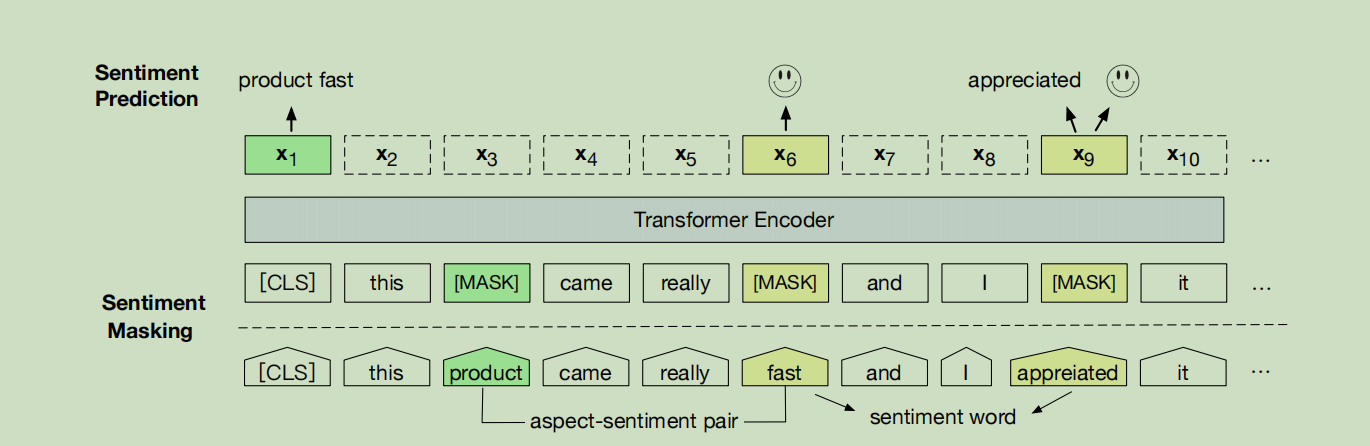
模型预训练阶段越接近真实的微调阶段,自然这个预训练模型就越适合这个微调任务
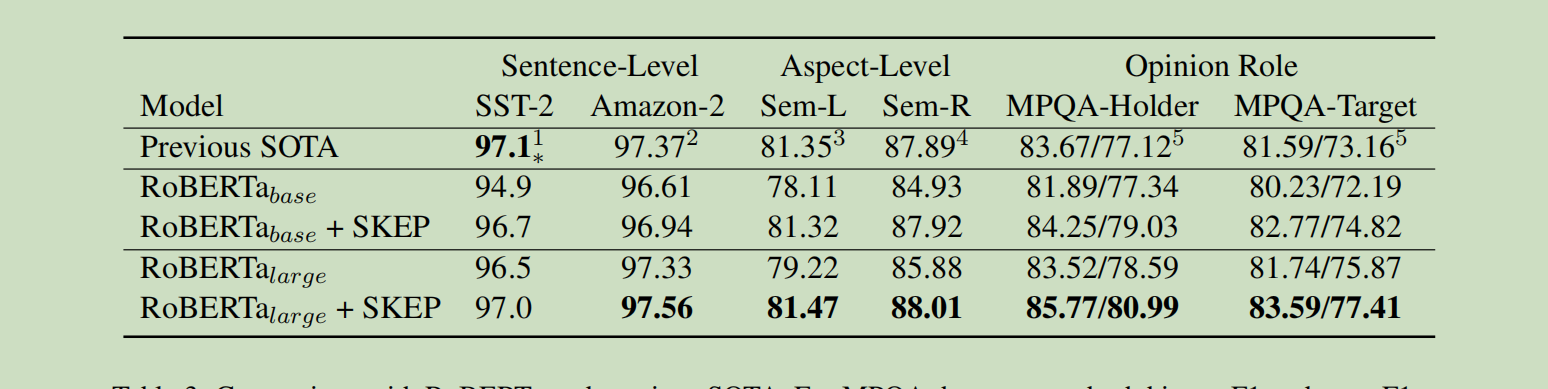
不管是分析学习还是应用某个模型,首先找到改模型的论文,上面有非常详细严谨的介绍,包括各种效果的展示,比赛打榜完全照着论文的配置就可以刷榜了
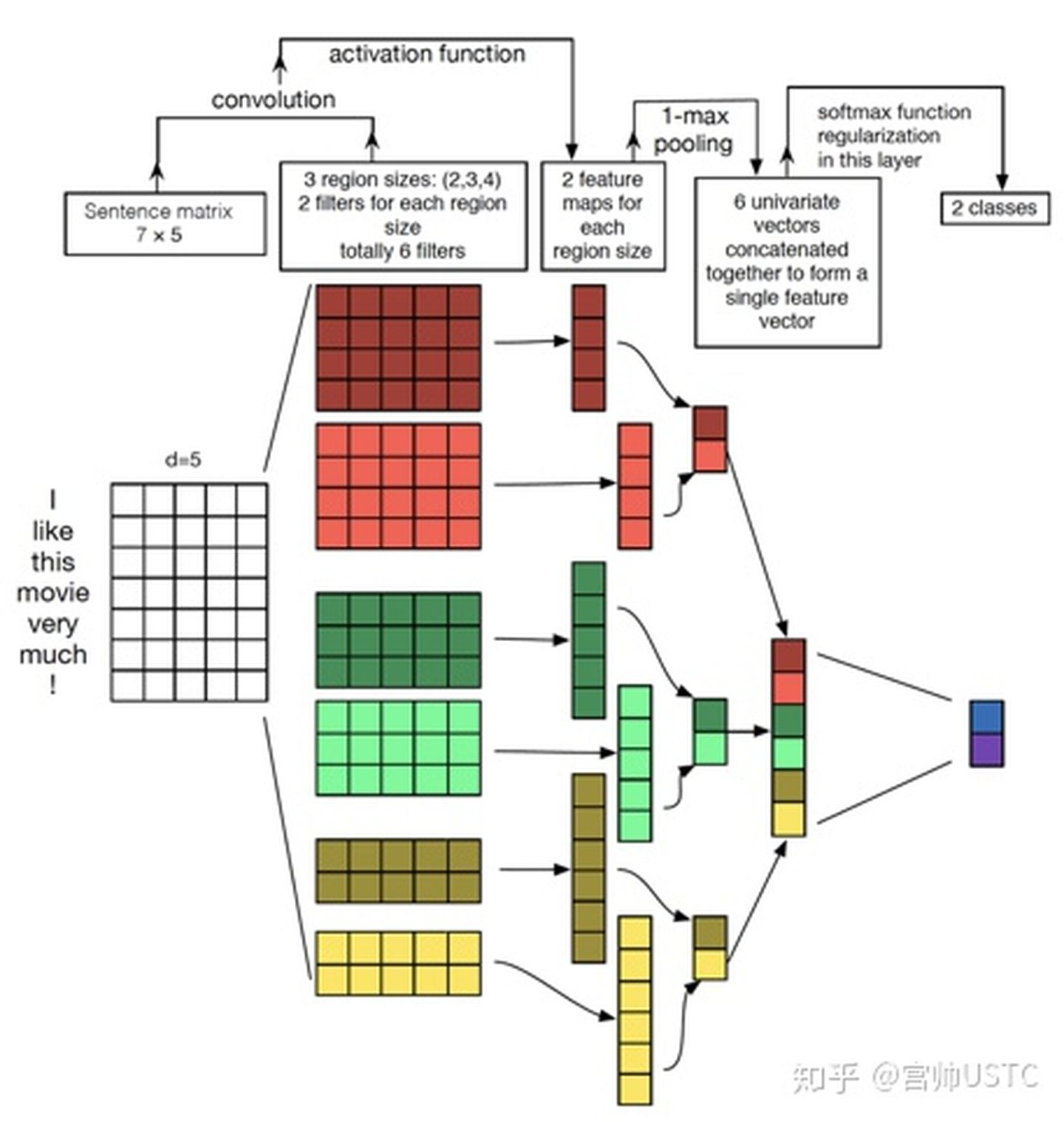
