前言
很多游戏中存在大量的点光源(PointLight),环境艺术家为了让游戏模拟现实的氛围,一个场景下放下上千个点光源(PointLight)毫不奇怪。

在上一章中 Directx11进阶教程之Tiled Based Deffered Shading 我们介绍了基于分块的光源剔除技术, 相对于传统的延迟渲染,渲染性能明显更好. 当然, Tiled Based Deffered Shading 也是存在巨大缺点,而图形渲染届的大佬们为了克服 Tiled Based 的算法缺点,又提出了 Cluster Based 的光源剔除算法.
Tiled Based(分块)剔除的缺点
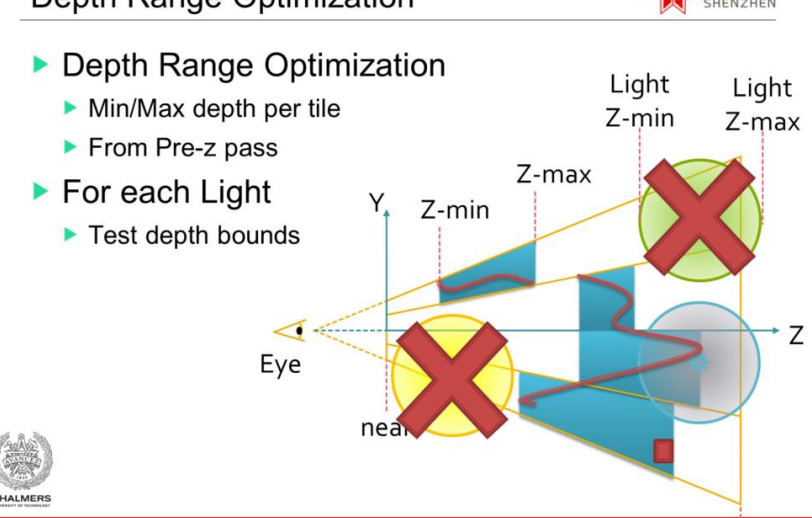
从上图可以看出 Tiled Based剔除光源主要利用每个Tiled的frustum和DepthBounds进行剔除, 然而这里的DepthBounds是存在不稳定因素的, 假设在一个tile里刚好有一个小物体处于这个frustum的最远处, 又有一个物体存在这个frustum的最近处,这时候DepthBounds 就失去了意义, tile里大量的像素就接受无效光源计算, 这种现象被称为 “Depth Discontinuity(深度不连续性)”
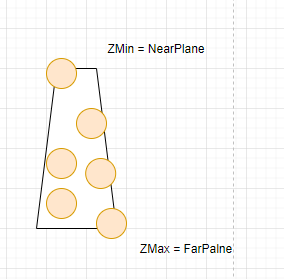
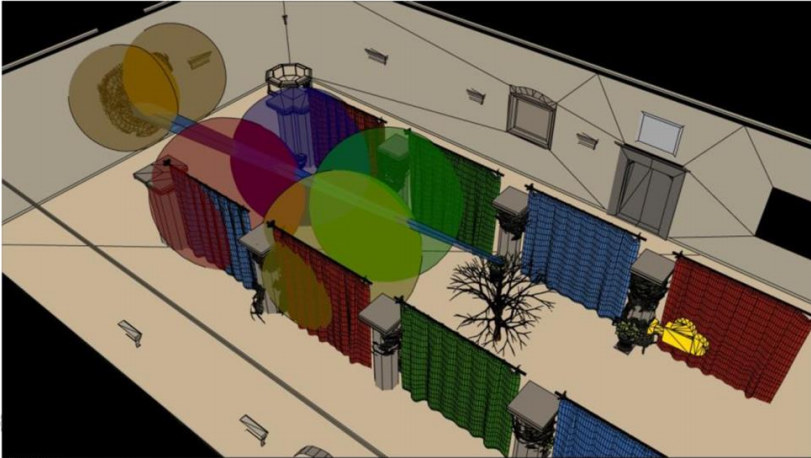
