列表(list)
列表
-
可以包含不同类型, 数字,字符串…,属于一种序列:
Aa[0] 表示第一个, Aa[-1] 等价于 Aa[len(Aa)-1] 表示最后一个

- 列表切片和跨度
a[0:2]
[1, 2]
a[2:]
[4, 'kky']
a[:](简写,头尾不写)
[1, 2, 4, 'kky']
a[0:3:2]
[1, 4]
a[::-2] (跨度-2,反向)
['kky', 2]
* a[::-1](倒叙打印)*
['kky', 4, 2, 1]
NOTE:列表切片并不会修改列表自身的组成结构和数据, 它其实是为列表创建一个新的拷贝(副本)并返回。
Eg.返回列表最后10位

列表的操作
| 方法 | 含义 |
|---|---|
| 增 | |
| s.append(x) | 将 x 元素添加到 s 列表的末尾,相当于s[len(s):] = [x] |
| s.extend(iterable) | 将可迭代对象中的每个元素依次添加到 s 列表的末尾,相当于s[len(s):] = iterable[3, 4, 5] |
| s.insert(i, x) | 将 x 元素插入到 s 列表中的 i 位置(其它元素依次往后递推)。所以,s.insert(0, x)是将 x 元素插入到 s 列表的开头;s.insert(len(s), x)则是将 x 元素插入到 s 列表的末尾,等同于s.append(x) |
| 删 | |
| s.remove(x) | 删除 s 列表中第一个 x 元素(如存在多个匹配元素);如果列表中不存在 x 元素,则抛出ValueError异常 |
| s.pop(i) | 删除 s 列表中第 i 个元素,并将其返回;如果没有指定 i 参数,s.pop()将删除最后一个元素并返回 |
| s.clear() | 删除 s 列表中的所有元素,相当于del a[:] |
| Del s[0] or del s | 前者删除一个元素,后者直接删除变量s(再次调用会报错) |
| 查 | |
| s.index(x[, start[, end]]) | 返回 x 元素位于 s 列表的索引值(start 和 end 可选,指定开始和结束位置,不过返回的索引值仍然是以序列开始位置计算的);如果找不到,则返回ValueError异常 |
| s.count(x) | 返回 x 元素在 s 列表中出现的次数 |
| 改 | s[3] = [“3”, “4”] 直接替换第四和五个元素 |
| s.sort(key=None, reverse=False) | 对列表中的元素进行原地排序(key 参数指定一个用于比较的函数;reverse 参数用于指定排序结果是否反转), 注意这里改变的是原列表 |
| s.reverse() | 原地反转列表中的元素(第一个与最后一个互换,第二个与倒数第二个互换,第三个与倒数第三个互换,…)并不是排序,只是调换顺序 |
| s.copy() | 返回 s 列表的一个浅拷贝,相当于s[:],新列表和原来的没关系; 另一种浅拷贝, 赋值型s2 = s ,这个时候s2或者s改变,对方都会相应做改变 |
Eg1.判定一个括号([{ 是否合法,成对出现,左右配对
s = input("请输入测试字符串:")
# 创建一个特殊列表
stack = []
for c in s:
# 如果是左括号,那么添加到特殊列表中
if c == '(' or c == '[' or c == '{':
stack.append(c)
# 如果是右括号的情况
else:
# 如果碰到右括号,但特殊列表中没有左括号,那么肯定是非法的
if len(stack) == 0:
print("非法T_T")
break
# 逐个给出 c 对应的右括号 d
if c == ')':
d = '('
elif c == ']':
d = '['
elif c == '}':
d = '{'
# 对比 d 和从特殊列表尾部弹出的元素
if d != stack.pop():
print("非法T_T")
break
else:
