sql server replication 为实现数据库读写分离,高可用等都提供了不错的解决方案。实现 replication 总共分为三种方法:
- 是 SSMS 来搭建,这个方法比较简单,只要你在脑袋里有了成型的架构思维和拓扑结构,就能很容易实现;
- 是依赖 T-sql script 的一套存储过程,以 sp_create*, sp_drop* 等存储过程, 配合 distribution 数据库的动态管理视图 (DMV) 来实现搭建,维护和监控;
- 可以使用 .NET Client 编程实现,这套方法比较灵活,而且可以系统化的管理多个 replciation 应用,比较适合大规模的 replication 搭建与管理。当然,既然有 .NET Client 方法也会有 Native Code 的方法,这个应用就有点广了,我也不至于用 c 从头来玩一遍分布式。
网络上针对第一种方法有了很多的记载和实验,动手一搜可以搜到很多的案例,自己看着搭建也可以很快走完整套流程,中间可能会有一些小细节或者小问题需要注意。但是涉及到第二种和第三种方法,就很少了,我在 MaryKay 的时候,老外针对这两种情况,也是选择放弃,甚至第一种就不考虑使用,大概就是因为不好用的原因。所以今天我就要以第一种方法切入,然后谈一下后面两种方法。
先从架构拓扑谈起,再细化到组件(Agents) 以及实现方法,最后讲一讲管理。从概念讲起,先在头脑里搭建这个 replication 的框架,每一个组件的配置及使用,然后灵活配置各个组件的应用,这一步一个脚印的往前进,循序渐进,才能走的更远。这个过程会花费很长的时间,所以耐心,是我完成搭建 replication 的一个必要条件。
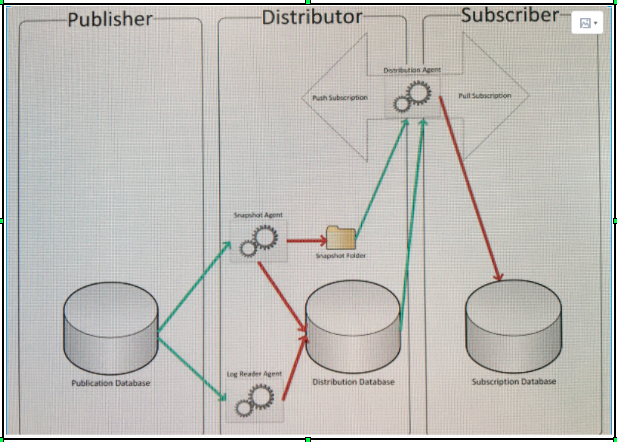
上面这张图,简明扼要的阐述了 replication 的架构与组件,绿线表示读,红线表示写。看图说话,我们一一将里面的关键点说明白:
- Publisher, Distributor, Subscriber, 这三者可以分布在不同的 database instance 上面,也可以都在同一个 Instance 上面。 实践中,我们一般都会将三种角色,分布在三个不同的服务器的 database instance 上面,保证了应用的可用性,不至于一台服务器宕机,其他服务都不可用的状况。
- Replication 是一种数据复制服务,在 sql server 中的实现,是脱离了 database engine 概念的,像 storage engine, query engine 等。 Replication (数据读)的实现,其实是一组 windows executables 的应用,学名上是 Agents,这些 Agents 普遍来说,都是建立在 Distributor 这个角色所在的 database instance 里面,具体就是配置在 Distribution 这个数据库里面,当然这个数据库名字可以更改,我们需要知道的是,这个数据库就像是一组元数据,存储了我们定义好的一系列 replication 组件,包括像 publication, subscription 等等。 这里唯一要注意的,就是 pull subscription 与 push subscription 的 Agents 存放地点,pull subscription 是将 Agents 存放到了 subscriber 上面而 push subscription 的 Agents 都存放到了 Distributor 上面。
- 既然谈到了 distributor, 我们就要提到,整个 replication 的创建的时候,第一个要创建的要素就是 Distributor: 选一台服务器,setup 一个 database instance, 让它作为 Distributor 角色,创建存放元数据的 distribution 数据库。为了易于管理,可以创建多个 Distribution 数据库,让每一个 distribute 数据库存放一组 publisher 的publication. 接下来就是创建 Publication 与 Subscription. 次序是先 publication 再 subscription. 这里有两个注意点: 一是 distributor 所在的 instance, 想要 publish 一些 publication的话,只能以自己的 distributor 作为分布者;二是任何想要用到这个 distributor 的 publisher 都必须在这个 distributor 上面先注册。理论上就是,我们不能随便分发你的出版刊物,但是你们出版社,也不能随便使用我们的分销渠道为你们服务,都必须先订了合同。
- Replication 可以有三种表现形式: Snapshot Replication, Transactional Replication 以及 Merge Replication. transactional replication: 可以用来集成数据仓库,提供高可用与高并发。 Merge Replication, 最常见的应用场景是移动应用,也可以做数据集成;Snapshot replication 则是用来初始化数据,在应用 transactional , merge replication 的时候,做一次全量抽取。可见, Snapshot Replicatoin 提供的是一个基础功能。
