我是靠谱客的博主 曾经月光,这篇文章主要介绍kubelet源码分析 syncLoopIteration(二) plegCh、syncChkubelet源码分析 syncLoopIteration(二) plegCh,现在分享给大家,希望可以做个参考。
kubelet源码分析 syncLoopIteration(二) plegCh、syncCh、relist
上一篇:kubelet源码分析 syncLoopIteration(一) configCh
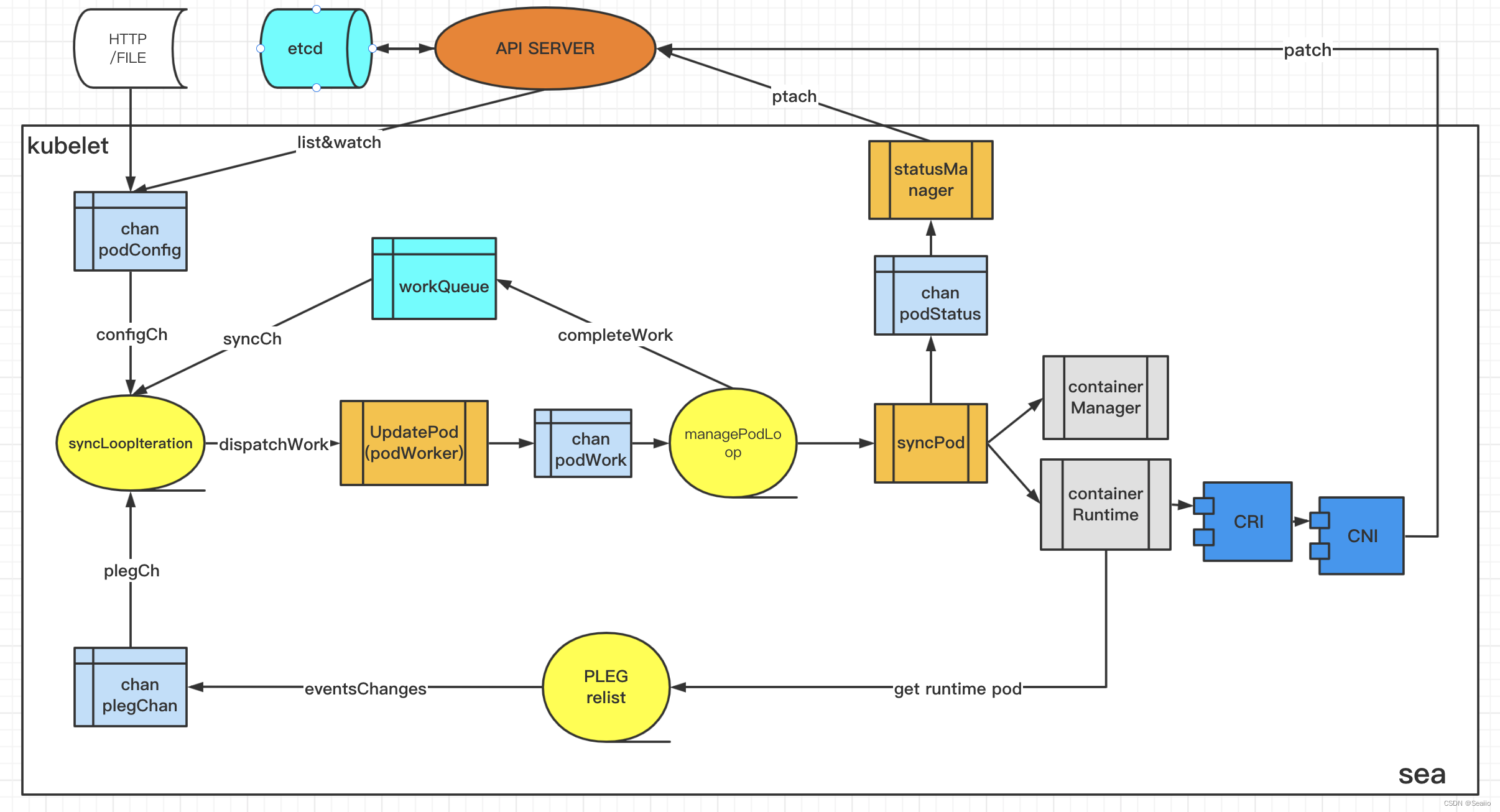
上一篇说了configCh管道的作用,这一篇说一下plegCh管道。这个管道主要是监听容器运行时状态的,当状态有变化后,会触发event然后到syncLoopIteration重新执行同步。
一、plegCh
1.初始化pleg运行
pleg.cache结构与kubelet.podCache与pod_workers.go中podCache,公用的一个结构。当容器有变化,pleg就会触发更新。kubelet.podCache与pod_workers.go中podCache都是同一个,也会变成最新的
- 在kubelet的Run函数中,会执行start
- 在syncLoop执行watch获得pleg的chan管道,传到syncLoopIteration函数中
- start函数会执行一个gorounite函数去每一秒执行一次relist
kl.pleg.Start()
plegCh := kl.pleg.Watch()
func (g *GenericPLEG) Start() {
go wait.Until(g.relist, g.relistPeriod, wait.NeverStop)
}
2.relist函数
- 获得当前时间
- 获得所有pod信息,包括沙箱容器
- 更新relist时间
- 将所有pod的数量做记录
- setCurrent函数,podRecords结构体下有两个podlist,一个新的一个老的。setCurrent是将上面获得的容器运行时的podlist赋值给新的。
- 所有的新老pod的容器组到一起进行遍历。进行新老的对比,如果有event变化,则记录。这里是根据容器id,去新、老pod中去查找这个容器,根据容器状态的变化做校验来确定是哪种event变化(2.1)
- 是否需要再次检查(检查上一次未通过的)
- 遍历有event变化的pod信息
- 如果需要检查,则将pod信息遍历更新,更新失败的记录到需要再次检查的map中
- g.podRecords.update(pid)是将老的pod变成新的,新的清空(为下次relist做准备)
- 遍历这个pod的event变化,如果是不知道的类型,跳过这次。否则,把这次变更推送到eventChannel管道(这个管道上面的kubelet会监听触发plegCh的)
- 同时如果这个event是删除容器,如果容器还没有退出码并且pod还存在切缓存也存在,获得容器运行时状态,并且记录他的所有退出码(这里的event对应的是容器,pod的status对应的是pod,pod可能有很多容器,所以根据pod下面的容器的id进行存储,一次性把pod的所有容器都存下来)
- 如果这个容器是删除的,并且已经有了退出码了,则记录一下日志即可(上面一步可能把所有容器的退出码都记录了,这里直接读取)
- 如果没有event,切需要再次检查一遍上次未通过的,则更新一下最新的信息。
- 更新relist所耗时间
func (g *GenericPLEG) relist() {
klog.V(5).InfoS("GenericPLEG: Relisting")
//获得当前时间
if lastRelistTime := g.getRelistTime(); !lastRelistTime.IsZero() {
metrics.PLEGRelistInterval.Observe(metrics.SinceInSeconds(lastRelistTime))
}
timestamp := g.clock.Now()
defer func() {
metrics.PLEGRelistDuration.Observe(metrics.SinceInSeconds(timestamp))
}()
// 获得所有pod信息,包括沙箱容器
podList, err := g.runtime.GetPods(true)
if err != nil {
klog.ErrorS(err, "GenericPLEG: Unable to retrieve pods")
return
}
g.updateRelistTime(timestamp)
//类型转换一下
pods := kubecontainer.Pods(podList)
//将所有pod的数量做记录
updateRunningPodAndContainerMetrics(pods)
//更新新的pod缓存
g.podRecords.setCurrent(pods)
eventsByPodID := map[types.UID][]*PodLifecycleEvent{}
for pid := range g.podRecords {
oldPod := g.podRecords.getOld(pid)
pod := g.podRecords.getCurrent(pid)
// 获得新的老的所有容器
allContainers := getContainersFromPods(oldPod, pod)
for _, container := range allContainers {
//检查是否有容器变化
events := computeEvents(oldPod, pod, &container.ID)
for _, e := range events {
updateEvents(eventsByPodID, e)
}
}
}
var needsReinspection map[types.UID]*kubecontainer.Pod
//缓存是否开启,如果开启,需要再次检查(检查上一次未通过的)
if g.cacheEnabled() {
