基于python手写深度学习网络系列(5)
神经网络的学习能力
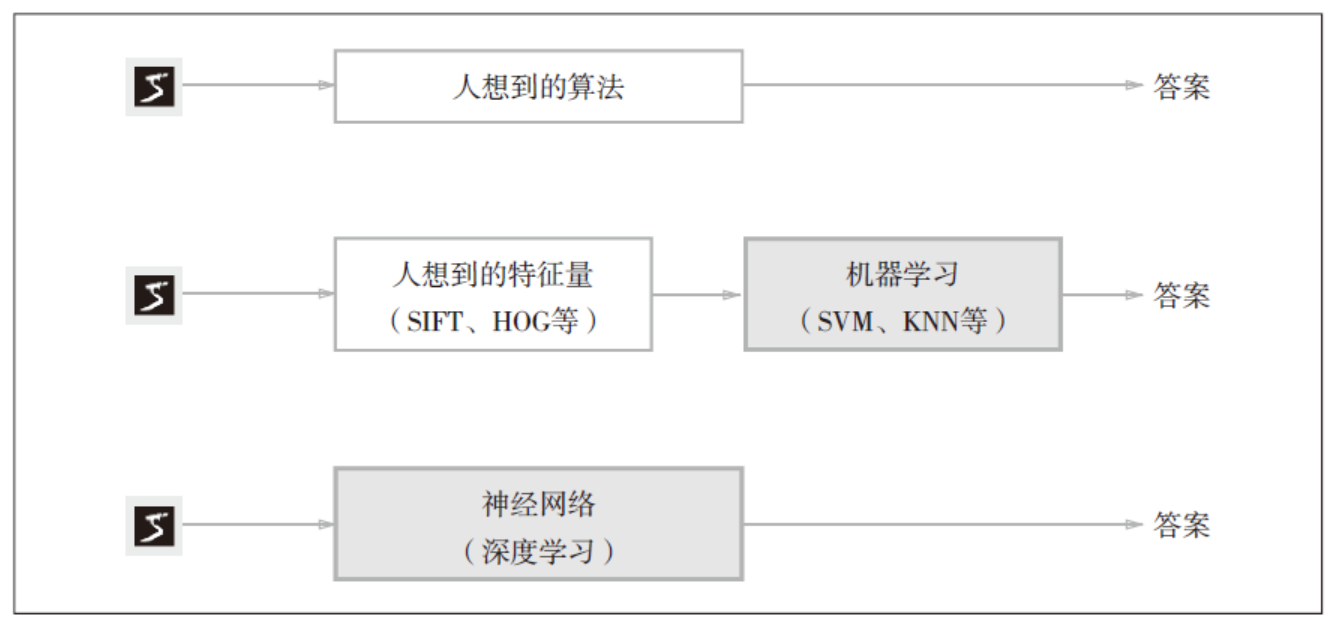
学习就是从训练数据中自动获取最优权重参数的过程
这里所说的“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器,常用的计算机视觉领域的特征量包括SIFT、SURF、HOG,将数据一般转化成向量的形式,然后再使用SVM,KNN等分类器进行学习(这是机器学习的过程)
为了正确评价模型的泛化能力,就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据,泛化能力就是处理训练数据之外的数据的能力。
过拟合(over fitting)
损失函数一般使用均方误差(mean squared error)和交叉熵误差等
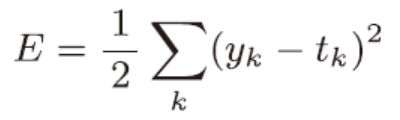
Yk是神经网络的输出,tk是监测数据,k是维度

将正确解标签表示为1,其他标签表示为0 的表示方法称为one-hot 表示。
交叉熵误差
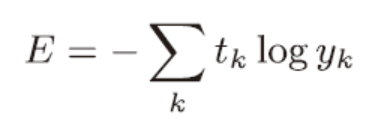

在考虑训练数据集时就要考虑所有数据损失函数的总和,交叉熵误差就会变成下面这样
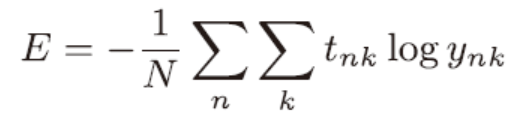
我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch 进行学习
在大量数据中抽取十个数据可以用np.random.choice()