- 关于 Snapshot Replication, 有趣的是它的实现机制: 首先会在 publication 数据库记上俩比 marker, 第一笔是记录 snapshot 开始的时间,第二笔是记录 snapshot 结束的时间。当把 snapshot 生成 bcp file 之后, log reader agent 会把俩比 marker 中发生的 command 也生成日志,再应用到已经生成的 bcp 文件中。 这样的作用就是保证一份完整的 snapshot。之后的 transaction replication 就只要生成最后一个 marker 之后的操作就行。从而避免了重复生成 snapshot 生成时间之间的发生在 publication database 上的操作。这样的 snapshot replication 就可以接受最后一个 log marker 之后的日志重做了。
这里先埋下个小问题:如果没有日志的操作,该怎么同步呢?
把图里的内容都讲了一遍了,就要问自己几个问题了:
- Publication 的内容都分发出去了,那么怎么保证 Publication 的内容与各个 Subscription 之间的内容保持一致性了呢? 检验机制有哪些? 一般我们想到的是做 Audit, 比如 checksum, except 等等。 但是实现起来比较复杂,sql server replication有哪些好用的特性能帮助我们快速的达到验证数据一致性的目的呢?
- 既然是 replication, 数据复制嘛,那么什么时候会同步一次,多久呢? 我们是不是可控这些同步数据的时间间隔呢?怎么去同步,手工,还是定义一些同步脚本?
- 错误控制?如果同步不成功,会有哪些警告,我们改如何处理这些警告?比如一台 remote replication 服务器宕机,那么这台服务器就不能接受 publication 了,那这一部分没有同步的数据,是不是会保留?什么时候会继续同步这部分数据?
- Snapshot 在创建的时候,会给数据库带来多少影响, 锁在这里面是如何实现的 ? Transactional , Merge Replication 又是如何使用锁的?
- replication 与 Log shipping , database mirroring 的区别: 前者可以发布整个数据库也可以仅仅是一个库中的部分对象,而后俩者则发布的是整个数据库。那么这部分对象同步到已存在的数据库时,是不是会重写当前数据库的其他对象?
- 上面留下的小问题: 如果没有日志的操作,该怎么同步呢? 比如我是用 bcp 插入的 publication 中的表,这部分数据都是没有日志的,那么怎么被 log reader agent 读取到,并同步到其他 replica 里面去?
人生嘛,就是解决一个一个的问题,要回答上面这些问题,还是靠一步一步做实验来弄清楚,先从 SSMS 搭建一个 replication 开始:
- 新建 3 台虚拟机,装上 sql server 2008R2 , 分别将 instance 命名为 Distributor, Publisher, Subscriber. 在 Publisher 中新建一个数据库, 名叫 stock, 我们假定这是一个用来存放股票相关的数据库。 新建一张表叫做 region. 我们的目标是把这张表同步到 Subscriber 中的 stock 数据库中去。这个 Subscriber 中的 stock 是必须先创建好的。
- 先建立一个 Distributor 角色,将它安装在 Distributor 这个 instance 上面,建立完之后,会有一个 distribution 的数据库,我们这里要额外注意下这个数据库里面的对象,数据库表,stored procedure 等。这些数据库对象在我们手工用 .net client 或者 T-sql 存储过程搭建 replication 的时候,会经常用到。
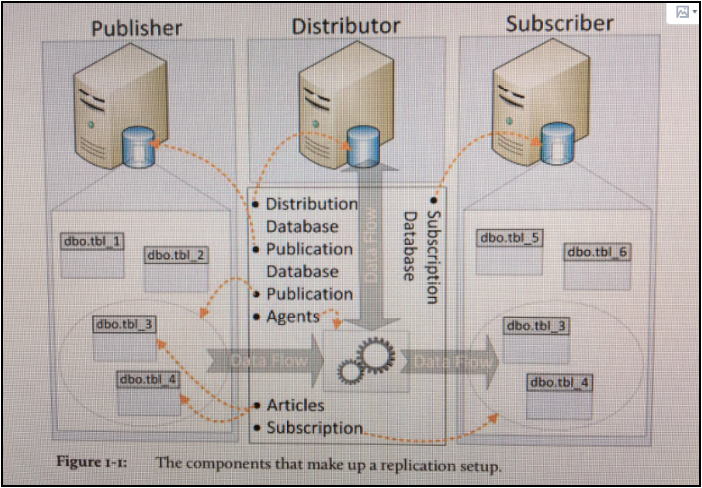
- 接着在 Publisher 这个 instance 下面,新建一个 publication. 这个 Publication 包含了一张表, region. 没错,这份 publication 是定义在 publisher 上面,所以不能在 distributor instance 上面找到。但是在 Publisher 上面指定 Distributor 的时候,会选择某一个 instance 来当 distributor ,我们这里正好是这个装有 distributor instance 的机器。所以在 distribution 数据库中,会有相关记录,表示已经有 publisher 在使用我们的 distributor 功能了。这里不能搞混的是 publication 与 Distributor Agent 的概念。Distributor 的 snapshot Agent 以及 Log Reader Agent 是在 Distributor 这个服务器上的,这两个 Agent 是去读 publication 的。所以 Publication 一定是在 publisher 服务器上创建的.
