4小时学完Python数据分析入门笔记(四)
- 接上文:4小时学完Python数据分析入门笔记(三)
- 写在前面
- Pandas DataFrame
- 创建DataFrame
- 选择(多)行列&(多)单元格
- DataFrame运算
- DataFrame变换
- 小结
接上文:4小时学完Python数据分析入门笔记(三)
写在前面
freecodecamp.org + RMOTR的Python数据分析课的笔记,全视频4小时22分钟。以下内容斜体和(括号)部分仅为我个人的想法或补充,其他文字为中文翻译。分几次发完,转载标明出处。
原视频链接:https://www.youtube.com/watch?v=r-uOLxNrNk8
Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn)
本来在开学前复习一遍的目标没有实现,一转眼都快期中了哈哈。今天有空继续,介绍Pandas DataFrame。
Pandas DataFrame
Pandas DataFrame像Excel,Pandas Series像Excel里的一列。Pandas DataFrame其实应该是接触更多的那种。
创建DataFrame
创建方式和创建Pandas Series很像。
df = pd.DataFrame({
'Population': [35.467, 63.951, 80.94 , 60.665, 127.061, 64.511, 318.523],
'GDP': [
1785387,
2833687,
3874437,
2167744,
4602367,
2950039,
17348075
],
'Surface Area': [
9984670,
640679,
357114,
301336,
377930,
242495,
9525067
],
'HDI': [
0.913,
0.888,
