oom killer日志分析,这是前篇,准备一些基础知识
带着问题看:
1.什么是oom killer
是Linux内核设计的一种机制,在内存不足的时候,选择一个占用内存较大的进程并kill掉这个进程,以满足内存申请的需求(内存不足的时候该怎么办,其实是个两难的事情,oom killer算是提供了一种方案吧)
2.在什么时候触发?
前面说了,在内存不足的时候触发,主要牵涉到【linux的物理内存结构】和【overcommit机制】
2.1 内存结构 node、zone、page、order
对于物理内存,linux会把它分很多区(zone),zone上还有node的概念,zone下面是很多page,这些page是根据buddy分配算法组织的,看下面两张图:
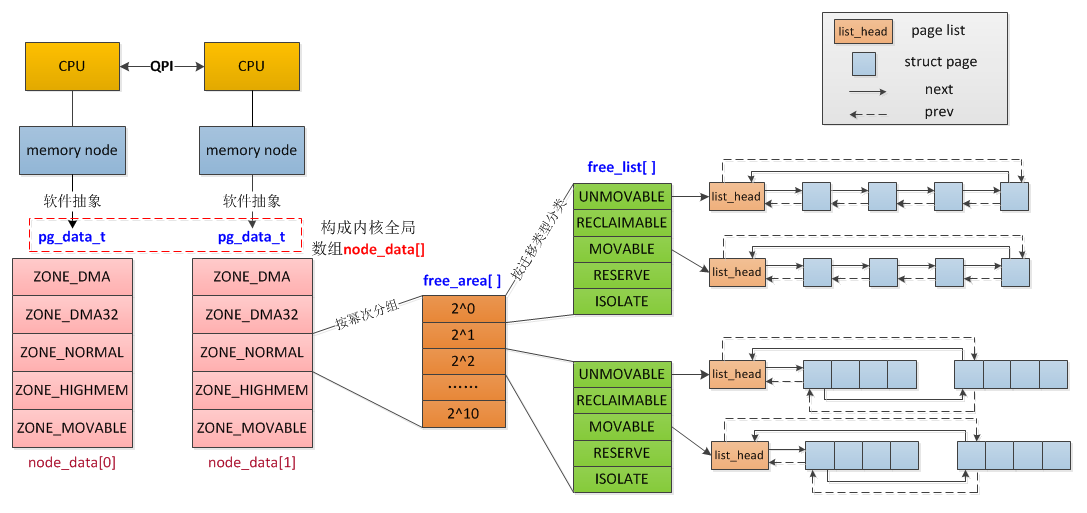
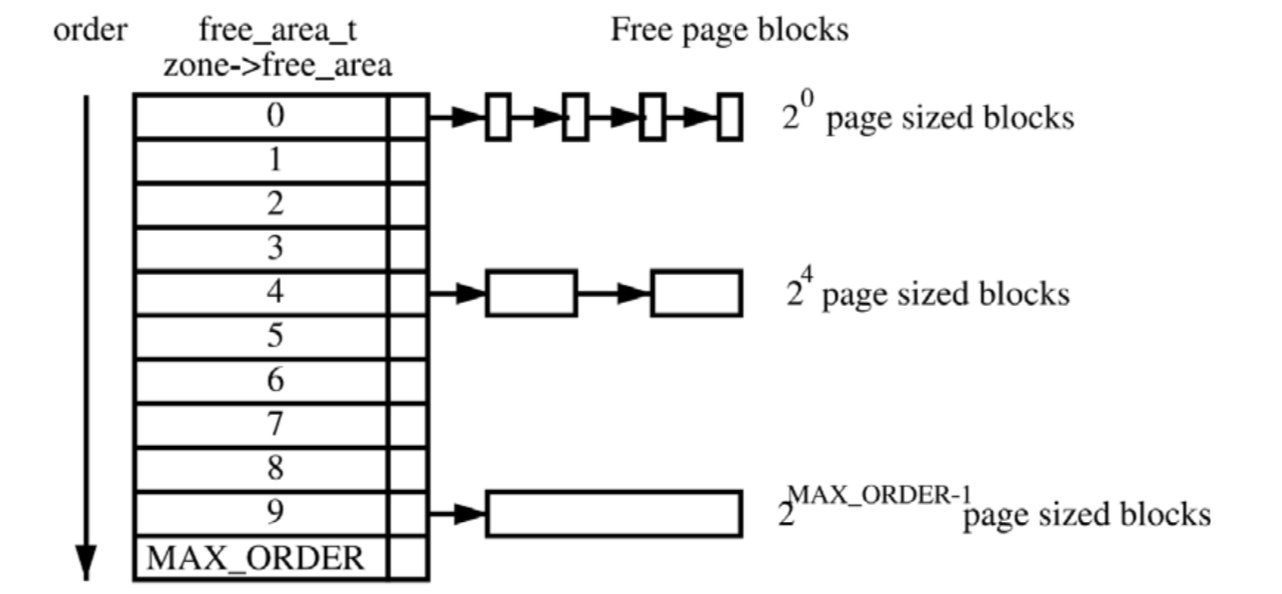
上面的概念做下简单的介绍,对后面分析oom killer日志很有必要:
- Node:每个CPU下的本地内存节点就是一个Node,如果是UMA架构下,就只有一个Node0,在NUMA架构下,会有多个Node
- Zone:每个Node会划分很多域Zone,大概有下面这些:
-
- ZONE_DMA:定义适合DMA的内存域,该区域的长度依赖于处理器类型。比如ARM所有地址都可以进行DMA,所以该值可以很大,或者干脆不定义DMA类型的内存域。而在IA-32的处理器上,一般定义为16M。
-
- ZONE_DMA32:只在64位系统上有效,为一些32位外设DMA时分配内存。如果物理内存大于4G,该值为4G,否则与实际的物理内存大小相同。
-
- ZONE_NORMAL:定义可直接映射到内核空间的普通内存域。在64位系统上,如果物理内存小于4G,该内存域为空。而在32位系统上,该值最大为896M。
-
- ZONE_HIGHMEM:只在32位系统上有效,标记超过896M范围的内存。在64位系统上,由于地址空间巨大,超过4G的内存都分布在ZONE_NORMA内存域。
-
- ZONE_MOVABLE:伪内存域,为了实现减小内存碎片的机制。
- 分配价值链
- 除了只能在某个区域分配的内存(比如ZONE_DMA),普通的内存分配会有一个“价值”的层次结构,按分配的“廉价度”依次为:ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA。
- 即内核在进行内存分配时,优先从高端内存进行分配,其次是普通内存,最后才是DMA内存
-
- Page:zone下面就是真正的内存页了,每个页基础大小是4K,他们维护在一个叫free_area的数组结构中
- order:数组的index,也叫order,实际对应的是page的大小,比如order为0,那么就是一堆1个空闲页(4K)组成的链表,order为1,就是一堆2个空闲页(8K)组成的链表,order为2,就是一堆4个空闲页(16K)组成的链表
2.2 overcommit
根据2.1,已经知道物理内存的大概结构以及分配的规则,不过实际上还有虚拟内存的存在,他的overcommit机制和oom killer有很大关系:
在实际申请内存的时候,比如申请1G,并不会在物理区域中分配1G的真实物理内存,而是分配1G的虚拟内存,等到需要的时候才去真正申请物理内存,也就是说申请不等于分配
所以说,可以申请比物理内存实际大的内存,也就是overcommit,这样会面临一个问题,就是当真的需要这么多内存的时候怎么办—>oom killer!
vm.overcommit_memory 接受三种值:
- 0 – Heuristic overcommit handling. 这是缺省值,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存
- 1 – Always overcommit. 允许overcommit,对内存申请来者不拒。
- 2 – Don’t overcommit. 禁止overcommit。
3.oom killer 怎么挑选进程?
linux会为每个进程算一个分数,最终他会将分数最高的进程kill
- /proc/<pid>/oom_score_adj
- 在计算最终的 badness score 时,会在计算结果是中加上 oom_score_adj,取值范围为-1000到1000
- 如果将该值设置为-1000,则进程永远不会被杀死,因为此时 badness score 永远返回0。
- /proc/<pid>/oom_adj
- 取值是-17到+15,取值越高,越容易被干掉。如果是-17,则表示不能被kill
- 该设置参数的存在是为了和旧版本的内核兼容
- /proc/<pid>/oom_score
- 这个值是系统综合进程的内存消耗量、CPU时间(utime + stime)、存活时间(uptime - start time)和oom_adj计算出的,消耗内存越多分越高,存活时间越长分越低
- 子进程内存:Linux在计算进程的内存消耗的时候,会将子进程所耗内存的一半同时算到父进程中。这样,那些子进程比较多的进程就要小心了。
- 其他参数(不是很关键,不解释了)
- /proc/sys/vm/oom_dump_tasks
- /proc/sys/vm/oom_kill_allocating_task
- /proc/sys/vm/panic_on_oom
- 关闭 OOM killer
- sysctl -w vm.overcommit_memory=2
- echo "vm.overcommit_memory=2" >> /etc/sysctl.conf
3.1 找出最有可能被杀掉的进程
vi oomscore.sh
#!/bin/bash
for proc in $(find /proc -maxdepth 1 -regex '/proc/[0-9]+'); do
printf "%2d %5d %sn"
"$(cat $proc/oom_score)"
"$(basename $proc)"
"$(cat $proc/cmdline | tr '�' ' ' | head -c 50)"
done 2>/dev/null | sort -nr | head -n 10
chmod +x oomscore.sh
./oomscore.sh
18 981 /usr/sbin/mysqld
4 31359 -bash
4 31056 -bash
1 31358 sshd: root@pts/6
1 31244 sshd: vpsee [priv]
1 31159 -bash
1 31158 sudo -i
1 31055 sshd: root@pts/3
1 30912 sshd: vpsee [priv]
1 29547 /usr/sbin/sshd -D3.2 避免的oom killer的方案
- 直接修改/proc/PID/oom_adj文件,将其置位-17
- 修改/proc/sys/vm/lowmem_reserve_ratio
- 直接关闭oom-killer
最后
以上就是平常流沙最近收集整理的关于oom killer理解和日志分析:知识储备的全部内容,更多相关oom内容请搜索靠谱客的其他文章。








发表评论 取消回复