对比MPP计算框架和批处理计算框架
标签(空格分隔): 翻译
大数据技术交流QQ群:543190166 欢迎各位加入学习讨论,共同进步
原文链接:
https://content.pivotal.io/blog/apache-hawq-next-step-in-massively-parallel-processing
MPP设计理念
MPP最开始的设计目的是为了消除共享资源的使用,即每个executor有独立的cpu、内存和磁盘等资源,每个executor一般不能访问其他executor的资源。但是有一种情况例外,那就是当数据必须要通过网络进行交换的时候(译者注:即shuffle)。这种设计理念效果很好,使MPP具有了比较凑合的扩展性。
MPP的第二个重概念是“并发”,即每个executor执行同样的数据处理逻辑,处理的数据则是这个executor所在的节点的本地存储的数据分片,在这些执行步骤中,有一些被称为同步点(synchronization points)的东东,这些同步点多数情况下是在执行节点间的数据交换,比如spark和mr中得shuffle操作。下图是一个典型的MPP查询时间线,垂直的虚线表示同步点,例如,如果遇到join或者aggregation(译者注:即sql中的group by)操作,就需要一个同步操作来完成shuffle,而task本身(译者注:executor是进程级概念,task是executor内部的线程)则执行的是数据聚合、join、排序以及其他可以在本节点独立完成的任务。

MPP的问题
MPP设计中遇到的最大问题就是“落后者”(straggler)。如果某个节点在执行任何任务时都比其他的节点慢,那么不管集群规模多大,整体的执行性能都会由这个“有问题”的节点决定了。下图中可以看出这种慢节点是如何导致降级集群性能降低的。
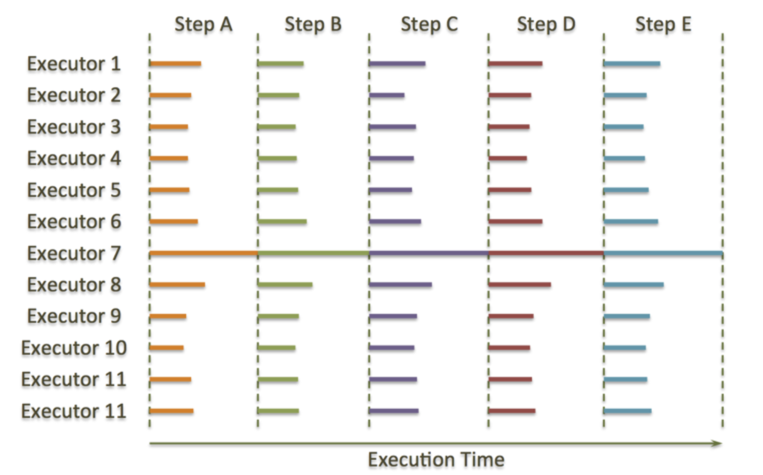
如上图,大部分时间里,一直都是一个executor7在孤独的执行,而其他executor则在静静的看它执行(译者注:这是因为同步点的存在导致的,既然叫同步点,就是说所有的executor要在这个点等待其他executor执行完成才能继续执行,至于为什么要等待,可以搜搜shuffle)。这就是MPP架构问题的根源所在,这种情况很容易发生,比如磁盘做了Raid,但是有磁盘突然坏了,raid的性能就会下降了,或者因为硬件或者OS的问题导致CPU性能下降,都可能会产生“慢节点”的问题。
Google做过关于磁盘损坏率的统计,可以看出AFR(年度损坏率),在最理想情况下都会有2%的磁盘在头三个月损坏。
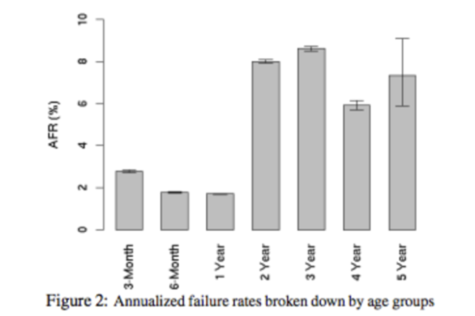
那么,在一个1000个磁盘的集群中,每年都会有20个磁盘损坏,按周算的话就是两周坏一个。如果集群规模上升到2000个磁盘,就是一周坏一个,4000个磁盘,一周坏两个。如果这些磁盘使用超过两年,那么前边的损坏数可以直接乘个4。
