活动地址:CSDN21天学习挑战赛
目录
- 一、Python操作PDF的库有很多
- 二、pdflumber作为案例讲解使用
- 2、安装配置
- 2、加载PDF
- 3、读取pdf文档信息
- 1)读取pdf文档信息
- 2)打印pdf文档总页码
- 4、pdfplumber.page类
- 1)读取pdf的数据(第一页)
- 2)读取第一页数据
- 3)将数据写入到Excel表中
- 4)读取完整pdf文档写入到Excel中
- 5)多pdf文本写入到Excel表中
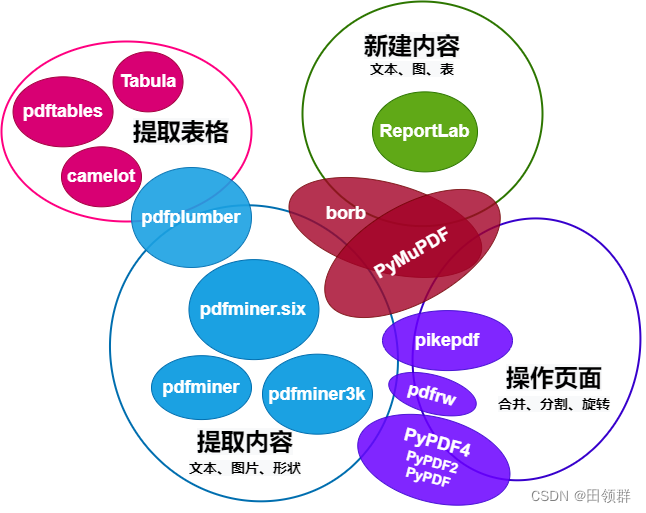
一、Python操作PDF的库有很多
- 几大库对比图
二、pdflumber作为案例讲解使用
pdfplumber及其依赖pdfminer.six专注PDF内容提取,例如文本(位置、字体及颜色等)和形状(矩形、直线、曲线),前者还有解析表格的功能。
## 1、优缺点
- 优点:
对于文字的解析非常优秀,没有发现错字漏字的情况
对于普通表格的解析也很棒
- 缺点:
对于表格分页的情况处理很弱
合并单元格的表格解析会不够理想,但是效果还是要比tabula好。
2、安装配置
pip install pdfplumber
结果:
2、加载PDF
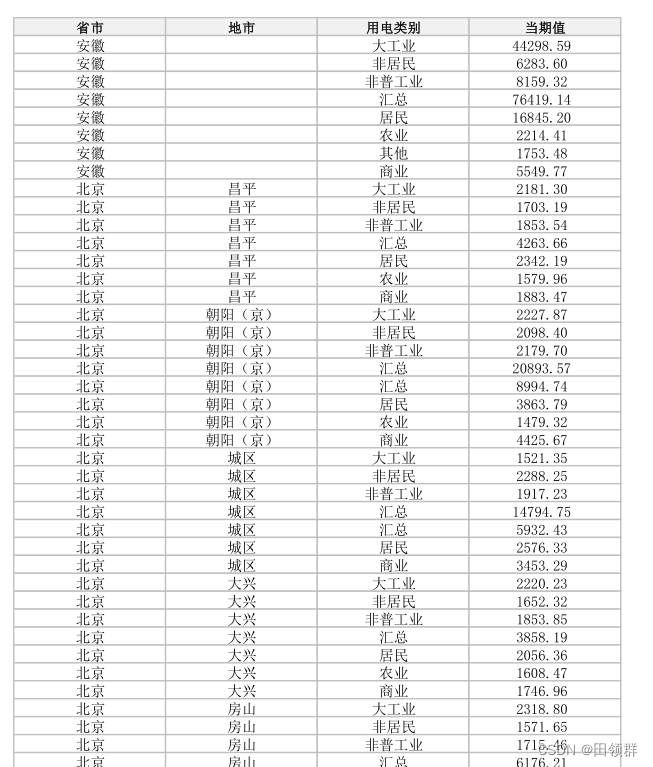
- pdf样式:
资源下载地址(0积分下载):https://download.csdn.net/download/walykyy/86398438 - 读取pdf文档
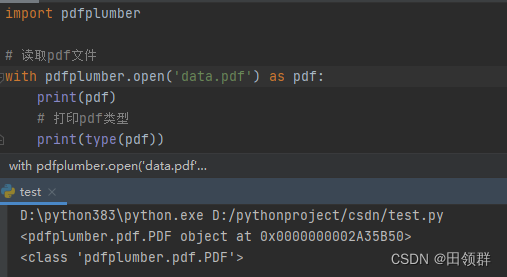
import pdfplumber
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
print(pdf)
# 打印pdf类型
print(type(pdf))
3、读取pdf文档信息
1)读取pdf文档信息
| 属性 | 描述 |
|---|---|
.metadata | 从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages | 一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息。 |
import pdfplumber
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
#读取文档信息
print(pdf.metadata)
结果:
{'Author': 'Tian', 'CreationDate': "D:20220811142408+08'00'", 'ModDate': "D:20220811142408+08'00'", 'Producer': 'Microsoft® Excel® 2016', 'Creator': 'Microsoft® Excel® 2016'}
2)打印pdf文档总页码
| 属性 | 说明 |
|---|---|
.metadata | 元祖的形式获取pdf文档的相关信息 |
.pages | 获取pdf的页码 |
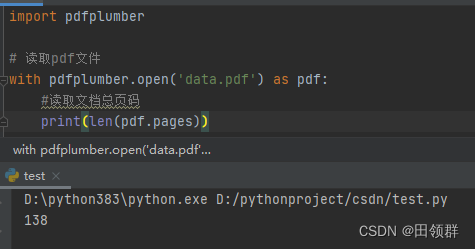
import pdfplumber
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
#读取文档总页码
print(len(pdf.pages))
4、pdfplumber.page类
是pdfplumber的核心
| 属性 | 描述 |
|---|---|
.page_number | 页码顺序,从第一页的1开始,第二页为2,依此类推 |
.width | 页面宽度 |
.heigh | 页面高度 |
.objects,.chars,.lines,.rects,.curves,.figures,.images | 这些属性中的每一个都是一个列表,并且每个列表针对嵌入面上的每个此类对象包含一个字典。 有关更多详细信息,请参见下面的"对象(Object)" |
