python多线程学习
前言
从今天开始,进行python的爬虫和多线程学习,没有为什么,就是突然感兴趣~
废话不多说,之间进入正题!
1、最简单的多线程
直接上个最简单的多线程py
import threading
import time
tasks = [
'movie1','movie2','movie3','movie4','movie5',
'movie6','movie7','movie8','movie9','movie10'
]
def download(movie):
print(f'start downloading {movie}')
time.sleep(2)
print(f'finished download {movie}')
for task in tasks:
t = threading.Thread(target=download, args = (task,))
t.start()
运行后得到结果
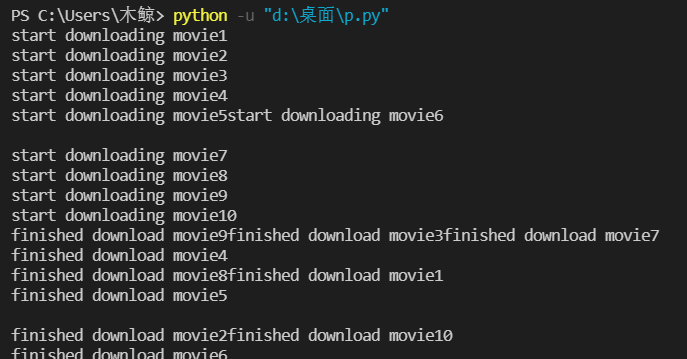
可以看到,程序是多线程进行的,开始当然是按着顺序的,可是完成是不同顺序的。这就是最简单的多线程。
2、threading类
t = threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
- group 线程组
- target 执行什么方法
- name 线程名字
- args,kwargs 参数设置
- daemon 守护线程
- t 一个线程对象
- t.name 线程编号
- t.ident 操作系统给线程的id
- t.is_alive() 查询线程是否active
- t.start() 启动线程
更多的方法,请查询官方文档
3、守护线程
开启守护线程
参数设置中daeman=True
守护线程,当主线程执行完成后,马上就终止当前的任务,不管是否完成。
类似与游戏的bgm。当你在打Boss,bgm刚刚到高潮时,Boss被击败,Boss处刑曲就结束了。这里的bgm就是守护线程。
用官方文档的话解释
Daemon线程会被粗鲁的直接结束,它所使用的资源(已打开文件、数据库事务等)无法被合理的释放。因此如果需要线程被优雅的结束,请设置为非Daemon线程,并使用合理的信号方法,如事件Event。
4、主线程
main_thread()是Python中线程模块的内置方法。 它用于返回主线程对象。 在正常情况下,这是Python解释程序从其启动的线程。
5、线程间的等待join()
thread_num = 100
threads = []
for i in range(thread_num):
t = threading.Thread(target=download)
t.start()
threads.append(t)
for t in threads:
t.join()
join()方法将被选中的线程,放入线程队列的尾部,等到上一个线程结束,才能开始
6、lock
我们看一段代码
import threading
import time
def download():
global count
for i in range(threading_tasks):
count += 1
count = 0
threading_tasks = 100000
thread_num = 100
threads = []
lock = threading.Lock()
startTime = time.time()
for i in range(thread_num):
t = threading.Thread(target=download)
t.start()
threads.append(t)
for t in threads:
t.join()
endTime = time.time()
print(f'应该下载的数量:{thread_num*threading_tasks}')
print(f'实际下载的数量:{count}')
print(f'下载的时间:{endTime-startTime}')

造成这个的原因就是因为同时有很多线程在执行 count += 1 这条命令
我们需要给download()方法上锁,避免count计数错误
import threading
import time
def download():
global count
for i in range(threading_tasks):
lock.acquire()
count += 1
lock.release()
count = 0
threading_tasks = 100000
thread_num = 100
threads = []
lock = threading.Lock()
startTime = time.time()
for i in range(thread_num):
t = threading.Thread(target=download)
t.start()
threads.append(t)
for t in threads:
t.join()
endTime = time.time()
print(f'应该下载的数量:{thread_num*threading_tasks}')
print(f'实际下载的数量:{count}')
print(f'下载的时间:{endTime-startTime}')
得到结果
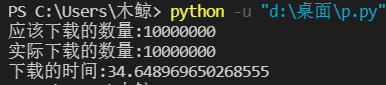
虽然时间增加了非常多,但是每个任务都确保完成了。这就是lock的好处。
最后
以上就是合适巨人最近收集整理的关于【python学习】对多线程的初步了解python多线程学习的全部内容,更多相关【python学习】对多线程内容请搜索靠谱客的其他文章。








发表评论 取消回复