在来一个例子, 如下面两图, 一棵树挡在相机的比较前面, 造成Tile里的Zmin变得非常小, 进而导致部分与狮子头像素完全不相交的点光源参与到狮子头像素的Shading计算,这是一种比较严重的计算浪费,典型的“Depth Discontinuity(深度不连续性)”

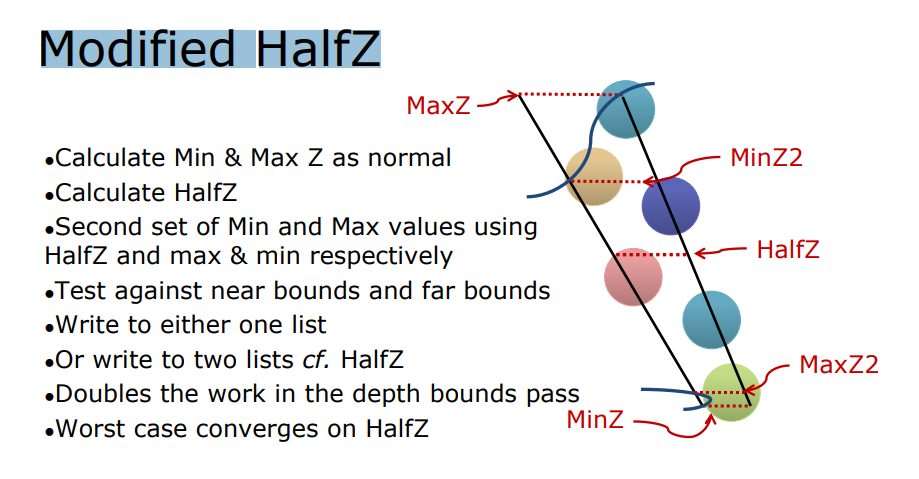
图形渲染工程师们为了解决 tiled based 的 Depth Discontinuity(深度不连续性), 改进 原始的 DepthBounds 提出了部分算法,比如 ”Modified HalfZ“ 引入在原有的Zmax和Zmin进行计算中间多层Z,再进行光源的剔除,一定程度上缓解了 ”Depth Discontinuity“现象
但还是存在下面两个严重缺点:
(1)不是每个游戏都存在PreZ渲染阶段,无法提前拿到像素的Depth,depthBounds完全没用,HalfZ更睡无从谈起
(2) 透明物体的渲染睡没有深度的,深度都是不透明物体的深度, 既然透明物体没有深度,那透明物体的光源剔除就只剩下 frustumCull 而不存在 DepthBoundsCull, 光源剔除效果可能大减.
为了进一步解决上面两个问题, 实时渲染届的大佬们提出了 cluster based(分簇) 剔除光源的概念.
Cluster Based Cull
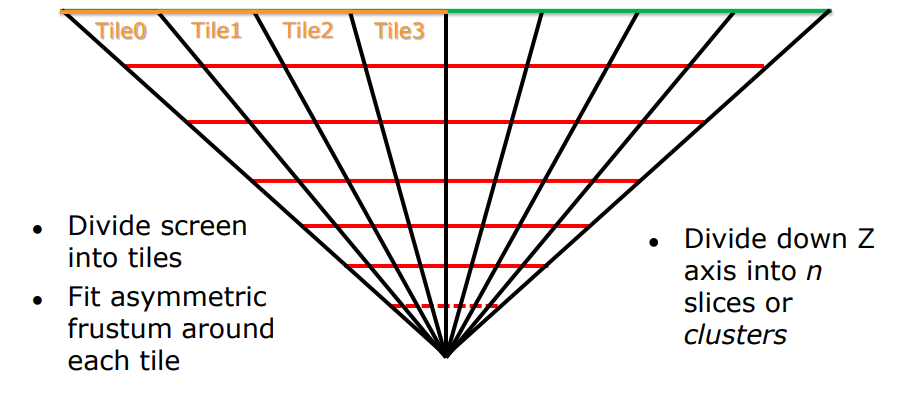
cluster based(分簇) 剔除光源就是引入Z划分的概念,将整个视截体从X,Y,Z方向进行切分, 分成一个个小视截体,如下所示,这里的Z划分固定的,根据FarPlane和NearPlane进行划分,并不依赖PreZ的值.
