一.介绍:
jieba:
“结巴”中文分词:做最好的 Python 中文分词组件
“Jieba” (Chinese for “to stutter”) Chinese text segmentation: built to be the best Python Chinese word segmentation module.
完整文档见 :
GitHub: https://github.com/fxsjy/jieba
特点
- 支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
- MIT 授权协议
在线演示: http://jiebademo.ap01.aws.af.cm/
安装说明
代码对 Python 2/3 均兼容
- 全自动安装: easy_install jieba 或者 pip install jieba / pip3 install jieba
- 半自动安装:先下载 https://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
- 手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
- 通过 import jieba 来引用
二.功能介绍及例子
1.分词主要功能:
先介绍主要的使用功能,再展示代码输出。jieba分词的主要功能有如下几种:
1. jieba.cut:该方法接受三个输入参数:需要分词的字符串; cut_all 参数用来控制是否采用全模式;HMM参数用来控制是否适用HMM模型
2. jieba.cut_for_search:该方法接受两个参数:需要分词的字符串;是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。
3. 待分词的字符串可以是unicode或者UTF-8字符串,GBK字符串。注意不建议直接输入GBK字符串,可能无法预料的误解码成UTF-8,
4. jieba.cut 以及jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取分词后得到的每一个词语或者使用
5. jieb.lcut 以及 jieba.lcut_for_search 直接返回list
6. jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
2.简单模式:
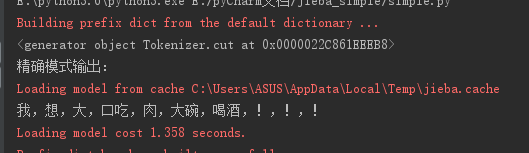
2.1.精确模式(返回结果是一个生成器,对大量数据分词很重要,占内存小):
import jieba s = '我想大口吃肉大碗喝酒!!!' cut=jieba.cut(s) print(cut) #精确模式 print('精确模式输出:') print(','.join(cut))
输出为:
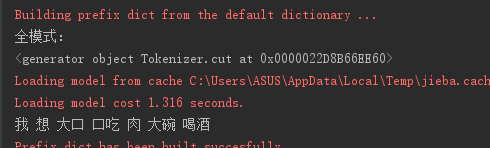
2.2.全模式(返回结果也是生成器,特点是把文本分成尽可能多的词):
import jieba s = '我想大口吃肉大碗喝酒!!!' print('全模式:') result=jieba.cut(s, cut_all=True) print(result) print(' '.join(result))
输出为:
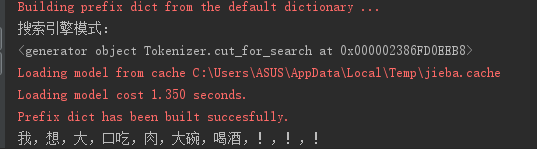
2.3.搜索引擎模式:
import jieba s = '我想大口吃肉大碗喝酒!!!' print('搜索引擎模式:') result=jieba.cut_for_search(s) print(result) print(','.join(result))
输出为:
3.获取词性:每个词都有其词性,比如名词、动词、代词等,结巴分词的结果也可以带上每个词的词性,要用到jieba.posseg
分词及输出词性:
import jieba.posseg as psg s = '我想大口吃肉大碗喝酒!!!' print('分词及词性:') result=psg.cut(s) print(result) print([(x.word,x.flag) for x in result])

过滤词性,如获取名词:
import jieba.posseg as psg s = '我想大口吃肉大碗喝酒!!!' print('分词及词性:') result=psg.cut(s) print(result) #筛选为名词的 print([(x.word,x.flag) for x in result if x.flag=='n'])
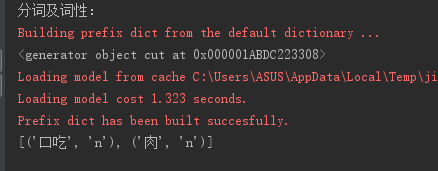
4.并行分词:在文本数据量非常大的时候,为了提高分词效率,开启并行分词就很有必要了。jieba支持并行分词,基于python自带的multiprocessing模块,但要注意的是在Windows环境下不支持。
# 开启并行分词模式,参数为并发执行的进程数 jieba.enable_parallel(5) # 关闭并行分词模式 jieba.disable_parallel()

