Sqoop的简介
产生背景
基于传统关系型数据库的稳定性,还是有很多企业将数据存储在关系型数据库中;
早期由于工具的缺乏,Hadoop与传统数据库之间的数据传输非常困滩。
基于前两个方面的考虑,需要一个在传统关系型数据库和Hadoop之间
进行数据传输的项目,Sqoop应运而生。
Sqoop是什么
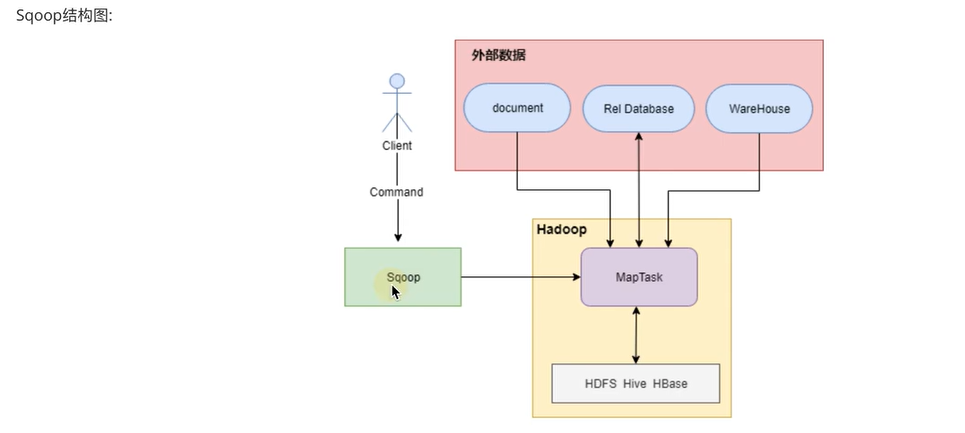
Sqoop是一个用于Hadoop和结构化数据存储(如关系型数据库)之间进行高效传输大批量数据的工具。它包括以下两个方面;可以使用Sqoop将数据从关系型数据库管理系统(如MySQL)导入到Hadoop系统"(如HDFS、Hive、HBase)中将数据从Hadoop系统中抽取并导出到关系型数据库(如MySQL)
常见数据库开源工具:
- sqoop
- datax
- kettle
- cannal
底层实现原理
Sqoop的核心设计思想是利用MapReduce加快数据传输速度。也就是说Sapop的导入和导出功能是通过基于MapTask(只有map)的MapReduce作业实现的.所以它是一种批处理方式进行数据传输,难以实现实时的数据进行导入和导出。
特点
优点:它可以将跨平台的数据进行整合。
缺点∶它不是很灵活。
主要执行操作
sqoop重要的几个关键词
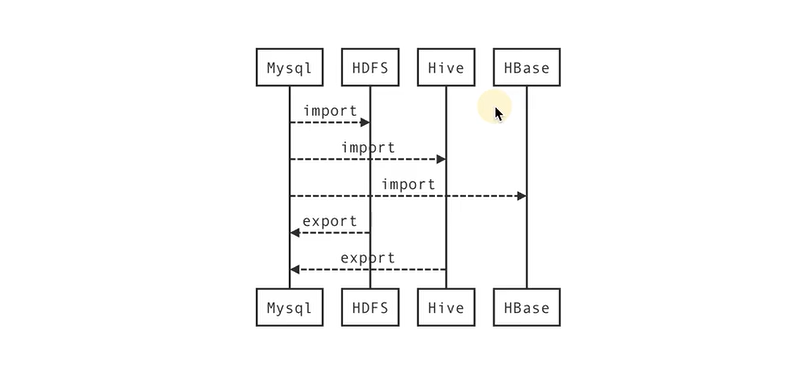
- import: 从关系型数据库到hadoop
- export: 从hadoop到关系型数据库
Sqoop的安装
注意:在安装sqoop之前要配置好本机的Java环境和Hadoop环境
先把spoop的安装包sqoop-1.4.7.bin__.hadoop-2.6.0.tar . gz拷贝在系统目录下的/root/soft下面
解压配置环境变量
#解压tar-gz包
[root@tianqinglong01 local] tar -zxvf /root/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/
#把sqoop的安装路径修改为sqoop,方便以后配置和调用
[root@tianqinglong01 local]# mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
[root@tianqinglong01 sqoop]# vi /etc/profile
#追加内容如下:
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
:wq
[root@tianqinglong01 sqoop]#source /etc/profile/
新建配置文件
[root@tianqinglong01 sqoop]# mv ./conf/sqoop-env-template.sh ./conf/sqoop-env.sh
修改配置文件
配置文件:
[root@tianqinglong01 sqoop]# vi ./conf/sqoop-env.sh
按照本系统实际安装的Hadoop系列目录配置好下面的路径:
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export ZOOCFGDIR=/usr/local/zookeeper
拷贝mysql驱动
因为我们现在通过JDBC让Mysql和HDFS等进行数据的导入导出,所以我们先必须把JDBC的驱动包拷贝到sqoop/lib路径下,如下
[root@tianqinglong01 softwares]# cp /root/mysql-connector-java-5.1.18.jar $SQOOP_HOME/lib
验证安装
#查看sqoop的版本
[root@tianqinglong01 sqoop]# sqoop version
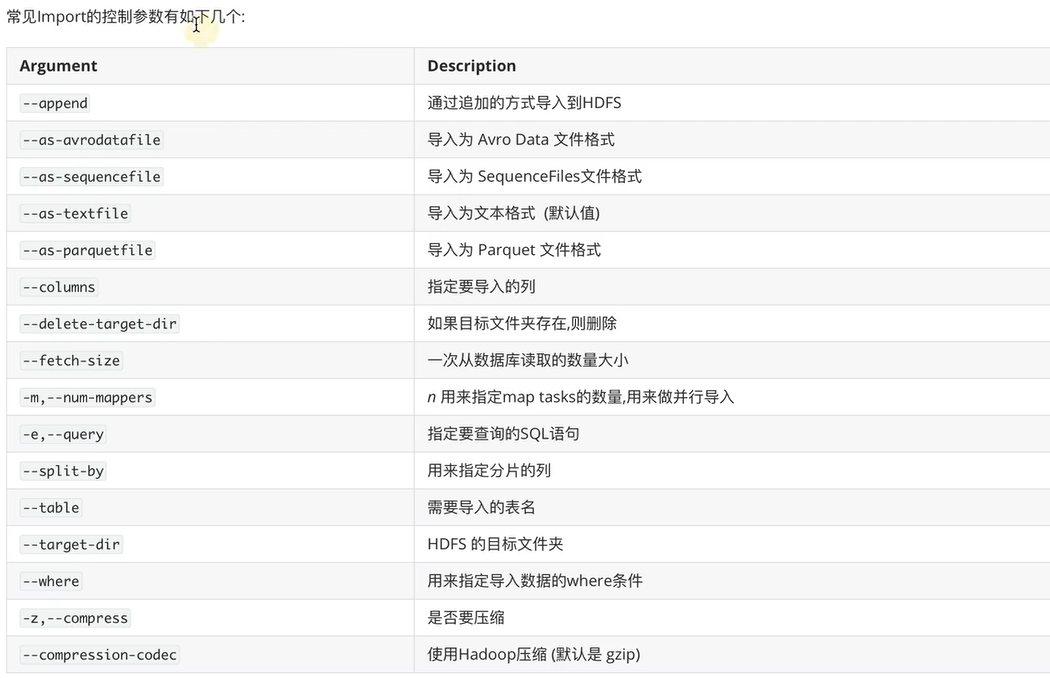
Import的控制参数
# 连接数据库
[root@tianqinglong01 scpoop]# sqoop import --connect jdbc:mysql://database.example.com/employees
# 指定连接的服务地址是database.examployee.com ,要连接的数据库是employees
sqoop导入案例 mysql到hdfs
Sqoop运行的时候不需要启动后台进程,直接执行sqoop命令加参数即可.简单举例如下:
## 通过参数用下面查看数据库
[root@tianqinglong01 scpoop]# sqoop list-databases --connect jdbc:mysql://tianqinglong03:3306 --username root --password 123456;
指定表导入
数据准备