0.916,
0.873,
0.891,
0.907,
0.915
],
'Continent': [
'America',
'Europe',
'Europe',
'Europe',
'Asia',
'Europe',
'America'
]
}, columns=['Population', 'GDP', 'Surface Area', 'HDI', 'Continent'])
df
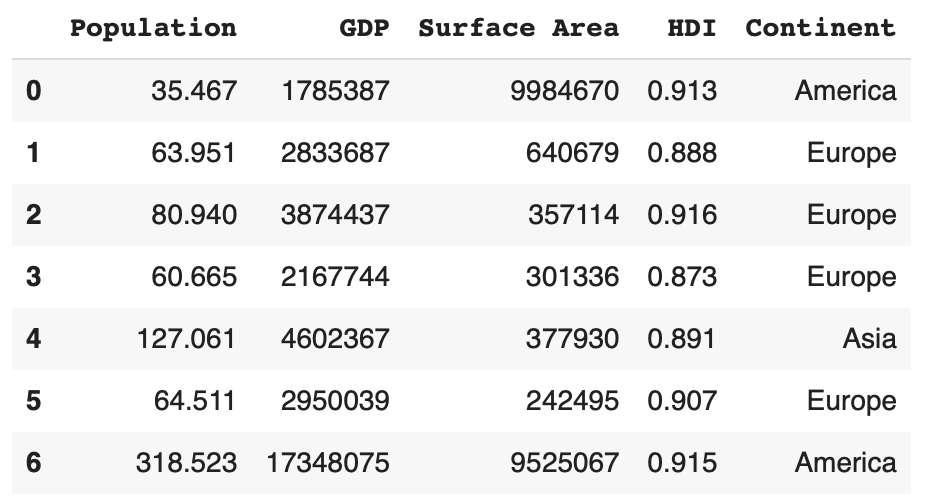
修改默认数字index:
df.index = [
'Canada',
'France',
'Germany',
'Italy',
'Japan',
'United Kingdom',
'United States',
]
df
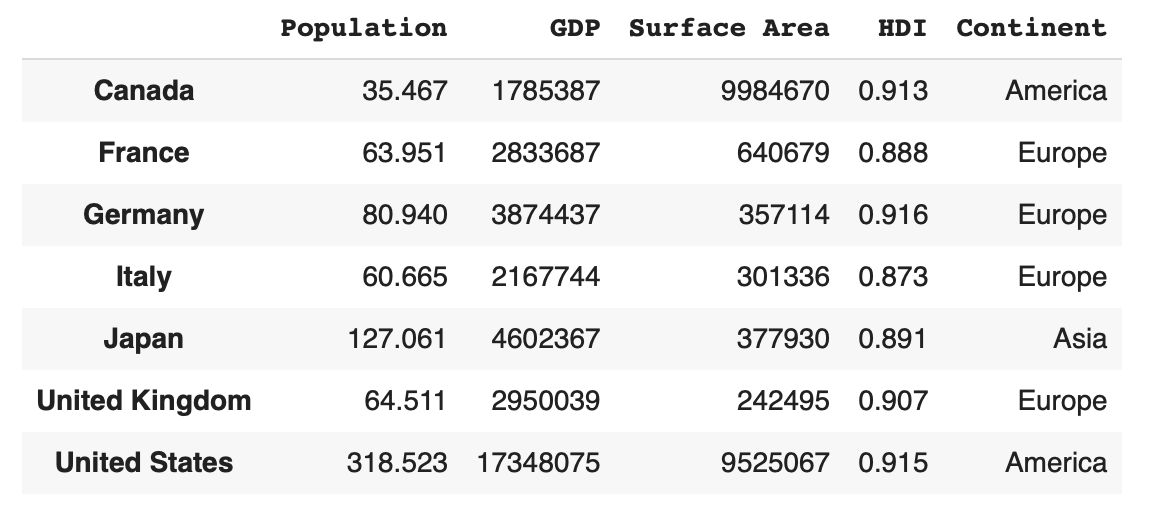
查看行列等基本信息的代码基本和series是一样的:
df.columns
df.index
df.info() # dataframe结构
df.size
df.shape # 类似2Darray
df.describe()
df.dtypes
df.dtypes.value_counts()
# 这里的输出结果就不一一写了
选择(多)行列&(多)单元格
选择一行有两种方法:按index选择用loc,按位置顺序选择用iloc。
df.loc['France']
df.iloc[1]
Population 63.951
GDP 2833687
Surface Area 640679
HDI 0.888
Continent Europe
Name: France, dtype: object
选择一列直接用该列名称。
df['Population']
Canada 35.467
France 63.951
Germany 80.940
Italy 60.665
Japan 127.061