5.获取出现频率Top n的词(有些词无实际意义,可筛选):
from collections import Counter words_total=open('1',encoding='utf-8').read() c = Counter(words_total).most_common(20) print (c)

6.使用用户字典提高分词准确性:
jieba分词器还有一个方便的地方是开发者可以指定自己的自定义词典,以便包含词库中没有的词,虽然jieba分词有新词识别能力,但是自行添加新词可以保证更高的正确率。
使用命令:
jieba.load_userdict(filename) # filename为自定义词典的路径。在使用的时候,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。

7.关键词抽取:
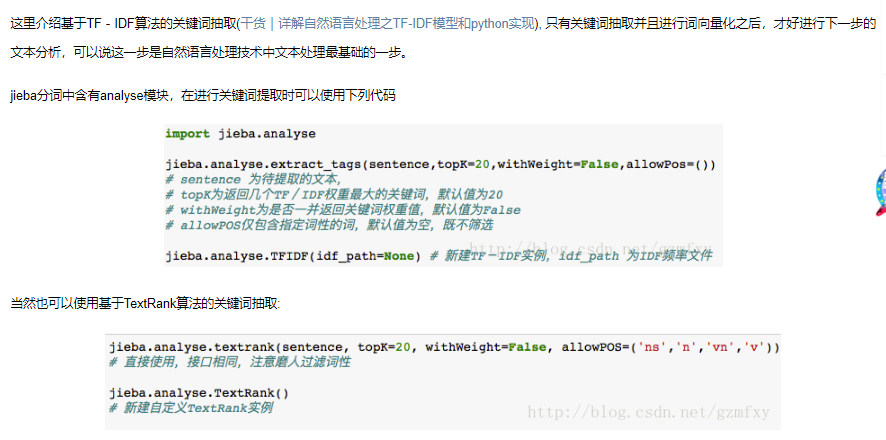
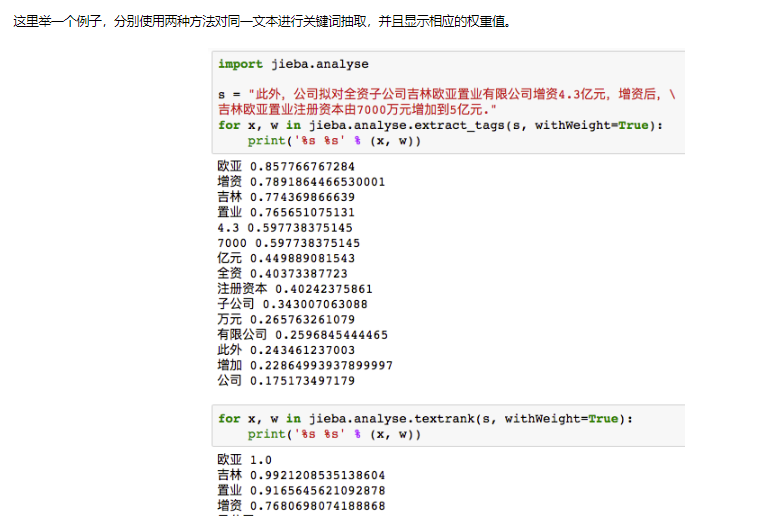
附:结巴分词词性对照表(按词性英文首字母排序)
形容词(1个一类,4个二类)
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
连词(1个一类,1个二类)
c 连词
cc 并列连词
副词(1个一类)
d 副词
叹词(1个一类)
e 叹词
方位词(1个一类)
f 方位词
前缀(1个一类)
h 前缀
后缀(1个一类)
k 后缀
数词(1个一类,1个二类)
m 数词
mq 数量词
名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
拟声词(1个一类)
o 拟声词
介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
处所词(1个一类)
s 处所词
时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:—— -- ——- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$
字符串(1个一类,2个二类)
x 字符串
xx 非语素字
xu 网址URL
语气词(1个一类)
y 语气词(delete yg)
状态词(1个一类)
z 状态词
参考:https://pypi.org/project/jieba/#history
https://www.cnblogs.com/jiayongji/p/7119065.html
https://blog.csdn.net/gzmfxy/article/details/78994396
转载于:https://www.cnblogs.com/lyq-biu/p/9641677.html
最后
以上就是魁梧秀发最近收集整理的关于结巴(jieba)分词附:结巴分词词性对照表(按词性英文首字母排序) 的全部内容,更多相关结巴(jieba)分词附内容请搜索靠谱客的其他文章。








发表评论 取消回复