- 常用方法
| 方法名 | 说明 |
|---|---|
.crop(bounding_box) | 返回裁剪后的页面,该bouding_box(边界框)应表示为具有值(x0, top, x1, bottom)的4元组。 裁剪后的页面保留了至少部分位于边界框内的对象。 如果对象仅部分落在该框内,则也会被涵盖。 |
.within_bbox(bounding_box) | 和.crop相似,但是只会包含完全在bounding_box内的部分。 |
.filter(test_function) | 返回仅包含.objects的页面版本,该对象的test_function(obj)返回True。 |
.extract_text(x_tolerance=0, y_tolerance=0) | 将页面的所有字符对象整理到一个字符串中。若其中一个字符的x1与下一个字符的x0之差大于x_tolerance,则添加空格。若其中一个字符的doctop与下一个字符的doctop之差大于y_tolerance,则添加换行符。 |
.extract_words(x_tolerance=0, y_tolerance=0, horizontal_ltr=True, vertical_ttb=True) | 返回所有单词外观及其边界框的列表。字词被认为是字符序列,其中(对于“直立”字符)一个字符的x1和下一个字符的x0之差小于或等于x_tolerance,并且一个字符的doctop和下一个字符的doctop小于或等于y_tolerance。对于非垂直字符也采用类似的方法,但是要测量它们之间的垂直距离,而不是水平距离。参数horizontal_ltr和vertical_ttb指示是否应从左到右(对于水平单词)从上到下(对于垂直单词)读取字词。 |
.extract_tables(table_settings) | 从页面中提取表格数据。 |
.to_image(**conversion_kwargs) | 返回PageImage类的实例。 |
1)读取pdf的数据(第一页)
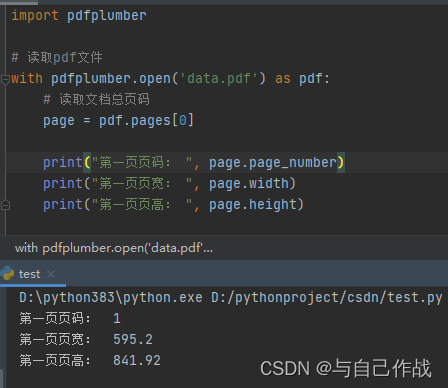
import pdfplumber
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
# 读取文档总页码
page = pdf.pages[0]
print("第一页页码: ", page.page_number)
print("第一页页宽: ", page.width)
print("第一页页高: ", page.height)
2)读取第一页数据
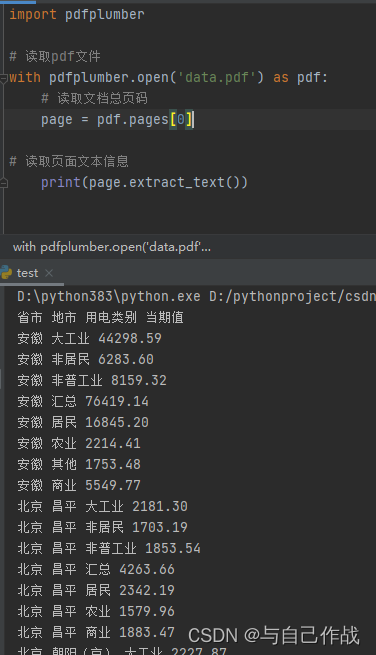
3)将数据写入到Excel表中
import pdfplumber
import xlwt
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
# 读取文档总页码
page = pdf.pages[0]
# 读取表格数据
table = page.extract_table()
# 创建Excel文本
work_book = xlwt.Workbook(encoding='utf-8')
# 新建sheet表格
work_sheet = work_book.add_sheet('sheet1')
# 定义列名
col = table[0]
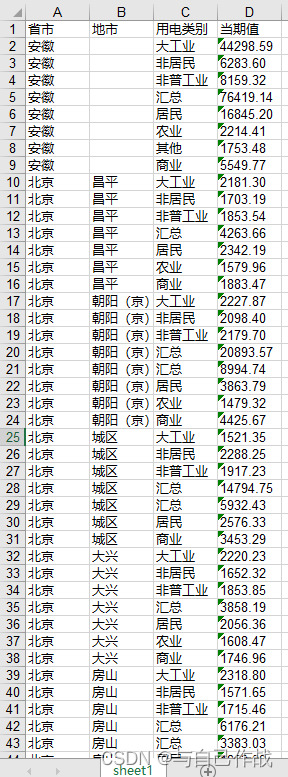
#将col写入到表单第一行,['省市', '地市', '用电类别', '当期值']
for i in range(0, len(col)):
work_sheet.write(0, i, col[i])
#将数据写入到sheet表中
for i in range(0, len(table[1:])):
data = table[1:][i]
for j in range(0, len(col)):
work_sheet.write(i + 1, j, data[j])
#保存
work_book.save('test2.xls')