总体实现思路
(1)游戏开始预先在相机空间分配多个cluster,每个cluster用AABB表示.
(2) 根据PreDepth计算哪些cluster受影响的(存在PreZ可以考虑这一步,剔除无用cluster, 不过实测这一步提升整个光源剔除效率非常有限, 甚至出现剔除效率降低的情况).
(3) 遍历所有的cluster, 并计算影响每个cluster的光源集合.
(4) 进行Shading, 根据像素的ScreenPos.xy 和PosViewZ 计算像素处于哪个cluster, 然后取出光源集合进行Shading计算.
实现步骤
(1)游戏开始预先在相机空间分配多个cluster,每个cluster用AABB表示-------必要步骤
这里X,Y的划分和tileShading是一样的,但是Z的划分存在多种方案.
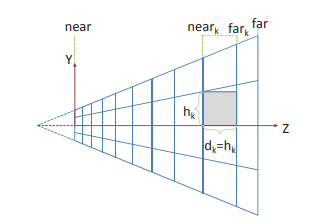
Ola Olsson的方案:
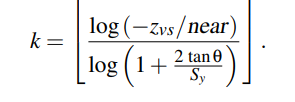
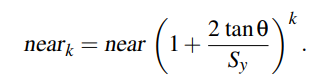
Doom (Id software) 的方案:
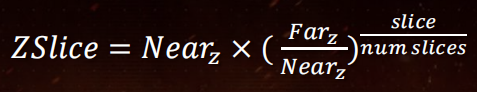
这里划分cluster采用了DOOM的方案进行计算,并且划分数量为 16 X 12 X 24 = 4608
struct Cluter
{
float4 minPoint;
float4 maxPoint;
};
cbuffer CBCommon:register(b0)
{
float ScreenWidth;
float ScreenHeight;
float farPlane;
float nearPlane;
float4 tileSizes;
};
cbuffer CBMatrix:register(b1)
{
matrix View;
matrix ProjInv;
};
float4 ConvertNDCToView(float4 p)
{
p = mul(p, ProjInv);
p /= p.w;
return p;
}
//Screen-NDC-View
float4 ScreenToView(float4 screenPos)
{
float2 tex = screenPos.xy / float2(ScreenWidth, ScreenHeight);
// XYndc = (tex - float2(0.5, 0.5)) * (2, -2)
float4 ndc = float4(tex.x * 2.0 - 1.0, 1.0 - 2.0 * tex.y, screenPos.z, screenPos.w);
return ConvertNDCToView(ndc);
}
//相似三角形求解
float3 LineIntersectionToZPlane(float3 a, float3 b, float z)
{
float3 normal = float3(0.0, 0.0, 1.0);
float3 ab = b - a;
float t = (z - dot(normal, a)) / dot(normal, ab);
float3 result = a + t * ab;
return result;
}
RWStructuredBuffer<Cluter> ClusterList : register(u0);
[numthreads(1, 1, 1)]
void CS(
uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID,
uint groupIndex : SV_GroupIndex,
uint3 dispatchThreadId : SV_DispatchThreadID)
{
const float3 eyePos = float3(0.0, 0.0, 0.0);
uint tileSizePx = (uint)tileSizes.w;
