1 背景介绍
如何使用单个预训练模型来完成三个任务的预测。
详细信息见:https://tianchi.aliyun.com/competition/entrance/531841/information
当前第一阶段baseline实现的分数是0.6236,排名84位。
2 赛题描述和数据
本赛题精选了3个具有代表性的任务,要求选手提交的模型可以同时预测每个任务对应的标签。
数据:
- OCNLI:是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集
- OCEMOTION:是包含7个分类的细粒度情感分析数据集
- TNEWS:来源于今日头条的新闻版块,共包含15个类别的新闻
3 相关工作
多任务学习(Multi-Task Learning/MTL),有时候也称为:联合学习( joint learning)、自主学习(learning to learn)、辅助任务学习(learning with auxiliary tasks )。大多数机器学习模型都是独立对一个任务进行学习的,而多任务学习则是将多个相关任务放在一起进行学习。从损失函数角度来说,只要优化的是多个损失函数,则就是在进行多任务学习。多任务学习的目标是,通过利用相关任务的训练信号中包含的特定领域信息来提高泛化能力。当前多任务学习的研究,主要集中在两个方面:模型结构和loss优化。
多任务学习动机
- 从生物学上讲,可以把MTL看作是受到人类学习的启发,在学习新任务时,人类通常会使用在其他相关任务上学来的知识。
- MTL避免重复计算共享层中的特征,既减少了内存的占用,也大大提高了推断速度。
- 单任务学习每个特定任务都需要大量带标签数据,MTL提供了一种有效的方法,来利用相关任务的监督数据。
- 多任务学习通过缓解对某一任务的多度拟合而获得正则化效果,从而使所学的表征在任务间具有通用性。
为什么有效?
- 每一个任务数据都有噪音,模型只学习一个任务容易在该任务上过拟合,而学习多个任务可以使模型通过平均噪声的方式获得更好的表示。
- 如果一个任务非常嘈杂,或者数据有限且高维,那么模型将很难区分相关和不相关的特征。MTL可以帮助模型将注意力集中在那些真正重要的特性上,因为其他任务将为这些特性的相关性或不相关性提供额外的证据。
- 对某个任务B来说,特征G比较容易学到,但对另外的任务A则比较难学到。可能因为任务A与特征G的交互比较复杂,或者其他特征阻碍了模型学习特征G的能力。这个时候,使用MTL,可以通过任务B来学习到特征G。
- MTL使模型偏向于所有任务都偏向的特征,这有助于推广到新的任务,因为特征在足够多的训练任务中表现良好,也会在新任务上表现良好,只要它们来自相同的环境。
- MTL通过引入归纳偏差来当做正则化,降低过拟合风险。
模型结构
- 硬共享模式
- 软共享模式
- 共享-私有模式
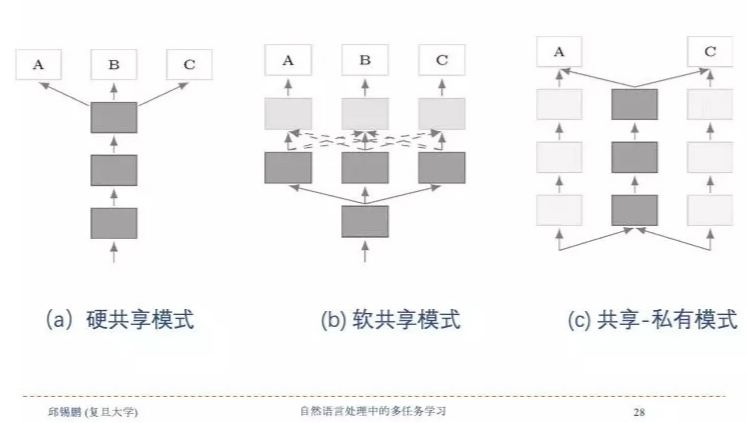
详细的介绍可见天池论坛
4 Baseline算法实现
使用TensorFlow1.x来实现多任务学习的baseline,采用的是硬共享模式。
详细代码见github项目AweSomeNLPBaseline 中的train_multi_learning.py文件。
3个epoch,没有任何的tricks,实现的分数如下:
- 使用chinese-bert-www-ext的score是0.5717
- 使用rberta-large的score是0.6236
接触这个比赛的时间太晚,已经快接近结束时间了。当前想了几个tricks如下:
- 在目标数据集上继续预训练
- 试试训练三个高精度teacher模型,来训练student模型
- 新增adam偏差修正
- 在实验过程中,ocemotion的score一直很低,可以尝试train完三个任务后,单独train一下这个任务
5 参考
【1】多任务学习优化(Optimization in Multi-task learning)
【2】模型汇总-14 多任务学习-Multitask Learning概述
【3】多任务学习-Multi-Task-Learning
【4】复旦大学邱锡鹏教授做客达观NLP研讨会:自然语言处理中的多任务学习
【5】Multi-Task Learning for Dense Prediction Tasks: A Survey
【6】An Overview of Multi-Task Learning in Deep Neural Networks
【7】Multi-Task Deep Neural Networks for Natural Language Understanding
【8】NLP集大成之预训练模型综述
【9】NLP重铸篇之BERT如何微调文本分类
【10】Multiple-gradient descent algorithm (mgda) for multiobjective optimization
【11】Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
【12】End-to-End Multi-Task Learning with Attention
【13】Dynamic task prioritization for multitask learning
【14】Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
【15】中文语言理解测评基准(CLUE)
【16】EasyTransfer:make the development of transfer learning in NLP applications easier.
最后
以上就是简单棒球最近收集整理的关于NLP中文预训练模型泛化能力挑战赛-Baseline算法实现的全部内容,更多相关NLP中文预训练模型泛化能力挑战赛-Baseline算法实现内容请搜索靠谱客的其他文章。








发表评论 取消回复