needsReinspection = make(map[types.UID]*kubecontainer.Pod)
}
//遍历所有发生的event的pod
for pid, events := range eventsByPodID {
pod := g.podRecords.getCurrent(pid)
if g.cacheEnabled() {
if err := g.updateCache(pod, pid); err != nil {
klog.V(4).ErrorS(err, "PLEG: Ignoring events for pod", "pod", klog.KRef(pod.Namespace, pod.Name))
needsReinspection[pid] = pod
continue
} else {
delete(g.podsToReinspect, pid)
}
}
//将老的pod信息改成新的,新的变成nil
g.podRecords.update(pid)
containerExitCode := make(map[string]int)
//遍历这个pod的所有event变化
for i := range events {
//如果是不知道的类型跳过
if events[i].Type == ContainerChanged {
continue
}
select {
//推送的kubelet的plegChg管道
case g.eventChannel <- events[i]:
default:
metrics.PLEGDiscardEvents.Inc()
klog.ErrorS(nil, "Event channel is full, discard this relist() cycle event")
}
//如果是失败的容器
if events[i].Type == ContainerDied {
//如果没有失败状态(退出码)
if len(containerExitCode) == 0 && pod != nil && g.cache != nil {
// 获得最新的容器运行时的pod状态
status, err := g.cache.Get(pod.ID)
if err == nil {
//遍历容器的状态信息,并且记录退出码
for _, containerStatus := range status.ContainerStatuses {
containerExitCode[containerStatus.ID.ID] = containerStatus.ExitCode
}
}
}
//如果容器有了退出码信息并且pod还在,记录一下日志
if containerID, ok := events[i].Data.(string); ok {
if exitCode, ok := containerExitCode[containerID]; ok && pod != nil {
klog.V(2).InfoS("Generic (PLEG): container finished", "podID", pod.ID, "containerID", containerID, "exitCode", exitCode)
}
}
}
}
}
//如果需要检查,并且pod需要同步的数量大于0
if g.cacheEnabled() {
if len(g.podsToReinspect) > 0 {
klog.V(5).InfoS("GenericPLEG: Reinspecting pods that previously failed inspection")
for pid, pod := range g.podsToReinspect
//更新这些pod信息
if err := g.updateCache(pod, pid); err != nil {
klog.V(5).ErrorS(err, "PLEG: pod failed reinspection", "pod", klog.KRef(pod.Namespace, pod.Name))
needsReinspection[pid] = pod
}
}
}
g.cache.UpdateTime(timestamp)
}
g.podsToReinspect = needsReinspection
}
2.1容器变化的校验
func computeEvents(oldPod, newPod *kubecontainer.Pod, cid *kubecontainer.ContainerID) []*PodLifecycleEvent {
var pid types.UID
if oldPod != nil {
pid = oldPod.ID
} else if newPod != nil {
pid = newPod.ID
}
oldState := getContainerState(oldPod, cid)//获得pod的容器状态
newState := getContainerState(newPod, cid)
return generateEvents(pid, cid.ID, oldState, newState)//比对两个pod的容器状态
}
func getContainerState(pod *kubecontainer.Pod, cid *kubecontainer.ContainerID) plegContainerState {
state := plegContainerNonExistent
if pod == nil {
return state
}
c := pod.FindContainerByID(*cid)//找到这个容器
if c != nil {
return convertState(c.State)//验证这个容器状态
}
c = pod.FindSandboxByID(*cid)
if c != nil {
return convertState(c.State)
}
return state
}
func convertState(state kubecontainer.State) plegContainerState {
switch state {