uint tileIndex = groupId.x + groupId.y * (uint)tileSizes.x + groupId.z * (uint)tileSizes.x * (uint)tileSizes.y;
//Calculate the min and max point in screen, far plane, near plane exit error(forever zero)
float4 maxPointSs = float4(float2(groupId.x + 1, groupId.y + 1) * tileSizePx, 1.0, 1.0);
float4 minPointSs = float4(groupId.xy * tileSizePx, 1.0, 1.0);
//MinPoint and MaxPoint of the cluster in view space(nearest plane, ndc pos.w = 0.0)
float3 maxPointVs = ScreenToView(maxPointSs).xyz;
float3 minPointVs = ScreenToView(minPointSs).xyz;
//Near and far values of the cluster in view space, the split cluster method from siggraph 2016 idtech6
float tileNear = nearPlane * pow(farPlane / nearPlane, groupId.z / tileSizes.z);
float tileFar = nearPlane * pow(farPlane / nearPlane, (groupId.z + 1) / tileSizes.z);
//find cluster min/max 4 point in view space
float3 minPointNear = LineIntersectionToZPlane(eyePos, minPointVs, tileNear);
float3 minPointFar = LineIntersectionToZPlane(eyePos, minPointVs, tileFar);
float3 maxPointNear = LineIntersectionToZPlane(eyePos, maxPointVs, tileNear);
float3 maxPointFar = LineIntersectionToZPlane(eyePos, maxPointVs, tileFar);
float3 minPointAABB = min(min(minPointNear, minPointFar), min(maxPointNear, maxPointFar));
float3 maxPointAABB = max(max(minPointNear, minPointFar), max(maxPointNear, maxPointFar));
ClusterList[tileIndex].minPoint = float4(minPointAABB, 1.0);
ClusterList[tileIndex].maxPoint = float4(maxPointAABB, 1.0);
}
(2) 根据PreDepth计算哪些cluster是无效的(不存在任何平面空间像素)----非必要步骤
存在PreZ可以考虑这一步,剔除无用cluster。不过实测这一步提升整个光源剔除效率非常有限, 甚至出现剔除效率降低的情况. 透明物体的cluster light cull可以省略这一步.
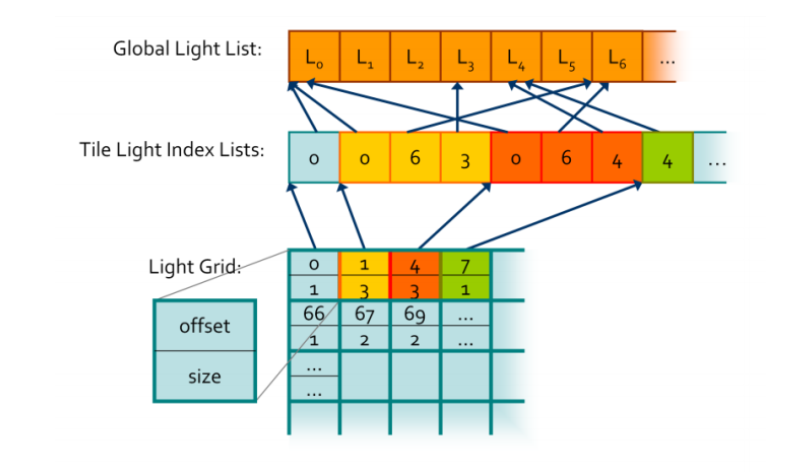
(3) 遍历所有的cluster, 计算影响每个cluster的光源集合, 并用全局索引偏移表和全局光源索引表来记录
这里为了简化数据结构, 全局索引偏移表和全局光源索引表 都是一维数组, 全局索引偏移表元素记录了每个cluster的的光源数量和每个cluster的的光源在全局光源索引表的Index偏移.
