Spark 源码中对livelistenerBus进行了这样的注释:
即所有spark消息SparkListenerEvents 被异步的发送给已经注册过的SparkListeners.
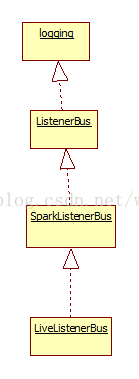
在SparkContext中, 首先会创建LiveListenerBus实例,这个类主要功能如下:
- 保存有消息队列,负责消息的缓存
- 保存有注册过的listener,负责消息的分发
private val EVENT_QUEUE_CAPACITY = 10000
private val eventQueue = new LinkedBlockingQueue[E](EVENT_QUEUE_CAPACITY)private[spark] class LiveListenerBus
extends AsynchronousListenerBus[SparkListener, SparkListenerEvent]("SparkListenerBus")
with SparkListenerBus {
private val logDroppedEvent = new AtomicBoolean(false)
override def onDropEvent(event: SparkListenerEvent): Unit = {
if (logDroppedEvent.compareAndSet(false, true)) {
// Only log the following message once to avoid duplicated annoying logs.
logError("Dropping SparkListenerEvent because no remaining room in event queue. " +
"This likely means one of the SparkListeners is too slow and cannot keep up with " +
"the rate at which tasks are being started by the scheduler.")
}
}
}继续把目光放在类AsynchronousListenerBus上,该类是消息机制的核心.既然是消息队列,就涉及到消息的生产和消费.首先来看消息的消费方式,AsynchronousListenerBus类会创建一个消费者线程listenerThread,来从消息队列中取得消息并进行分发,下面是实现代码:
private val listenerThread = new Thread(name) {
setDaemon(true)
override def run(): Unit = Utils.tryOrStopSparkContext(sparkContext) {
while (true) {
eventLock.acquire()
self.synchronized {
processingEvent = true
}
try {
val event = eventQueue.poll
if (event == null) {
// Get out of the while loop and shutdown the daemon thread
if (!stopped.get) {
throw new IllegalStateException("Polling `null` from eventQueue means" +
" the listener bus has been stopped. So `stopped` must be true")
}
return
}
postToAll(event)
} finally {
self.synchronized {
processingEvent = false
}
}
}
}
}整个思想就是典型的生产者消费者思想.为了保证生产者和消费者对消息队列的并发访问,在每次需要获取消息的时候,调用eventLock.acquire()来获取信号量, 信号量的值就是当前队列中所含有的事件数量.如果正常获取到事件,就调用postToAll将事件分发给所有listener, 继续下一次循环. 如果获取到null值, 则有下面两种情况:
- 整个application正常结束, 此时stopped值已经被设置为true
- 系统发生了错误, 立即终止运行
下面来看看生产者,代码如下:
def post(event: E) {
if (stopped.get) {
// Drop further events to make `listenerThread` exit ASAP
logError(s"$name has already stopped! Dropping event $event")
return
}
val eventAdded = eventQueue.offer(event)
if (eventAdded) {
eventLock.release()
} else {
onDropEvent(event)
}
}
该函数用来将事件放入到消息队列中,每成功放入一个事件,就调用eventLock.release()来增加信号量额值.以供消费者线程来进行消费. 如果队列满了,就调用onDropEvent来处理, 该函数已经在上面列出,此处不再赘述.
