storm+kafka+logstash+springBoot+高德地图
项目概述:
作用:交通信息化,智慧城市
需求:实时统计人流量并通过热力图展示。
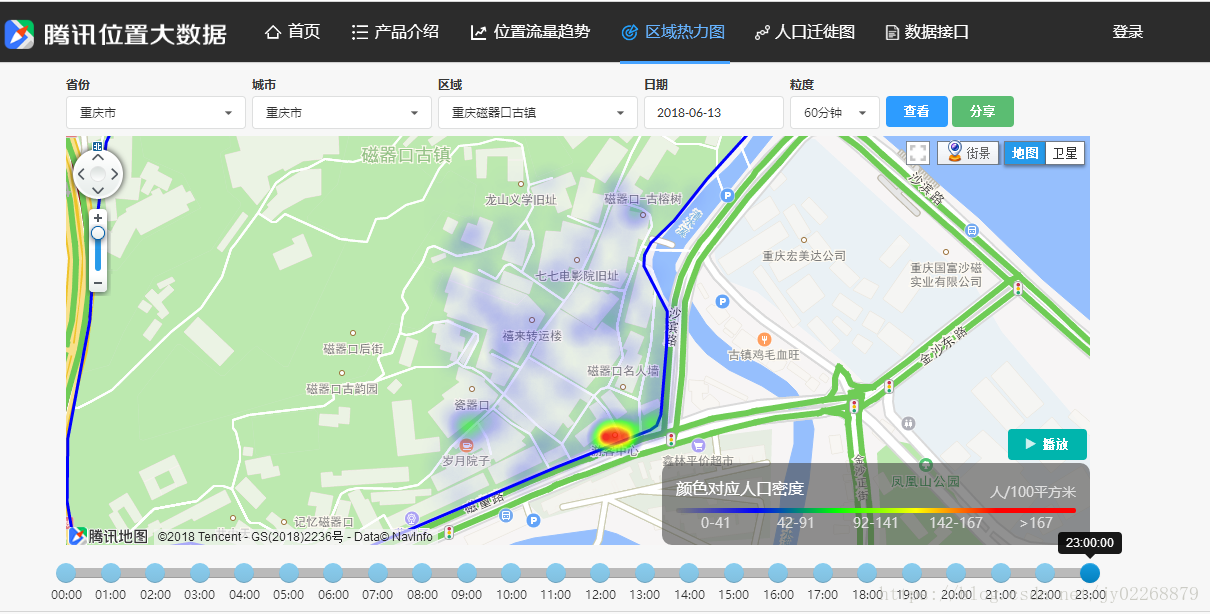
类似于腾讯热力图的景区人流量统计
如何采集某个区域人流量的数据:
1.GPS:获取经纬度信息。
2.手机移动网络信令:移动通信信令(数据样本容量大,覆盖范围广,数据稳定可靠)对信令信息的相应字段进行分析、挖掘、并结合GIS技术实现自定义区域实时人流量的智能化统计分析。通过移动用户发生的通信事件记录来判断该用户所处的位置,可以根据事件发生的区域,对用户的行为轨迹进行定义。
1.区域内inside:用户处在目标区域范围内
2.区域外outside:用户处在目标区域范围外
3.离开leave:观察到驻留在某个区域的用户在该区域以外的某个地方发生了一个通信事件,则认为该用户离开了该区域。
4.出现appear:观察到用户在一个区域发生了通信事件,则认为该用户在该区域出现。如果用户在某个区域第一次出现,则认为用户进入了该区域。
通过信令拿到当前位置的经纬度。
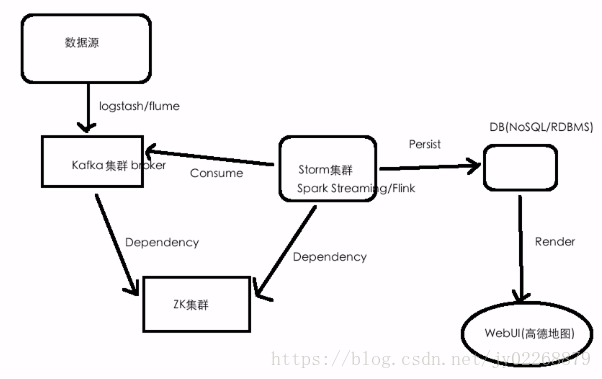
项目架构:
projectStormDataSource.py日志产生器代码
#!/usr/bin/env/ python
# coding=UTF-8
import random
import time
infos = [
"105.795545,29.74814",
"109.887206,31.236759",
"107.767851,29.417501",
"108.750152,28.851412",
"106.996368,28.885217",
"107.127392,29.049247",
"106.409199,28.606263",
"108.993301,30.656046"
]
phones = [
"18523981111", "18523981112", "18523981113",
"18523981114", "18523981115", "18523981116",
"18523981117", "18523981118", "18523981119"
]
def phone_m():
return random.sample(phones, 1)[0]
def info_m():
return random.sample(infos, 1)[0]
def producer_log(count=3):
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f = open("/app/logstash/testFile.txt", "a+")
while count >= 1:
query_log = "{phone}t{info}t[{local_time}]".format(phone=phone_m(), local_time=time_str, info=info_m())
print(query_log)
f.write(query_log + "n")
count = count - 1
if __name__ == '__main__':
# print phone_m()
# print info_m()
producer_log(10)logstash配置
cd /app/logstash
vi FileLogstashKafka.confinput {
file{
path => "/app/logstash/testFile.txt"
}
}
output {
kafka {
topic_id => "storm_topic"
bootstrap_servers => "node1:9092"
batch_size => 1
codec => plain{
format => "%{message}"
}
}
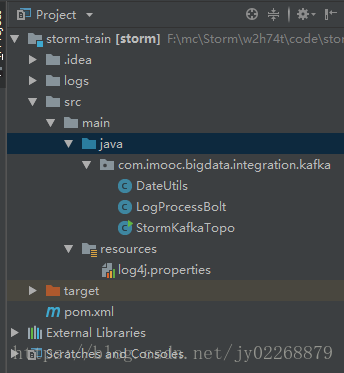
}项目目录
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.imooc.bigdata</groupId>
<artifactId>storm</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>storm</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<storm.version>1.1.1</storm.version>
<hadoop.version>2.9.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-jdbc</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<!-- 如果不加这个 报错NoClassDefFoundError:kafka/api/OffsetRequest -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 如果不加这个 报错NoClassDefFoundError:org/apache/curator/shaded/com/google/common/cache/CacheBuilder -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