- 同3 所说, Subscription 也是配置在 Subscriber 这个 instance 上面的。 至于 Distributor Agent 是创建在 Distributor 还是 Subscriber 上面, 就看是哪种类型的 Subscription 了。前文有讲这里不再累述。配置完,记得要看下 distribute 数据库。这里发生的变化都在这个库里能体现出来。
这里有张图,可以很好的看到,publication, distributor agents, subscription 的所属问题,注意黑圆点的标注:
好了,上面写的是思路,具体的实现,我们一步一步来,在这个实现的步骤里面,肯定会遇到很多不可思议的事情,一件一件记录下来,肯定能获得不少 serendipity (意外的收获):
Distributor 配置好之后,我们要为 publisher配置 distributor 了,这个时候,奇怪的问题来了,用密码登陆 distributor 的时候,始终登陆不了,总是出现这个错误 “ sql server could not cononect to the distributor with the specified password”。参考了网络上的一篇帖子,有这么个用法:
首先,先检查下 remote access 在数据库里面是不是开启,而在可以检查这个选项的时候,还需要将 show advanced options 这个开关给开起来,看看是怎么开的 :
sp_configure ‘show advanced options’, 1
reconfigure
这还只是第一步,先将 show advanced options 启动,reconfigure 就是让这个选项获得新值之后,重新写到数据库配置文里面。接下来就是配置 remote access, 让其 Run Value 等于 1:
sp_configure ‘remote access’, 1
reconfigure
到这一步就可以了,重启 sql server instance, 再 sp_configure 查看下 remote access 的值, 确认 Run_Value 是1 了。这一步在 publisher, distributor 上面都要执行好。别以为 sql server 默认会帮你把一切都配置好,尤其是要用到 replication,failover cluster 等这类特性的时候,我们需要检查一些常规的配置,比如刚才 1 中提到的 remote access, 接下来 remote access 是允许了,但是 remote access 用到的相关渠道(协议)是不是也已经开启了呢? 这里讲的就是 sql server configuration manager 里面会用到的 TCP/IP, Named pipes 远程协议是不是被启动了? 没启动,这里要启动起来。否则,经典的连接错误就会找上来:
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider: SQL Network Interfaces, error: 28 - Server doesn’t support requested protocol)- Distributor 的功能包括了,从 publisher 拉回 snapshot和相关 transaction,并推给 subscriber 或者等着 subscriber 来取 snapshot 或者 transaction。 这里就会有两个 sql agent job(根据我们的 replication type , job 的数量会有不同), 名字很好认,一眼就能看出来,那么修改这两个 job 的时间调度就能修改我们需要的 replication 更新频率了。
- 前面有个问题,publication 的这一部分数据,会不会冲掉原来的表的数据和对象? 同一个表的数据会被冲掉,但是已经存在的对象是冲不掉的,比如有一张表是在订阅之前就存在在 subscriber 数据库中的,那么只要 publication 里面没有同名的表,这张表还是会被留下来的,不受影响。
- 继续回答前面的问题,我们知道 Distributor 的 log Reader Agent 是去读取 publisher 的日志,从而生成一份日志重做的行为数据,存在 distribution 数据库里,等待下次同步的时候,在 subscriber 的 subscription 数据库里重新跑下这份日志重做的行为数据,完成一次 Transactional Replication. 但是如果我们在 publisher 的 publication 上面(这份 publication 就包含一份 article, 就是一张表 region, 包括了两个字段 regionId, regionName), 用了一次 bcp 导入了 1000 条数据,都知道 bcp 是不写日志的,那么 Transaction Replication 做增量更新的时候,会不会同步这 1000 条数据到 subscription 的数据库里面呢?