所谓的卷积就是特征提取而已,一个卷积核提取出整个的特征,维度变成1.没个卷积核提取的特征维度都是1最好可以把没个卷积核提取的特征拼接起来。
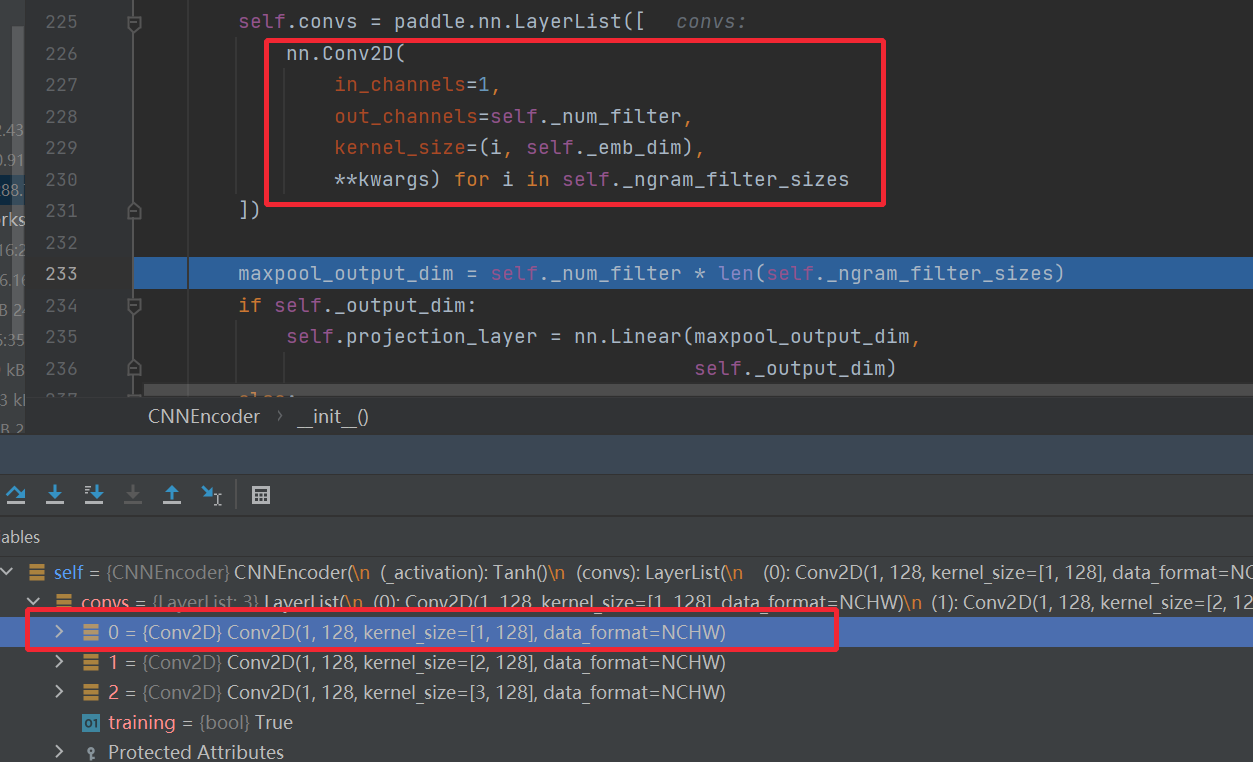
NCHW,个数,通道数,高,宽,每个大小的卷积核,都有128个,这128的参数是不一样的,提取的特征也是不一样的,每个卷积核提取完变成一维,然后再把每一维做组合。
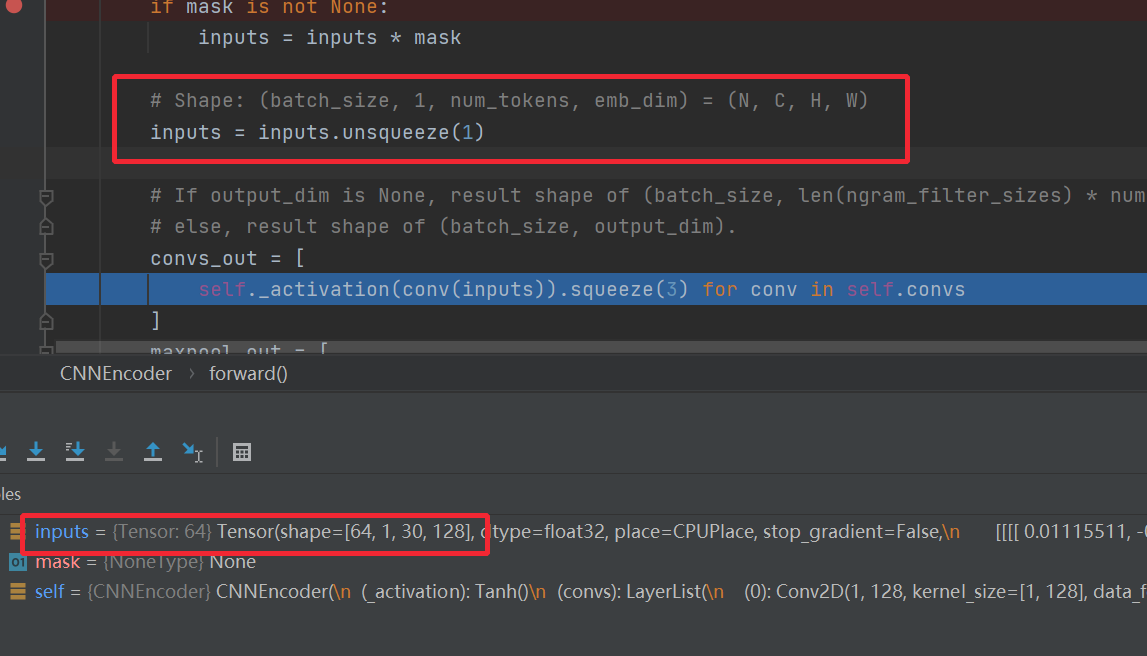
转换成程序能运行的卷积运算
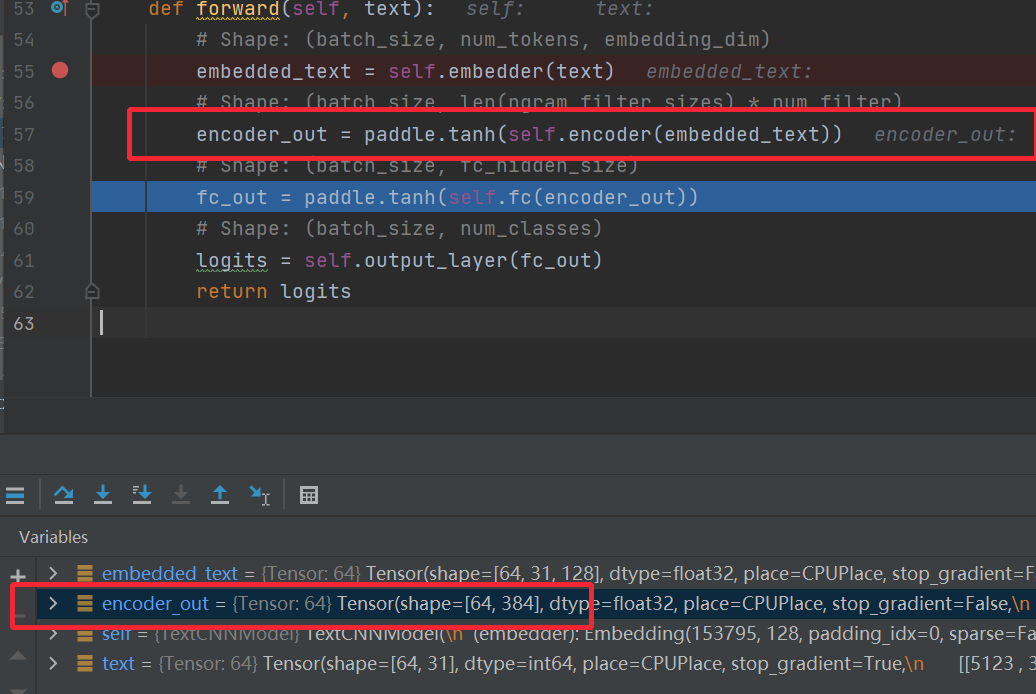