# 如果循环走完,特殊列表不为空,那么肯定是左括号比右括号多的情况
# 那肯定有同学会问:右括号比左括号多的情况在哪里判断?
# 小甲鱼答:在上面 d != stack.pop() 的判断中已经可以排除了~
if len(stack) == 0:
print("合法^o^")
else:
print("非法T_T")
Eg2. 查找列表中相同元素的最后一个元素index
#建副本反转
>>> nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 8, 8, 5, 6, 3, 2, 1, 2]
>>> nums_copy = nums.copy()
>>> nums_copy.reverse()
>>> len(nums_copy) - 1 - nums_copy.index(1)
15
#暴力搜寻:
>>> count = nums.count(1)
>>> length = len(nums)
>>> for each in range(length):
... if nums[each] == 1:
... count -= 1
... if count == 0:
... print(each)
... break
15
Eg3. 摩尔投票法
摩尔投票法分为两个阶段:
对抗阶段:分属两个候选人的票数进行两两对抗抵消
计数阶段:计算对抗结果中最后留下的候选人票数是否有效
工作原理想象为诸侯争霸,假设每个国家都是全民皆兵,并且打起仗来都是以 1 换 1 的形式消耗人口,当一个国家人口总数为 0,那么 Gameover,OK,如果某国人口数量超过所有国家总人口的一半,最终赢家就肯定是它
(相邻连个元素比较,若相同计数加1,否则抵消计数归0,后面的遍历继续比较)
nums = [2, 2, 4, 2, 3, 6, 2]
# 对抗阶段
major = nums[0]
count = 0
for each in nums:
if count == 0:
major = each
if each == major:
count += 1
else:
count -= 1
# 统计阶段
if nums.count(major) > len(nums) / 2:
print("主要元素是:", major)
else:
print("不存在主要元素。")
列表的加法和乘法
-
加法:列表的拼接,两边都是列表
-
乘法:重复列表的条目若干次
-
嵌套列表(nested list): 二维列表,matrix 举证
matrix = [[1, 2, 3],[3, 4, 5],[5, 6, 7]]
打印嵌套列表元素:
for i in matrix:
for each in i:
print(each, end=' ')
print()
is 同一性运算符,检验两个对象是否指向**同一个对象*
a = 250
b = 250
a is b
出于性能优化方面的考虑,Python 在内部为 -5~256 范围内的整数维护了一个数组,起到缓存的作用。这样,每次你试图创建一个 -5~256 范围内的整数时,Python 都会从这个数组中返回相对应的引用,而不是重新开辟一块新的内存空间存放。
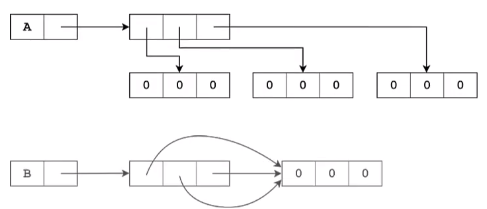
- 获得嵌套列表:
- 使用遍历得到嵌套列表(不同的内存空间)–> 推荐此法
a = [0] * 3
for i in range(3):
a[i] = [0] * 3
- 使用乘法得到嵌套列表(指针的copy)
b = [[0] * 3] * 3
b
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
a[1][1] = 1
a
[[0, 0, 0], [0, 1, 0], [0, 0, 0]]
b[1][1] = 1
b
[[0, 1, 0], [0, 1, 0], [0, 1, 0]]
#使用 is 来判断是否为同一对象
a[0] is a[1]
False
a[1] is a[2]
False
b[0] is b[1]
True
b[1] is b[2]
True
#内存中布局:
列表去重
old = [‘西班牙’, ‘葡萄牙’, ‘葡萄牙’, ‘匈牙利’, ‘牙买加’]
new = []
for each in old:
if each not in new:
new.append(each)
Print(new)
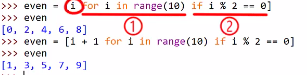
列表推导式
==> 就相当于for循环创建列表的简化版
[expression for target in interable if expression]
代码解释:
1.列表推导式会遍历后面的可迭代对象,然后按照for前的表达式进行运算,生成最终的列表.
2.如果有if条件语句,for遍历后紧跟着进行条件判断.
3.如果有多个for循环,则最终的数据数量为多个for循环的笛卡尔积.( 所谓[笛卡尔积]通俗点说就是指包含两个集合中任意取出两个元素构成的组合的集合. )
4.可以进行嵌套的列表推导,与嵌套for循环的原理相同.