首先,我们要搭建一个 Transactional Replication 的环境。注意要给需要做 publication 的表带上主键,否则会有这么个错误:
the database contains no objects that can be replicated with the selected publication type
接着用 bcp 导入 1000 条数据,过不到 1 分钟,去看下 subscription 里的同步表 stock, 发现数据居然同步过来了。这里面其实我犯了个错误,概念性的错误,bcp 其实是会写日志的,不写日志的情况,仅仅是在bulk-logged 和 simple recovery model 下面,不过这样是肯定会丢数据的,事实证明,没有日志的表,是不允许 replicate 的。碰到这种情况, snapshot replication 是个好选择。 - Snapshot Replication 在 init snapshot 的时候,会对表进行一个 S 锁,对 page, rid 分别进行 IX, X 锁。影响还是蛮大的。Transaction Replication 增量读的是日志,由于有 primary key 的存在,所以对 key 也进行了锁,而且是 X 锁。
- 在配置 publisher publication的时候,会有对 retention 做限制。比如,(即使在 publication全部同步完之后)增量抽取的日志保留多长时间,在每一份 subscription 没有同步之前,会保留多长时间等。
- 在每一份 publication 的右键菜单里,包含了一个 validate subscription 的选项,好东西,用来验证数据一致性。比起我们手写 checksum 或者 except 来验证,是不是方便了很多呢?这个 validation 的结果,SSMS 是不会马上给你看到的,我们要打开 Launch Replication Monitor 来看, 找到 Distributor to Subscription history , 查看 action message, 就可以看到 validation 到底有没有 pass 了。
- 不过细想,一个 publisher 只能订一个 distributor ,好像不合理? 为什么不能签订多个 distributor ,这样可以分散一个 distributor 的压力,也可以实现多播的可能性。
到这里,把前面的自个儿问自个儿的问题都回答了,那么我们就要进入下一个话题,如何用 T-SQL 编程的方法或者 .NET Client 的方法来构建 replication 呢?
- 大概的一个拓扑, 我们将三种角色分别安装在三台不同的 sql server 服务器上
1.1 distributor
1.2 publisher, publication, article
1.3 subscriber , subscription
1.4 Agents , Schedulers - 简单的一个实现, 以 snapshot replication 为例子
2.1 distributor script :
我们会在 distributor 角色的 sql server 服务器上,将这台服务器设置为 distributor ,建立 distribution 数据库, 并配置一个允许使用它作为 distributor 的 publisher。
2.2.1 sp_adddistributor 第一次执行的时候,必须指定password, 这个 password 是 distributor_admin 密码。 在 publisher 连接 distributor 的时候,也必须指定这个 distributor_admin 的密码,用来通信。下面这个例子其实还需要为 sp_adddistributor 参数 @password 赋值.
2.2.2 三大要素: distributor 所用到的 Instance , 以 serverNameinstanceName 命名; distributor 用到的数据库 distribution (名字可以更改); Snapshot 用到的存储路径.
DECLARE @distributor AS sysname;
DECLARE @distributionDB AS sysname;
DECLARE @publisher AS sysname;
DECLARE @directory AS nvarchar(500);
DECLARE @publicationDB AS sysname;
-- Specify the Distributor name.
SET @distributor = 'storagedistributor';
-- Specify the distribution database.
SET @distributionDB = N'distributionstock';
-- Specify the Publisher name.
SET @publisher ='publishercrm';
-- Specify the replication working directory.
SET @directory = N'C:snapshot';
-- Specify the publication database.
SET @publicationDB = N'stocktrans';
-- Install the server StorageDistributor as a Distributor using the defaults,
-- including autogenerating the distributor password.
USE master
EXEC sp_adddistributor @distributor = @distributor;
-- Create a new distribution database using the defaults, including
-- using Windows Authentication.