本质上就是通过各种特征提取操作后,把词向量,转换成一个整体的句子向量。
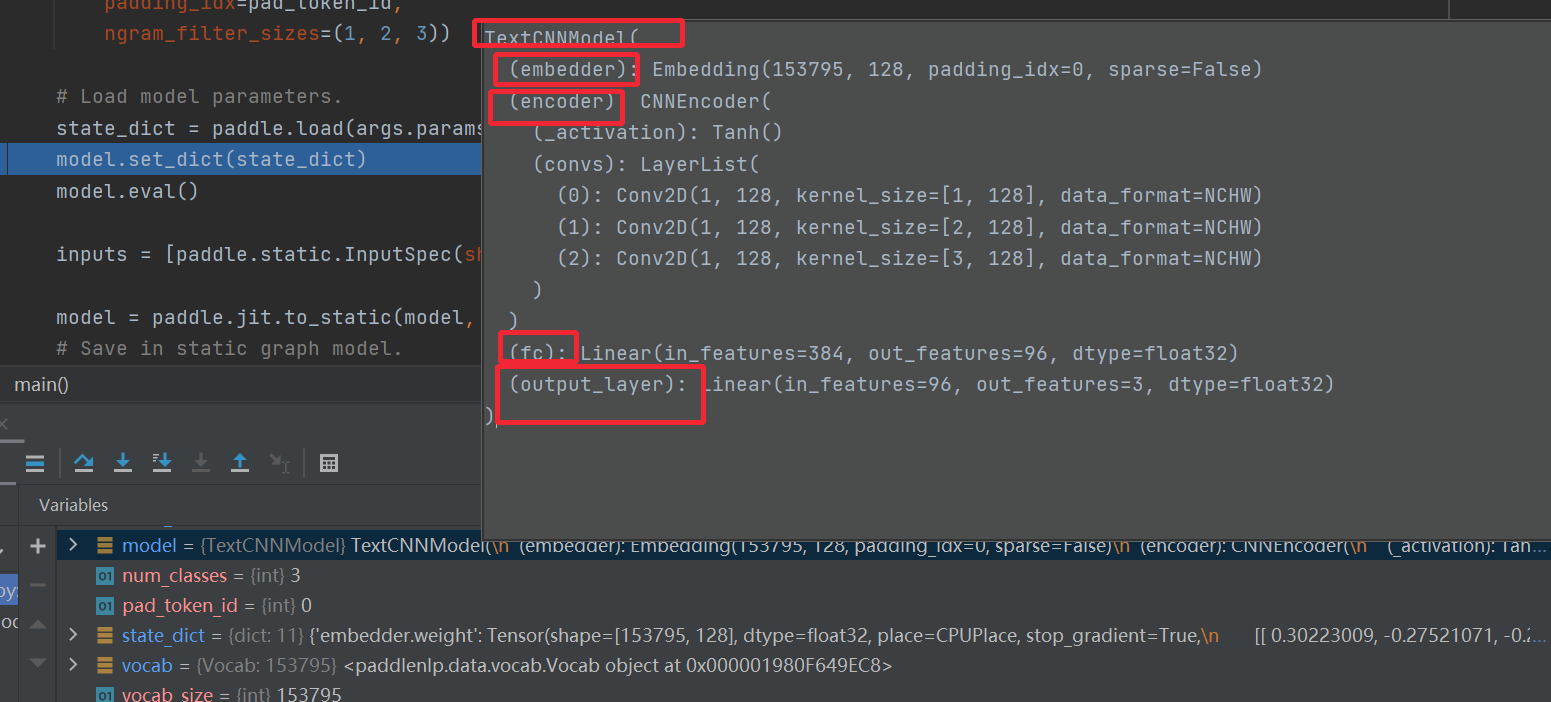
输入层,编码层,全连接层,输出层,标准的配置
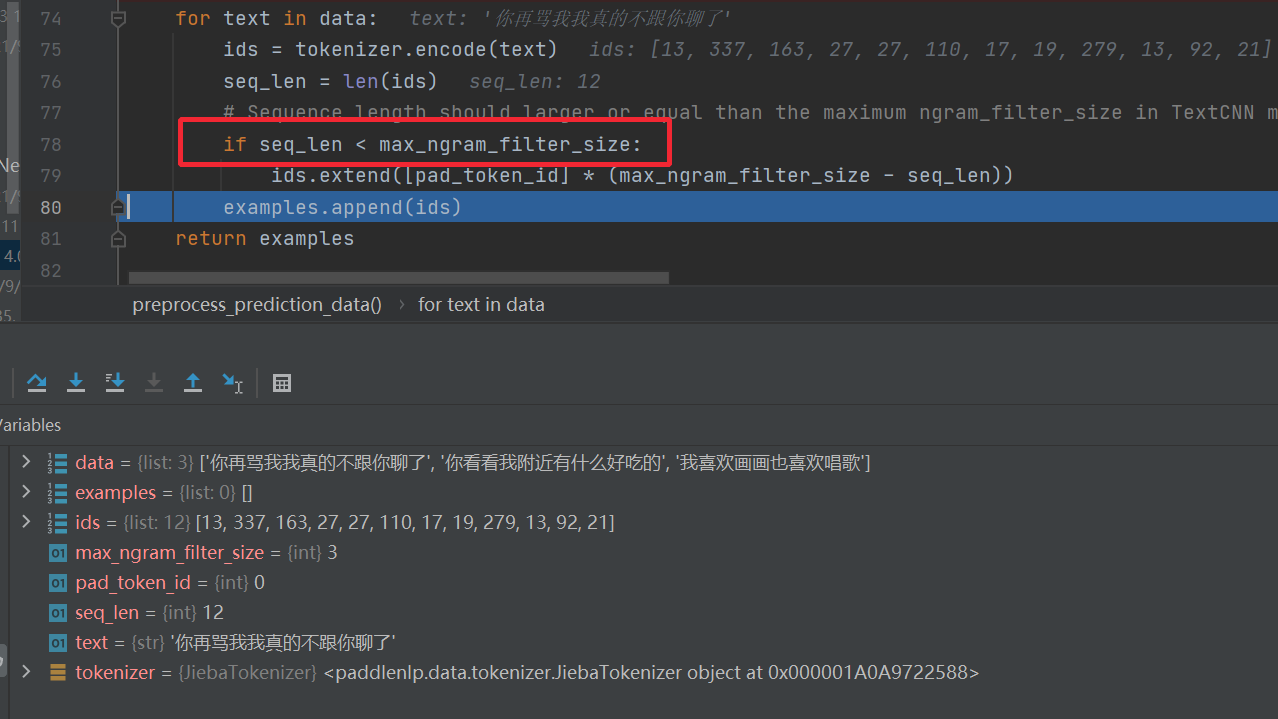
实际句子的长度不能小于卷积核的长度,否则没法做所谓的卷积运算
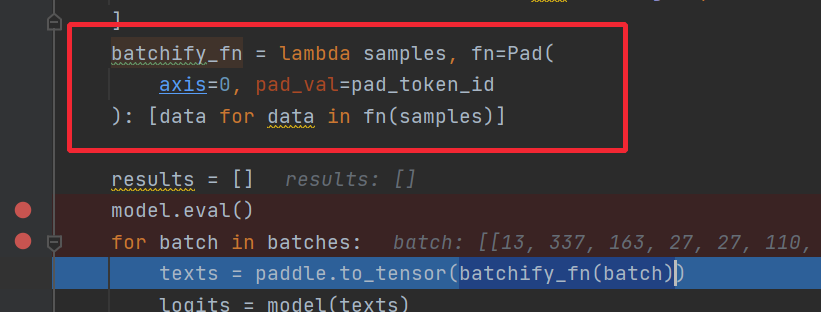
数据性质的转变,和数据类型的转变,数据形状上做padding,类型上python类型转换成numpy类型