事实上,等集群到了一定规模,MPP系统总是会有那么一个节点发生磁盘阵列故障,这就会导致集群整体性能下降。这就是为什么几乎所有的MPP系统的单集群大小不会超过50台服务器。
MPP和MapReduce这种批处理架构的另外一个显著不同则在于并发(concurrency)方面。并发是指可以有效的同时运行的查询数(译者注:MPP一般面向即系查询业务,所以响应时间一般在秒级。所谓有效,就是说这些查询可以在用户可以接受的查询时间内返回,如果并发查询数很高,但是每个查询都需要等几个小时,那就不叫有效查询了)。MPP是完全“对称的”,即当查询开始执行时,每个节点都在并行的执行完全相同的任务, 就是说MPP支持的并发数和集群的节点数没有关系。例如,4个节点的集群和400个节点的集群支持的并发查询数是相同的,随着并发数增加,这二者几乎在相同的时间点出现性能骤降,可以看看下图:
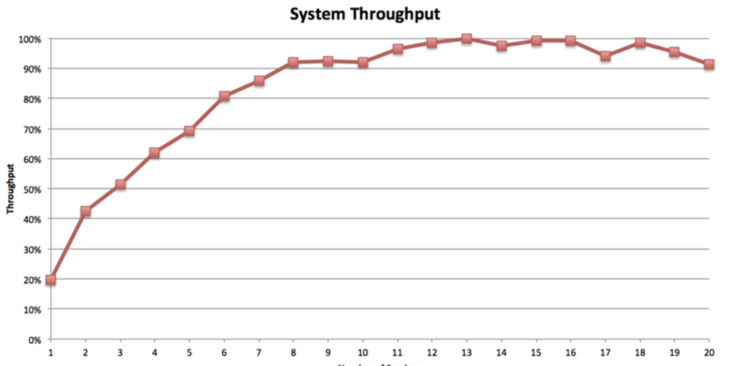
10-18个并发sessions时,系统总的吞吐量最大。如果并发数上升到20以上,总吞吐就会下降到最大吞吐的70%(这里吞吐量是这样定义的:相同类型(比如都是groupby,或者都是join查询)的查询在固定时间段内完成执行的个数)。Yahoo的一个团队也注意到了相同的现象,可以参阅Yahoo team investigating Impala concurrency limitations.。总而言之,MPP需要为高效数据处理速度买低并发的单。
批处理设计理念
为了处理上述问题,MapReduce及其后续的衍生品应运而生,例如Apache Hadoop和Apache Spark。这类系统的主要思想是,原本在两个同步点之间是单task执行,现在则被切分成多个独立的“task”,而task的总数则和executor的总数无关。举例来说明,HDFS上运行的MapReduce任务,task数等于总的split数(split数和要处理的HDFS文件的Block总数相同)。在两个同步点之间,这些任务被随机的分配到空闲的executor上,这就和MPP不同了,MPP的task是和存储这个task要处理的数据的节点绑定的。MapReduce的同步点包括的job的启动、shuffle以及job的停止;对spark而言则是job的启动、shuffle、数据缓存和job停止。下图以spark为例来说明这个流程,图中的横条代表独立的task,每个executor可以并行处理3个task
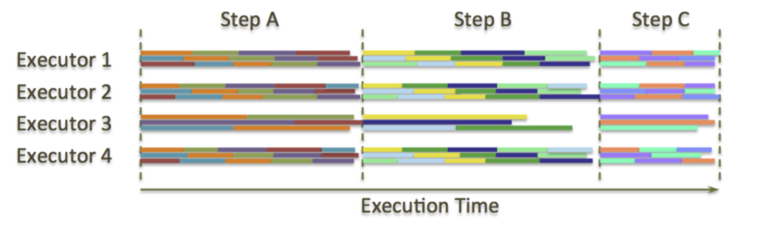