sqoop的典型导入都是把关系数据库中的表导入到HDFS中,使用--table参数可以指定具体的表导入到hdfs,譬如用--table emp, 默认情况下是全部字段导入如下:
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
> --username root --password 123456
> --table emp
> --target-dir hdfs://tianqinglong01:8020/sqoop/emp
> --delete-target-dir
可以快速使用hdfs的命令查询结果
[root@tianqinglong01 sqoop]# hdfs dfs -cat /sqoop/emp/*
指定列导入
如果想导入某几列,可以使用--columns,如下:
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
> --username root --password 123456
> --table emp
> --columns 'empno,mgr'
> --target-dir hdfs://tianqinglong01:8020/sqoop/emp
> --delete-target-dir
可以快速使用hdfs的命令查询结果
[root@tianqinglong01 sqoop]# hdfs dfs -cat /sqoop/emp/*
指定条件导入
在导入表的时候,也可以通过指定where条件来导入,具体参数使用--where ,譬如要导入员工号大于7800的记录,可以用下面参数:
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
> --username root --password 123456
> --table emp
> --columns 'empno,mgr'
> --where 'empno>7800'
> --target-dir hdfs://tianqinglong01:8020/sqoop/emp
> --delete-target-dir
命令查询结果
[root@tianqinglong01 sqoop]# hdfs dfs -cat /sqoop/emp/*
指定sql导入
上面的可以通过表字段,条件进行导入但是还不够灵活,其实soop还可以通过自定义的sql来进行导入可以通过--query参数来进行导入这样就最大化的用到了Sq的灵活性.如下:
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
> --username root --password 123456
> --query 'select empno,mgr,job from emp where empno>7800 and $CONDITIONS'
> --target-dir hdfs://tianqinglong01:8020/sqoop/emp
> --delete-target-dir
> --spilt-by empno
> -m 1
注意:在通过--query来导入数据时,必须要指定--target-dir
如果你想通过并行的方式导入结果,每个map task需要执行sq|查询语句的副本,结果会根据sqoop推测的边界条件分区。query必须包含$CONDITIONS。这样每个scoop程序都会被替换为一个独立的条件。同时你必须指定--split-by .分区
-m 1是指定通过一个Mapper来执行流程
命令查询结果
[root@tianqinglong01 sqoop]# hdfs dfs -cat /sqoop/emp/*
单引号双引号区别
在导入数据时,默认的字符引号是单引号,这样sqoop在解析的时候就按照字面量来解析,不会做转移:例如:;
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS'
如果使用了双引号,那么Sqoop在解析的时候会做转义的解析,这时候就必须要加转义字符:如下;
--query "select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS"
mysql缺主键问题
1、如果mysql的表没有主键,将会报错:
19/12/0210:39:0 ERROR tool . ImportTool: Import
failed: No primary key could be found for table u1. Please specify one with
-- split- by or perform a sequential import with '-m 1'
解决方案:
通过--split-by 来指定要分片的列
代码如下:
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/ qfdb
--username root --password 123123、