真正的消息路由是由SparkListenerBus的onPostEvent函数完成的:
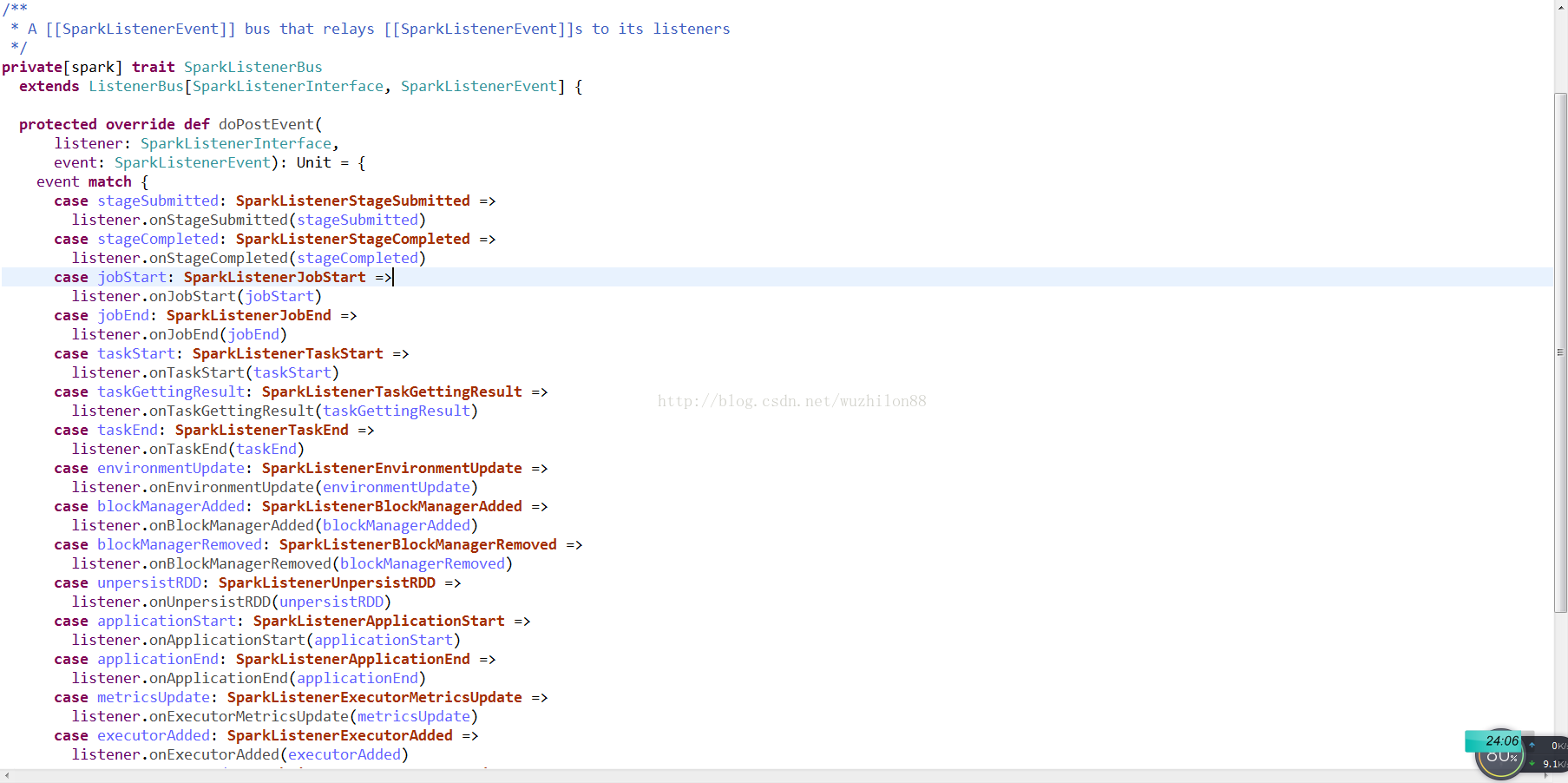
上面的代码很直观,根据不同的消息类型,调用listener对应的方法来进行处理.
下面来看看listener的定义, 所有的listener都混入了SparkListener特质.该特质定义了针对所有消息的处理函数, 定义全部为空:
对于特定的listener,在混入SparkListener特质之后,只需要重写相应的处理函数即可. 为了方便在进行消息路由时进行模式匹配,所有的具体的listener类均被定义为样本类.
对于spark中的事件来说,思想与listener类似,只是混入的特质不同而已, 事件混入的特质为SparkListenerEvent.
