
MySQL作为最常用的数据库管理语言之一,在使用过程中经常会遇到排名问题,下面就来梳理一下MySQL排名情况。
先建立score表,插入数据
create table score values(student_id int,class int,score int);
insert into score(student_id,class,score) VALUES
(1,1,98),
(2,1,76),
(3,1,98),
(4,1,60),
(5,2,88),
(6,2,76),
(7,2,98),
(8,2,45),
(9,3,23),
(10,3,97),
(11,3,94),
(12,3,65)查看数据
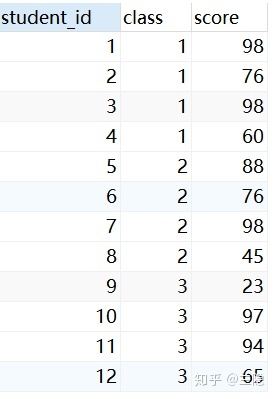
问题1:不考虑是否有分数相同的情况,对每个分数进行从高到底排名,即同样的分数可以名次不一样。
解答:不考虑分数相同的情况下,即只要按照分数从高到底排好序之后统计行号就能达到目的。
SELECT a.*,(@rownum:=@rownum +1) as rank from score as a,(SELECT (@rownum:=0)) as b
order by a.score desc得到结果如下,三个98分分别是第1, 第2,第3名,名次总数等于行数。
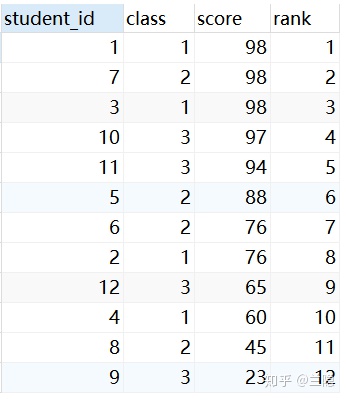
问题2:考虑分数相同的情况,比如3个98分相同时,排名不变,当分数不同时,排名增加1,即接下来的97分是第2名。
解答:理解排名的含义,第N名其实就是有N-1个分数(前N-1名的分数,不重复)比我的分数高
SELECT a.*,(SELECT COUNT(distinct b.score) FROM score as b where a.score<b.score) +1 as rank
from score as a
ORDER BY a.score DESC结果如下,12个分数有3个是与其他重复的,因此只有9个名次。
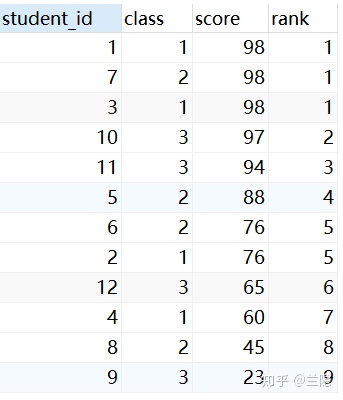
问题3:考虑分数相同的情况,比如3个98分相同时,排名不变,但是会占据一个位置,当分数不同时,比如接下来的97分是第4名。
解答:这里跟问题2的区别在于,问题2是根据的分数是可以重复的,而这里的分数是不能重复的。即:第N名是前面有N-1个人的分数(哪怕前N-1个人的分数是一样的)比我高。因此,这里只需要将问题2中的SQL语句中的distinct去掉即可。
SELECT a.*,(SELECT COUNT(b.score) FROM score as b where a.score<b.score) +1 as rank
from score as a