--query 'select empno,mgr,job from emp WHERE empno>7800 and $CONDITIONS'
--target-dir hdfs://qianfeng01:9000/sqoop/emp
--delete-target-dir
--split-by empno
-m 1
Mysql到hive
说明
Sqoop的导入工具的主要功能是将数据上传到HDFS中的文件中。如果您有一个与HDFS集群相关联的Hive,Sqoop还可以通过生成和执行CREATETABLE 语句来定义Hive中的数据,从而将数据导入到Hive中。将数据导入到Hive中就像在Sqoop命令行中添加--hive-import选项。
如果Hive表已经存在,则可以指定--hive-overwrite选项,以指示必须替换单元中的现有表。在将数据导入HDFS或省略此步骤之后,Sqoop将生成一个Hive脚本,其中包含使用Hive的类型定义列的CREATE表操作,并生成LOAD Data INPATH语句将数据文件移动到Hive的仓库目录中。
在导入Hive之前先要配置Hadoop的Classpath才可以,否则会报类找不到错误,在/etc/profile未尾添加如下配置:
export HADOOP_CLASSPATH=$HADOOP_CCLASSPATH:$HIVE_HOME/lib/*
# 刷新配置
source /etc/profile
参数说明

实际导入案例
提示:为了看到演示效果,可以先在Hive删除emp表
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/ qfdb
--username root --password 123456
--table emp
--hive-import
[--hive-overwrite ]
[--fields-terminated-by ','] #注意表也要改分隔符
[--hive-table 'qfdb.emp1']
-m 1
在hive中查看表
hive> show tables;
#结果如下
OK
emp
可以在hive中查看数据是否导入
select * from emp;
# 结果如下
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESgAN 7698 1981-02-20 1600.0 300.0 30
7521 WARD SALESdw 7698 1981-02-22 1250.0 500.030
7566 JONES MAAGER 7839 1981-04-02 2975.0 NULL20
7654 MARTIN SALESAN 7698 1981-09-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-e5-e1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-06-09 2450.0 NULL 10
7783 SC0T ANALYST 7566 1987-04-19 3000,0 MULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL10
7844 TURNER SALESMAN 7698 1981-09-08 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-05-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-03 950.0 NULL 30
7902 FORDA NALYST 7566 1981-12-03 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-01-23 1300.0 NULL 10
导入数据库没有主键的问题
sqoop-import
案例1
表没有主键,需要指定map task的个数为1个才能执行
sqoop导入原理
Sqoop默认是并行的从数据库源导入数据。您可以使用-m或–num-mappers参数指定用于执行导入的map任务(并行进程)的数量。每个参数都取一个整数值,该整数值对应于要使用的并行度。默认情况下,使用四个任务。一些数据库可以通过将这个值增加到8或16来改善性能。
默认情况下,Sopop将标识表中的主键id列用作拆分列。从数据库中检索分割列的高值和低值,map任务操作整个范围的大小均匀的组件。譬如ID的范围是0-800.那么Sqoop默认运行4个进程通过执行《SELECT NIN(id), vX(id) FROM emp找出id的范围,然后把4个任务的id设置范围是(0-200)M200-400)(400-60)1600-800)但是当一个表没有主键时,上面的切分就无法进行sqoop导入时就会出镊,这时候可以通过-m把mapper的数量设为1,只有也Mapper在运行,这时候就不需要切分也可以遵免主键不存在时候报错的问题.