#define THREAD_GROUD_X 16
#define THREAD_GROUD_Y 12
#define THREAD_GROUD_Z 2
#define GROUD_THREAD_TOTAL_NUM THREAD_GROUD_X * THREAD_GROUD_Y * THREAD_GROUD_Z
struct Cluter
{
float4 minPoint;
float4 maxPoint;
};
struct LightGrid
{
float offset;
float count;
};
struct PointLight
{
float3 pos;
float3 color;
float radius;
float4 attenuation;
};
cbuffer CBCommon:register(b0)
{
float ScreenWidth;
float ScreenHeight;
float lightCount;
};
cbuffer CBMatrix:register(b1)
{
matrix View;
matrix ProjInv;
};
StructuredBuffer<PointLight> PointLights : register(t0);
RWStructuredBuffer<Cluter> ClusterList : register(u0);
RWStructuredBuffer<LightGrid> LightGridList : register(u1);
RWStructuredBuffer<float> GlobalLightIndexList : register(u2);
RWStructuredBuffer<uint> globalIndexCount: register(u3);
RWStructuredBuffer<float> ClusterActiveList: register(u4);
//groupshared PointLight sharedLights[GROUD_THREAD_TOTAL_NUM];
float GetSqdisPointAABB(float3 pos, uint cluterIndex)
{
float sqDistance = 0.0;
Cluter cluter = ClusterList[cluterIndex];
for (int i = 0; i < 3; ++i)
{
float v = pos[i];
if (v < cluter.minPoint[i])
{
float diff = cluter.minPoint[i] - v;
sqDistance += diff * diff;
}
if (v > cluter.maxPoint[i])
{
float diff = v - cluter.maxPoint[i];
sqDistance += diff * diff;
}
}
return sqDistance;
}
bool TestSphereAABB(uint lightIndex, uint cluterIndex)
{
PointLight light = PointLights[lightIndex];
//PointLight light = sharedLights[lightIndex];
float radius = light.radius;
float3 spherePos = mul(float4(light.pos, 1.0), View).xyz;
float sqDistance = GetSqdisPointAABB(spherePos, cluterIndex);
return sqDistance <= (radius * radius);
}
[numthreads(THREAD_GROUD_X, THREAD_GROUD_Y, THREAD_GROUD_Z)]
void CS(
uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID,
uint groupIndex : SV_GroupIndex,
uint3 dispatchThreadId : SV_DispatchThreadID)
{
uint threadCount = GROUD_THREAD_TOTAL_NUM;
uint lightCountInt = (uint)lightCount;
uint passCount = (lightCountInt + threadCount - 1) / threadCount;
uint clusterIndex = groupIndex + threadCount * groupId.z;
uint visibleLightCount = 0;
//Unvalid Cluster
if (ClusterActiveList[clusterIndex] == 0.0)
{
LightGridList[clusterIndex].offset = (float)globalIndexCount[0];
LightGridList[clusterIndex].count = 0.0;
return;
}
//one cluster max light num <= GROUD_THREAD_TOTAL_NUM
uint visibleLightIndexs[GROUD_THREAD_TOTAL_NUM];
for (uint passIndex = 0; passIndex < passCount; ++passIndex)
{
uint lightIndex = passIndex * threadCount + groupIndex;
//sharedLights[groupIndex] = PointLights[lightIndex];
//GroupMemoryBarrierWithGroupSync();
for (uint light = 0; light < threadCount; ++light)
{
uint lightRealIndex = light + passIndex * threadCount;
if (lightRealIndex < lightCountInt && TestSphereAABB(light, clusterIndex))
{
visibleLightIndexs[visibleLightCount] = lightRealIndex;
visibleLightCount += 1;
}
}
}
//We want all thread groups to have completed the light tests before continuing
GroupMemoryBarrierWithGroupSync();
uint offset;
InterlockedAdd(globalIndexCount[0], visibleLightCount, offset);
for (uint i = 0; i < visibleLightCount; ++i)
{
GlobalLightIndexList[offset + i] = visibleLightIndexs[i];
}
LightGridList[clusterIndex].offset = (float)offset;
LightGridList[clusterIndex].count = (float)visibleLightCount;
}
(4) 进行Shading, 根据像素的ScreenPos.xy 和PosViewZ 计算像素处于哪个cluster, 然后取出光源集合进行Shading计算.
