今日分享开始啦,请大家多多指教~
Spring 的循环依赖已经被说烂了,可能很多人也看吐了。但很多说的还是不够清楚,没有完整的表达出 Spring 的设计目的。只介绍了 What ,对于 Why 的介绍却不太够。
本文会从设计角度,一步一步详细分析 Spring 这个“三级缓存”的设计原则,说说为什么要这么设计。
Bean 创建流程
Spring 中的每一个 Bean 都由一个BeanDefinition 创建而来,在注册完成 BeanDefinition 后。会遍历BeanFactory中的 beanDefinitionMap 对所有的 Bean 调用 getBean 进行初始化。
简单来说,一个 Bean 的创建流程主要分为以下几个阶段:
- Instantiate Bean - 实例化 Bean,通过默认的构造函数或者构造函数注入的方式
- Populate Bean - 处理 Bean 的属性依赖,可以是Autowired注入的,也可以是 XML 中配置的,或者是手动创建的
BeanDefinition 中的依赖(propertyValues) - Initialize Bean - 初始化 Bean,执行初始化方法,执行 BeanPostProcessor 。这个阶段是各种 Bean
的后置处理,比如 AOP 的代理对象替换就是在这个阶段
在完成上面的创建流程后,将 Bean 添加到缓存中 - singletonObjects,以后在 getBean 时先从缓存中查找,不存在才创建。
Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
先抛开 Spring 的源码不谈,先看看按照这个创建流程执行会遇到什么问题
1. Instantiate Bean
首先是第一阶段 - 实例化,就是调用 Bean Class的构造函数,创建实例而已,没啥可说的。至于一些获取 BeanDefinition 构造方法的逻辑,不是循环依赖的重点。
2. Populate Bean
第二阶段 - 填充Bean,其目的是查找当前 Bean 引用的所有 Bean,利用 BeanFactory 获取这些 Bean,然后注入到当前 Bean 的属性中。
正常情况下,没有循环引用关系时没什么问题。比如现在正在进行 ABean 的 populate 操作,发现了 BBean 的引用,通过 BeanFactory 去 getBean(BBean) 就可以完成,哪怕现在 BBean 还没有创建,在getBean中完成初始化也可以。完成后将 BBean 添加到已创建完成的 Bean 缓存中 - singletonObjects。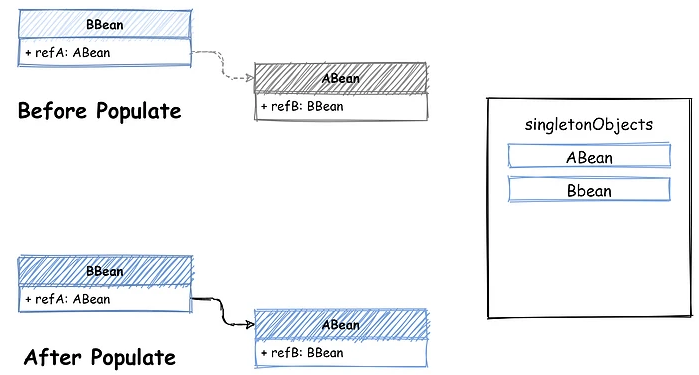
最后再将获取的 BBean 实例注入到 ABean 中就完成了这个 populate 操作,看着还挺简单。
此时引用关系发生了点变化,ABean 也依赖了 BBean,两个 Bean 的引用关系变成了互相引用,如下图所示: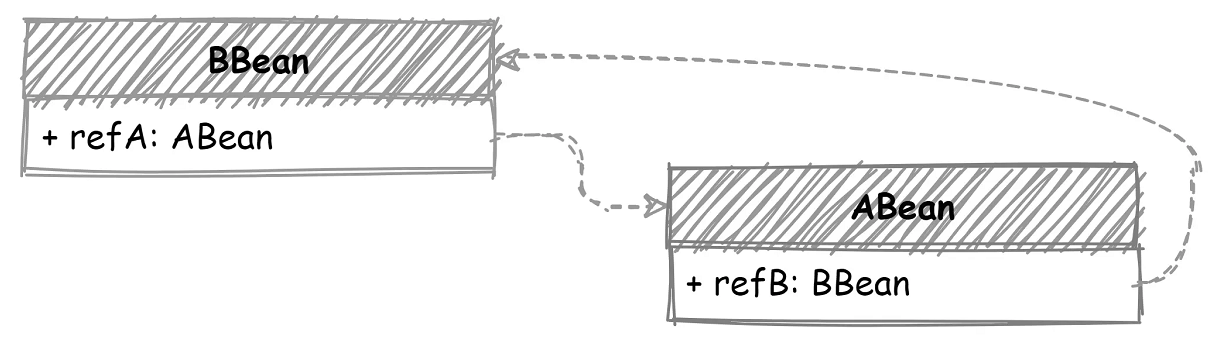
再来看看现在 populate 该怎么执行:
首先还是先初始化 BBean ,然后发现了 Bbean 引用的 ABean,现在 getBean(ABean),发现 ABean 也没有创建,开始执行对 ABean 的创建:先实例化,然后对 ABean 执行 populate,可 populate 时又发现了 ABean 引用了 BBean,可此时 BBean 还没有创建完成,Bean 缓存中也并不存在。这样就出现死循环了,两个 Bean 相互引用,populate 操作完全没法执行。