————————————————
区别在于,循环是将元素加入已存列表,而推导式是创建一个全新的列表然后赋值原来的变量名
- 加筛选分句
[expression for target in iterable if condition]
执行顺序:for --> if --> i
- 加嵌套
[expression for target1 in iterable1
for target2 in iterable2
for targetN in iterableN]
Eg. 外层循环在前,内层在后
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flatten = [col for row in matrix for col in row]
flatten
[1, 2, 3, 4, 5, 6, 7, 8, 9]
==> flatten = []
for row in matrix:
for col in row:
flatten.append(col)
Eg: "_" 可以作为临时变量名(无关紧要)
s = [ x + y for x in 'fishc' for y in 'FISHC']
s
['fF', 'fI', 'fS', 'fH', 'fC', 'iF', 'iI', 'iS', 'iH', 'iC', 'sF', 'sI', 'sS', 'sH', 'sC', 'hF', 'hI', 'hS', 'hH', 'hC', 'cF', 'cI', 'cS', 'cH', 'cC']
_ = []
for x in 'fishc':
for y in 'FISHC':
_.append(x + y)
- 嵌套+筛选
[expression for target1 in iterable1 if condition1
for target2 in iterable2 if condition2
for targetN in iterableN if condtionN]
Eg:
_ = []
_ = [[x, y] for x in range(10) if x % 2 == 0 for y in range(10) if y % 3 ==0]
_
[[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]]
等价:
for x in range(10):
if x % 2 == 0:
for y in range(10):
if y % 3 == 0:
_.append([x, y])
EG:
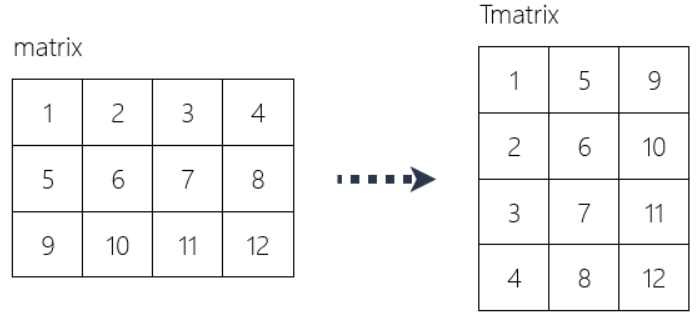
Tmatrix = [[row[i] for row in matrix] for i in range(4)]
Tmatrix
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
相当于
transposed = []
for i in range(4):
... transposed.append([row[i] for row in matrix])
Eg. Find a lucky number: 同行最小,同列最大
matrix = [[10, 36, 52],
[33, 24, 88],
[66, 76, 99]]
row = len(matrix)
col = len(matrix[0])
min_row = [1024] * row
max_col = [0] * col
for i in range(row):
for j in range(col):
min_row[i] = min(matrix[i][j], min_row[i])
max_col[j] = max(matrix[i][j], max_col[j])
print(min_row)
print(max_col)
for i in range(row):
for j in range(col):
if matrix[i][j] == min_row[i] and matrix[i][j] == max_col[j]:
print("row:", i, "col:", j)
print("number is: ", matrix[i][j])
else:
print("no such number")
KISS = keep it simple & stupid 代码写的原则
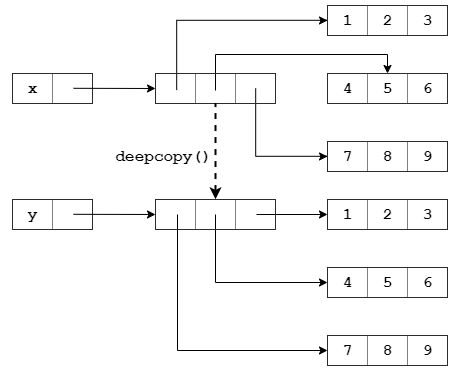
浅拷贝和深拷贝
-
浅拷贝:s.copy() or 切片s1 = s[:]
-
当浅拷贝包含嵌套列表的时候,s.copy()只是引用
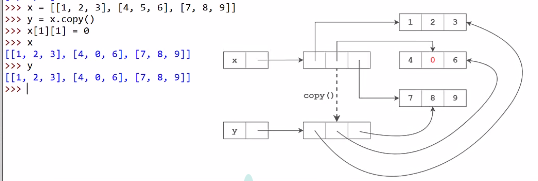
-
深拷贝 copy 函数:
import copy --> copy.deepcopy()连嵌套的对象也一起都copy,什么都copy

元组(tuple)
元组概念
- 像列表同事容纳多种类型,也拥有字符串不可变的特性,阉割版列表?优点更安全
列表 = [0, 1, 2, 3 …]
元组 = (0, 1, 2, 3…) (note: 也可以不带括号,也能用下标获取元素, 元组内容不可变, 可使用切片)
- 元组只能查 – count and index
- 支持拼接(+)和重复(*)
- 支持嵌套
- 没有元组推导式
m = (1, 2, 4)
n = (3, 4, 5)
m + n
(1, 2, 4, 3, 4, 5)
m * 3
(1, 2, 4, 1, 2, 4, 1, 2, 4)
k = m, n
k
((1, 2, 4), (3, 4, 5))
- 如何生成仅含一个元素的元组(一定得有逗号,不然就是int)
S = (34, )
- 空元组是 S = ()
- 包含列表元素的元组是可变的
i = [1, 2, 4]
j = [3, 5, 6]
l = (i, j)
l
([1, 2, 4], [3, 5, 6])
l[0][1] = 33
l
([1, 33, 4], [3, 5, 6])
- 解包:x, y, z = argv (元组或字符串)
封装:创建元组
a, *b, c = "FishC"
>>>a
'F'
>>>b
['i', 's', 'h']
>>>c
'C'
字符串(str)
字符串概念
- 根本上是序列
eg.