#include "BRDF.fx"
struct LightGrid
{
float offset;
float count;
};
struct PointLight
{
float3 pos;
float3 color;
float radius;
float4 attenuation;
};
Texture2D WorldPosTex:register(t0);
Texture2D WorldNormalTex:register(t1);
Texture2D SpecularRoughMetalTex:register(t2);
Texture2D AlbedoTex:register(t3);
Texture2D DepthTex:register(t4);
SamplerState clampLinearSample:register(s0);
RWStructuredBuffer<LightGrid> LightGridList : register(u1);
RWStructuredBuffer<float> GlobalLightIndexList : register(u2);
RWStructuredBuffer<PointLight> PointLightList : register(u3);
cbuffer CBCommon:register(b0)
{
float3 cameraPos;
float4 tileSizes;
float ScreenWidth;
float ScreenHeight;
float2 cluserFactor;
float farPlane;
float nearPlane;
};
struct VertexIn
{
float3 Pos:POSITION;
float2 Tex:TEXCOORD;
};
struct VertexOut
{
float4 Pos:SV_POSITION;
float2 Tex:TEXCOORD0;
};
VertexOut VS(VertexIn ina)
{
VertexOut outa;
outa.Pos = float4(ina.Pos.xy, 1.0, 1.0);
outa.Tex = ina.Tex;
return outa;
}
float DepthBufferConvertToLinear(float depth)
{
float a = 1.0 / (nearPlane - farPlane);
return (nearPlane*farPlane * a) / (depth + farPlane * a);
};
float4 PS(VertexOut outa) : SV_Target
{
float2 uv = outa.Tex;
float4 color = float4(0.0, 0.0, 0.0, 1.0);
float2 screenPos = float2(uv.x * ScreenWidth, uv.y * ScreenHeight);
float depth = DepthTex.Sample(clampLinearSample, outa.Tex).r;
float viewZ = DepthBufferConvertToLinear(depth);
uint clusterZ = uint(max(log2(viewZ) * cluserFactor.x + cluserFactor.y, 0.0));
uint3 clusters = uint3(uint(screenPos.x / tileSizes.w), uint(screenPos.y / tileSizes.w), clusterZ);
uint clusterIndex = clusters.x + clusters.y * (uint)tileSizes.x + clusters.z * (uint)tileSizes.x * (uint)tileSizes.y;
uint lightOffset = (uint)LightGridList[clusterIndex].offset;
uint lightCount = (uint)LightGridList[clusterIndex].count;
//G-Buffer-Pos(浪费1 float)
float3 worldPos = WorldPosTex.Sample(clampLinearSample, uv).xyz;
//G-Buffer-Normal(浪费1 float)
float3 worldNormal = WorldNormalTex.Sample(clampLinearSample, uv).xyz;
worldNormal = normalize(worldNormal);
float3 albedo = AlbedoTex.Sample(clampLinearSample, uv).xyz;
//G-Buffer-Specual-Rough-Metal(浪费1 float)
float3 gBufferAttrbite = SpecularRoughMetalTex.Sample(clampLinearSample, uv).xyz;
float specular = gBufferAttrbite.x;