United Kingdom 64.511
United States 318.523
Name: Population, dtype: float64
注意上面三个返回的值都是Pandas Series。
选择多行同样有两种方式:loc和iloc。
df.loc['France': 'Italy']
df.iloc[1:4]
df.iloc[[1,2,3]]
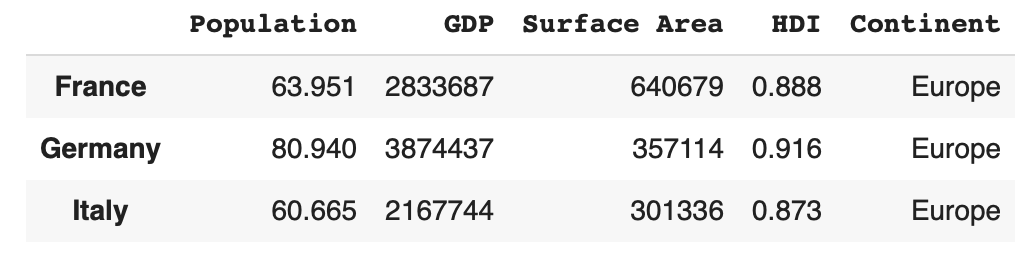
选择多列:
df[['Population', 'GDP']]
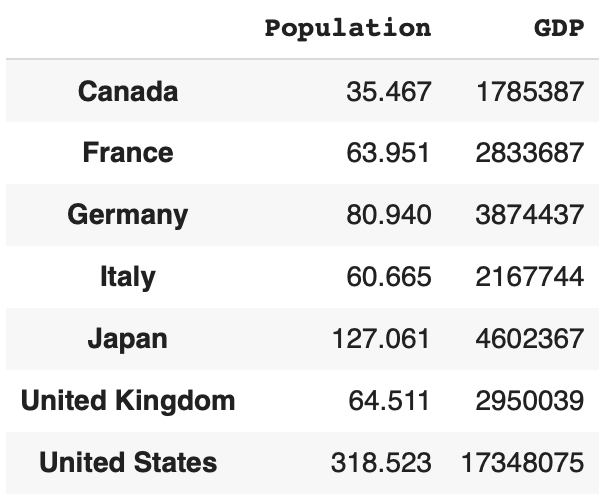
选择n行n列:
df.loc['France': 'Italy', ['Population', 'GDP']]
df.iloc[1:4, [0, 1]]
df.iloc[1:4, 0:2]
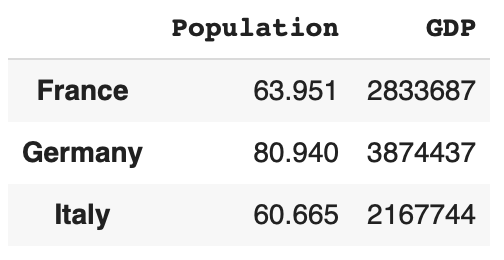
条件选择需要引入布尔运算。
df['Population'] > 70
Canada False
France False
Germany True
Italy False
Japan True
United Kingdom False
United States True
Name: Population, dtype: bool
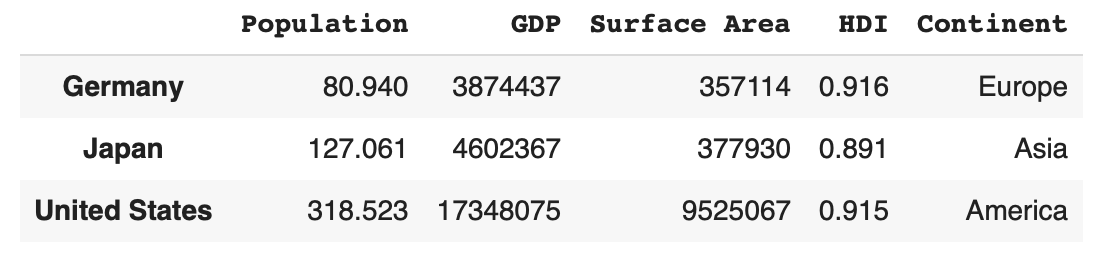
df.loc[df['Population'] > 70]
DataFrame运算
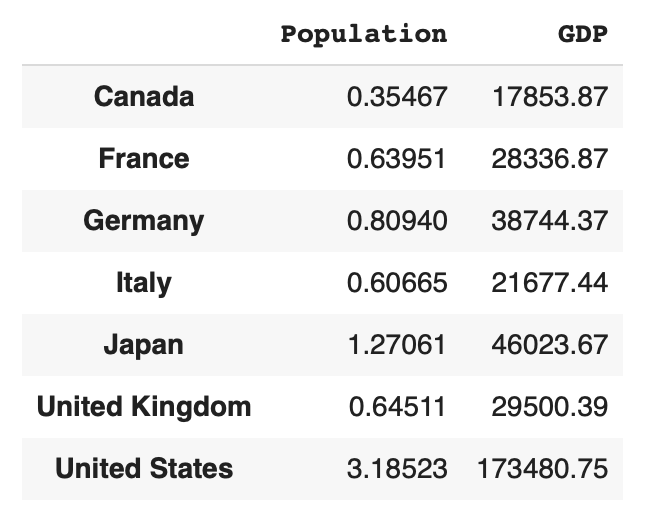
加减乘除的基本运算还是和series一样。
df[['Population', 'GDP']] / 100
DataFrame间运算稍微复杂一点点:
先新建一个pandas series