#错误信息 ERROR tool.ImportTool: Import failed: Mo primary key could be found for table emp. Please specify one with --plit-by or perform asequential import with '-m 1'.```
导入代码
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
--username root --password 123456
--table emp -m 1
DBMS-HDFS
案例2
表没有主键,使用split-by指定split的字段
[root@tianqinglong01 sqoop]# bin/sqoop import --connect jdbc:mysql://tianqinglong03:3306/qfdb
--username root --password 123456
--table emp
--split-by empno
--delete-target-dir
--target-dir hdfs://tianqinglong01:9000/sqoop/emp
-- 出错
caused by:java.sql.SQL Exception: nu11,message from server:"Host
'tianqinglong01' is not allowed to connect to this MySQL server"
解决方案
先连接mysql
[root@tianqinglong01 sqoop]# mysql -u root -p
使用下面的语句: . :所有库下的所有表 % : 任何IP地址或主机都可以连接
mysql> GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'mysql' WITH GRANT OPTION;
FLUSH PRIVILEGES;
grant all privileges on .to 'root'@'localhost' identified by 'mysql' with grant option;
FLUSH PRIVILEGES;
Sqoop导出
在sqoop中,使用export进行导出,指的是从hdfs导出数据到MySQL
1、构建mysql的表
create table 'u2'(
`id` int(11) default null,
`age` int(11) default '0'
)engine=innoDB default charset=utf8;
create table 'u3'(
`id` int(11) default null,
`name` varchar(20) default null,
`age` int(11) default '0'
)engine=innoDB default charset=utf8;
# 先导入hdfs才能导出嘛
2.从HDFS导出到mysql
[root@tianqinglong01 sqoop]# sqoop export --connect jdbc:mysql://tianqinglong01:3306/qfdb
--username root
--password root
--table u2
--driver com.mysql.jdbc.Driver
--export-dir '/sqoop/emp1/*'
-m 1
# 方法二
先重新导入数据:
[root@tianqinglong01 sqoop]# sqoop import --connect jdbc:mysql://tianqinglong01:3306/qfdb
--username root
--password root
--query 'select id,name,age from stu where id>6 and $CONDITIONS'
--driver com.mysql.jdbc.Driver
--target-dir '/sqoop/emp1/*'
--split-by id
-m 1
--field-terminated-by 't'
--null-string 'N'
--null-non-string '0'
导出数据
[root@tianqinglong01 sqoop]# sqoop export --connect jdbc:mysql://tianqinglong01:3306/qfdb
--username root
--password root
--table u3
--driver com.mysql.jdbc.Driver
--export-dir '/sqoop/emp1/*'
--input-fields-terminated-by 't'