这个可以同时处理单个数据或者批量数据
监督数据是标签形式时
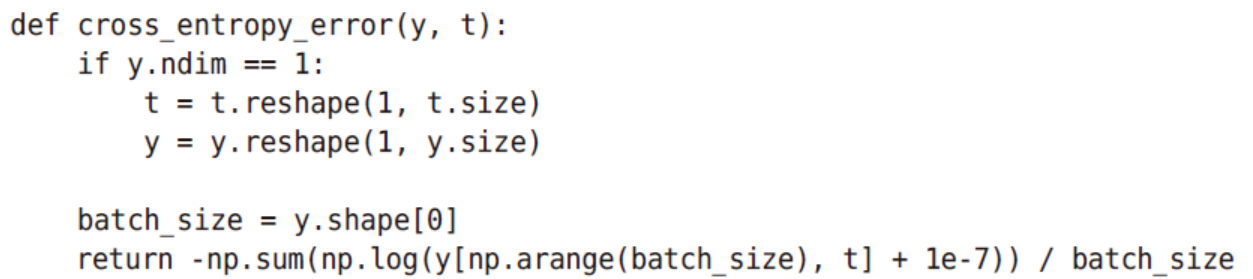
y[np.arange(batch_size),t]能抽出各个数据的正确解标签对应的神经网络的输出(在这个例子中,y[np.arange(batch_size), t] 会生成NumPy 数组[y[0,2], y[1,7], y[2,0],
y[3,9], y[4,4]])。
为什么要引入损失函数,不直接用精度?
在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0。
为什么会变0?识别精度对微小的参数变化基本没有反应,跃迁函数的导数在绝大多数地方都为0.
想要实现沿着梯度的下降,就需要先计算倒数,偏导数,乃至梯度

此代码有个问题

在grad[idx]那里,如果不加上编号,那么计算出啦就是一个值而不是一个数组。


那么代码中的lambda应该怎么用呢?编程中提到的 lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
map() 函数,它可以将一个函数映射到一个可枚举类型上面。
map(f, a)也就是将函数 f 依次套用在 a 的每一个元素上面,获得结果 [2, 3, 4]。现在用 lambda 表达式来替换 f,就变成:map( lambda x : x + 1, [1, 2, 3] )
所以在上面代码中的lambda起到的作用就是将d*t+y的值赋给t然后再return
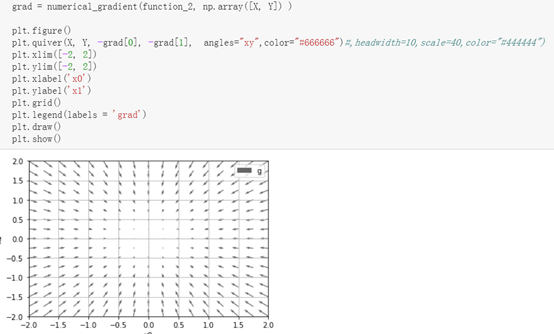
这里的quiver函数还需要理解一下。
quiver(U, V, **kw)quiver(U, V, C, **kw)quiver(X, Y, U, V, **kw)quiver(X, Y, U, V, C, **kw)
寻找最小值的方法叫梯度下降法,寻找最大值的叫梯度上升法。
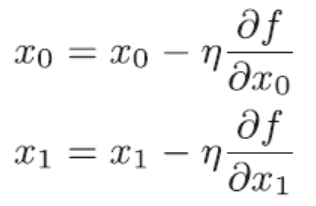
η 表示更新量,在神经网络的学习中,称为学习率,属于超参数,与权重和偏置不同,是人工设定的。