从上图可以看出,executor3的执行时间是几乎是其他executor的2倍,说明这个executor出问题了,但是没关系,这个executor只需要处理比其他executor少的task就行了(译者注:在spark或者mr中,task是分批执行的,能并行执行的task数由配置的cpu核数决定,所以执行快的节点被分配要执行的总task数较多,需要分多个批次才能处理完,而执行快的节点分配的task少,一个批次就执行完,所以总体来看,慢节点能在差不多同时和快节点执行完成)。如果慢节点慢到实在不能忍,推测执行可以就会介入:执行慢的节点的任务会在其他节点启动,同时执行(译者注:谁先执行完就用谁的结果,而没有执行完的task会被kill掉)。
批处理是怎么做到这一点的?答案就是共享存储。处理一块数据,不需要让数据一定要存储在某个特定的节点,需要这块数据时,可以从集群中其他节点那里获取到。当然了,远程操作涉及网络和磁盘IO,有一定代价,所以计算框架会尝试优先处理本地存储的数据。但是在“degraded”场景下,推测执行可以有效缓解性能下降问题,这在MPP中是完全不可能的。下图是对云计算中推测执行的一个调研结果
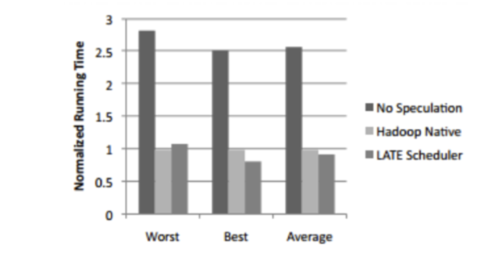
这张图片测试的是wordcount,可以看出,推测执行可以在云环境下提升2.5倍的性能,而云环境则是以解决“straggler”问题得名。共享存储和细粒度(译者注:task级别调度)结合,使得批处理系统在扩展性方面优于MPP,批处理系统的集群规模往往可以扩展到几千的节点和几万的磁盘的级别。
批处理的问题
但是任何优化都是有代价的。MPP下,不需要把中间结果写入磁盘,因为每个executor处理一个task,所以数据可以直接“流入”下一执行阶段进行处理,这就是所谓的pipeline执行,性能非常可观。 但是如果在一个单独的executor中串行的处理不相关的task,就必须把中间结果写到本地磁盘上,以便下一个执行步骤能开始消费本步骤的数据。这就是为什么这类批处理系统比较慢的原因了。
根据我的个人经验,对比当前的MPP系统和Spark这类系统(相同的硬件环境),spark普遍比MPP慢3到5倍。50个节点的MPP集群,性能和250的节点的spark集群性能相当,但是spark集群规模可以超过250个节点,但是MPP做不到。
考虑把MPP和批处理融合
至此,大家可以看到两类系统的优势和劣势了,MPP更快,但是“stragglers”问题和并发问题难以解决。批处理系统则需要在磁盘存储中间结果,但是集群并发性能可以随着集群整体规模比例增加。能否考虑把二者结合呢?告诉你们吧,Apache HAWQ就是这么设计的,惊喜不惊喜?开心不开心?
回忆一下MPP查询时如何执行的:若干并行进程处理相同的任务,每个进程处理他们本地存储中的数据。但是引入HDFS后,任务处理不会被绑定在固定的节点,也就是说可以从固定执行节点的束缚中挣脱出来。为什么呢?这是因为HDFS对同一block默认有三个副本,这样计算框架可以在至少3个节点上启动任务处理本地数据,而不存在需要通过网络读取远程数据的情况发生.