其实解决这个问题也很简单,出现死循环的关键是两个 Bean 互相引用,populate 时另一个 Bean 还在创建中,没有创建完成。
只需要增加一个中间状态的缓存容器,用来存储只执行了 instantiate 还未 populate 的那些 Bean。到了populate 阶段时,如果完整状态缓存中不存在,就从中间状态缓存容器查找一遍,这样就避免了死循环的问题。
如下图所示,增加了一个中间状态的缓存容器 - earlySingletonObjects,用来存储刚执行 instantiate 的 Bean,在 Bean 完成创建后,从 earlySingletonObjects 删除,添加到 singletonObjects 中。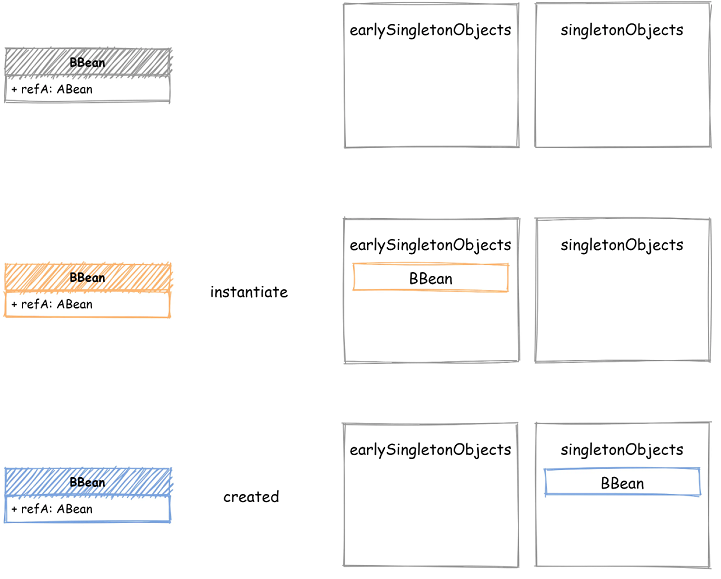
回到上面的例子,如果在 ABean 的 populate 阶段又发现了 BBean 的引用,那么先从 singletonObjects 查找,如果不存在,继续从 earlySingletonObjects 中查找,找到以后注入到 ABean 中,然后 ABean 创建完成(BeanPostProcessor待会再说)。现在将 ABean 添加到 singletonObjects 中,接着返回到创建 BBean 的过程。最后把返回的 ABean 注入到 BBean 中,就完成了 BBean 的 populate 操作,如下图所示: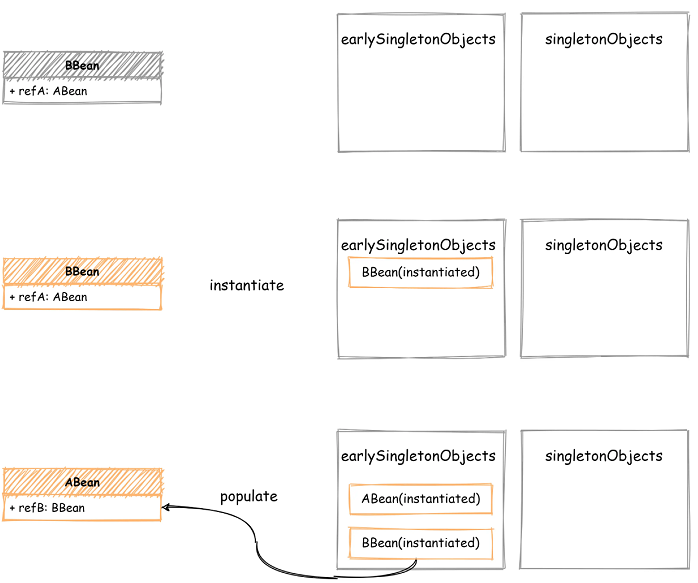
循环依赖的问题,就这么轻易的解决了,看着很简单,只是加了一个中间状态而已。但除了 instantiate 和 populate 阶段,还有最后一个执行 BeanPostProcessor 阶段,这个阶段可能会增强/替换原始 Bean
3. Initialize Bean
这个阶段分为执行初始化方法 - initMethod,和执行 BeanFactory 中定义的 BeanPostProcessor(BPP)。执行初始化方法没啥可说的,重点看看 执行BeanPostProcessor 部分。
BeanPostProcessor 算是 Spring 的灵魂接口了,很多扩展的操作和功能都是通过这个接口,比如 AOP。在populate 完成之后,Spring 会对 Bean 顺序执行所有的 BeanPostProcessor,然后返回 BeanPostProcessor 返回的新 Bean 实例(可能有修改也可能没修改)
//org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#applyBeanPostProcessorsBeforeInitialization
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
//对当前 Bean 顺序的执行所有的 BeanPostProcessor,并返回
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
Spring 的 AOP 增强功能,也是利用 BeanPostProcessor 完成的,如果该 Bean 有 AOP 增强的配置,那么执行完 BeanPostProcessor 之后就会返回一个新的 Bean,最后存储到 singletonObjects 中的也是这个增强之后的 Bean
