-
- 简介
- 打开Hive
- 任务描述
- 解决思路
- 技术点
简介
Hive是Hadoop生态中非常重要的一环,可以作为数据仓库存储极大量的数据;另外,还可以实现与MySQL、NoSQL等传统数据库,HBase等大数据控件之间的数据ETL。在我的日常工作中,将使用Hive的经验总结如下。
打开Hive
Hive从属于Hadoop生态的一环,一般安装在Linux服务器上,我司也不例外。由于环境早已配置好了,这里只讲述hive的使用,不讲述其安装配置。
1.打开Xshell软件,建立个人Windows PC机与Linux服务器的远程连接;
2.在界面中输入su hdfs进入操作者模式,再输入hive,从Linux中进入Hive内部,启动Hive的代码如下:
[root@name01-test ~]# su hdfs
[hdfs@name01-test root]$ hive
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/spark-assembly-1.6.0-cdh5.15.0-hadoop2.6.0-cdh5.15.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/spark-assembly-1.6.0-cdh5.15.0-hadoop2.6.0-cdh5.15.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/spark-assembly-1.6.0-cdh5.15.0-hadoop2.6.0-cdh5.15.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.15.0-1.cdh5.15.0.p0.21/jars/hive-common-1.1.0-cdh5.15.0.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> [hdfs@name01-test root]$ 注意:这里只有第一行的[root@name01-test ~]# su hdfs中的su hdfs和第二行的hive是自己手动输入的,下面的大段代码都是系统默认给出的,不用管。接下来,在hive> [hdfs@name01-test root]$后面敲出Hive SQL即可;
注意:这里进入hive的代码,不能直接输入hive;因为我连接服务器的账号是root,而当hadoop集群加上权限管理后,即使是linux的root用户也不能拥有最高权限了,root用户很多数据库都进去不了了。因为hdfs的管理员是hdfs,因此,只能以su dhfs的方式进去;
3.Hive QL简称HQL,语法与MySQL几乎完全一样。所以说,搞数据开发,MySQL是基石,非常之重要;
任务描述
昨天小组组长给了一个新手任务:
我的本地电脑描述为PC-A,远程电脑PC-B上有个MySQL数据库,hadoop集群部署在测试服务器PC-C上。现在,需要把PC-B上的一些table导入到PC-C的Hive数据仓库中。怎么办?
解决思路
- 利用Navicat软件连接到远程电脑PC-B的MySQL上,会发现MySQL中有很多个DataBases,每个db又有很多个Tables。选择自己需要导出的Tables,记住它的名字。假设需导出的table为数据库D_db下的E_tab;
- 利用Kettle Spoon软件,连接到D_db上;然后建立“表输入”-“文本文件输出”关系,以E-tab为输入文件,自主命名一个txt为输出文件,利用Kettle Spoon将MySQL中的目标表格转化为F_txt格式,并保存到本地;
- 利用Xftp软件,建立起PC-A本地电脑与hadoop PC-C的连接,再讲上述的F_txt拷贝到PC-C的Linux的某个地址下;
- 利用Xshell软件,再PC-A上远程操作PC-C的系统,进入hive数据库之后,新建一个新表G_tab,然后将F_txt直接加载到G_tab中,即完成了小组长所述的数据转移操作。