# 字符串切片法证明回文数
x = "12321"
"是回文数" if x == x[::-1] else "不是回文数"
'是回文数'
#递归法:
def is_palindromic(n, start, end):
if start > end:
return 1
else:
return is_palindromic(n, start + 1, end - 1) if n[start] == n[end] else 0
string = input('Please input a string here: ')
if is_palindromic(string, 0, (len(string) - 1)):
print(string + 'is a palindromic')
else:
print(string + 'is not a palindromic')
字符串方法
- 大小写字母换来换去
capitalize(第一个单词首字母大写)
casefold(所有字母小写,可以用于其他语言)
title(所有单词首字母大写)
Swapcase(所有字母大小写翻转)
upper(所有字母大写)
lower(所有字母小写,仅用于英语)
- 左中右对齐:
Center(width, fillchar=’ ') 居中,width需大于字符串长度
Ijust(width, fillchar=’ ') 左对齐
Rjust(width, fillchar=‘’) 右对齐
Zfill(width) 用0填充左侧
-
字符串 功能
- 查找功能
Count(sub[, start[, end]]) – 查找子字符串出现次数
find(sub[, start[, end]]) — 从左往右查找,返回下标值
rfind(sub[, start[, end]]) — 从右往左查找
index(sub[, start[, end]]) — 和find一样
rindex(sub[, start[, end]])
Note: find() 和 index()的区别在于查找一个不存在的字符时,find返回-1, index会抛出异常
- 替换
Expandtabs([tabsize=8]) — 将tab换成多少个空格(size指定)
Replace(old, new, count=-1) —将old 字符串替换成new, count -1 代表替换所有
Translate(table) <— str.maketrans(x[, y[, z]]) 得到table
Table x 表示原字符串,y表示替换的字符串,z表示忽略的字符串 "I Love FishC".translate(str.maketrans("ABCDEF", "123456")) 'I Love 6ish3' "I Love FishC".translate(str.maketrans("ABCDEF", "123456", "Love")) 'I 6ish3*'- 判断
Startswith(prefix[, start[, end]]) — 判断字符串是否出现在起始位置,可指定开始/结束位置
endswithswith(prefix[, start[, end]])— 判断字符串是否出现在起始位置,同上
note: 两个函数也支持传入元组来匹配多个项 x = "我爱Pyhon呀!" x.startswith(("你", "我", "她")) TrueIsupper() – 是否所有字符都大写
Islower() – 是否所有字符都小写
istitle() – 所有字符首字母大写
Isalpha() – 字符中只有字母构成
Isascii() – 是否为ASCII
Isspace() — 空格,tab, n 都是空白space
Isprintable() — 转义字符不可打印
isdecimal() —十进制
Isdigit() — 范围比decimal大
Isnumeric() — 简体/繁体/罗马数字。。。都支持
Isalnum() — (如果isalpha(), isdecimal(), isnumeric(), isdigit() 中任意是true的话,此isalnum就会返回true,集大成者)
Isidentifier() — 判断字符串是否为python合法标识符,和变量名规则相似,不能以数字开头
keyword 函数中iskeyword来判断是否为python保留字符like if/else
- 截取
strip(chars=None) – 去除左右侧空白
lstrip(chars=None) – 去除左侧空白
rstrip(chars=None) – 去除右侧空白
当给定字符时就能从左向右依次去掉指定的单个字符直到碰到第一个不匹配项停止并返回截取部分 "w3ww.cbaiddc.com.cobm".strip("wcom.") # 从左右分别开始匹配 '3ww.cbaiddc.com.cob' "w3ww.cbaiddc.com.cobm".lstrip("wcom.") # 从左边匹配 '3ww.cbaiddc.com.cobm'py3.9后
removeprefix(prefix) – 去掉制定的前缀
removesuffix(suffix) – 去掉制定的后缀
"www.baidu.com".removeprefix("www.")- 拆分和拼接
partition(seq) — 通过给定分隔符将字符串从左往右分割并返回一个**三元组*
rpartition(seq) – 同上, 从右往左分割
split(seq=None, maxsplit=-1) — 默认切割空格并以列表形式返回, seq 为分隔符,maxsplit 为切几刀,-1表示找到分隔符就切,如果为1表示切一刀就返回,
