目录
一、实验题目
二、分析与设计
三、源代码
一、实验题目
编写识别由下列文法G[E]所定义的表达式的递归下降语法分析器。
EàE+T | E-T | T
TàT*F | T/F |F
Fà(E) | i
输入:含有十进制数或十六进制数的表达式,如:75+(1ah-3*2)+68/2#。
输出:语法正确或语法错误信息。
提示:
1)先用实验1代码将含有十进制数或十六进制数的表达式转换为对应的含i的表达式,例如75+(1ah-3*2)+68/2#转换为i+(i-i*i)+i/i#。
2)再对含i的表达式进行语法分析。
二、分析与设计
(1) 分析
a) 判断文法是否左递归,将文法改写为LL(1)文法
文法存在左递归
消除文法左递归:
E->TE’
E’->AE’|ε
A->+T|-T
T->FT’
T’->BT’|ε
B->*F|/F
F->(E)|i
b) 求FIRST与FOLLOW集
| FIRST(E)={(,i} | FOLLOW(E)={ ),#} |
| FIRST(E’)={+,-,ε} | FOLLOW(E’)={ ),#} |
| FIRST(A)={+,-} | FOLLOW(A)={+,-,),#} |
| FIRST(T)={(,i} | FOLLOW(T)={ +,-,),#} |
| FIRST(T’)={*,/, ε} | FOLLOW(T’)={ +,-,),#} |
| FIRST(B)={*,/} | FOLLOW(B)={*,/,+,-,),#} |
| FIRST(F)={(,i} | FOLLOW(F)={ *,/,+,-,),#} |
c) 求SELECT集,并判断文法是否可以用递归下降分析法作语法分析
SELECT(E’->AE’)∩SELECT(E’->ε)={+,-}∩{},#}=Ø
SELECT(A->+T)∩SELECT(A->-T)={+}∩{-}=Ø
SELECT(T’->BT’)∩SELECT(T’->ε)={*,/}∩{+,-,},#}=Ø
SELECT(B->*F)∩SELECT(B->/F)={*}∩{/}=Ø
SELECT(F->(E))∩SELECT(F->i)={(}∩{i}=Ø
所以,该文法为LL(1)文法,可以用递归下降分析法作语法分析
(2) 设计
a) 主要数据结构及实现
全局变量:
char* q;//指向输入符号串中当前的字符
char word[20];//存储当前识别的单词
int state = 0;//表示所处的状态,初始状态为0
int i;//单词的下标
int j = 0;//输出数组out数组的下标
int wordErro = 1;//词法分析是否正确的标志,1:正确;0:错误
char sym; //保存输入的字符
char line[30]; //保存读入的一行表达式
char out[30]; //保存词法分析后带i的表达式
int cur; //表达式字符串的当前下标
int error; //错误标志 0:正确 -1:错误
//利用这7个函数对应7个语法分析状态进行操作
int E(), E1(), T(), T1(), F();
b) 主要程序模块的算法流程图
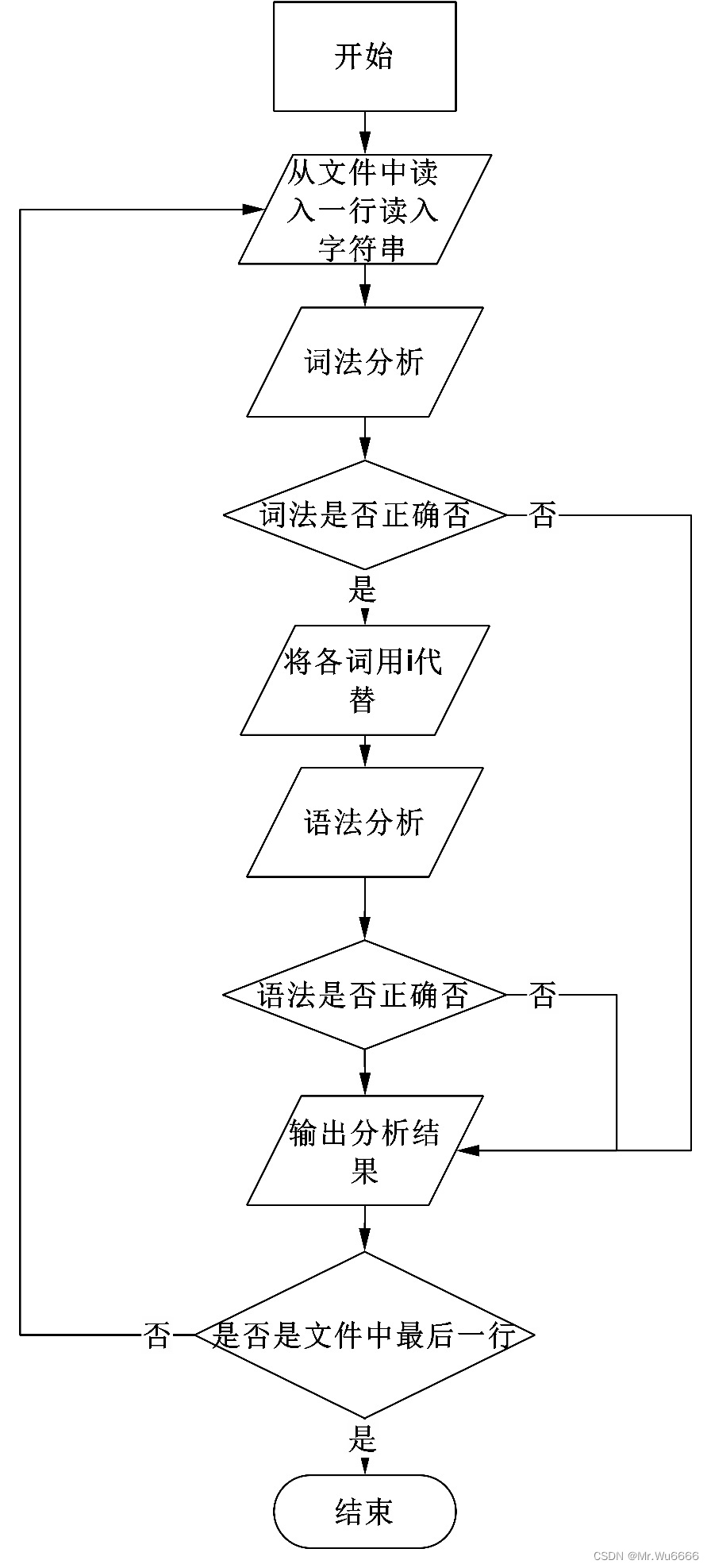
(3) 编码实现
(4) 上机调试
三、源代码
/*词法分析
输入:包含十进制和十六进制的表达式
输出:标准形式的表达式
*/
#include "stdio.h"
#include "string.h"
#include "conio.h"
#include<iostream>
using namespace std;
enum type { digit, Hh, AF, letter, oparetors };
char* q;//指向输入符号串中当前的字符
char word[20];//存储当前识别的单词
int state = 0;//表示所处的状态,初始状态为0
int i;//单词的下标
int j = 0;//输出数组out数组的下标
int wordErro = 1;//词法分析是否正确的标志,1:正确;0:错误
int isDigitOrChar(char ch) {
if (ch >= 48 && ch <= 57) //数字
return digit;
else if (ch == 72 || ch == 104)
return Hh; //Hh
else if ((ch >= 65 && ch <= 70) || (ch >= 97 && ch <= 102))//ABCDEF或者abcdef
return AF;
else if ((ch >= 65 && ch <= 90) || (ch >= 97 && ch <= 122))//除A-F外的其他字母
return letter;
else if (ch == 40 || ch == 41 || ch == 42 || ch == 43 || ch == 45 || ch == 47 || ch == 35)//(、)、*、+、-、/ 、# 这六个运算符
return oparetors;
}
int toExpress(char* words, char* out) {
wordErro = 1;
state = 0;
i = 0;
j = 0;
printf("词法分析的结果为:");
q = words;
while (*q) {
switch (state) {
case 0: //当前为0状态
switch (isDigitOrChar(*q)) {
case digit://数字
word[i++] = *q;
state = 2;
break;
