以下是基于用户和基于物品的图示:
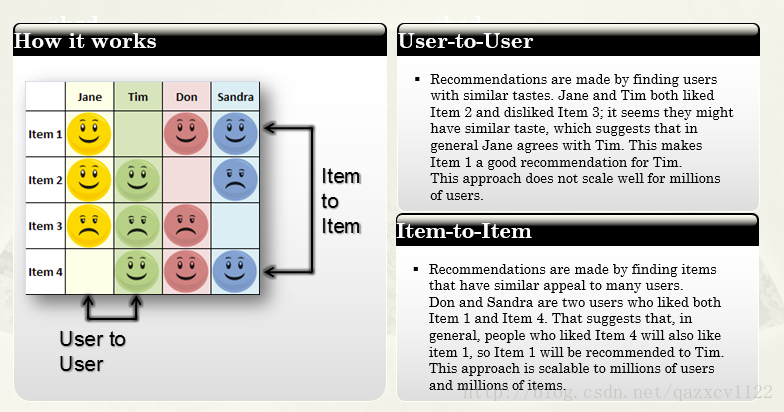
基于用户(user-to-user)
在一定的历史数据支撑下,协同过滤算法认为一个用户的口味和其他和他相似的用户的口味一样,比如用户A 喜欢item1,item2,item3,item4,item5, 而用户B喜欢item1,item2,item3,item4, 那么就可以为用户B喜欢item5,用户之间的相似度计算是基于皮尔森公式的(如图),其中r代表rate(评分),ru,i代表用户u对物品i的评分,ru表示用户u的评分均值。
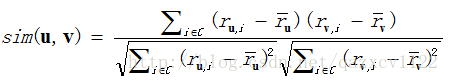
最后预测评分是利用如下的公式:
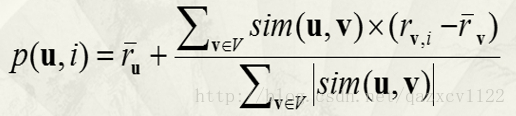
基于物品(item-to-item)
上述的计算是基于用户之间的在评分行为上的相似度的,另外一种是基于物品间用户对它们的评分行为的相似性来计算物品间的相似度的,公式如下:
相似度:(r代表rate(评分),ru,i代表用户u对物品i的评分,ru表示用户u的评分均值)
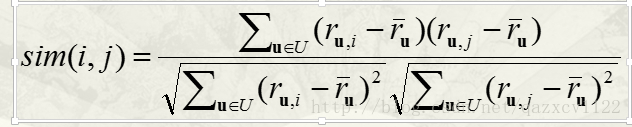
预测评分:(根据和物品i相近的若干个物品j来评分)
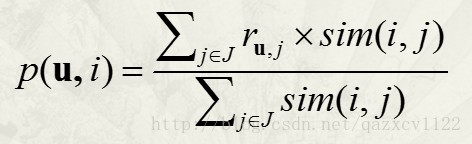
附带一段基于用户的代码和数据集,
写得比较粗糙,数据集有四列,
分别代表 用户id, 物品id,评分,时间,
数据:http://download.csdn.net/detail/qazxcv1122/6685217
如果程序运行不成功,很可能是读取文件以及读取numPairs出错。
#include "math.h"
#include <stdio.h>
#include <stdlib.h>
using namespace std;
/*
SCUT
*/
//the parameter of training set
int numUser;//用户的数量
int numItem;//物品的数量
double RMSE=0;
double MAE=0;
int numPairs;//测试数据集里的行数
int KNN=500;//k个最相近的用户
int **train;//测试数据矩阵,行代表用户,列代表物品,记录的是用户对物品的评分
int **test;//测试数据集,将文本中的数据集直接抄进来
double *userAverage;//记录每一个用户的平均评分
double **similarity;//numUser*numUser的矩阵,用来存储每个用户与其他用户的相似度
int** similarUser;//numUser*KNN的矩阵,记录每个用户中与之最相近的KNN个用户的id
//读取测试数据集
int** readTrain(char* name)
{
FILE* file=fopen(name,"r");
numUser=numItem=0;
int temp1,temp2,temp3,temp4;
//查找最大的用户id和最大的物品Id,分别记入numUser,numItem
while(!feof(file))
{
fscanf(file,"%d %d %d %d",&temp1,&temp2,&temp3,&temp4);
if(numUser<temp1)
numUser=temp1;
if(numItem<temp2)
numItem=temp2;
}
fclose(file);
//分配空间
int** array = new int*[numUser];
for(int i=0;i<numUser;i++)
array[i]=new int[numItem];
for(int i=0;i<numUser;i++)
for(int j=0;j<numItem;j++)
array[i][j]=0;
file=fopen(name,"r");
//读取数据到二维数组中
while(!feof(file))
{
fscanf(file,"%d %d %d %d",&temp1,&temp2,&temp3,&temp4);
array[temp1-1][temp2-1]=temp3;
}
return array;
}
int** readTest(char* name)
{
FILE* file=fopen(name,"r");
numPairs=0;
int temp1,temp2,temp3,temp4;
while(!feof(file))
{
fscanf(file,"%d %d %d %d",&temp1,&temp2,&temp3,&temp4);
numPairs++;//记录行数
}
fclose(file);
int** array = new int*[numPairs];
for(int i=0;i<numPairs;i++)
array[i]=new int[4];
file=fopen(name,"r");
for(int i=0;i<numPairs;i++)
fscanf(file,"%d %d %d %d",&array[i][0],&array[i][1],&array[i][2],&array[i][3]);
return array;
}
//利用皮尔森公式计算相似度
double pearson(int* user1,int id1,int*user2,int id2)
{
double difpro=0;
double squl=0,squr=0;
for(int i=0;i<numItem;i++)
{
if(user1[i]!=0&&user2[i]!=0)//对于2个用户,只考虑他们共同评过分的物品
{
difpro+=(user1[i]-userAverage[id1])*(user2[i]-userAverage[id2]);
squl+=(user1[i]-userAverage[id1])*(user1[i]-userAverage[id1]);
squr+=(user2[i]-userAverage[id2])*(user2[i]-userAverage[id2]);
}
}
if(squl==0||squr==0||difpro==0)//防止分母为0的情况。
return 0;
else
return difpro/(sqrt(squl)*sqrt(squr));
}
//计算所有用户间的相似度,并且存到similarity中
double** calSimilarity()
{
double** similar=new double*[numUser];
userAverage=new double[numUser];
