比赛链接:https://algo.qq.com
以下是Top-20队伍公布名单:
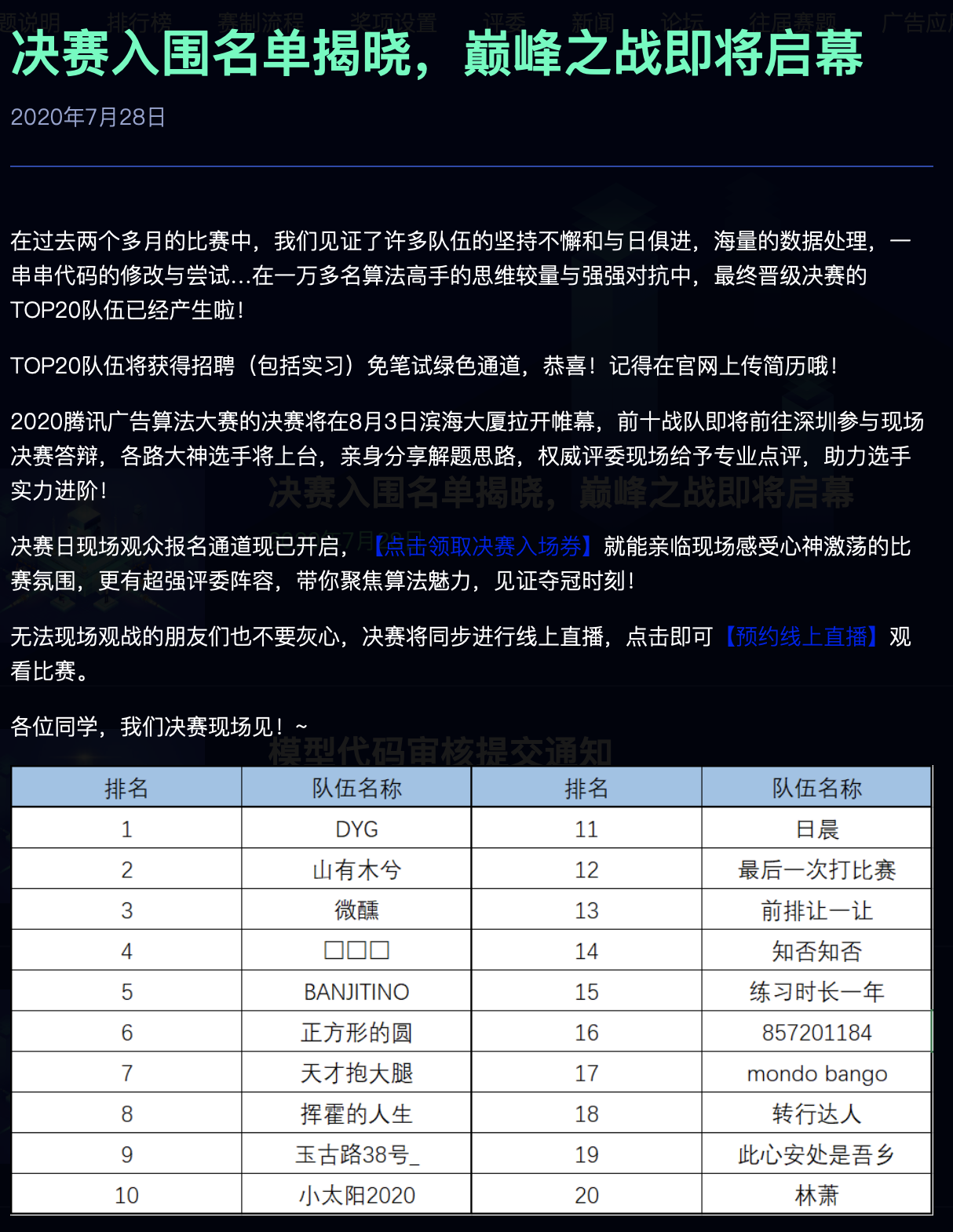
2020腾讯广告算法大赛
- 写在前面
- 赛题分析
- 方案分析
- 特征工程
- 模型的选择
- 特征提取
- 数据增广
- 调整学习率
- 有意思的尝试
- 模型的融合
- TOP-10方案总结
- 代码开源
- 写在最后
写在前面
先简单介绍下我们队伍的情况,队伍名称:日晨,我们队伍由三名在校生组成,昵称分别为:istar、lyu、wujie(我)。
最终的结果可以说是稍微有点遗憾了,和rank10只相差了0.0002左右的分数,错失了去深圳总部答辩学习(旅游玩耍)的机会哈哈。
因没有参与答辩,不会过多的包装,简洁迅速地解析我们的方案,并且我们会把一些有用没用的trick过一遍,希望可以帮到大家~
赛题分析
本次赛题给出一组用户在长度为 91 天(3 个月)的时间窗 口内的广告点击历史记录作为训练数据集。每条记录中包含了日期(从 1 到 91)、用户信息 (年龄,性别),被点击的广告的信息(素材 id、广告 id、产品 id、产品类目 id、广告主 id、广告主行业 id 等),以及该用户当天点击该广告的次数。详细说明请Click~
然后需要我们预测用户的性别和年龄段(主办方已将年龄提前分桶好)
可以看到给出的特征并不多,本次题目总结来说是脱敏数据下的nlp分类问题,由于数据均为脱敏处理,所以使用bert等一些预训练模型基本是没有可能。
方案分析
我们的方案主要从三个方面去介绍,特征工程,模型的选择以及模型的融合。
特征工程
在特征工程方面上,我们并没有做太多的尝试,因为对于这些大量的稀疏类别特征,刻画一些真正work的特征需要大量的业务知识,而我们作为在校生,更看重对于后面两部分的尝试并验证一些最新的想法吧。
我们的特征工程包括以下五部分:
Word2vec、Deepwalk、TfidfVectorizer、CountVectorizer、Target-encoding
Word2vec:提取词向量,输入的是各个用户按照时间的点击序列;
w2v = Word2Vec(input_docs, size=embed_size, sg=1, window=20, seed=2020, workers=64, min_count=1, iter=10)
Deepwalk:提取词向量,输入的是从各个用户id和特征id在构造好的图上随机游走的序列;
model = Word2Vec(sentences, size=L, sg=1, window=10, seed=1024, workers=64, min_count=1, iter=15)
TfidfVectorizer:统计特征,因输出维度很大,会使用七个弱模型stacking,在作为最终模型的输入;
CountVectorizer:统计特征,输出维度很大,与TfidfVectorizer处理方法一致;
#七个弱模型如下
model_list = [
['LogisticRegression', LogisticRegression(random_state=1017, C=3)],
['SGDClassifier', SGDClassifier(random_state=1017, loss='log')],
['PassiveAggressiveClassifier', PassiveAggressiveClassifier(random_state=1017, C=2)],
['RidgeClassfiy', RidgeClassifier(random_state=1017)],
['LinearSVC', LinearSVC(random_state=1017)],
['BernoulliNB', BernoulliNB()],
['MultinomialNB', MultinomialNB()]
