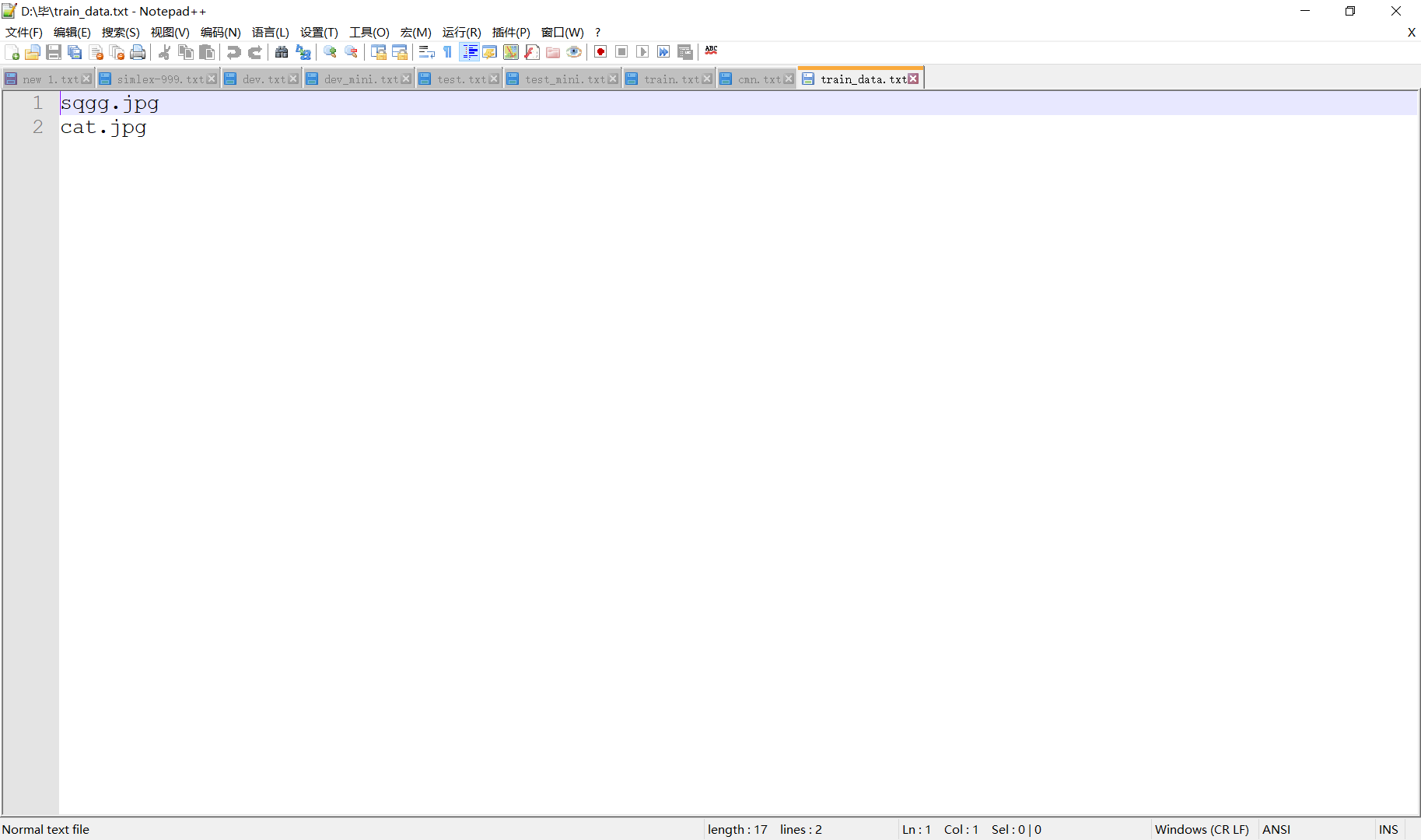
我们看一下train_data里面都有啥子吧:
第一步:编写转换器
means = [0.485, 0.456, 0.406]
stds = [0.229, 0.224, 0.225]
size = 224
transform1 = transforms.Compose([
transforms.Resize(size),
transforms.CenterCrop(size),
transforms.ToTensor(),
transforms.Normalize(means, stds),
])我们只需要知道transorm是一个转换器,以后直接使用tranform1(img)就可以将来img变成tensor了。而Compose后面的都是在定义此转换如何进行数据增强和转成tensor。比如transforms.Resize(size)也就是要把img进行resize。ToTensor表示转成Tensor。
注意:ToTensor要写在Resize这些之后,因为transform1的运行过程是从上到下依次执行的。而resize这些操作只能对img进行不能对tensor进行的。
第二步:编写myDataSet
myDataSet我们只需要编写3个函数:__init__(), __getitem__(), __len()__
下面是__init__()函数:需要在此方法中完成:self.images(待训练图片路径列表), self.labels(待训练图片标签列表),self.transform(图片转tensor需要的转换器)的构造
def myReadFile(pth):
'''
:param pth:
:return:取出train_data和train_label中的数据并返回一个列表
'''
files = []
with open(pth, "r", encoding='utf-8') as f:
for line in f.readlines():
files.append(line.strip('n'))
return files
class myDataset(Dataset):
def __init__(self, transform):
self.images = myReadFile("train_data.txt")
self.labels = myReadFile("train_label.txt")
self.transform = transform 下面是__getitem__(self, index):需要在此方法完成:根据index,取出对应的图片路径和标签然后转换成tensor,最后return
class myDataset(Dataset):
def __getitem__(self, index):
img_org = Image.open(self.images[index]).convert('RGB') # 加载图片
img_tensor = self.transform(img_org) # 转成tensor
img_tensor.requires_grad_() # 计算数据的梯度,可以省略
label = self.labels[index] # 加载标签
return img_tensor, label # 返回下面是__len__(self):需要完成:返回列表的长度
class myDataset(Dataset):
def __len__(self):
return len(self.images)第三步:利用DataLoader加载数据了
train_data = myDataset(transform1)
trainLoader = DataLoader(train_data, batch_size=1, shuffle=True)
for batch_x, batch_y in trainLoader:
....相当于一次循环tranLoader就调用batch_size次的myDataset.__getitem()__,然后batch_x = (x1, x2, x3....)的tuple了。确诊x1,x2,x3均是一张图片转成的tensor
conclusion
终于写完了2020.06.18 :)
最后
以上就是大力小土豆最近收集整理的关于pytorch使用笔记(一):加载数据前言数据加载conclusion的全部内容,更多相关pytorch使用笔记(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复