case Hh: //Hh
case AF: //ABCDEF或者abcdef
case letter: //除A-F外的其他字母
word[i++] = *q;
state = 1;
break;
case oparetors: //运算符
word[i++] = *q;
printf("%c", word[0]);
out[j++] = word[0];
state = 0;
memset(word, 0, sizeof(word));
i = 0;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5; //转到出错状态
break;
}
break;
case 1: //当前为1状态
switch (isDigitOrChar(*q)) {
case digit://数字
word[i++] = *q;
state = 1;
break;
case Hh: //Hh
case AF: //ABCDEF或者abcdef
case letter: //除A-F外的其他字母
word[i++] = *q;
state = 1;
break;
case oparetors: //运算符,1状态可以为标识符的结束状态
word[i++] = *q;
state = 0;
printf("i");
out[j++] = 'i';
for (int m = 0;m < sizeof(word);m++) {
if (isDigitOrChar(word[m]) == oparetors) {
printf("%c", word[m]);
out[j++] = word[m];
}
}
memset(word, 0, sizeof(word));
i = 0;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5; //转到出错状态
break;
}
break;
case 2: //当前为2状态
switch (isDigitOrChar(*q)) {
case digit://数字
word[i++] = *q;
state = 2;
break;
case Hh: //Hh
word[i++] = *q;
state = 3;
break;
case AF: //ABCDEF或者abcdef
word[i++] = *q;
state = 4;
break;
case oparetors: //运算符,2状态可以为十进制整数的结束状态
word[i++] = *q;
state = 0;
printf("i");
out[j++] = 'i';
for (int m = 0;m < sizeof(word);m++) {
if (isDigitOrChar(word[m]) == oparetors) {
printf("%c", word[m]);
out[j++] = word[m];
}
}
memset(word, 0, sizeof(word));
i = 0;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5; //转到出错状态
break;
}
break;
case 3: //当前为3状态
switch (isDigitOrChar(*q)) {
case oparetors: //运算符,3状态可以为十六进制整数的结束状态
word[i++] = *q;
state = 0;
printf("i");
out[j++] = 'i';
for (int m = 0;m < sizeof(word);m++) {
if (isDigitOrChar(word[m]) == oparetors) {
printf("%c", word[m]);
out[j++] = word[m];
}
}
memset(word, 0, sizeof(word));
i = 0;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5;
break;
}
break;
case 4: //当前为4状态
switch (isDigitOrChar(*q)) {
case digit://数字
word[i++] = *q;
state = 4;
break;
case Hh: //Hh
word[i++] = *q;
state = 3;
break;
case AF: //ABCDEF或者abcdef
word[i++] = *q;
state = 4;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5; //转到出错状态
break;
}
break;
case 5: //出错状态
switch (isDigitOrChar(*q)) {
case oparetors: //运算符
word[i++] = *q;
state = 0;
memset(word, 0, sizeof(word));
i = 0;
wordErro = 0;
break;
default: //其他字符(非法)
word[i++] = *q;
state = 5; //转到出错状态
break;
}
break;
}
q++; //指针下移(指向输入符号串的下一个字符)
}
if (wordErro == 1) {
printf("n》》》词法正确!《《《n");
}
else {
printf("n》》》词法错误!《《《n");
}
return 0;
}
/*从test.txt文件中读入由i和运算符组成的式子,
判断是否合法