技术点
- 将本地电脑PC-A连接到远程服务器PC-B~MySQL。这个实在太简单了,就不说了;
- Navicat、Kettle Spoon、Xftp、Xshell的基本使用方法;
- Linux的基本命令,MySQL和Hive的基本语句(二者很相似);
- 在PC-C中新建的表格G_tab,其属性名必须与E_tab完全一致。创建G_tab的方法,需要使用到其DLL,可通过下面两种方法来得到;
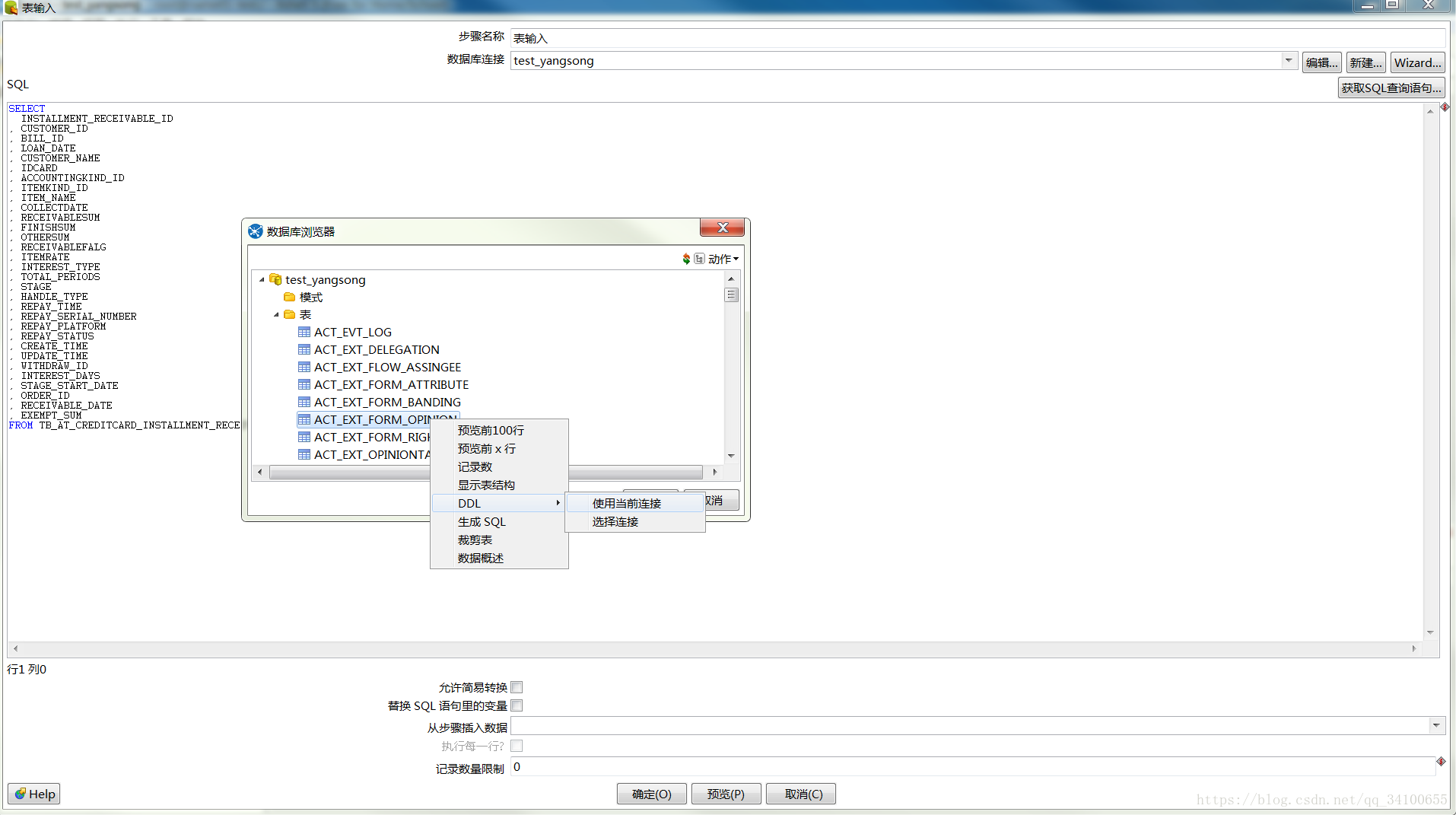
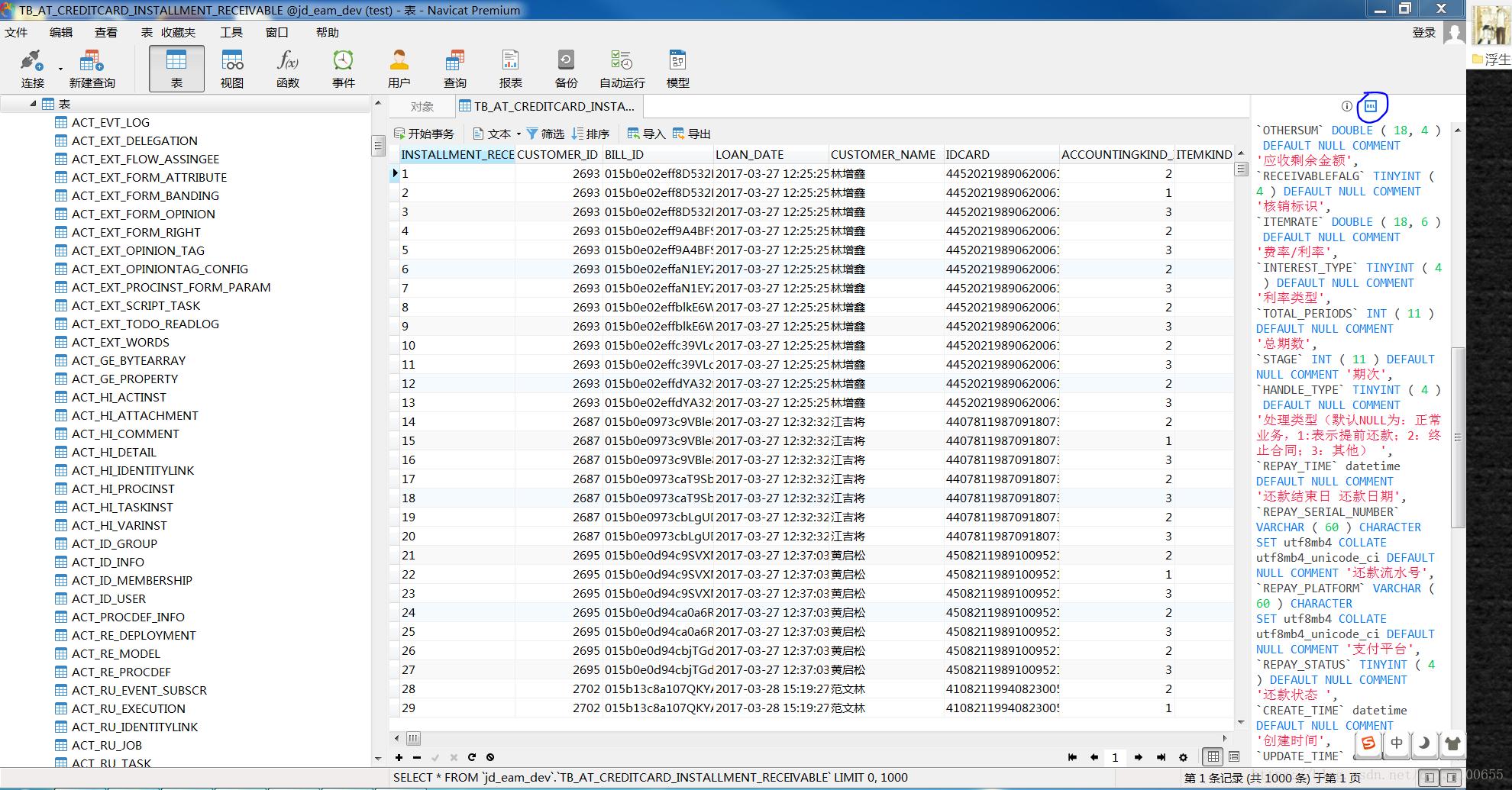
- 得到DLL之后,还需要修改其语法,特别是属性、分隔符等,使其符合Hive语法,才能将上述语句粘贴到Hive命令行下面,新建G_tab;
load data local inpath '/root/ys/ys.txt(你自己的文件名及Linux路径)' into table G_tab; 详情可参考https://www.cnblogs.com/juncaoit/p/6027977.html; - 要尤其注意,使用Kettle Spoon转换MySQL为txt的时候,要设置分隔符,最好是||,这一点非常重要;相对应的,在新建G_tab时,要在其DLL末尾加上一句:
ROW FORMAT DELIMITED FIELDS TERMINATED BY '(分隔符)' STORED AS TEXTFILE。否则,导入Hive的都是NULL;
8.导入完毕之后,使用:SELECT * FROM G_tab或者SELECT * FROM G_tab LIMIT 100查看前100行数据,是否与MySQL中的一致,若不一致,则说明导入Hive出了问题。
最后
以上就是迷人导师最近收集整理的关于数据转移-从MySQL到Hive的全部内容,更多相关数据转移-从MySQL到Hive内容请搜索靠谱客的其他文章。








发表评论 取消回复