--input-null-string '\N'
--input-null-non-string '\N'
-m 1
要注意以下问题
- mysql表的编码格式做为utI8,hdfs文件中的列数类型和mysql表中的字段数一样
- 导出暂不能由hbase表导出mysql关系型数据库中
--export-dir是一个hdfs中的目录,它不识别_SUCCESS文件–query导入的时候注意设置问题。- 导出数据中有些列值有"null"。会报没法解析
- 导出数据的类型需要和mysql中的一致[能自动转没有问题)
sqoop的job
增量导入数据
使用场景:
- 经常被操作不断产生敌据的表。建议增量。
- 当某表基数很大,但是变化很小。也建议增量
使用方式
- 1、query where :能精确锁定数据范围
- 2、–incremental:增量,最后记录值来做的
query where方式:
通过查询具体日期的方式进行导入新建一个脚本文件
[root@hadoop01 sqoop]vi ./import.sh
写入以下内容:
#!/bin/bash
# yesterday= `date -d "1 days ago" "+%Y-%m-%d"`
yesterday='2019-82-01'
sqoop import --connect jdbc:mysql://tianqinglong01:3306/sales_source
--username root
--password 123123
--query "select * from sales_order where DATE(order_date) ='${yesterday}' and $CONDITIONS"
--driver com.mysal.jdbc.Driver
--delete-target-dir
--target-dir /user/hive/warehouse/sales_order/dt=${yesterday}
--split-by id
-m 1
--fields-terrminated-by 't'
--null-string '\N'
--null-non-string '0'
通过下面hdfs可以快速查询到结果:
[root@hadoop01 sqoop]# hdfs dfs -cat /user/hive/warehouse/sales_order/dt=2019-01-01/*
Job基本操作
job的好处:
1、一次创建,后面不需要创建。可重复执行job即可
2、它可以帮我们记录增量导入致据的最后记录值
3、job的元致据默认存储目录:$HOME/.sqoop/
4、job的元数据也可以存储于mysql中。
列出sqoop的job
[root@tianqinglong01 sqoop]# sqoop job --list
创建一个sqoop的job
[root@tianqinglong01 sqoop]# sqoop job
--create job1 --import --connect jdbc:mysql://tianqinglong01:3306/qfdb
--username root --password 123456
--table emp
--target-dir '/sqoop/job/job1'
--delete-target-dir
-m 1
查看sqoop的job
[root@tianqinglong01 sqoop]# sqoop job --show job1
删除job
[root@tianqinglong01 sqoop]# sqoop job --delete job1
执行
[root@tianqinglong01 sqoop]# sqoop job --exec job1
问题:
1、创建job报错:19/12./02 23:29:17 ERROR sooop.S4oop: got exception running Saoop:java.lang.NullPointerException
java.lang.NullPointerException
at org.json.JsON0bject.cinit>(Js0NObject.jaa:144)
解决办法:
添加java-json.jar包到sqoop的lib目录中。
如果上述办法没有办法解决,请注意hcatlog的版本是否过高,过高将其hcatlcg包删除sqoop的lib日录即可。
2、报错: Caused by: java.lang.ClassNotFoundException: org.json.JSONObject
解决办法:
添加java-json.jar到sqoop的lib目录中。
metastore服务
metastore服务是元数据服务,用于存储sqoop的job相关信息。将信息保存于关系型数据库中。
优点:
1、job信息更加有保障
2、多个client之间贡献job信息。
(1)在mysql创建sqoop的元数据存储数据库(如果由root可以用root)