rsplit(seq=None, maxsplit=-1)
splitlines(keepends=False) — 按行切割,结果以列表返回,默认参数为False 表示不带换行符,为True表示带换行符, r n rn
"苟日新\r\n日日新\n又日新".splitlines() ['苟日新', '日日新', '又日新'] "苟日新\r\n日日新\n又日新".splitlines(True) ['苟日新\r\n', '日日新\n', '又日新']join(iterable) — 拼接, 速度比字符串“+” 要快很多,最前面的表示要拼接的分割符
".".join(["www", "google", "com"]) 'www.google.com' ".".join(("www", "google", "com")) 'www.google.com' "".join(["google", "google"]) 'googlegoogle'
字符串的格式化
format()方法
- 格式:
"{}{}".format(x, y) --> x, y分别赋给前面的{}{},支持自定义顺序,取元组里面的下标,或者手动指定值
"看到我的{1}{name},你的第一{2}是{0}".format("奇怪", "帅气", "反应", name="名字")
'看到我的帅气名字,你的第一反应是奇怪'
- 语法:
format_spec ::= [[fill]align][sign][#][0][width][grouping_option][.precision][type] fill ::= <any character> align ::= "<" | ">" | "=" | "^" sign ::= "+" | "-" | " " width ::= digit+ grouping_option ::= "_" | "," precision ::= digit+ type ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" | "n" | "o" | "s" | "x" | "X" | "%"
- Align用法:

我们将位置索引和格式化语法使用冒号(:)进行分隔:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TTXJDVb6-1649859000915)(…/resources/image25-30.png)]
两种方法补0,符号后面,数字前面
"{:010}".format(-250) (仅对数字类型生效,如果-250改为字符串将报错)
'-000000250'
"{:0=10}".format(-334)
'-000000334'
- [fill]用法
冒号后跟填充符
“{1:%>10}{0:%<10}”.format(“250”, “520”)
‘%%%%%%%520250%%%%%%%’
- 字符串[sign] — “+ - 空格”
符号化 – 仅数字类型
+ 加上整数
- 默认行为
"{:+}{:-}".format(250, -520)
'+250-520'
-
group option
{:,} or {:_} 表示千分位分隔符(grouping_option),
"{:,}".format(234567)
'234,567'
"{:_}".format(234567)
'234_567'
- 关于精度(precision)

"{:.2f}".format(3.1415926)
'3.14'
"{:.2g}".format(3.1415926)
'3.1'
"{:.2}".format("Hello World!")
'He'
"{:.2}".format(234)
ValueError: Precision not allowed in integer format specifier
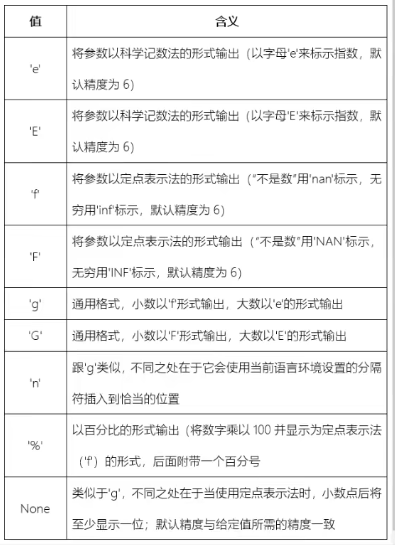
- 关于类型(type)
决定字符串如何呈现
- 适用于整数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zD45celF-1649859000916)(../resources/image27-26.png)]](https://www.shuijiaxian.com/files_image/2023060823/c38ac5fd157a4071a827c9530555d80b.png)
"{:b}".format(8) --> 1000
"{:x}".format(80) -->'50'
"{:#b}".format(8) --> 0b1000 (# 用于提示当前字符为什么类型)
- 浮点数和复数
"{:e}".format(12345555)
'1.234556e+07'
"{:E}".format(12345555)
'1.234556E+07'
"{:f}".format(123.455)
'123.455000'
"{:g}".format(123.455)
'123.455'
"{:%}".format(0.123455)
'12.345500%'
可以赋值法:
“{:{fill}{align}{width}.{prec}{type}}”.format(3.14, fill = “+” , align = “^”, width = “10”, prec = “4”, type = “g” )
‘+++3.14+++’
f-字符串(F-String)
- 是一种语法糖,简化字符串格式化的方法,更简洁,在前面加上"f" or “F”,即可,字符串如果包含
