Hadoop基本架构
什么是Hadoop?
Hadoop架构是一个开源的、基于Java的编程框架,设计用于跨电脑集群来处理大数据。Hadoop架构管理多个节点之间的数据传输,确保即使有一个节点坏掉了,系统仍然保有适当的功能。
Hadoop架构有两个主要的组件:分布式文件系统和MapReduce引擎。主要的分布式文件系统是Hadoop分布式文件系统(HDFS),这里存储着程序。MapReduce引擎是用于执行程序的一个框架。
如果说Hadoop可以召唤出任何一个开发人员脸上的微笑,无论他是一个多么严肃的人,这并不奇怪。该框架名字的由来因其创始人儿子的一个大象玩具而得名。
Hadoop的历史及特点
1.Hadoop的历史
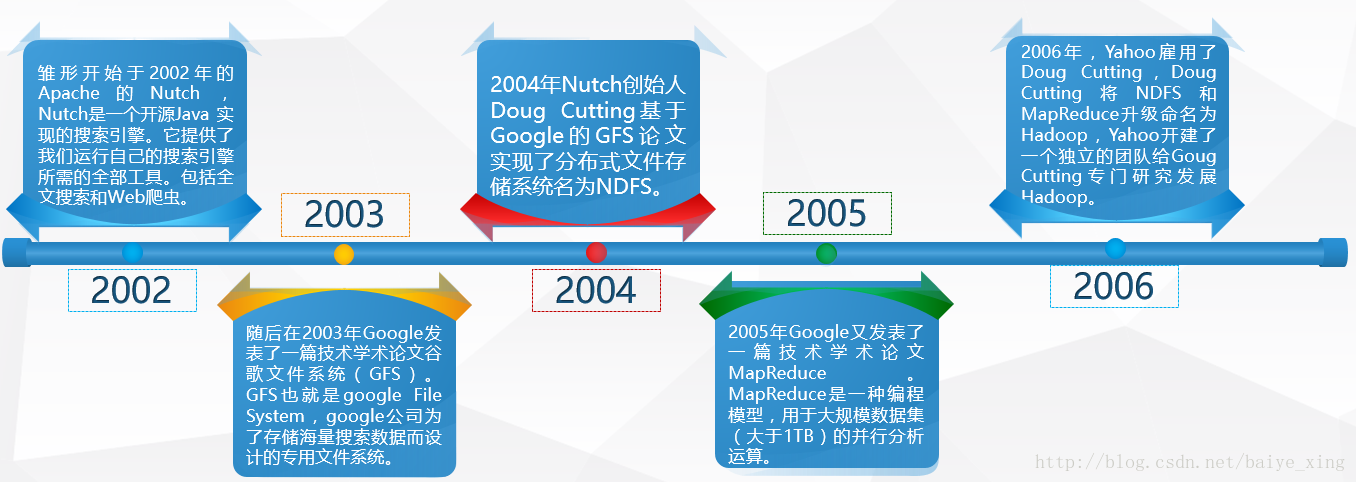
2.Hadoop的特点
- 扩容能力(Scalable)
能可靠地(reliably)存储和处理千兆字节(PB)数据 - 成本低(Economical)
可以通过普通机器组成的服务器集群来分发以及处理数据。这些服务器几圈总计可以达到千个节点。 - 高效率(Efficient)
通过分发数据,hadoop 可以在数据所在的节点上并行的(parallel)处理它们,这使得处理非常快。 - 可靠性(Reliable)
hadoop 能自动地维护数据的多份副本,并且在任务失败后能自动重新部署(redeploy)计算任务