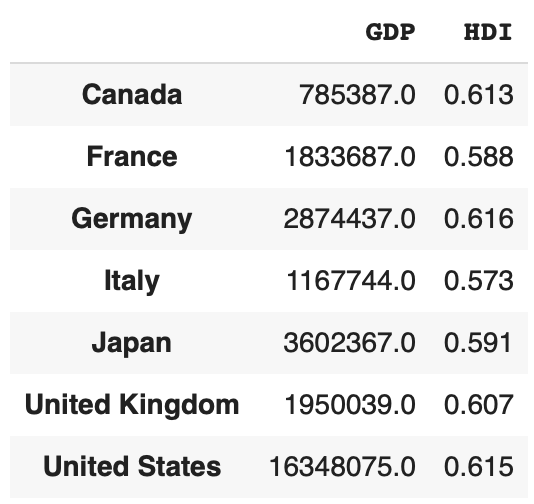
crisis = pd.Series([-1_000_000, -0.3], index=['GDP', 'HDI'])
crisis

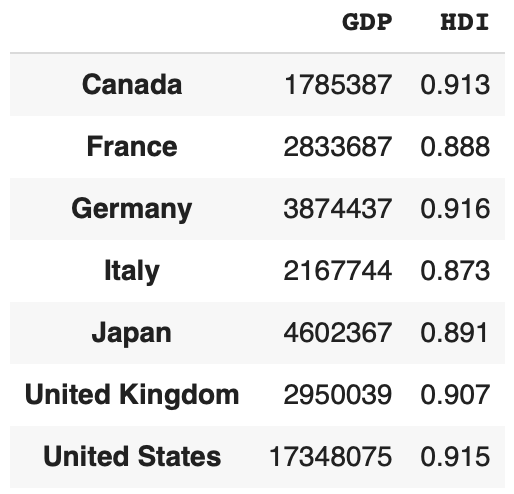
再看看我们想要进行运算的dataframe:
df[['GDP', 'HDI']]
最后进行运算:
df[['GDP', 'HDI']] + crisis
DataFrame变换
添加新的一列:
langs = pd.Series(
['French', 'German', 'Italian'],
index=['France', 'Germany', 'Italy'],
name='Language'
)
df['Language'] = langs
df
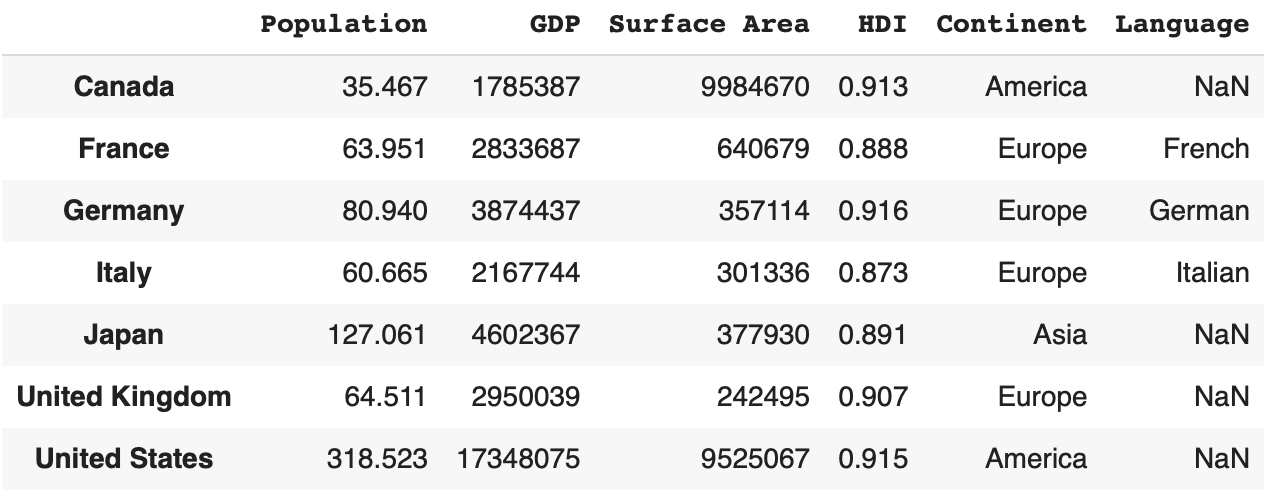
我们没有说明一些值,比如Canada对应Language的值,所以右上角的单元格是NaN。
修改一列的值:
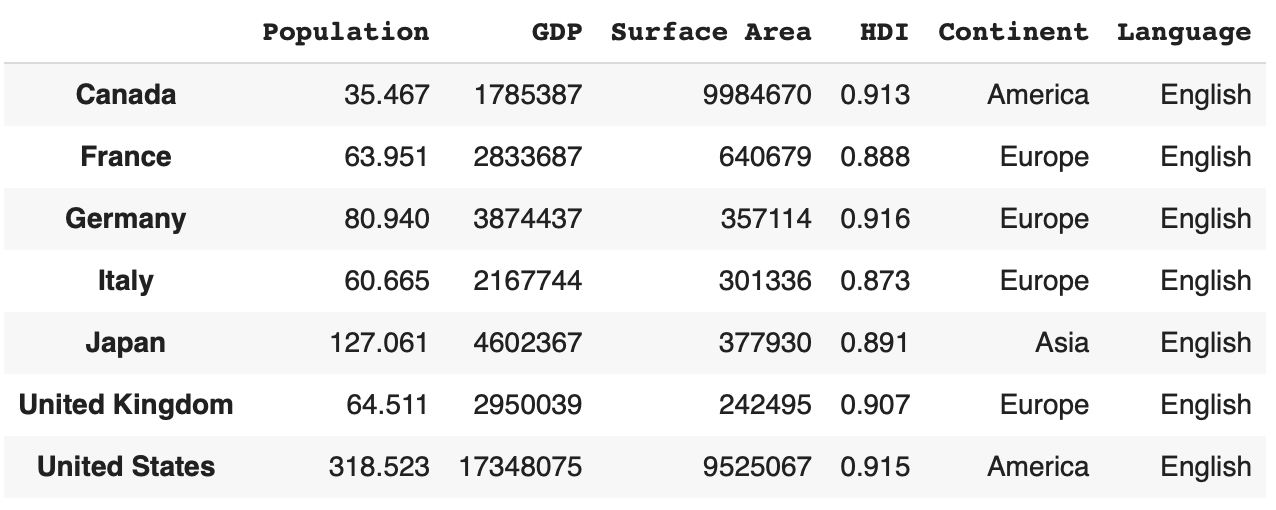
df['Language'] = 'English'
df
修改行名:
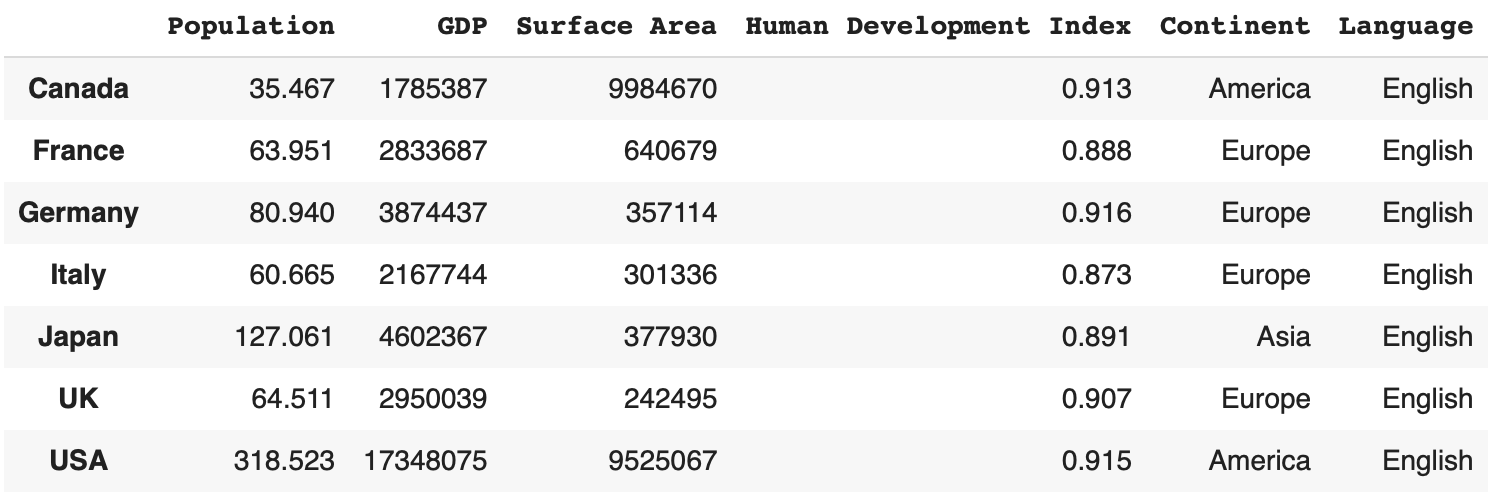
df.rename(
columns={
'HDI': 'Human Development Index',
'Anual Popcorn Consumption': 'APC'
}, index={
'United States': 'USA',
'United Kingdom': 'UK',
'Argentina': 'AR' # 我们其实没有这一行但是没关系不会造成问题
})
统一行名大小写:
df.rename(index=str.upper)
df.rename(index=lambda x: x.lower())
