当前使用的操作系统:ubuntu11.10
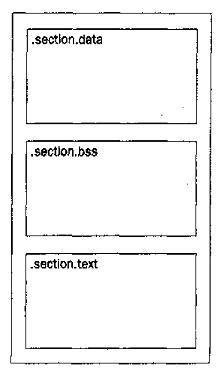
汇编程序由定义好的段构成,每个段都有不同的目的,三个最常用的段:
1)data 段
汇编程序data(数据)段是可选的。
数据段声明带有初始值的数据元素,这些数据元素用作汇编程序的变量。
2)bss 段
汇编程序 bss段 是可选的。
bss段声明使用 零(或 NULL)值初始化的数据元素。这些元素最常用作汇编程序中的缓冲区
3)text 段
汇编程序必须有 text(文本)段。
这个段是 在可执行程序内声明指令码 的地方。
定义段:
GNU汇编器使用 .section 命令语句声明段。
.section 语句只使用一个参数------它声明的段的类型
定义起始点:
当汇编语言程序被转换为可执行文件时,连接器必须知道指令码中的起始点是什么。
GNU 汇编器声明一个默认标签,或者说标识符,_start ,它应该用作应用程序的入口点。
_start 标签用于表明程序应该从这条指令开始运行。如果连接器找不到这个标签,就会生成如下错误消息:

汇编程序的基本模板如下:
.section.data
< initialized data here >
.section .bss
< initialized data here>
.section.text
.globl_start
_start:
@a1@
.section .data
output:
.ascii "The processor Vendor ID is 'XXXXXXXXXXXXX'n"
.section.text
.globl_start
_start:
#.globlmain
#main:
movl $0, %eax
cpuid
movl$output,%edi
movl%ebx,28(%edi)
movl%edx,32(%edi)
movl%ecx,36(%edi)
movl$4, %eax
movl$1,%ebx
movl$output,%ecx
movl$42,%edx
int$0x80
movl$1,%eax
movl$0, %ebx
int$0x80
sdf
CPUID 指令是一条汇编指令,它是请求处理器的特定信息并且把信息返回到特定寄存器的低级指令。
CPUID 指令使用单一寄存器值作为输入。EAX 寄存器用于决定 CPUID 指令生成什么信息。根据 EAX 寄存器的值, CPUID 指令在 EBX,ECX 和 EDX 寄存器中生成关于处理器的不同信息。

本例子中,使用零选项从处理器获得简单的厂商ID字符串。
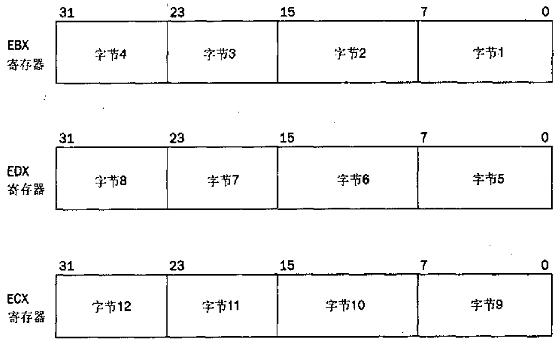
当 零(0)值被放入到 EAX 寄存器并且执行 CPUID 指令时,处理器把厂商ID字符串返回到 EBX,EDX 和 ECX 寄存器中,如下:
1)EBX 包含字符串的最低 4 个字节
2)EDX 包含字符串的中间 4 个字节
3)ECX 包含字符串的最高 4 个字节
字符串按照 小端法(little-endian)格式放入寄存器中:
@b1@ 在数据段中声明了一个字符串:
output:
.ascii "The processor Vendor ID is 'XXXXXXXXXXXXX'n"
.ascii 声明使用 ASCII 字符声明一个文本字符串。
这个字符串元素被预定义并且放在内存中,其起始内存位置由 output标识符 指示。
后面的 x 在保留给数据变量的内存区域中作为占位符,从处理器获得厂商ID字符串时,会把这些字符串放在位于这些内存位置的数据中。
@b2@ 声明程序的指令码和一般的起始位置:
.section.text
.globl_start
_start:
@b3@ 程序做的第一件事就是使 EAX 寄存器 加载 零 值,然后运行 CPUID 指令:
movl $0, %eax
cpuid
@b4@ EAX中的零值定义 CPUID 输出选项(在本例子 中是厂商ID字符串)。
CPUID指令运行之后,必须收集分散在 3个 输出寄存器中的指令响应:
movl$output,%edi
movl%ebx,28(%edi)
movl%edx,32(%edi)
movl%ecx,36(%edi)
首先创建一个指针,处理内存中声明的 output 变量时会使用这个指针。
output 标识符的内存位置被加载到 EDI 寄存器中。
接下来,按照 EDI 指针,包含厂商ID字符串片段的 3 个寄存器的内容被放到数据内存中的正确位置。
括号外的数值表示相对于 output标识符的放置数据的位置。这个数字和 EDI 寄存器中的地址相加,确定寄存器中的值被写入的地址。这个过程使用实际的厂商ID字符串片段替换用作 x 占位符(注意:厂商ID字符串按照奇怪的顺序 EBX,EDX 和 ECX 分散在寄存器中) 。
@b5@ 在内存中放置好所有厂商ID字符串片段之后,就可以显示信息了:
movl$4,%eax
movl$1,%ebx
movl$output,%ecx
movl$42,%edx
int$0x80
使用一个 linux 系统调用(int $0x80)从 linux 内核访问控制台显示。linux 内核提供了很多可以很容易地从汇编应用程序访问的预置函数。为访问内核函数,必须使用 int 指令码,它生成具有 0x80 值的软中断。
执行的具体函数有EAX寄存器的值来确定。如果没有这个内核函数,就必须自己把每个输出字符发送到正确的显示器 I/O地址上。
4 对应的是 sys_write
linux 的 write 系统调用用于把字节写入到文件中。
1)EAX包含系统调用的值
2)EBX包含要写入的文件描述符
3)ECX包含字符串的起始地址
4)EDX包含字符串的长度
标准输出(STDOUT)表示当前会话的显示终端,它的文件描述符为 1,。写入到这个文件描述符将在控制台屏幕上显示信息。
@b6@ 显示完信息后,就应该退出程序:
movl$1,%eax
movl$0, %ebx
int$0x80
sdf
通过系统调用1(sys_exit()),程序被正确的终止,并且返回到命令提示符,零值表示程序成功执行。
EBX 寄存器包含程序返回给shell的退出代码值。可以使用 EBX寄存器的内容,按照汇编程序内的情况在shell脚本程序中生成不同的结果。
@b DONE@
生成可执行文件:

运行可执行文件:

用 gcc 编译:
1,修改代码如下:
.section.text
#.globl_start
#_start:
.globlmain
main:

调试程序:(为了调试汇编程序,必须使用 -gstabs 参数编译源文件)
@a2@ 在汇编程序中使用 C库函数
.section.data
output:
.asciz"The process vandor id is '%s'n"
.section .bss
.lcommbuffer,12
.section.text
.globl_start
_start:
movl$0,%eax
cpuid
movl$buffer,%edi
movl%ebx,(%edi)
movl%edx,4(%edi)
movl%ecx,8(%edi)
pushl$buffer
pushl$output
callprintf
addl$8,%esp
pushl $0
callexit
@b1@ .asciz 命令
printf函数使用多个输入参数,这些参数取决于要显示的变量。第一个参数是输出字符串,带有用于显示变量:
output:
.asciz"The process vandor id is '%s'n"
sfsdf
注意:这里使用的是 .asciz 命令,而不是 .ascii 。printf 函数要求以空字符串结尾的作为输出字符串。 .asciz 命令在定义的字符串末尾添加空字符。
@b2@ .lcomm 命令
printf函数要使用的下一个参数是将要包含 厂商ID字符串的缓冲区。因为不需要定义这个缓冲区的初始值,所以在 bss段中使用 .lcomm 命令把它声明为 12 个字节的缓冲区区域:
.section .bss
.lcommbuffer,12
@b3@ PUSHL指令
pushl$buffer
pushl$output
callprintf
为了把参数传递给 C 函数 printf,必须把参数压入堆栈中。这就要使用 PUSHL 指令完成。
参数放入堆栈的顺序和 printf 函数获取它们的顺序是相反的,所以缓冲区值被首先放入,然后是输出字符串值。
完成这些操作后, 使用 CALL 指令调用 printf 函数。
@b4@ 程序退出
addl$8,%esp
pushl $0
callexit
ADDL 指令用于清空 为 printf 函数放入堆栈中的参数。
再通过 PUSHL 指令把 0 压入堆栈中,
最后调用系统函数 exit,参数为 0,也就是exit(0);表示程序正常退出。
@b DONE@
连接C库函数
1)在汇编程序中使用 C 库函数时,必须把 C库文件连接到程序目标代码中,如果C库函数不可用,连接 器会发生如下错误:

在 linux 系统上,标准的 C 动态库位于 libc.so.x 文件中,其中 x 表示库的版本。
这个库文件包含了标准 C 函数,包括 printf 和 exit。
在使用 gcc 时,这个文件会被自动连接到 C 程序中。但是在汇编程序中,必须手动把它连接到程序目标代码中以便 C 函数能够操作。为了连接 libc.so 文件,必须使用 GNU 连接器的 -l 参数:

这个时候,连接了标准C函数库文件的程序目标代码没有问题。可是当执行这个可执行文件时,却发生了错误。
原因:连接器能够解析 C 函数,但是函数本身没有包含到最终的可执行程序中,我们使用的是动态链接库,连接器假设运行时能够找到必须的库文件。显然,本例子中并不是这样。
为解决这个问题,还必须指定在运行时加载动态库的程序:

@a DONE@
最后
以上就是紧张柜子最近收集整理的关于Linux运行8086代码,* linux下编译,链接,运行,汇编程序的全部内容,更多相关Linux运行8086代码,*内容请搜索靠谱客的其他文章。








发表评论 取消回复