背景
有一次跑数据发现另外一张表的条件放在on后比放在where慢,然后放on后面和放where后面查询结果会不一样。
我们先了解查询结果的展现,后面再了解下更深层
展现
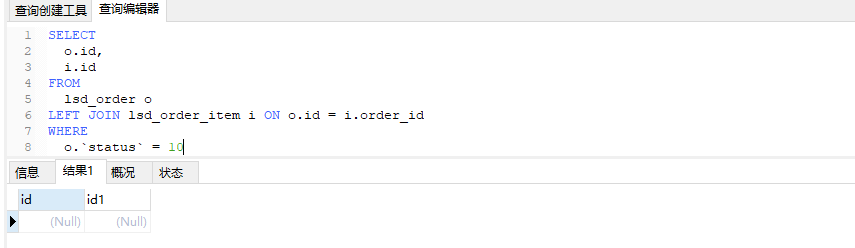
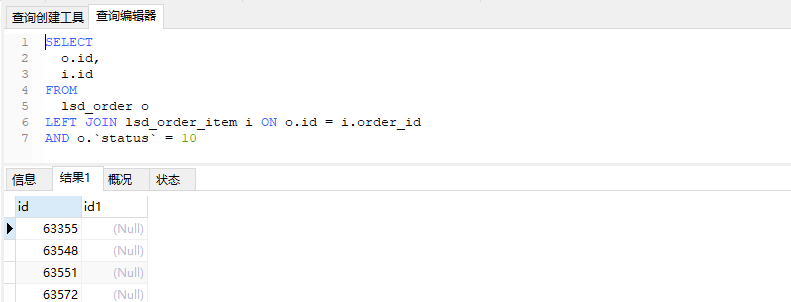
可以发现o表的筛选条件放在on只会影响i表的结果,不会影响o,放在where会影响两边的结果,当然只是针对左右连接。只有on可以发现是先连接再去筛选,先把连接的结果放在内存再去展示的时候筛选掉。
join原理
先根据筛选条件找出数据量小的驱动表,然后再取驱动表的每一行去和非驱动表的每一行匹配,比如驱动表有N行非驱动M极端条件下需要匹配N*M次(Simple Nested-Loop Join)。
感觉很麻烦没有优化方法嘛?非驱动联表字段可以建立索引(Index Nested-Loop Join);即使没用上Index Nested-Loop 还有Block Nested-Loop Join,mysql会把驱动表的联表字段缓冲到join buffer然后批量和非驱动表比较,详情看。
索引区别
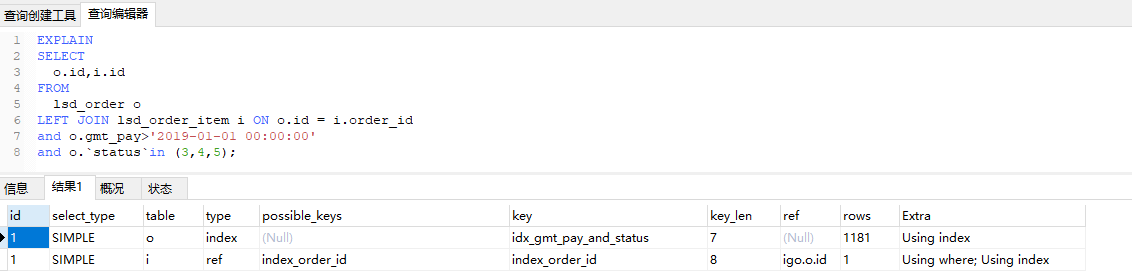
o表使用的是覆盖索引并没有回表,i表使用了ref类型索引回表查了id。看到这里你可能会觉得奇怪为啥是覆盖索引不是range,因为join只有on的时候会先进行连接再进行on后面的条件进行筛选,所以优化器进行o.id拿取的时候会去找相关索引由于o.id索引key_len=8但是idx_gmt_pay_and_status的key_len=7叶节点照样有o.id所以选择占内存小的。
要先筛选驱动表再去匹配怎么写如下:
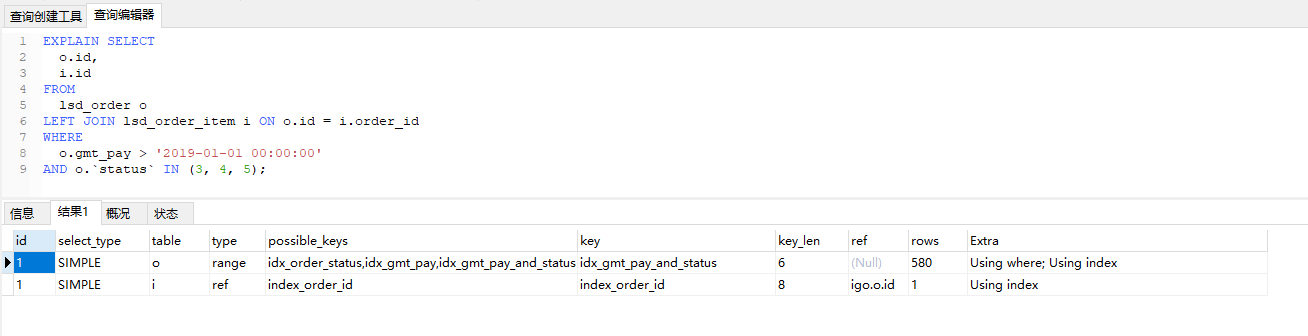
这个才是正确的写法。但是放在on上也有其存在意义,因为有些业务是只要连接上了就要left jion右边的左边的可以为空。具体还要根据业务来,甚至牺牲效率,但是也可以通过代码不通过联表来实现。
最后
以上就是疯狂纸鹤最近收集整理的关于Join连接条件放在on后面好和where的区别背景展现join原理索引区别的全部内容,更多相关Join连接条件放在on后面好和where内容请搜索靠谱客的其他文章。








发表评论 取消回复