目录
字典:又叫哈希,散列
集合:元素唯一性,可用于数据去重复
字典:又叫哈希,散列
- 字典是映射类型,无序的,字典中的顺序无关紧要。而列表,元组,字符串是序列类型。
- 标志符号:大括号{}
- 字典由多个键和对应值组成,键是唯一的,而值可以不唯一,每个键值组合称为项
- 字典的键必须是可哈希对象,即不可变对象(字符串,整数,不包含可变对象的元组,不可变集合),不能是可变对象(变量,列表,字典本身)。因为字典根据键,通过散列函数来计算值的存储位置,如果键可变,则每次根据同一个key计算出的地址不同,字典内部就会混乱。这又叫哈希算法。散列表时间复杂度为O(1)
- 在字典中,对不存在的key访问赋值会自动创建对应的key并添加相应的值value进去。而在序列中,为不存在的位置进行赋值会报错。
- 字典用空间换时间,查找和插入速度快,不会随着key增加而变慢,但需要占用大量内存。列表占用内存少,查找和插入的时间随着元素的增加而增加。
- 访问字典只要知道键名,不需要知道位置
创建字典:
1.创建空字典:
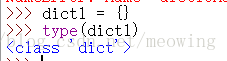
2.键值通过冒号组合,{键:值},‘小古’,‘大黄’,1为键(key),后面的为值(value)

3.dict()以元组的形式创建字典时,它里面只有一个变量 dict(mapping),所以我们将各个元组以一个括号括起来作为一个变量
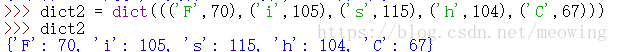
4.dict()以关键字参数创建字典,这种方法的键只能是字符串,不能是整数,否则会报错

修改字典:对原有的键进行重新赋值,覆盖原来的值
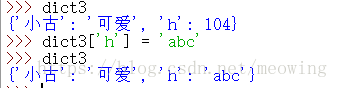
添加字典:添加新的键并同时赋值,如果不同时赋值就会访问报错,KeyError键不存在。

字典的内置函数:
1.fromkeys(键[,值]):当值不指定时,值默认为None;当指定值时,会同时分配给全部键,不能单独对应分配;不能批量修改原有字典,会直接创建一个新的字典,覆盖原有字典

2.keys,values,items(键,值),以列表返回字典的键,值,项

可以用于遍历字典
for eachKey in dict3.keys():
print(eachKey)
for eachValue in dict3.values():
print(eachValue)
for x,y in dict3.items():
print('{}:{}'.format(x,y))3. get(目标键[,备胎]),当访问字典里不存在的键时会报错,而get方法可避免,它会默认返回一个None代表没有这个键。键不存在时返回的值可以自己设定。自己设定的值,只有当目标键不存在时才会返回,键存在时还是会返回原有的值。

等价于用 if + 成员资格符 in/not in 先判断字典中有没有这个键,有就输出值,没有就输出其他东西
if '黄道益' in dict3:
print(dict3['黄道益'])
else:
print('不存在!')4. clear() 清空字典
5. copy() 浅拷贝:申请了新内存,ID地址不同,不会干扰。
直接复制:共用内存堆,ID地址一样,会干扰。

6. pop(键)弹出指定键,popitem()是无序,随机地弹出项

7. setdefault(键,default=‘None’),和get类似,但如果键不存在于字典中,将会添加键并将值设为default,默认为None

往字典中的元素添加数据,我们首先要判断这个元素是否存在,不存在则创建一个默认值。如果在循环里执行这个操作,每次迭代都需要判断一次,降低程序性能。用setdefault更有效率

8. update(新dict) :将新字典的键/值对更新到原字典里

字典中的键映射多个值
1.值value可以为列表和集合

2.defaultdict(初始化参数) 初始化参数分别为 list 和 set,还可用不带参数的可调用函数作为参数



集合:元素唯一性,可用于数据去重复
创建集合:
1. set1 = {1,2,3,4,5} 花括号中的元素没有体现映射关系
2. set() 工厂函数 ,里面可以传递列表,元组,字符串等序列

访问集合:因为集合是无序的,所以不能用索引来访问
1.for遍历集合:
for x in set1:
print(x)2.in/not in 判断集合中有没有某个元素

内置函数:
1. add() 增加元素,重复增加不会报错
2. remove() 删除元素,删除没有的元素会报错

3. len() 集合长度
不可变集合:不能随意增加,删除集合中的元素 frozenset([])
数学运算:因为集合无序,所以可以进行交集,并集运算

最后
以上就是悲凉大叔最近收集整理的关于python学习笔记之字典,集合的全部内容,更多相关python学习笔记之字典内容请搜索靠谱客的其他文章。








发表评论 取消回复