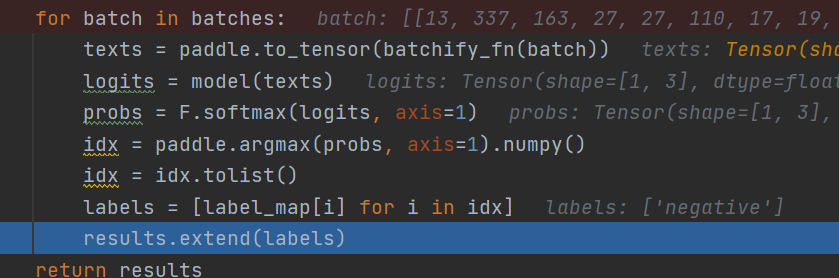
编码的时候转tensor,解码就是逐步转换类型,转转numpy再转list
skep

传参的MASK和解码的MASK未来信息不是一回事,这个传参的是避免填充的padding字符参与运算
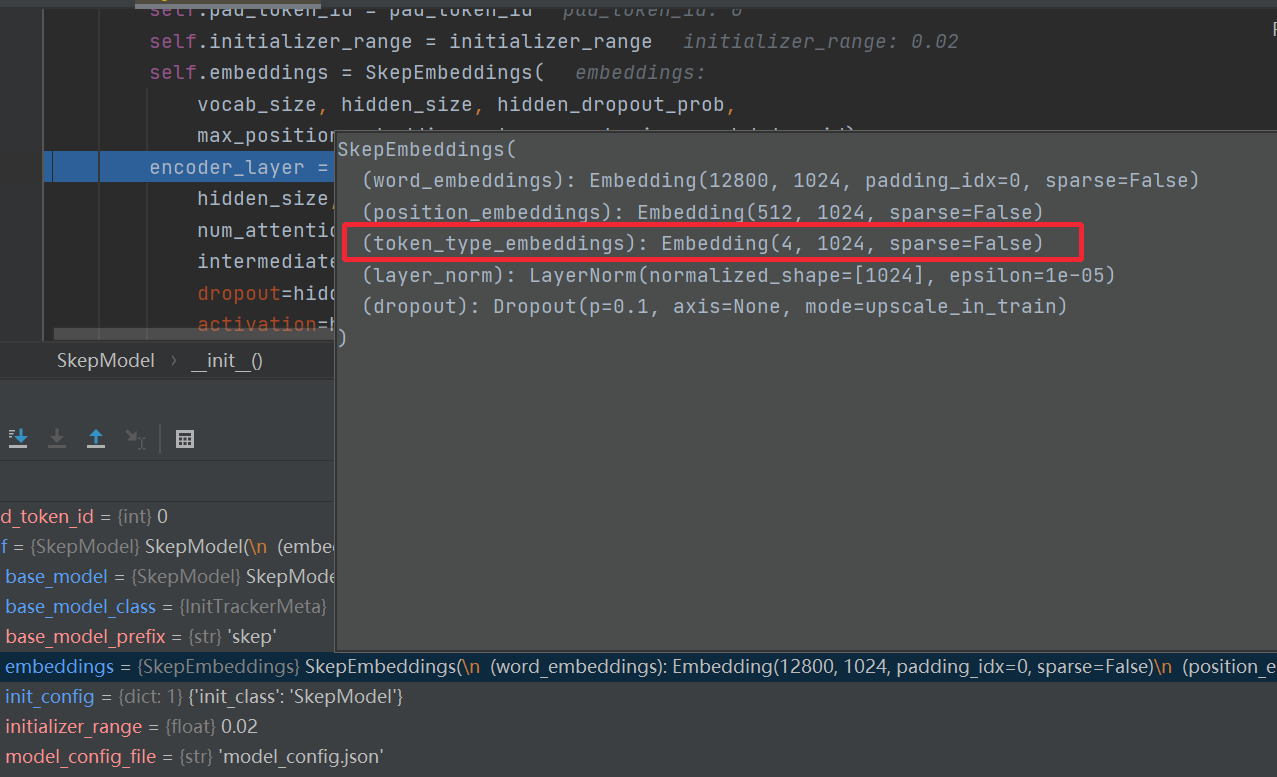
句子的长度是划分成了4个部分
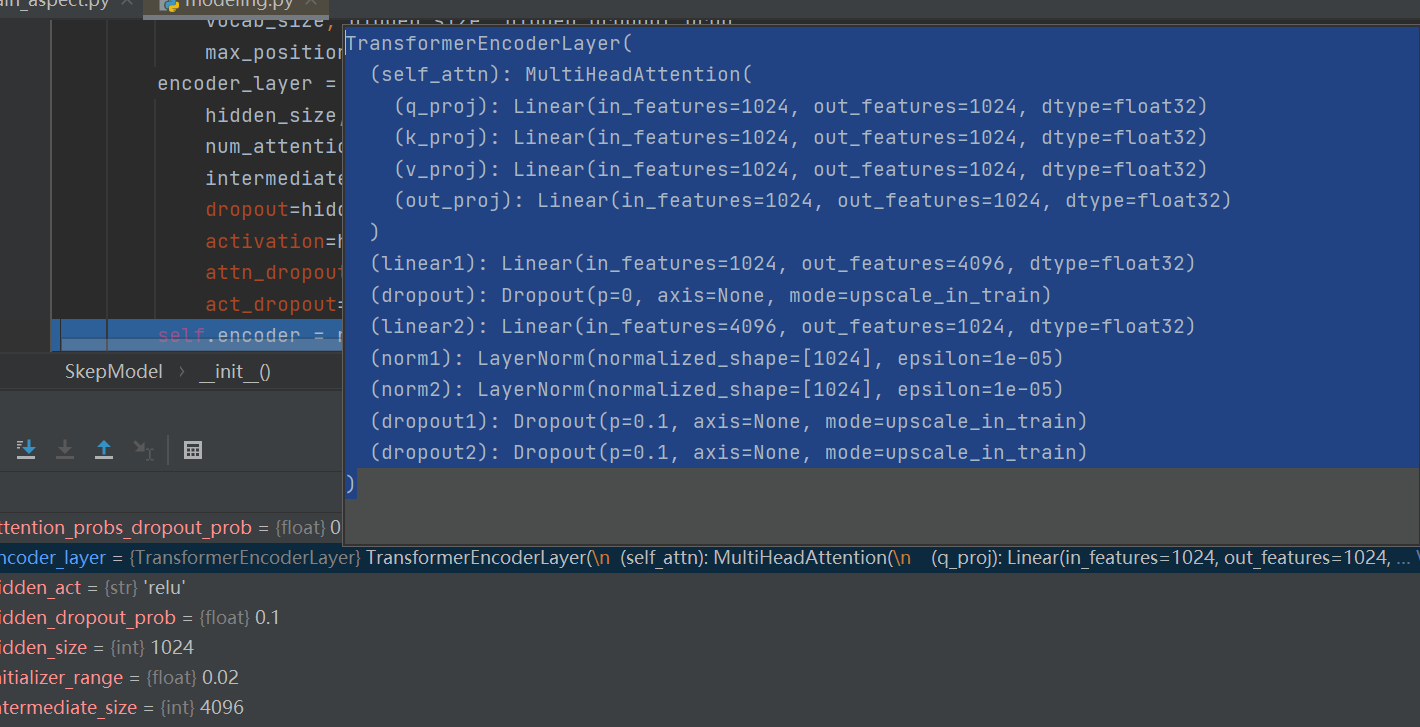
多头注意力线性变换和drop out
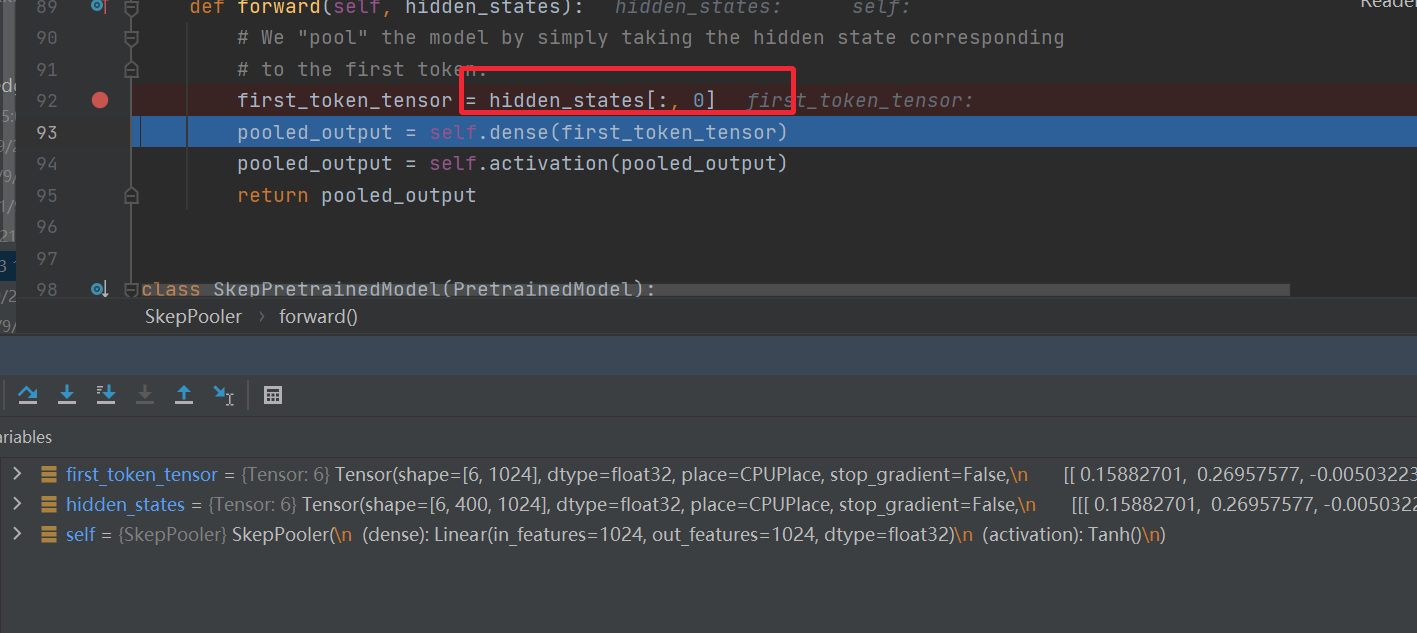