double average=0;
int nonzero=0;
for(int i=0;i<numUser;i++)//计算各个用户的平均评分
{
average=0;
nonzero=0;
for(int j=0;j<numItem;j++)
{
if(train[i][j]!=0)
{
average+=train[i][j];
nonzero++;
}
}
userAverage[i]=average/nonzero;
}
for(int i=0;i<numUser;i++)//初始化
{
similar[i]=new double[numUser];
for(int j=0;j<numUser;j++)
similar[i][j]=0;
}
for(int i=0;i<numUser;i++)//计算相似度
{
for(int j=0;j<numUser;j++)
{
if(i!=j)
similar[i][j]=pearson(train[i],i,train[j],j);
}
}
return similar;
}
//第一个参数是一个用户对物品打分情况的数组,第二个就是这个用户对其他所有用户的相似度
void slectionSort(int* singlesimilarUser,double* singlesimilarity)
{
int temp=0,temp2=0;
for(int i=KNN-1;i>0;i--)
{
temp=0;
for(int j=0;j<=i;j++)
{
if(singlesimilarity[singlesimilarUser[temp]]<singlesimilarity[singlesimilarUser[j]])
temp=j;
}
temp2=singlesimilarUser[i];
singlesimilarUser[i]=singlesimilarUser[temp];
singlesimilarUser[temp]=temp2;
}
}
void sort()//选择排序
{
for(int i=0;i<numUser;i++)
slectionSort(similarUser[i],similarity[i]);
}
/*位每个用户找出KNN个最相似的其他用户
开始向排序,先将1到KNN的用户的id放进similarUser中,
然后根据这些用户的相似度来排序,排好序后就选择KNN到numUser
的用户中较相似的用户插入到之前排好序的序列中,具体看代码
*/
void finKSimilar()
{
similarUser=new int*[numUser];
for(int i=0;i<numUser;i++)
similarUser[i]=new int[KNN];
for(int i=0;i<numUser;i++)
{
for(int j=0;j<KNN;j++)
similarUser[i][j]=j;
}
sort();
int curpos=0;
for(int i=0;i<numUser;i++)
{
for(int j=KNN;j<numUser;j++)
{
curpos=0;
int temp=similarUser[i][curpos];
while( similarity[i][j] > similarity[i][temp])
{
curpos++;
if(curpos<KNN)
temp=similarUser[i][curpos];
else
break;
}
if(curpos>0)
{
for(int k=0;k<curpos-1;k++)
similarUser[i][k]=similarUser[i][k+1];
similarUser[i][curpos-1]=j;
}
}
}
}
/*
推荐过程,逐条读取测试数据集中的每行数据,
获得用户id及其实际打分,然后为这个用户计算
他对这个物品的预测分值,然后计算MAE和RMSE.
*/
void recommendation()
{
int curUser,curItem,neighbour;
double actualRate,predition;
double downTerm,upTerm;
for(int i=0;i<numPairs;i++)
{
curUser=test[i][0]-1;
curItem=test[i][1]-1;
actualRate=test[i][2];
predition=0;
downTerm=upTerm=0;
for(int j=KNN-1;j>=0;j--)
{
neighbour=similarUser[curUser][j];
if(train[neighbour][curItem]!=0)
{
upTerm+=similarity[curUser][neighbour]*(train[neighbour][curItem]-userAverage[neighbour]);
downTerm+=abs(similarity[curUser][neighbour]);
}
}
predition=userAverage[curUser];
if(downTerm!=0&&upTerm!=0)
predition+=upTerm/downTerm;
predition = (int)(predition + 0.5);//由于评分是整数,所以加入四舍五入
MAE+=abs(predition-actualRate);
RMSE+=(predition-actualRate)*(predition-actualRate);
}
MAE/=numPairs;
RMSE/=numPairs;
RMSE=sqrt(RMSE);
}
int main()
{
char* trainSet="C:/Users/Me/Desktop/data-rs/80train.txt";
char* testSet="C:/Users/Me/Desktop/data-rs/test.txt";
train=readTrain(trainSet);
test=readTest(testSet);
similarity=calSimilarity();
finKSimilar();
recommendation();
printf("get done!n");
printf("MAE=%fnRMSE=%f",MAE,RMSE);
system("pause");
return 0;
}
最后
以上就是哭泣背包最近收集整理的关于数据挖据-协同过滤算法 (collaborative-filtering, CF)的全部内容,更多相关数据挖据-协同过滤算法内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复