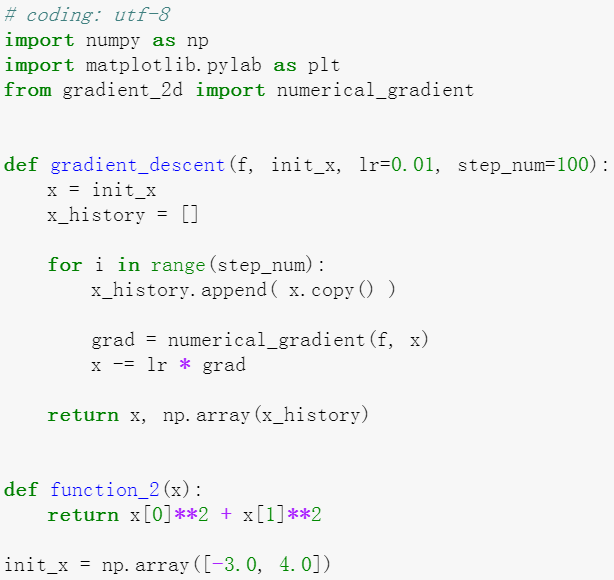
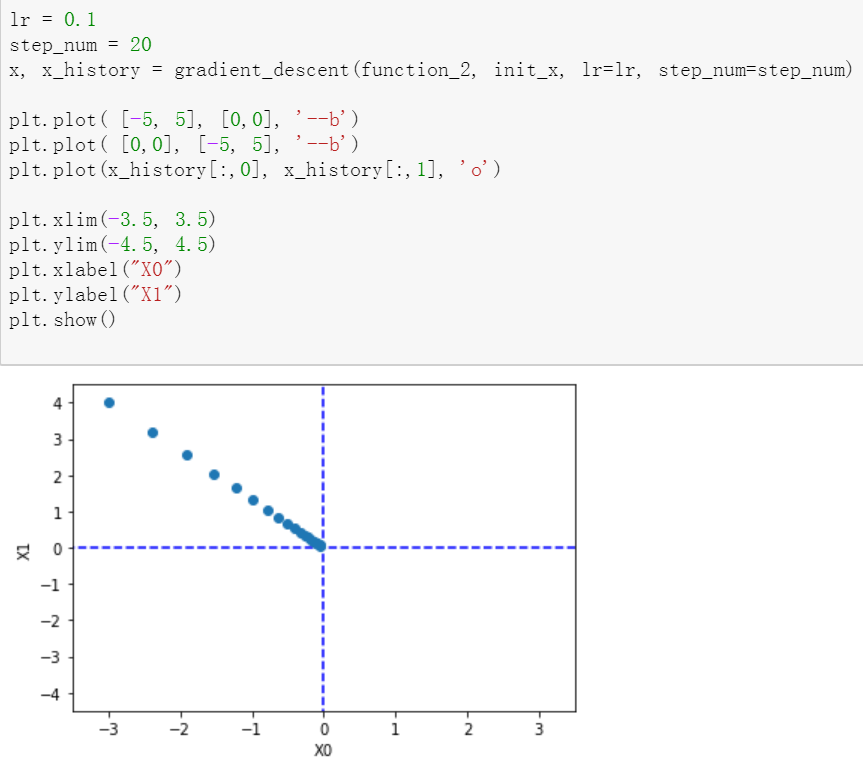
这是提供的代码和图像结果
学习效率过大或过小都不行
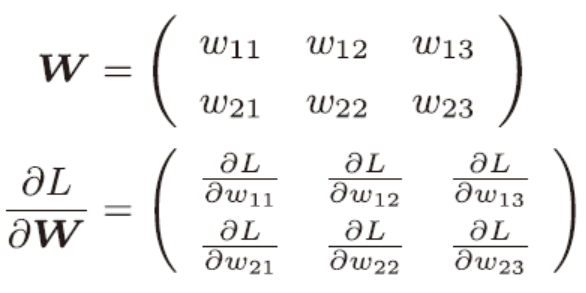
上边是损失函数关于权重参数的梯度
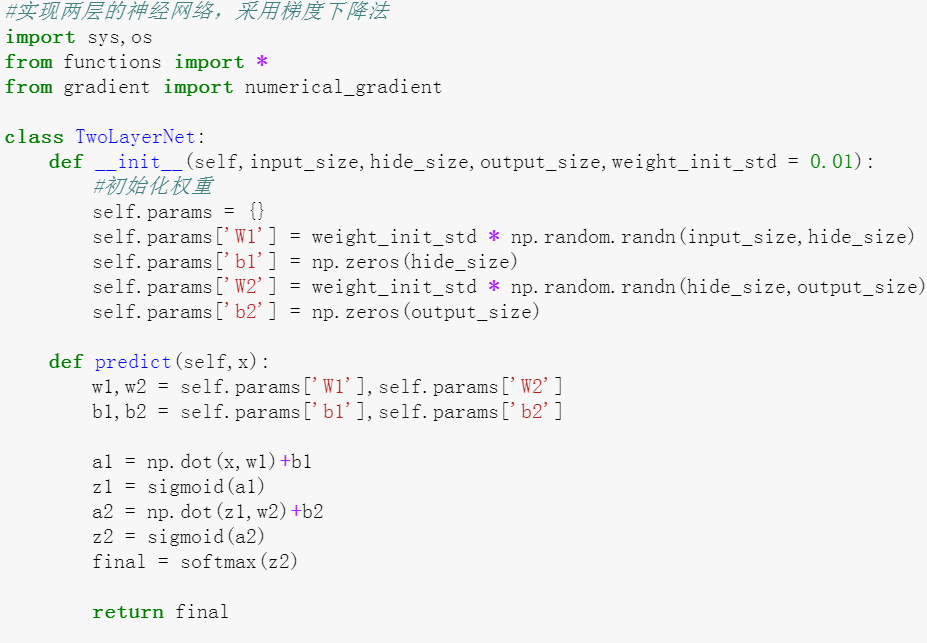
接下来以一个简单的神经网络为例,来实现求梯度的代码
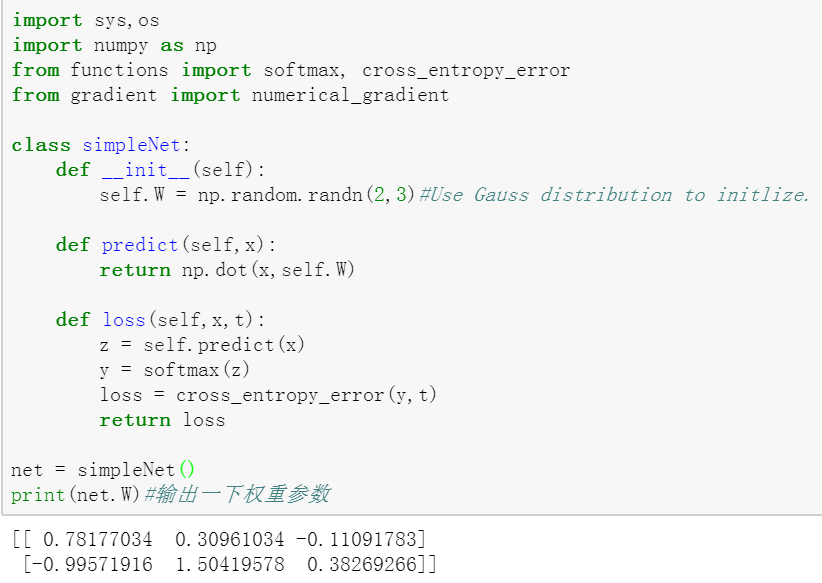
首先是一个简单的神经网络,权重参数是通过高斯函数生成的。
输入变量,可以得到最后的损失函数
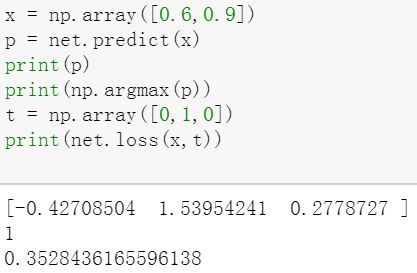
这里的参数W并不是真正的W,实际上这个函数还是求在W情况下,输入x,t后的损失函数值
在numerical_gradient中会执行f这个函数,net.W是传给f的参数。