</dependencies>
</project>
StormKafkaTopo.java
package com.imooc.bigdata.integration.kafka;
import com.google.common.collect.Maps;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.jdbc.bolt.JdbcInsertBolt;
import org.apache.storm.jdbc.common.ConnectionProvider;
import org.apache.storm.jdbc.common.HikariCPConnectionProvider;
import org.apache.storm.jdbc.mapper.JdbcMapper;
import org.apache.storm.jdbc.mapper.SimpleJdbcMapper;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.TopologyBuilder;
import java.util.Map;
import java.util.UUID;
/**
* logstash+kafka+storm+mysql+springBoot+高德地图
*/
public class StormKafkaTopo {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
// Kafka使用的zk地址
BrokerHosts hosts = new ZkHosts("node1:2181,node2:2181,node3:2181");
// Kafka存储数据的topic名称
String topic = "storm_topic";
// 指定ZK中的一个根目录,存储的是KafkaSpout读取数据的位置信息(offset)
String zkRoot = "/" + topic;
String id = UUID.randomUUID().toString();
SpoutConfig spoutConfig = new SpoutConfig(hosts, topic, zkRoot, id);
// 设置读取偏移量的操作
spoutConfig.startOffsetTime = kafka.api.OffsetRequest.LatestTime();
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
String SPOUT_ID = KafkaSpout.class.getSimpleName();
builder.setSpout(SPOUT_ID, kafkaSpout);
String BOLD_ID = LogProcessBolt.class.getSimpleName();
builder.setBolt(BOLD_ID, new LogProcessBolt()).shuffleGrouping(SPOUT_ID);
//jdbc bolt 结果写入MySQL
Map hikariConfigMap = Maps.newHashMap();
hikariConfigMap.put("dataSourceClassName","com.mysql.jdbc.jdbc2.optional.MysqlDataSource");
hikariConfigMap.put("dataSource.url", "jdbc:mysql://localhost/sid");
hikariConfigMap.put("dataSource.user","root");
hikariConfigMap.put("dataSource.password","密码");
ConnectionProvider connectionProvider = new HikariCPConnectionProvider(hikariConfigMap);
String tableName = "stat";
JdbcMapper simpleJdbcMapper = new SimpleJdbcMapper(tableName, connectionProvider);
JdbcInsertBolt userPersistanceBolt = new JdbcInsertBolt(connectionProvider, simpleJdbcMapper)
.withTableName(tableName)
.withQueryTimeoutSecs(30);
builder.setBolt("JdbcInsertBolt", userPersistanceBolt).shuffleGrouping(BOLD_ID);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(StormKafkaTopo.class.getSimpleName(),