可我们上面的“中间状态缓存”解决方案中,存储的却只是刚执行完成 instantiate 的 Bean。如果在上面循环依赖的例子中,populate ABean 时由于 BBean 只完成了实例化,所以会从 earlySingletonObjects 获取只完成初始化的 BBean 并注入到 ABean中。
如果 BBean 有 AOP 的配置,那么此时注入到 ABean 中的 只是一个只实例化未 AOP 增强的对象。当 BBean 执行 BeanPostProcessor 后,又会创建一个增强的 BBean 实例,最终添加到 singletonObjects 中的,是增强的 BBean 实例,而不是那个刚实例化的 BBean 实例
如下图所示,BBean 中注入的是黄色的只完成了初始化的 ABbean,而最终添加到 singletonObjects 却是执行完 AOP 的增强 ABean 实例: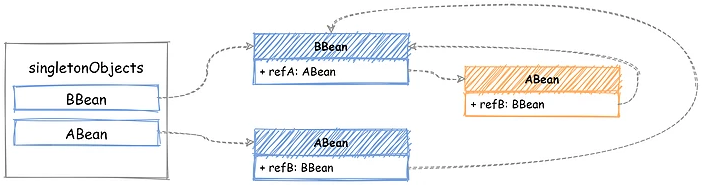
由于 populate 之后还有一步 BeanPostProcessor 的增强,导致我们上面的解决方案无效了。但也不是完全无解,如果可以让增强型的 BeanPostProcessor 提前执行,然后添加到“中间状态的缓存容器”中,是不是也可以解决问题?
不过并不是所有的 Bean 都有 AOP(及其他执行 BPP 后返回新对象) 的需求,如果让所有 Bean 都提前执行 BeanPostProcessor 并不合适。
所以这里可以采用一种“延迟处理”的方式,在中间增加一层 Factory,在这个 Factory 中完成“提前执行”的操作。
如果没有提前调用某个 Bean 的 “延迟处理”Factory,那么就不会导致提前执行 BeanPostProcessor,只有循环依赖场景下,才会出现这种只完成初始化却未完全创建的 Bean ,才会调用这个 Factory。这个 Factory 的模式就叫延迟处理,如果不调用 Factory 就不会提前执行 BPP。
instantiate 完成后,把这个 Factory 添加到“中间状态的缓存容器”中;这样当发生循环依赖时,原先获取的中间状态 Bean 实例就会变成这个 Factory,此时执行这个Factory 就可以完成“提前执行 BeanPostProcessor”的操作,并且获取执行后的新 Bean 实例
现在增加一个 ObjectFactory,用来实现延迟处理:
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
然后再创建一个 singletonFactories,作为我们新的中间状态缓存容器,不过这个容器存储的并不是 Bean 实例,而是创建 Bean 的实现代码
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
现在再写一个“提前执行”BeanPostProcessor 的 ObjectFactory,添加到 singletonFactories 中。
//完成bean 的 instantiate 后
//创建一个对该 Bean 提前执行 BeanPostProcessor 的 ObjectFactory
//最后添加到 singletonFactories 中
addSingletonFactory(beanName,
() -> getEarlyBeanReference(beanName, mbd, bean)
);
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
......