Hadoop的组成
1.Hadoop的核心组件
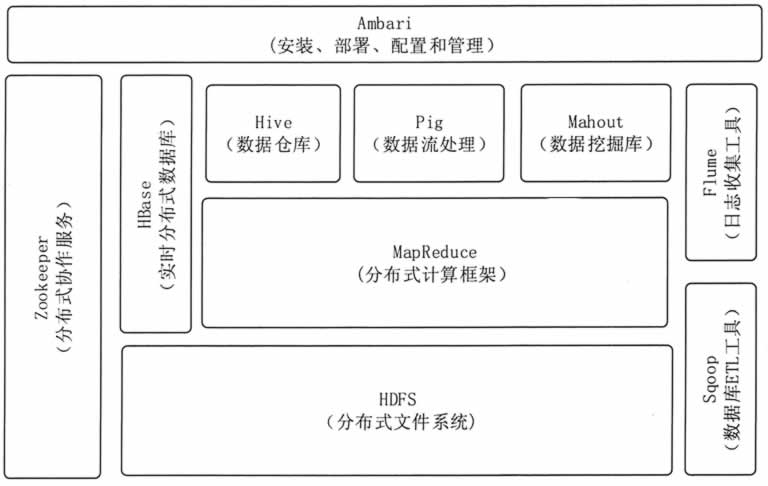
分析:Hadoop的核心组件分为:HDFS(分布式文件系统)、MapRuduce(分布式运算编程框架)、YARN(运算资源调度系统)
2.HDFS的文件系统
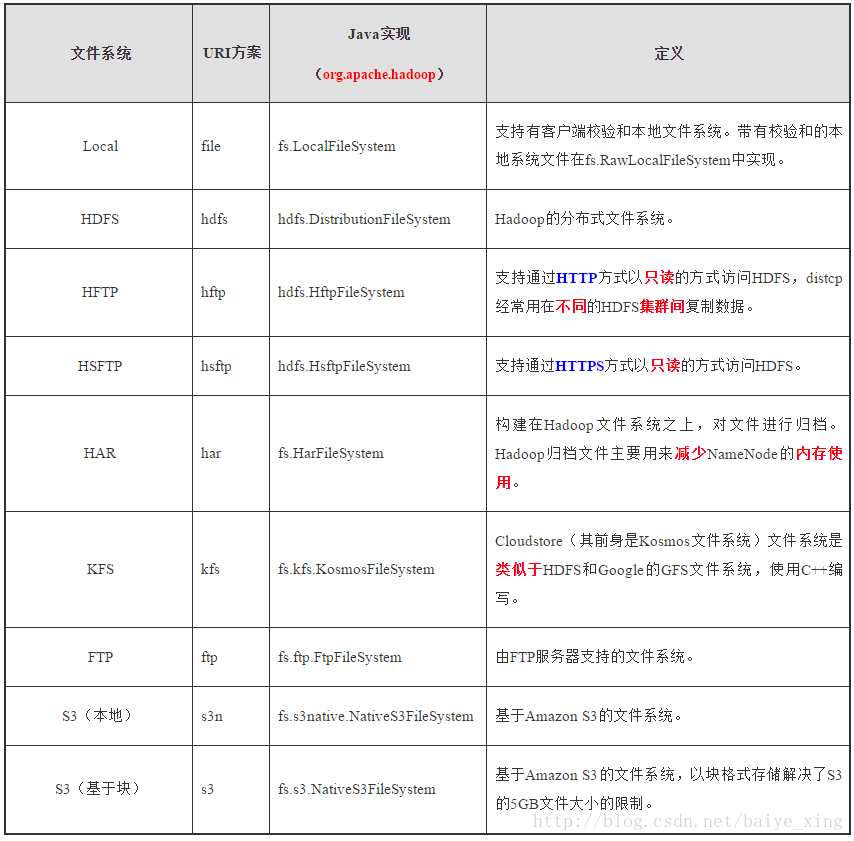
HDFS
1.定义
- 整个Hadoop的体系结构主要是通过HDFS(Hadoop分布式文件系统)来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
- HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2.组成
- HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
- 从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
- 图解
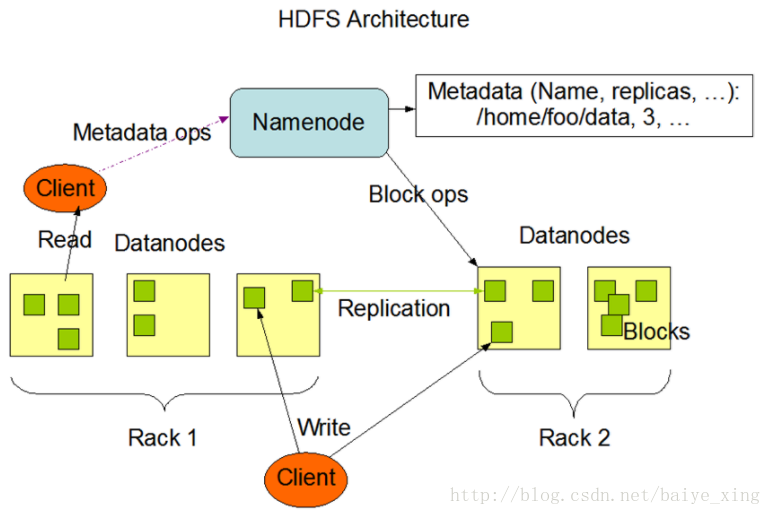
分析:NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