*/
char sym; //保存输入的字符
char line[30]; //保存读入的一行表达式
char out[30]; //保存词法分析后带i的表达式
int cur; //表达式字符串的当前下标
int error; //错误标志 0:正确 -1:错误
//声明函数
int E(), E1(), T(), T1(), F();
//读入当前字符
char read(char line[], int k) {
return line[k];
}
int E() {
T();
E1();
return 0;
}
int E1() {
if (sym == '+' || sym == '-') {
cur++;
sym = read(line, cur);
T();
E1();
}
else if (sym == '#' || sym == ')') {
return 0;
}
else {
error = -1;
}
return 0;
}
int T() {
F();
T1();
return 0;
}
int T1() {
if (sym == '*' || sym == '/') {
cur++;
sym = read(line, cur);
F();
T1();
}
else if (sym == '+' || sym == ')' || sym == '#' || sym == '-') {
return 0;
}
else {
error = -1;
}
return 0;
}
int F() {
if (sym == 'i') {
cur++;
sym = read(line, cur);
}
else if (sym == '(') {
cur++;
sym = read(line, cur);
E();
if (sym == ')') {
cur++;
sym = read(line, cur);
}
else {
error = -1;
}
}
else {
error = -1;
}
return 0;
}
int main(int argc, char* argv[]) {
FILE* fp;
//打开文本文件
fopen_s(&fp, "C:/Users/wzy/Desktop/编译原理实验2 -测试用例-test.txt", "r");
if (fp == NULL) {
printf("open file error!n");
getchar();
return -1;
}
//逐行读入表达式,并分析是否符合语法规则
while (!feof(fp)) {
printf("------------------------------------------n");
strcpy_s(line, "�");
fscanf_s(fp, "%s", &line, 30); //逐行读
cur = 0;
error = 0;
printf("输入字符串为:%s n", line);
char inputString[30];//中间变量,存储输入的字符串
for (int i = 0;i < sizeof(line);i++) {
inputString[i] = line[i];
}
//进行词法分析
toExpress(line, out);
memset(line, 0, sizeof(line));
for (int i = 0;i < sizeof(line);i++) {
line[i]= out[i];
}
if (wordErro == 1) {//若词法正确,则进行语法分析
sym = read(line, cur);//读入当前字符
E();//开始语法分析
//如果表达式有错
if (error == -1) {
printf("》》》语法错误!《《《n分析结果:%s为非法字符串n", inputString);
printf("------------------------------------------n");
}
//如果表达式合法
else if (error == 0) {
printf("》》》语法正确!《《《n分析结果:%s为合法字符串n", inputString);
printf("------------------------------------------n");
}
memset(line, 0, sizeof(line));
memset(out, 0, sizeof(out));
wordErro = 1;
}
else{
printf("》》》不进行语法分析!!《《《n分析结果:%s为非法字符串n", inputString);
printf("------------------------------------------n");
continue;
}
}
fclose(fp);
getchar();
return 0;
}test.txt中的内容(测试用例):
80+5eH+(6+1h)*2+4h#
6+(5+2))*5+80bh#
95eah+3*(5+10)+35h#
9*6+(5+2)*5+80bh#
59h+((3+9ah)*3+4#
7+9*2#
最后
以上就是高贵小蚂蚁最近收集整理的关于【编译原理】- 递归下降的语法分析器的实现一、实验题目二、分析与设计三、源代码的全部内容,更多相关【编译原理】-内容请搜索靠谱客的其他文章。

![dfa敏感词过滤算法 java_[源码和文档分享]基于JAVA实现的基于DFA的词法分析程序...](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)






发表评论 取消回复