new Config(),
builder.createTopology());
}
}
LogProcessBolt.java
package com.imooc.bigdata.integration.kafka;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
/**
* 接收Kafka的数据进行处理的BOLT
*/
public class LogProcessBolt extends BaseRichBolt {
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
try {
byte[] binaryByField = input.getBinaryByField("bytes");
String value = new String(binaryByField);
/**
* 13977777777 116.399466,39.989743 [2018-01-14 11:22:34]
*
* 解析出来日志信息
*/
String[] splits = value.split("t");
String phone = splits[0];
String[] temp = splits[1].split(",");
String longitude = temp[0];
String latitude = temp[1];
long time = DateUtils.getInstance().getTime(splits[2]);
System.out.println(phone + "," + longitude + "," + latitude + "," + time);
collector.emit(new Values(time, Double.parseDouble(longitude), Double.parseDouble(latitude)));
this.collector.ack(input);
} catch (Exception e) {
this.collector.fail(input);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("time", "longitude", "latitude"));
}
}
DateUtils.java
package com.imooc.bigdata.integration.kafka;
import org.apache.commons.lang3.time.FastDateFormat;
/**
* 时间解析工具类
*/
public class DateUtils {
private DateUtils(){}
private static DateUtils instance;
public static DateUtils getInstance(){
if (instance == null) {
instance = new DateUtils();
}
return instance;
}
FastDateFormat format = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss");
public long getTime(String time) throws Exception {
return format.parse(time.substring(1, time.length()-1)).getTime();
}
}
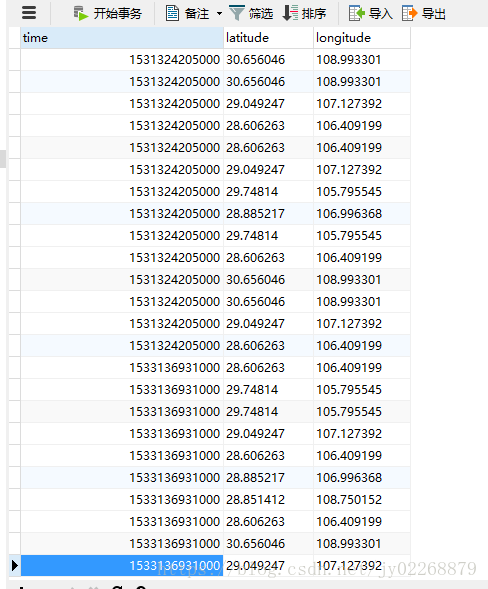
MySQL创建表
CREATE TABLE `stat` (
`time` bigint(20) DEFAULT NULL,
`latitude` double DEFAULT NULL,
`longitude` double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;启动zk
cd /app/zookeeper/bin
./zkServer.sh start
启动kafka
cd /app/kafka
bin/kafka-server-start.sh -daemon config/server.properties &
启动logstash的FileLogstashKafka.conf文件
cd /app/logstash
bin/logstash -f FileLogstashKafka.conf
IDEA启动程序
使用python生成日志
cd /app/logstash
python projectStormDataSource.py
查看IDEA控制台
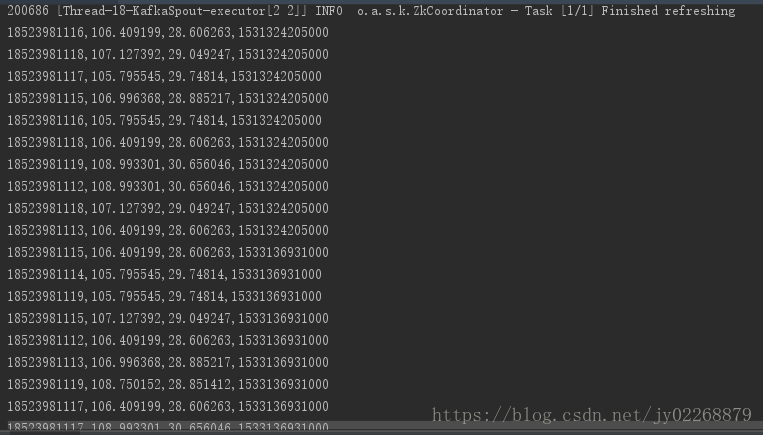
查看MySQL
数据可视化展示:Spring Boot+高德地图热力图动态数据展示+MySQL
最后
以上就是土豪鸡最近收集整理的关于【十三】景区人流量统计:python日志生成+logstash+kafka+storm+mysql+springBoot+高德地图的全部内容,更多相关【十三】景区人流量统计内容请搜索靠谱客的其他文章。








发表评论 取消回复