create database sqoop;
create user 'sqoop'@'%' identified by 'sqoop';
grant all privileges on sqoop.* to 'sqoop'@'%';
flush privileges;
(2)配置Sqoop的元数据存储参数
在$SQOOP_HOME/conf/sqoop-site.xml中添加以下的参数,在/code/sqoop-site.xml也可以查阅。
sqoop.metastore.server.location:指定元数据服务器位置,初始化建表时需要。sqoop.metastore.client.autoconnect.url:客户端自动连接的数据库的URL。sqoop.metastore.client.autoconnect.username:连接数据库的用户名。sqoop.metastore.client.enable.autoconnect:启用客户端自动连接数据库。
sqoop.metastore.client.record.password:在数据库中保存密码,不需要密码即可执行sqoop job脚本。sqoop.metastore.client.autoconnect.password:连接数据库的密码。
<property>
<name>sqoop.metastore.client.enable.autoconnect</name>
<value>false</value>
</property>
<property>
<name>sqoop.metastore.client. autoconnect.url</name>
<value>jdbc:mysql://192.168.10.103:3306/sqoop</value>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.username</name>
<value>root</value>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.password</name>
<value>123456</value>
</property>
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
</property>
<property>
<name>sqoop.metastore.server.location</name>
<value>/usr/local/sqoop/sqoop-metastore/shared.db</value>
</property>
<property>
<name>sqoop.metastore.server.port</name>
<value>16000</value>
</property>
(3)重启Sqoop服务
保存配置并重启完成后,MySQL的sqoop库中有了一个名为SQOOP_ROOT的空表。
#启动:
[root@tianqinglong01 sqoop1.4.7]# sqoop metastore &
#查看进程:
[root@tianqinglong01 sqoop1.4.7]# jps
sqoop
#关闭:
[root@tianqinglong01 sqoop1.4.7]# sqoop metastore --shutdown
[root@tianqinglong01 conf]# sqoop job --list --meta-connect 'jdbc:mysql://tianqinglong03/sqoop?user=root&password=123456'
(4)预装载SQOOP表
insert into SQOOP_ROOT values (NULL,'sqoop.hsqldb.job.storage .version','0' );
(5)将表的存储引擎修改为MYISAM(如job信息存储到mysql的SQOOP_SESSIONS则不用执行如下)
alter table SQOOP_ROOT engine=myisam;
alter table SQOOP_SESSIONS engine=myisam;
(6)job相关操作

最后
以上就是自然戒指最近收集整理的关于Sqoop学习Sqoop的简介Sqoop的安装Import的控制参数sqoop导入案例 mysql到hdfsMysql到hive导入数据库没有主键的问题Sqoop导出sqoop的job的全部内容,更多相关Sqoop学习Sqoop的简介Sqoop的安装Import的控制参数sqoop导入案例内容请搜索靠谱客的其他文章。



![Day14[20200726]一、回顾二、SQOOP课程安排](https://www.shuijiaxian.com/files_image/reation/bcimg10.png)




发表评论 取消回复