USE master
EXEC sp_adddistributiondb @database = @distributionDB,
@security_mode = 1;
GO
-- Create a Publisher and enable stocktrans for replication.
-- Add publishercrm as a publisher with storagedistributor as a local distributor
-- and use Windows Authentication.
DECLARE @distributionDB AS sysname;
DECLARE @publisher AS sysname;
-- Specify the distribution database.
SET @distributionDB = N'distribution'stock;
-- Specify the Publisher name.
SET @publisher = 'publishercrm'
USE [distributionstock]
EXEC sp_adddistpublisher @publisher=@publisher,
@distribution_db=@distributionDB,
@security_mode = 1;
GO2.2 publication script , article script
2.2.1 首先要做的两点,就是:一启动 publisher 的角色;二配置要使用的 distributor . 这里使用到的存储过程 sp_replicationdboption .
use stocktrans
go
sp_adddistributor
@distributor = 'storagedistributor',
@password = 'XXXXXXXXXXX'
sp_replicationdboption 'stocktrans','publish',true 2.2.2 在第一步里指定的 replication database, 执行 sp_addpublication 来添加 publication.
-- Create a new transactional publication with the required properties.
EXEC sp_addpublication
@publication = 'stocktranspub',
@status = N'active',
@allow_push = N'true',
@allow_pull = N'true',
@independent_agent = N'true';
-- Create a new snapshot job for the publication, using a default schedule.
EXEC sp_addpublication_snapshot
@publication = 'stocktranspub',
@job_login = 'smartofficejoe',
@job_password = 'xxxx',
-- Explicitly specify the use of Windows Integrated Authentication (default)
-- when connecting to the Publisher.
@publisher_security_mode = 1;
GO 2.2.3 添加 article
DECLARE @publication AS sysname;
DECLARE @table AS sysname;
DECLARE @filterclause AS nvarchar(500);
DECLARE @filtername AS nvarchar(386);
DECLARE @schemaowner AS sysname;
SET @publication = N'stocktranspub';
SET @table = N'stock';
SET @schemaowner = N'dbo'';
EXEC sp_addarticle
@publication = @publication,
@article = @table,
@source_object = @table,
@source_owner = @schemaowner,
@vertical_partition = N'true',
@type = N'logbased'2.3 subscription script 以 push subscription 为例子. 所有的操作都在publisher, publication 里面执行。
2.3.1 判断 publication 是不是可以被 push 或者 pull
Sp_helppublication
2.3.2 添加 push subscription
Sp_addsubscription
2.3.3 添加 push distributor agent
Sp_addpushsubscription_agent
2.3.4 默认是一天执行一次 snapshot push over ,那么怎么去修改这个同步间隔呢?
Sp_add_schedule
use stocktrans
go
sp_addsubscription
@publication = 'stocktranspub',
@subscriber = 'sqlclustermysqlcluster',
@destination_db = 'stock'3 . 监控健康指标
3.1 Replication Monitor
4 . 移除 replication , 察看 distribution 数据库元数据的更改
4.1 先移除 subscriber 和 subscription Sp_dropsubscription,sp_subscription_cleanup
4.2 再移除 publisher 和 publication
4.3 再移除 distributor
4.4 细节解说
为了禁止 Replication,我们必须依次执行以下步骤:
4.4.1 停掉所有的 Replication 相关的 Sql Agent Job, 关于 Replication 相关的 Sql Agent job ,命名也是有规律可以寻的,可以参考这篇文章 Replication Agent Security Model
4.4.2 在每一个 subscriper 的 subscription 数据库上,执行 sp_removedbreplication,删掉 replication 相关的数据库对象。
4.4.3 在 publisher 的 publication 数据库上,执行 sp_removedbreplication 来删掉 replication 相关的数据库对象。如果配置了 distributor ,那么执行 sp_dropdistributor 来删掉相关应用。
4.4.4 在 Distributor 的实例上,执行 sp_dropdisttpublisher. 有多少 publisher 配置了,就要执行相应的次数的命令,直到全部删掉。之后,执行 sp_dropdistributiondb 来卸载相关的 distribution 数据库。配置了多少 distribution 数据库,针对每个库都要做一次 sp_dropdistributiondb。最后执行 sp_dropdistributor 来删掉这个 distributor 角色。
最后
以上就是笑点低店员最近收集整理的关于SQL Server Replication的全部内容,更多相关SQL内容请搜索靠谱客的其他文章。








发表评论 取消回复