}
}
}
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//提前执行 BeanPostProcessor
for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {
exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
}
再次回到上面循环依赖的例子,如果在对 ABean 执行 populate 时,又发现了 BBean 的引用,那么此时先从我们这个新的延迟处理+提前执行的缓存容器中查找,不过现在找到的已经不再是一个 BBean 实例了,而是我们上面定义的那个getEarlyBeanReference 的 ObjectFactory ,通过调用 ObjectFactory.getObject() 来获取提前执行 BeanPostProcessor 的这个 ABean 实例。
如下图所示,在对 ABean 执行 populate 时,发现了对 BBean 的引用,那么直接从 singletonFactories 中查找 BBean 的 ObjectFactory 并执行,获取 BeanPostProcessor 增强/替换后的新 Bean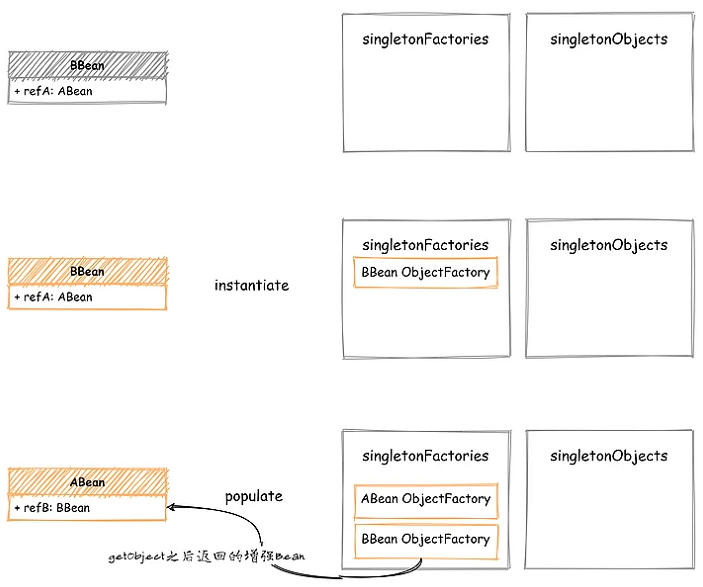
现在由于我们的中间状态数据从 Bean 实例变成了 ObjectFactory,所以还需要在初始化之后,再检查一下 singletonFactories 是否有当前 Bean,如果有的化需要手动调用一下 getObject 来获取最终的 Bean 实例。
通过“延迟执行”+“提前执行”两个操作,终于解决了这个循环依赖的问题。不过提前执行 BeanPostProcessor 会导致最终执行两遍 BeanPostProcessor ,这个执行两遍的问题还需要处理。
这个问题解决倒还算简单,在那些会更换原对象实例的 BeanPostProcessor 中增加一个缓存,用来存储已经增强的 Bean ,每次调用该 BeanPostProcessor 的时候,如果缓存中已经存在那就说明创建过了,直接返回上次创建的即可。Spring 为此还单独设计了一个接口,命名也很形象 - SmartInstantiationAwareBeanPostProcessor
如果你定义的 BeanPostProcessor 会增强并替换原有的 Bean 实例,一定要实现这个接口,在实现内进行缓存,避免重复增强
貌似现在问题已经解决了,一开始设计的 earlySingletonObjects 也不需要了,直接使用我们这个中间状态缓存工厂 - singletonFactories 就搞定了问题。
不过……如果依赖关系再复杂一点,比如像下面这样,ABean 中有两个属性都引用了 BBean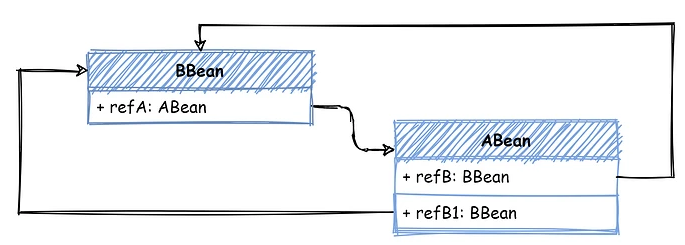