{xxx},就会以对应的变量替换,version > 3.6

f"{90:2b}"
'1011010'
f"{3.14145:.2f}"
'3.14'
f"{3.14145:.2g}"
'3.1'
fill = "+"
align = "^"
width = "10"
prec = "4"
type = "g"
f"{3.1415:{fill}{align}{width}.{prec}{type}}"
'++3.142+++'
格式化符号含义
如果字符串中需要出现%, 使用%%表示,print('Math grade: %d %%' % 7) --> 7%
| 符号 | 说明 |
|---|---|
| %c | 格式化字符及其 ASCII 码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同 %e,用科学计数法格式化浮点数 |
| %g | 根据值的大小决定使用 %f 或 %e |
| %G | 作用同 %g,根据值的大小决定使用 %f 或者 %E |
格式化操作符辅助命令
| 符号 | 说明 |
|---|---|
| m.n | m 是显示的最小总宽度,n 是小数点后的位数 |
| - | 用于左对齐 |
| + | 在正数前面显示加号(+) |
| # | 在八进制数前面显示 ‘0o’,在十六进制数前面显示 ‘0x’ 或 ‘0X’ |
| 0 | 显示的数字前面填充 ‘0’ 取代空格 |
Python 的转义字符及其含义
| 符号 | 说明 |
|---|---|
| ’ | 单引号 |
| " | 双引号 |
| a | 发出系统响铃声 |
| b | 退格符 |
| n | 换行符 |
| t | 横向制表符(TAB) |
| v | 纵向制表符 |
| r | 回车符 |
| f | 换页符 |
| o | 八进制数代表的字符 |
| x | 十六进制数代表的字符 |
| � | 表示一个空字符 |
| \ | 反斜杠 |
序列
- 列表/元组/字符串 — 同父异母亲兄弟 — 统称 *序列
- 支持索引获取每一个元素
- 第一个索引值为0
- 都可以通过切片的方法获取一个范围
- 都有很多共同的运算符
根据是否能被修改,分为可变(列表)和不可变(元组 字符串)序列
- 可作用于序列的运算符和函数
运算符:+(拼接) *(重复)
python中每一个对象有三个属性:唯一标志 + 类型 + 值
- 唯一标志 — 对象身份证,id() bif函数可返回这个身份证值
m = [1, 2, 3]
id(m)
1211259326016
m *= 2
m
[1, 2, 3, 1, 2, 3]
id(m)
1211259326016
- 同一性运算符:
is / is not — 用于检测对象的id值是否相等,从而判断是否为同一对象
in / not in —判断某个元素是否包含在序列中
del — 用于删掉一个或多个指定对象
x = [1, 2, 4]
y = [1, 2, 4]
x is y
False
x is not y
True
"fish" in "fishc"
True
"fish" not in "fishc"
False
eg. del 用法
x = [1, 2, 3, 4, 5]
del x (# 全部删除)
x
Traceback (most recent call last):
File "<pyshell#97>", line 1, in <module>
x
NameError: name 'x' is not defined
x = [1, 2, 3, 4, 5]
del x[1:4] (# 支持切片,删特定元素)
x
[1, 5]
x = [1, 2, 3, 4, 5]
x[1:4] = [] (# 单用切片可同样使用)
x
[1, 5]
x = [1, 2, 3, 4, 5]
del x[::2] (# 支持step, 但是切片法不支持这种删除step数)
x
[2, 4]
x = [1, 2, 3, 4, 5]
x[::2] = []
Traceback (most recent call last):
File "<pyshell#108>", line 1, in <module>
x[::2] = []
ValueError: attempt to assign sequence of size 0 to extended slice of size 3
序列的方法
-
列表、元组,字符串相互转换
– list(), tuple(), str()(只是加个引号) -
min() / max() --对比传入的函数得到min/max值
-
min(iterable, *[, key, default]) — default表示min()无法比较的时候抛出的东西
-
min(arg1, arg2, *args[, key])
-
max(iterable, *[, key, default])
-
max(arg1, arg2, *args[, key])
s = [1, 2, 3, 4, 5]
min(s)
1
t = "PeanutfisC"
max(t) --- 比较字符的编码值,F < f
'u'
x = []
min(x)
Traceback (most recent call last):
ValueError: min() arg is an empty sequence
min(x, default = "Hey buddy, I can compare nothing if you are nothing!")
'Hey buddy, I can compare nothing if you are nothing!'