消息队列建立及发送流程介绍:
具体的消息发送流程如下所示:
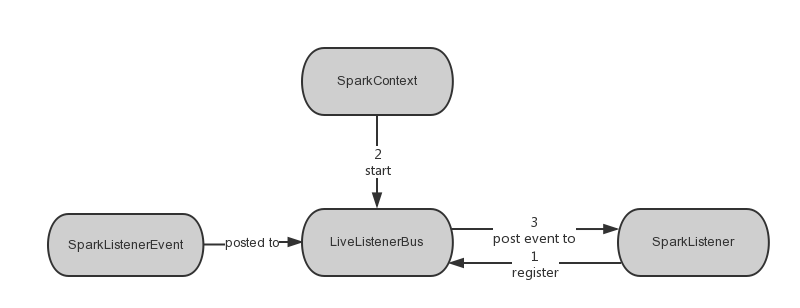
在SparkContext中,会
- 创建LiveListenerBus类类型的成员变量listenerBus
- 创建各种listener,并加入到listenerBus中
- post一些事件到listenerBus中
- 调用listenerBus.start() 来启动事件处理程序
这里有一点需要注意的是, 在listenerBus.start() 调用之前, 可以向其中post消息, 这些消息会被缓存起来,等start函数调用之后, 消费者线程会分发这些缓存的消息. listenerBus.start()是在SparkContext中的setupAndStartListenerBus函数中被调用的, 下面来看看该函数的实现:
// Use reflection to instantiate listeners specified via `spark.extraListeners`
try {
val listenerClassNames: Seq[String] =
conf.get("spark.extraListeners", "").split(',').map(_.trim).filter(_ != "")
for (className <- listenerClassNames) {
// Use reflection to find the right constructor
val constructors = {
val listenerClass = Utils.classForName(className)
listenerClass.getConstructors.asInstanceOf[Array[Constructor[_ <: SparkListener]]]
}
val constructorTakingSparkConf = constructors.find { c =>
c.getParameterTypes.sameElements(Array(classOf[SparkConf]))
}
lazy val zeroArgumentConstructor = constructors.find { c =>
c.getParameterTypes.isEmpty
}
val listener: SparkListener = {
if (constructorTakingSparkConf.isDefined) {
constructorTakingSparkConf.get.newInstance(conf)
} else if (zeroArgumentConstructor.isDefined) {
zeroArgumentConstructor.get.newInstance()
} else {
throw new SparkException(
s"$className did not have a zero-argument constructor or a" +
" single-argument constructor that accepts SparkConf. Note: if the class is" +
" defined inside of another Scala class, then its constructors may accept an" +
" implicit parameter that references the enclosing class; in this case, you must" +
" define the listener as a top-level class in order to prevent this extra" +
" parameter from breaking Spark's ability to find a valid constructor.")
}
}
listenerBus.addListener(listener)
logInfo(s"Registered listener $className")
}
} catch {
case e: Exception =>
try {
stop()
} finally {
throw new SparkException(s"Exception when registering SparkListener", e)
}
}
listenerBus.start(this)
_listenerBusStarted = true
}这段代码首先运用反射机制来处理spark.extraListeners设置, 在spark doc中有关于该设置的解释:
A comma-separated list of classes that implement SparkListener; when initializing SparkContext, instances of these classes will be created and registered with Spark’s listener bus. If a class has a single-argument constructor that accepts a SparkConf, that constructor will be called; otherwise, a zero-argument constructor will be called. If no valid constructor can be found, the SparkContext creation will fail with an exception.
大意为:该设置制定的listener会在初始化SparkContext时被创建注册,然而对于listener的构造函数时有要求的:
- 有一个单参数构造函数且参数为SparkConf类型, 则该构造函数被调用
- 否则,如果有无参构造函数, 则将被调用
- 如果没有定义构造函数,则程序异常结束
当extraListeners被构造并注册之后, listenerBus.start被调用:
def start(sc: SparkContext) {
if (started.compareAndSet(false, true)) {
sparkContext = sc
listenerThread.start()
} else {
throw new IllegalStateException(s"$name already started!")
}
}与此同时,启动消费者线程listenerThread, 开始进行消息路由.
当程序运行结束后,会调用stop函数:
def stop() {
if (!started.get()) {
throw new IllegalStateException(s"Attempted to stop $name that has not yet started!")
}
if (stopped.compareAndSet(false, true)) {
// Call eventLock.release() so that listenerThread will poll `null` from `eventQueue` and know
// `stop` is called.
eventLock.release()
listenerThread.join()
} else {
// Keep quiet
}
}这里可以看到,在stop函数中调用了eventLock.release()来增加信号量的值. 然而并未向消息队列中加入新的消息,这就导致在消费者线程listenerThread读取队列时会返回null值,进而达到结束listenerThread线程的目的.
最后
以上就是酷酷斑马最近收集整理的关于spark ListenerBus 监听器的全部内容,更多相关spark内容请搜索靠谱客的其他文章。








发表评论 取消回复