那么在对 ABean 执行 populate 时,先处理 refB 这个属性;此时从 singletonFactories 中查找到 BBean 的这个提前执行 BeanPostProcessor 的 ObjectFactory,调用 getObject 获取到提前执行 BeanPostProcessor 的 BBean 实例,注入到 refB 属性中。
那到了 refB1 这个属性时,由于 BBean 还是一个没有创建完成的状态(singletonObjects 中不存在),所以仍然需要获取 BBean 的 ObjectFactory,执行 getObject,导致又对 BBean 执行了一遍 BeanPostProcessor。
为了处理这个多次引用的问题,还是需要有一个中间状态的缓存容器 - earlySingletonObjects。不过这个缓存容器和一开始提到的那个 earlySingletonObjects 有一点点不同;一开始提到的 earlySingletonObjects 是存储只执行了 instantiate 状态的 Bean 实例,而我们现在存储的是执行 instantiate 之后,又提前执行了 BeanPostProcessor 的那些 Bean。
在提前执行了 BeanPostProcessor 之后,将返回的新的 Bean 实例也添加到 earlySingletonObjects 这个缓存容器中。这样就算处于中间状态时有多次引用(多次 getBean),也可以从 earlySingletonObjects 获取已经执行完 BeanPostProcessor 的那个 Bean,不会造成重复执行的问题。
总结
回顾一下上面一步步解决循环依赖的流程,最终我们通过一个延迟处理的缓存容器,加一个提前执行完毕BeanPostProcessor 的中间状态容器就完美解决了循环依赖的问题
至于 singletonObjects 这个缓存容器,它只用来存储所有创建完成的 Bean,和处理循环依赖关系并不大。
至于这个处理机制,叫不叫“三级缓存”……见仁见智吧,Spring 在源码/注释中也没有(3-level cache之类的字眼)。而且关键的循环依赖处理,只是“二级”(延迟处理的 Factory + 提前执行 BeanPostProcessor 的Bean),所谓的“第三级”是应该是指 singletonObjects。
下面用一张图,简单总结一下处理循环依赖的核心机制: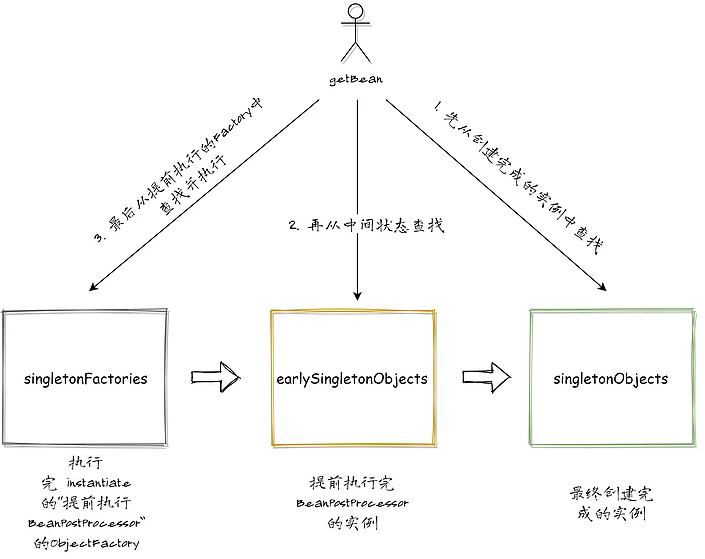
不过提前执行 BeanPostProcessor 这个操作,算不算打破了原有的设计呢?原本 BeanPostProcessor 可是在创建Bean 的最后阶段执行的,可现在为了处理循环依赖,给移动到 populate 之前了。虽然是一个不太优雅的设计,但用来解决循环依赖也不错。
尽管 Spring 支持了循环依赖(仅支持属性依赖方式,构造方法依赖不支持,因为实例化都完成不了),但实际项目中,这种循环依赖的关系往往是不合理的,应该从设计上就避免。
今日份分享已结束,请大家多多包涵和指点!
最后
以上就是体贴蛋挞最近收集整理的关于从设计角度,深入分析 Spring 循环依赖的解决思路的全部内容,更多相关从设计角度,深入分析内容请搜索靠谱客的其他文章。








发表评论 取消回复