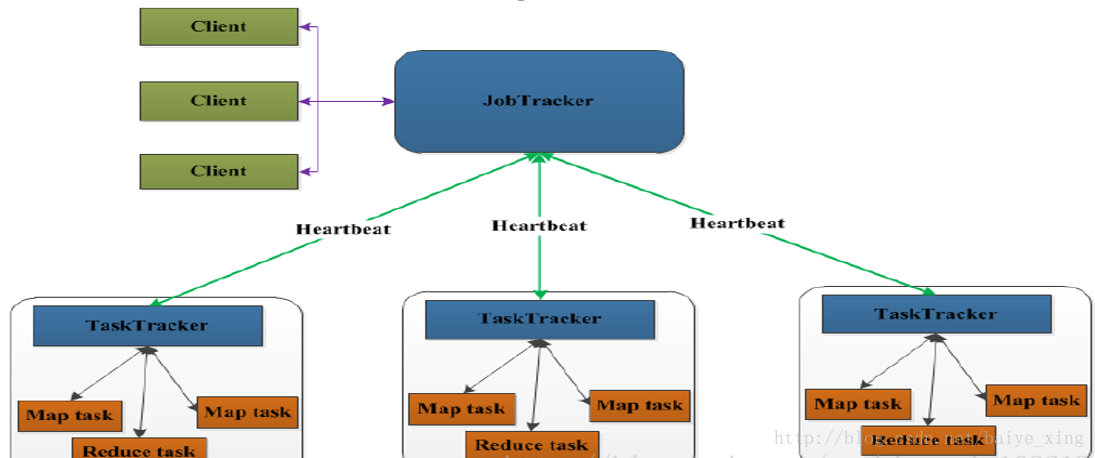
MapReduce
1.定义
- Hadoop MapReduce是google MapReduce 克隆版。
- MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
2.组成
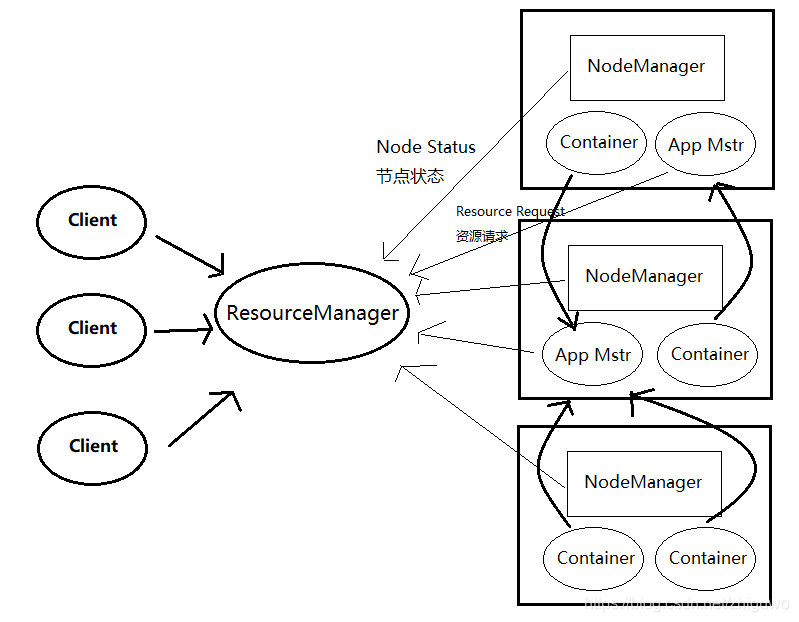
YARN
1)ResourceManager(rm) : 处理客户端请求Request、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm): 单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster(App Mstr):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错;
4)Container:对任务运行环境的抽象,封装了CPU 、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
最后
以上就是彪壮寒风最近收集整理的关于Hadoop架构的全部内容,更多相关Hadoop架构内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复