ORDER BY a.score DESC结果如下,可以看出第2,第3名是缺失的,被另外两个98分占据了。
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
Hive提供了窗口函数,以上问题可以通过窗口函数来解决。
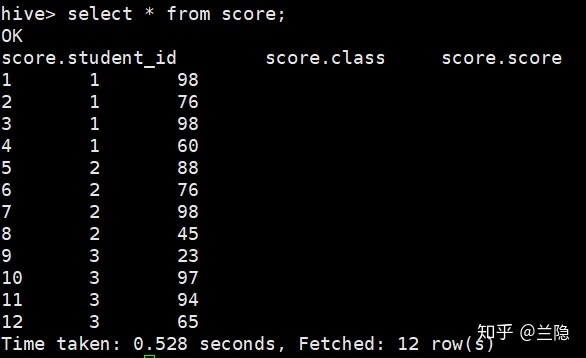
进入Hive,首先一样是建表,插入数据,查询数据结果如下:
对应上面的3种排名问题,Hive分别有三个窗口函数:
row_number():按照顺序,从1开始,row_number()的值不会重复,当排序值相同时会按照表中的顺序进行排列。
rank():值相同时排名一样,会留下空位。
dense_rank():dense,密集的意思。值相同时排名一样,不会留下空位。
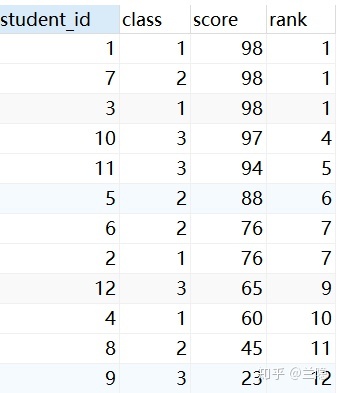
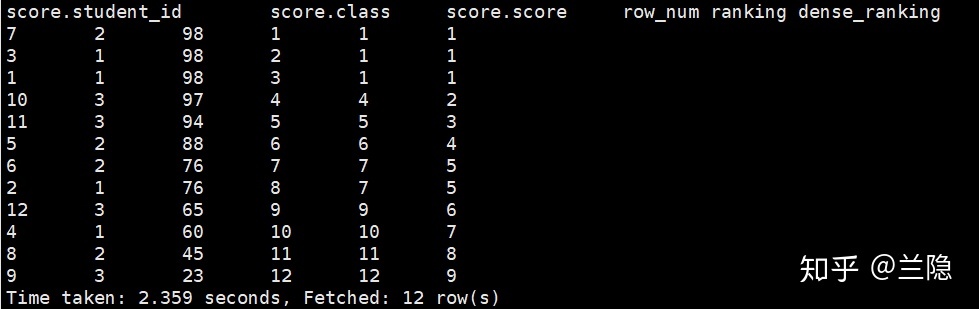
Hive执行如下语句:
select *,
row_number() over (order by score desc) as row_num,
rank() over (order by score desc) as ranking,
dense_rank() over (order by score desc) as dense_ranking
from score;结果如下,row_num, ranking, dense_ranking同时查询出来了。
当然,Hive的这几个窗口函数还经常被用在分组排名上面。
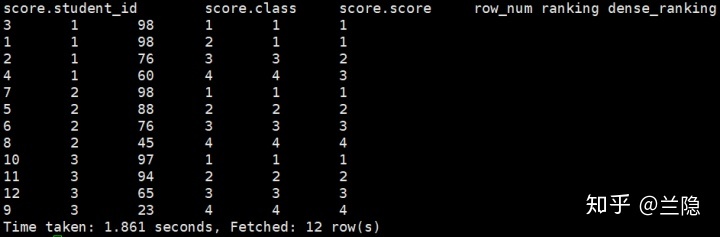
如根据以上几个窗口函数按照班级分组再排名一次,则只需要在order by score desc的前面加上partition by class 就好。
select *,
row_number() over (partition by class order by score desc) as row_num,
rank() over (partition by class order by score desc) as ranking,
dense_rank() over (partition by class order by score desc) as dense_ranking
from score;结果如下
窗口函数在分组排名是确实非常好用,省去了在MySQL写一些比较长的条件判断、赋值语句,也能极大地方便查询。
最后
以上就是无私白猫最近收集整理的关于虚拟机 中hive中的数据导入mysql_MySQL和Hive中的排名问题的全部内容,更多相关虚拟机内容请搜索靠谱客的其他文章。








发表评论 取消回复