这里可以用lambda快速创建匿名函数,这里用的是将net.loss的结果赋值给w
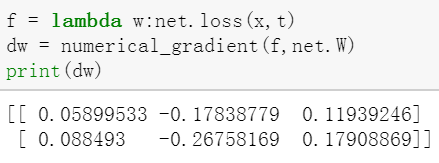
实际上赋值给谁都一样,最后f都要等于赋值给的那个值,相当于一个连等
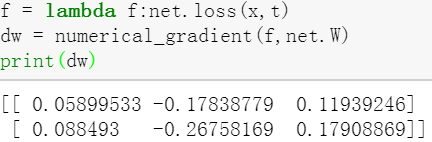
这是为了对应形状为多维数组的权重参数W,使用的numerical_gradient函数
这里猜测it是定义了一个迭代器

算法的步骤总结:
- 选取mini-batch小数据包
- 计算损失函数对权重的梯度
- 沿梯度方向更新权重
- 重复步骤123
Mini-batch是随机选择的,所以称为随机梯度下降法。(对随机算则的数据进行的梯度下降法)stochastic gradient descent,很多深度学习框架中,以SGD为名的函数实现该算法。
实现twolayernet的代码如下,其中要注意的是:
求精确度时,对卷积结果最大值的判定是对一行进行判定,每一行是一个结果,然后minibatch中有多少组数据就有多少列,所以argmax要加上参数axis = 1.默认等于1是对列进行判定。


这里是开始利用之前写的类进行Mnist手写数字识别数据集进行测试

过拟合:虽然训练数据中的数字图像能被正确识别,但是不在训练数据中的数字图像却无法被识别的现象。
Epoch:一个epoch表示学习中所有训练数据均被使用过一次时的更新次数。对于总共10000笔训练数据,用大小100笔数据的小批量学习时,重复随机梯度下降法100次,所有的数据就遍历了。(实际上,先将所有数据打乱,然后按指定的批次大小,按序生成minibatch,每个minibatch都有一个索引号,按序遍历即可)
改正后代码有了小变化

进行判定后,每一个epoch计算一次,然后绘图

那么这种数值方法求解梯度的方法胜在比较好理解,但是需要大量的运算,下一篇我们就要用误差反向传播来改善它!
最后
以上就是阔达短靴最近收集整理的关于基于python手写深度学习网络系列(5)神经网络的学习能力基于python手写深度学习网络系列(5)的全部内容,更多相关基于python手写深度学习网络系列(5)神经网络内容请搜索靠谱客的其他文章。








发表评论 取消回复