- **len() ** – 调用C来计算,读取C结构体的对象长度,限制为:32位范围2^31-1, 64位是2^63-1
sum(x[, start=y]) — 求和,从y开始相加
len((1, 2, 3, 4, 5))
5
len("peanutfish")
10
sum([1, 2, 3, 4, 5], start = 5)
20
-
sorted() / reversed()
sorted() – 返回一个全新的列表,不同于(列表的s.sort() 表示源列表被改), 可接受任何可迭代对象作为参数对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
sorted(s, reverse=True) – 倒序
sorted(s, key=len) — key是排序方法,这里引入len函数,无括号
s = ["peach", "pitaya", "durain", "dragon", "tangerine"]
sorted(s)
['dragon', 'durain', 'peach', 'pitaya', 'tangerine']
sorted(s, reverse = True)
['tangerine', 'pitaya', 'peach', 'durain', 'dragon']
sorted(s, key = len)
['peach', 'pitaya', 'durain', 'dragon', 'tangerine']
reversed() — 返回的是一个参数的反向迭代器(相当于可迭代对象),使用list()可以表示出来。
reversed([1, 2, 3, 4])
<list_reverseiterator object at 0x00000284DF0B48B0>
list(reversed("peanutfish"))
['h', 's', 'i', 'f', 't', 'u', 'n', 'a', 'e', 'p']
all() — 元素所有为真
any() – 元素任意一个为真
x = [1, 1, 0]
all(x)
False
any(x)
True
enumerate() — 用于返回一个枚举对象,它的功能是将可迭代对象中的每个元素以及从0开始的序号共同构成一个二元组的列表
ss = ["Spring", "Summer", "Autumn", "Winter"]
enumerate(ss)
<enumerate object at 0x00000284DF0CFC80>
list(enumerate(ss))
[(0, 'Spring'), (1, 'Summer'), (2, 'Autumn'), (3, 'Winter')]
>> list(enumerate(ss, start = 10)) -- 表示序号从10开始
[(10, 'Spring'), (11, 'Summer'), (12, 'Autumn'), (13, 'Winter')]
zip() — 用于创建一个聚合多个可迭代对象的迭代器。会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第i个元组包含来自每个参数的第i个元素。如果每个对象的长度不一致,则以最短为准。会丢弃多余的元素在长对象里面。
通过itertools 里面的zip_longest() 可以解决这个问题, ord
x = [1, 2, 3]
y = (4, 5, 6)
z = "Peanut"
zipped = zip(x, y, z)
list(zipped)
[(1, 4, 'P'), (2, 5, 'e'), (3, 6, 'a')]
import itertools
zipped = itertools.zip_longest(x, y, z)
list(zipped)
[(1, 4, 'P'), (2, 5, 'e'), (3, 6, 'a'), (None, None, 'n'), (None, None, 'u'), (None, None, 't')]
map(func, iterator obj) — 会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回的运算结果的迭代器。
>>> list(map(str, [1, 2, 3]))
['1', '2', '3']
pow(x, y) = x ** y
如果对象的长度不一致,则以最短为准,其余丢弃
filter(func, iterator obj) — 会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素以迭代器的形式返回。
>>> list(filter(int, ['0', '1', '2']))
['1', '2']
迭代器 vs 可迭代对象
-
一个迭代器肯定是一个可迭代对象
-
可迭代对象可以重复使用而迭代器则是一次性的
iter() — 是可迭代对象变为迭代器
type() — 看元素类型
next() — 依次提取迭代器的每个元素,每次一个
next(x, “没有啦”) – 如果迭代器没元素了就是说"没有啦"
字典
introduction
Python 的字典有好多个名称(“映射”、“哈希”、“散列"或者"关系数组”),那你知道为什么字典会被称为 Hash(散列函数是用于从数据中创建小的数字指纹的方)法。
你知道为什么字典对于键(Key)的存储数据要求比较严格(可哈希对象不能是变量(列表,字典…etc)),但对于对应的值(Value)的存储却要求很宽松

如图,Python 调用内部的散列函数,将键(Key)作为参数进行转换,得到一个唯一的地址(这也就解释了为什么给相同的键赋值会直接覆盖的原因,因为相同的键转换后的地址是一样滴),然后将值(Value)存放到该地址中。
对于 Python 来说,键(Key)必须是可哈希的,换句话说就是要可以通过散列函数计算出唯一地址的。那如果拿一个变量当键(Key)可以吗?肯定不行。因为变量随时都可能改变,不符合可哈希原则!