这就是为什么HAWQ引入了“虚拟segment”的概念,Greenplum中的segemnt是指常驻在节点上的PostgreSQL单独实例,当然这里的PostgreSql是经过修改的。这些单实例可以用来生成“executor”进程,每个查询在单节点对应一个executor。如果是小查询,可以由4个executor进程完成或者一个也可以。如果是大的查询,可能就需要100个甚至1000个executor了。不管查询是大是小,都是按照MPP的方式完成的,即一个进程只能处理本地数据,并且中间结果不写磁盘。但是虚拟segment则可以让executor在任何节点执行。看下图来理解(不同颜色代表不同查询,点线表示查询中的shuffle):
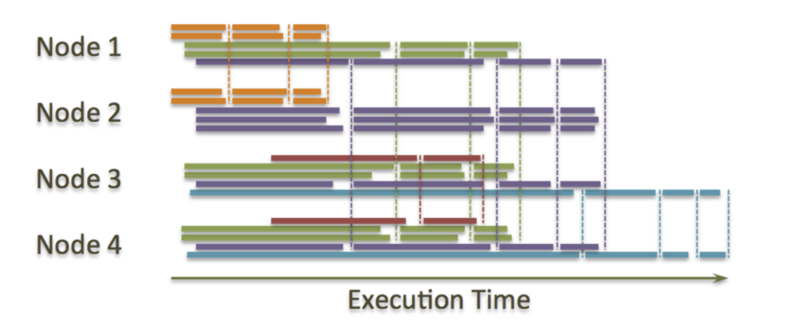
有什么好处呢?
- 这可以缓解MPP中的straggler问题。因为我们可以动态增加和删除集群中的”straggler“节点,所以硬盘损坏不会造成集群整体性能降低,并且系统可以扩展到的节点数比传统MPP多一个数量级。而且现在也可以把问题节点从集群中暂时删除,不会有executor在这些节点上去执行了。移除这些节点的时延也是不存在的。
- 查询现在需要的executor数是动态的,这就可以得到更高的并发性,这突破了MPP系统的限制,具有了批处理系统的灵活性。脑补一下,如果有个集群有50个节点,每一个节点都可以并行的跑200个进程,就会有50*200个“execution slot“可以执行任务,如果你的并发需求是20个,那么每一个使用500个executor,如果并发是200,每个使用50个executor,一个查询的话就是独占10000个executor了。相当灵活是不是?继续,如果一个大的查询需要4000个segment,但是其他600个查询每个只需要10个executor,没关系,一样可以做到。
- 数据pipeline。在两个stage之间,实时的把数据从一个executor传递到另外一个(独立的查询依然是MPP的流程,而不是批处理的流程),所以不需要把中间结果写磁盘,这样查询速度就会非常接近MPP系统。
- 和MPP类似,我们仍然可以尽可能的在本地存储的数据上执行查询任务,这是依靠HDFS的”short-circuit read“实现的。每个executor尝试在存储自己需要处理数据百分比最高的节点上执行,这样可以提高性能。
更进一步
HAQW引入了一种全新的设计,把MPP和批处理系统进行了融合,整合了二者的优点,同时解决了二者的缺点。当然,世界上没有完美的解决方案,这就是为什么需要给特定的数据处理问题引入特定的解决方案的原因。
最后
以上就是迅速黑裤最近收集整理的关于对比MPP计算框架和批处理计算框架对比MPP计算框架和批处理计算框架MPP设计理念MPP的问题批处理设计理念批处理的问题考虑把MPP和批处理融合更进一步的全部内容,更多相关对比MPP计算框架和批处理计算框架对比MPP计算框架和批处理计算框架MPP设计理念MPP内容请搜索靠谱客的其他文章。








发表评论 取消回复