去第一个做分类
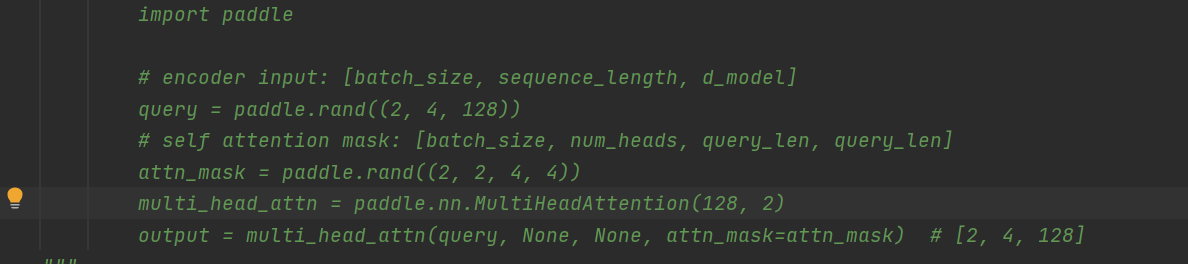
paddle multiattention的案例
def _read(self, filename, split):
"""Reads data"""
with open(filename, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
if idx == 0:
# ignore first line about title
continue
line_stripped = line.strip().split('t')
if not line_stripped:
continue
if split == "test":
yield {"tokens": list(line_stripped[1])}
else:
try:
entity, text = line_stripped[0], line_stripped[1]
start_idx = text.index(entity)
except:
# drop the dirty data
continue
labels = ['O'] * len(text)
labels[start_idx] = "B"
for idx in range(start_idx + 1, start_idx + len(entity)):
labels[idx] = "I"
yield {
"tokens": list(text),
"labels": labels,
"entity": entity
}
几行代码,直接在读取数据的时候,就把要抽取的实体的label转换出来了
最后
以上就是凶狠世界最近收集整理的关于67_sentiment_analysis理论代码理解skep的全部内容,更多相关67_sentiment_analysis理论代码理解skep内容请搜索靠谱客的其他文章。

![[web] k8s 攻略](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)
![[云原生专题-42]:K8S - 核心概念 - placeholder-有状态服务](https://www.shuijiaxian.com/files_image/reation/bcimg17.png)





发表评论 取消回复