结果:
4)读取完整pdf文档写入到Excel中
import pdfplumber
import xlwt
# 读取pdf文件
with pdfplumber.open('data.pdf') as pdf:
# 读取文档总页码
pages = pdf.pages
# 定义一个数组
item = []
for page in pages:
# 读取表格数据
table = page.extract_table()
for i in table:
item.append(i)
# 创建Excel文本
work_book = xlwt.Workbook(encoding='utf-8')
# 新建sheet表格
work_sheet = work_book.add_sheet('sheet1')
# 定义列名
col = item[0]
# 将col写入到表单第一行,['省市', '地市', '用电类别', '当期值']
for i in range(0, len(col)):
work_sheet.write(0, i, col[i])
# 将数据写入到sheet表中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col)):
work_sheet.write(i + 1, j, data[j])
# 保存
work_book.save('test2.xls')
5)多pdf文本写入到Excel表中
import pdfplumber
import xlwt
import os
# 读取文件夹路径
file_dir = r'D:pythonprojectfile'
file_list = []
# 循环读取路径pdf文件
for files in os.walk(file_dir):
# print(files) ('D:\pythonproject\file', [], ['1.pdf', '2.pdf', '3.pdf'])
for file in files[2]:
# 对文件名切割,以.作为切割符;拼接地址存入file_list中
if file.split('.')[1] == 'pdf' or file.split('.')[1] == 'PDF':
file_list.append(file_dir + '\' + file)
# 定义一个临时表存放数据
item = []
# 读取pdf文件
for file_page in file_list:
with pdfplumber.open(file_page) as pdf:
for page in pdf.pages:
for i in page.extract_table():
item.append(i)
# 创建Excel文本
work_book = xlwt.Workbook(encoding='utf-8')
# 新建sheet表格
work_sheet = work_book.add_sheet('sheet1')
# 定义列名
col = item[0]
# 将col写入到表单第一行,['省市', '地市', '用电类别', '当期值']
for i in range(0, len(col)):
work_sheet.write(0, i, col[i])
# 将数据写入到sheet表中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col)):
work_sheet.write(i + 1, j, data[j])
# 保存
work_book.save('test3.xls')
注意:pdf文档转换的时候一定要弄好,Excel转pdf时候转换成功,但是里面有乱码导致一直读不出来报错,搞了好久
最后
以上就是哭泣雪糕最近收集整理的关于Python 读pdf数据写入Excel表中一、Python操作PDF的库有很多二、pdflumber作为案例讲解使用的全部内容,更多相关Python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复