删除行列:
这里要特别注意之前没有指出的一个地方:以下操作都不直接修改df。
df.drop('Canada')
df.drop(['Canada', 'Japan'])
df.drop(columns=['Population', 'HDI'])
df.drop(['Italy', 'Canada'], axis=0) # axis是0代表行
df.drop(['Canada', 'Germany'], axis='rows')
df.drop(['Population', 'HDI'], axis=1) # axis是1代表列
df.drop(['Population', 'HDI'], axis='columns')
但这个操作直接修改df:
df.drop(columns='Language', inplace=True)
稍微注意一下两者区别即可。
小结
介绍了Pandas DataFrame的基本运用。
原视频链接:https://www.youtube.com/watch?v=r-uOLxNrNk8
Data Analysis with Python - Full Course for Beginners (Numpy, Pandas, Matplotlib, Seaborn)
上一篇:4小时学完Python数据分析入门笔记(三)
下一篇:未完待续To be continued…
最后
以上就是务实音响最近收集整理的关于4小时学完Python数据分析入门笔记(四) Data Analysis with Python(Numpy, Pandas, Matplotlib, Seaborn)接上文:4小时学完Python数据分析入门笔记(三)写在前面Pandas DataFrame小结的全部内容,更多相关4小时学完Python数据分析入门笔记(四)内容请搜索靠谱客的其他文章。








发表评论 取消回复