Target-encoding:使用训练集的标签20分类五折交叉统计一些特征信息,比如用户各个id的一个概率值,最后进行mean和max。
模型的选择
如今各大比赛方案选择的模型无非两种,树模型和神经网络,对于这一道数据过亿的超大规模数据题目,NN无疑是最佳的选择。
特征提取
在经过embedding的提取后,我们需要进一步提取特征,使用的是最常见的LSTM、CNN、GRU;
通过多种搭积木的方法,再经过不断的调试,可以得到许多效果不错的模型;
模型网络结构可以参考下面的开源链接。
数据增广
nlp的数据增广并没有cv的骚操作多,最常见的就是增加、删除、替换、翻转、打乱。
在本赛题中,我们着重使用了翻转和打乱这两个操作,提分非常明显。
对于脱敏数据的数据增广上,我们有了进一步的思考,对embedding矩阵引入对抗样本的概念,梯度反向求导加到原有的embedding矩阵上,这一操作也是在单模上有了千分位的提升。值得一提的是,我们的对抗样本只用了最基本的FGM算法,因为机器计算资源有限,没能尝试PGD、FreeLB等更高级的算法。
当然,我们对测试集也有进行数据增广,在推理结果时,额外使用翻转这一个操作,对模型的两个输出进行平均处理。
调整学习率
因为这个赛题的特殊性,万分位的提升都可以影响最终的排名,因此学习率这一块必须认真考虑。
我们尝试了三种不同的学习率调整方法,还尝试了warmup等方法:
ReduceLROnPlateau(验证集);
周期性学习率调整;
余弦退火调整学习率。
最终选择的是ReduceLROnPlateau(验证集)和周期性学习率调整。
有意思的尝试
这里说一下,我们尝试的一些小trick和一些方法的心得吧(不一定有效)。
- Label-Smoothing(标签平滑),这个trick在 cv分类里面经常用到且有效的方法,在这道nlp题目里起不到一丝的作用,甚至还会有反作用。
- Pseudo-Labelling( 伪标签),这个一般应用到小型数据集中会有奇效,在针对这个大型数据集上,我们也是绞尽脑汁,从模型的输出分辨困难样本和错误样本,例如对错误样本更换标签等等,在单模上有1k左右的提升,但在stacking里效果不明显。
- 自蒸馏,因为有些用户是机器人等等的情况,导致标签存在一些不准确的情况,模型很可能被这些不准确的标签误导。我们尝试了自蒸馏的方式,将最终stacking模型的五折测试集输出,训练集的out-of-fold的结果与真正标签以3:7混合作为训练新模型的标签。单折age线下可以提升到5215+,效果很明显,但stacking效果也不明显。
- 对抗样本,在cv里的对抗训练对于普通样本效果一般会变差,但在nlp里面效果会变好,这也是值得关注的一个点。
模型的融合
模型的融合主要尝试了平均融合、加权融合、LGBstacking、NNstacking;
还尝试了一些参考皮尔逊相关系数剔除部分输出特征再stacking的方法;
经过线下线上尝试,最稳定的是NNstacking,一直保持线下线上一致,并且可以比平均融合线上高出1个k左右的分数。
TOP-10方案总结
决赛答辩结束后,再抽空总结一下前排大佬的方案~
代码开源
wujie的GitHub开源:链接????
lyu的GitHub开源:链接????
istar的GitHub开源:链接????
写在最后
腾讯这一年一度的算法大赛无疑是很值得参加的,基本国内的竞赛大佬都有出现,只有硬碰硬,我们才能接触到最前沿的业务和学习到最先进的算法~
感谢两个队友这三个月的战斗以及交流,相互学习,共同成长~
感谢腾讯给予复赛选手的免费4*v100资源(还得吐槽一下那个cos桶,坑了我200)~
明年有机会再见????~
最后
以上就是虚幻板凳最近收集整理的关于2020腾讯广告算法大赛初赛rank6,复赛rank11方案简单分享及代码开源的全部内容,更多相关2020腾讯广告算法大赛初赛rank6内容请搜索靠谱客的其他文章。








发表评论 取消回复