同样的,列表、字典、集合这些都是可变的,所以都不能做为键(Key)来使用。
元祖做限制:元组中只包括像数字和字符串这样的不可变元素时,才可以作为字典中有效的键(Key)。
-
字典:python中一种映射类型,格式{key:value} eg: {“Nike”:“Just do it”} , 只能通过key检索,区别于序列的用法
dict1 = {"西瓜":"watermalon", "火龙果":"pitaya", "柠檬":"Lemon", "黄瓜":"cucumbe"} dict1["柠檬"] 'Lemon' dict2 = {} #空字典 dict2[1] = "ONE" #随意给定一个key:value,会自动加入字典 dict2 {1: 'ONE'} dict2[1] = "yichi" #通过赋值改value dict2 {1: 'yichi'} help(dict)
字典的创建
- 使用元组/列表创建出mapping, 注意括号数量,工厂dict()函数只有一个参数
- 使用zip函数
- 使用赋值:key不能加引号
- 使用字典嵌套
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
字典内置方法
- dict.fromkeys(S[,v]) -> new dict with keys from S and values equal to v(v default to none) , 不改变原字典的东西
S = 可以是多个, 但是v只能是一个
dict1 = {}
>>> dict1.fromkeys('good','123')
{'g': '123', 'o': '123', 'd': '123'}
dict2 = {}
dict2.fromkeys(("Lakers", "Clipper"), "LA")
{'Lakers': 'LA', 'Clipper': 'LA'}
dict2.fromkeys(("Lakers", "Clipper"), ("LA", "US"))
{'Lakers': ('LA', 'US'), 'Clipper': ('LA', 'US')} #元组作为整体变成value
dict2.fromkeys(("Lakers", "Clipper")) #value 默认为none
{'Lakers': None, 'Clipper': None}
dict2
{}
-
dict.keys() — 列出dict字典的所有key
dict.values() — 列出dict字典的所有value
dict.items() — 元组形式打印
‘21’ in dict1 — 检查成员资格
‘22’ not in dict1
- dict.clear() — 清空字典 (赋值法清空列表有隐患 a = {})
dict.copy()— 浅拷贝(只拷贝外壳,内嵌的东西依然共用), id() 检测地址,和赋值比较(相同的地址)
dict2
{'a': 'A', 'b': 'B'}
dict3 = dict2
dict3
{'a': 'A', 'b': 'B'}
id(dict2)
1515762669376
id(dict3)
1515762669376
dict2.clear()
dict2
{}
dict3
{}
- dict.pop() – 给定key,弹出(删除)值,然后列表中此键值消失
dict.popitem() – 随机弹出项,字典是无序的
dict1.pop("2")
'two'
dict1
{'1': 'one', '3': 'three', '4': 'four'}
dict1.popitem()
('4', 'four')
dict1
{'1': 'one', '3': 'three'}
-
dict.setdefault() – 和get有点像,可添加 键or键值
a.update(b) – 使用b字典的value更新A里面同一key的value
dict1.setdefault("2")
dict1
{'1': 'one', '3': 'three', '2': None}
dict1.setdefault("4","5")
'5'
dict1
{'1': 'one', '3': 'three', '2': None, '4': '5'}
dict5 = {"4":"four"}
dict1.update(dict5)
dict1
{'1': 'one', '3': 'three', '2': None, '4': 'four'}
Nice example:
""" 通讯录程序 """
#menu
print("|--- 欢迎进入通讯程序 ---|")
print("|--- 1:查询联系人资料 ---|")
print("|--- 2:插入新的联系人 ---|")
print("|--- 3:删除已有联系人 ---|")
print("|--- 4:退出通讯录程序 ---|")
contact = {} #初始化一个空字典
#while循环保证一直提示输入
while 1:
instr = int(input("请输入相关的指令代码: "))
if instr == 1:
name = input("请输入联系人姓名: ")
if name in contact:
print(name + ":", contact[name])
print("")
else:
print("输入的用户不存在!")
print("")
if instr == 2:
name = input("请输入联系人的姓名: ")
if name in contact:
print("您输入的姓名在通讯录中已存在 -->>", name, " : ", contact[name])
print("")
if input("是否修改用户的资料(YES/NO):") == "YES":
tel = int(input("请输入用户的联系方式: "))
contact[name] = tel
print("联系人修改为:" + name + ":", contact[name])
print("")
else:
print("返回菜单")
print("")
else:
tel = int(input("请输入用户的联系方式: "))
contact[name] = tel
print("联系人:", name, ":", contact[name],"创建成功!")
print("")
if instr == 3:
name = input("请输入联系人姓名: ")
if name in contact:
print("此联系人已删除: ", name, ":", contact.pop(name))
print("")
else:
print("您要删除的联系人: ", name, " 不存在!")
print("")
if instr == 4:
break
print("|--- 感谢使用通讯程序 ---|")
最后
以上就是淡然大侠最近收集整理的关于python3基础知识复习 -- 列表/元组/字符串/序列/字典的全部内容,更多相关python3基础知识复习内容请搜索靠谱客的其他文章。








发表评论 取消回复