float roughness = gBufferAttrbite.y;
float metal = gBufferAttrbite.z;
for (uint i = 0; i < lightCount; ++i)
{
uint lightIndex = GlobalLightIndexList[lightOffset + i];
PointLight light = PointLightList[lightIndex];
float3 lightPos = light.pos;
float3 lightColor = light.color;
float4 attenuation = light.attenuation;
float3 pixelToLightDir = lightPos - worldPos;
float distance = length(pixelToLightDir);
float3 L = normalize(pixelToLightDir);
float3 V = normalize(cameraPos - worldPos);
float3 H = normalize(L + V);
float attenua = 1.0 / (attenuation.x + attenuation.y * distance + distance * distance * attenuation.z);
float3 radiance = lightColor * attenua;
//f(cook_torrance) = D* F * G /(4 * (wo.n) * (wi.n))
float D = DistributionGGX(worldNormal, H, roughness);
float G = GeometrySmith(worldNormal, V, L, roughness);
float3 fo = GetFresnelF0(albedo, metal);
float cosTheta = max(dot(V, H), 0.0);
float3 F = FresnelSchlick(cosTheta, fo);
float3 ks = F;
float3 kd = float3(1.0, 1.0, 1.0) - ks;
kd *= 1.0 - metal;
float3 dfg = D * G * F;
float nDotl = max(dot(worldNormal, L), 0.0);
float nDotv = max(dot(worldNormal, V), 0.0);
float denominator = 4.0 * nDotv * nDotl;
float3 specularFactor = dfg / max(denominator, 0.001);
//specular贴图相当于specular遮罩
color.xyz += (kd * albedo / PI + specularFactor * specular) * radiance * nDotl * 2.2;
}
return color;
}上面大概是 ClusterBasedDefferedRender 的实现方式。透明物体的也非常适用ClusterBased的办法,用的ClusterBasedForwardRender
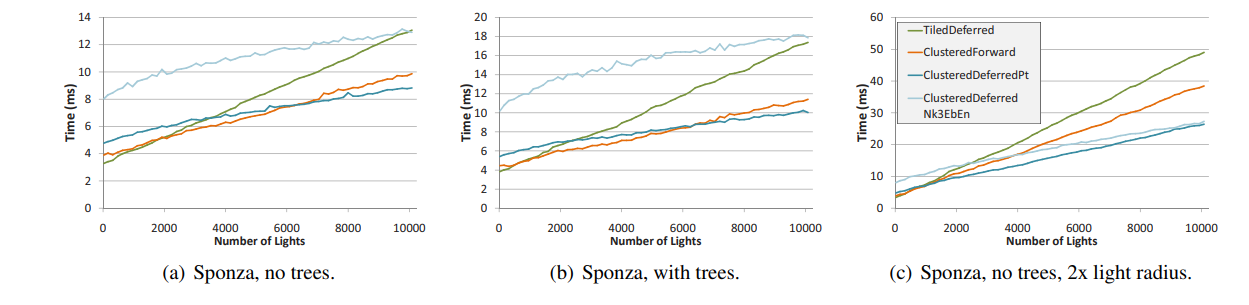
渲染结果

各种RenderPipeline的功能和性能对比
下面的 ”no“并非代表不能, 而是代表 ”困难性能消耗比常规大的意思“, 从这两三年的发展来看,总体上 ClusterBasedForwardRender 是业界的未来,综合的优点太诱人了。

项目源码链接
https://github.com/2047241149/SDEngine
参考资料
【1】http://www.cse.chalmers.se/~uffe/clustered_shading_preprint.pdf
【2】https://ubm-twvideo01.s3.amazonaws.com/o1/vault/gdc2015/presentations/Thomas_Gareth_Advancements_in_Tile-Based.pdf?tdsourcetag=s_pctim_aiomsg
【3】http://www.humus.name/Articles/PracticalClusteredShading.pdf
【4】https://www.slideshare.net/TiagoAlexSousa/siggraph2016-the-devil-is-in-the-details-idtech-666?next_slideshow=1
【5】https://newq.net/dl/pub/SA2014Practical.pdf
【6】 http://www.aortiz.me/2018/12/21/CG.html
最后
以上就是炙热云朵最近收集整理的关于Directx11进阶教程之Cluster Based Deffered Shading的全部内容,更多相关Directx11进阶教程之Cluster内容请搜索靠谱客的其他文章。








发表评论 取消回复