case kubecontainer.ContainerStateCreated:
return plegContainerUnknown
case kubecontainer.ContainerStateRunning:
return plegContainerRunning
case kubecontainer.ContainerStateExited:
return plegContainerExited
case kubecontainer.ContainerStateUnknown:
return plegContainerUnknown
default:
panic(fmt.Sprintf("unrecognized container state: %v", state))
}
}
//这里是新老状态对比的
func generateEvents(podID types.UID, cid string, oldState, newState plegContainerState) []*PodLifecycleEvent {
//如果新老状态一样,代表没变化
if newState == oldState {
return nil
}
klog.V(4).InfoS("GenericPLEG", "podUID", podID, "containerID", cid, "oldState", oldState, "newState", newState)
switch newState {
//选择新状态变更就可以了
case plegContainerRunning:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerStarted, Data: cid}}
case plegContainerExited:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerDied, Data: cid}}
case plegContainerUnknown:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerChanged, Data: cid}}
case plegContainerNonExistent:
switch oldState {
case plegContainerExited:
// We already reported that the container died before.
return []*PodLifecycleEvent{{ID: podID, Type: ContainerRemoved, Data: cid}}
default:
return []*PodLifecycleEvent{{ID: podID, Type: ContainerDied, Data: cid}, {ID: podID, Type: ContainerRemoved, Data: cid}}
}
default:
panic(fmt.Sprintf("unrecognized container state: %v", newState))
}
}
二、syncCh
这个比较简单,所有的pod进入syncLoopIteration后,最终会走到managePodLoop函数中,当这个函数执行完成后,会将pod信息存入到workQueue队列里。同时syncCh会一秒循环一次这个队列,将pod数据再次进入syncLoopIteration函数执行
syncTicker := time.NewTicker(time.Second)
func (p *podWorkers) completeWork(pod *v1.Pod, phaseTransition bool, syncErr error) {
switch {
case phaseTransition:
p.workQueue.Enqueue(pod.UID, 0)
case syncErr == nil:
p.workQueue.Enqueue(pod.UID, wait.Jitter(p.resyncInterval, workerResyncIntervalJitterFactor))
case strings.Contains(syncErr.Error(), NetworkNotReadyErrorMsg):
p.workQueue.Enqueue(pod.UID, wait.Jitter(backOffOnTransientErrorPeriod, workerBackOffPeriodJitterFactor))
default:
p.workQueue.Enqueue(pod.UID, wait.Jitter(p.backOffPeriod, workerBackOffPeriodJitterFactor))
}
p.completeWorkQueueNext(pod.UID)
}
上一篇:kubelet源码分析 syncLoopIteration(一) configCh
最后
以上就是曾经月光最近收集整理的关于kubelet源码分析 syncLoopIteration(二) plegCh、syncChkubelet源码分析 syncLoopIteration(二) plegCh的全部内容,更多相关kubelet源码分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![linux命令查询服务器硬件信息dmidecode -t systemdmidecode 2.12grep “” /sys/class/dmi/id/[pbs]*cat /sys/class/dmi/id/board_vendorcat /sys/class/dmi/id/product_namecat /sys/class/dmi/id/product_serialcat /sys/class/dmi/id/bios_versiondmesg | grep -i DMI](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)
发表评论 取消回复