- MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。官方文档
入门
初始化工程
- 通过Spring Initializr 初始化一个Spring Boot 的工程。版本选择
2.2.1.RELEASE,MyBatis-Plus 版本选择3.0.5两个要配对,不然会出问题。
引入依赖
<dependencies>
<!-- spring boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--spring boot devtools 用于热部署之类的-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<!-- 配置处理器,配置文件代码提示 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<!-- bean的辅助工具类-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- spring boot的测试starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
配置
- 要配置一个数据库的连接,不然一开始就无法运行。在
application.yml或application.properties文件中配置。spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/mybatisplus?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&rewriteBatchedStatements=true spring.datasource.username=root spring.datasource.password=root
使用
创建一个数据库
DROP TABLE IF EXISTS user;
CREATE TABLE `user`
(
id BIGINT(20) NOT NULL COMMENT AUTO_INCREMENT '主键ID',
NAME VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
create_time DATETIME COMMENT "创建时间",
update_time DATETIME COMMENT "更新时间",
`version` INT DEFAULT 0 COMMENT "版本号",
`deleted` BOOLEAN DEFAULT FALSE COMMENT "删除标志 0为未被删除 1为被删除"
PRIMARY KEY (id)
);
DELETE FROM user;
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');
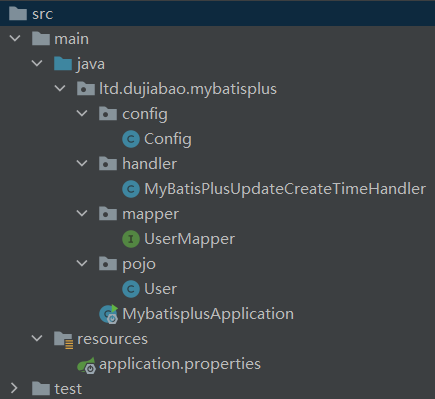
工程目录
- config为配置类的包,
Handler为一些额外的处理方法,mapper为dao层,pojo为java bean
Java Bean
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.NONE)
private Long id;
private String name;
private Integer age;
private String email;
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
@Version
@TableField(fill = FieldFill.INSERT)
private Integer version;
@TableLogic
@TableField(fill = FieldFill.INSERT)
private Integer deleted;
}
mapper
- 写一个继承MyBatis Plus(后面简称MP)的mapper接口
@Repository public interface UserMapper extends BaseMapper<User> { } BaseMapper源码。增删改查操作基本都有。public interface BaseMapper<T> { int insert(T var1); int deleteById(Serializable var1); int deleteByMap(@Param("cm") Map<String, Object> var1); int delete(@Param("ew") Wrapper<T> var1); int deleteBatchIds(@Param("coll") Collection<? extends Serializable> var1); int updateById(@Param("et") T var1); int update(@Param("et") T var1, @Param("ew") Wrapper<T> var2); T selectById(Serializable var1); List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> var1); List<T> selectByMap(@Param("cm") Map<String, Object> var1); T selectOne(@Param("ew") Wrapper<T> var1); Integer selectCount(@Param("ew") Wrapper<T> var1); List<T> selectList(@Param("ew") Wrapper<T> var1); List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> var1); List<Object> selectObjs(@Param("ew") Wrapper<T> var1); IPage<T> selectPage(IPage<T> var1, @Param("ew") Wrapper<T> var2); IPage<Map<String, Object>> selectMapsPage(IPage<T> var1, @Param("ew") Wrapper<T> var2); }
配置类
- 需要开启对mapper的扫描
@Configuration @MapperScan("ltd.dujiabao.mybatisplus.mapper") public class Config {}
主类
- 没什么要修改的,开启就好
@SpringBootApplication public class MybatisplusApplication { public static void main(String[] args) { SpringApplication.run(MybatisplusApplication.class, args); } }
测试
- 在测试类中简单的测试一下查询语句
@SpringBootTest public class MybatisplusApplicationTests { @Autowired private UserMapper userMapper; @Test public void testSelectList() { List<User> users = userMapper.selectList(null); System.out.println(users); } }
配置日志
- 为了看到动态合成的SQL语句,可以加一个日志配置
# mybatis日志 mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl - 至此,完成了一个最简单的MP配置
CURD接口
- 以上,已经列出了
BaseMapper的所有方法,下面就简单地测试一下。
insert
@Test
public void testInsert() {
User user = new User();
user.setName("5354");
user.setAge(12);
user.setEmail("6545265@qq.com");
userMapper.insert(user);
}
- 以上并没有插入主键
id值,但是MP会自动帮我们插入一个19位的随机id值。这就可以谈到插入主键的几种策略了。

主键策略
- 参考文档
- MP默认使用
snowflake算法,在MP中被称为ID_WORKER
数据库自增长序列或字段
- 也就是在数据库中设置字段为主键并且
AUTO_INCREMENT
优点
- 简单,代码方便,性能可以接受。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点
- 不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
- 在性能达不到要求的情况下,比较难于扩展。
- 如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
- 分表分库的时候会有麻烦。
优化方案:
- 针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。
- 比如:Master1 生成的是1,4,7,10;Master2生成的是2,5,8,11;Master3生成的是 3,6,9,12。
- 这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
UUID
- 常见的方式。可以利用数据库也可以利用程序生成,一般来说全球唯一。
优点
- 简单,代码方便。
- 生成ID性能非常好,基本不会有性能问题。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点
- 没有排序,无法保证趋势递增。
- UUID往往是使用字符串存储,查询的效率比较低。
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
- 传输数据量大
- 不可读
优化方案
- 为了解决UUID不可读,可以使用UUID to Int64的方法
- 为了解决UUID无序的问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。
Redis 生成ID
- 当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。
- 可以用Redis的原子操作 INCR和INCRBY来实现。
- 可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
- A:1,6,11,16,21
- B:2,7,12,17,22
- C:3,8,13,18,23
- D:4,9,14,19,24
- E:5,10,15,20,25
优点
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。
Twitter的snowflake算法
- snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。
- 其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
- snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点
- 不依赖于数据库,灵活方便,且性能优于数据库。
- ID按照时间在单机上是递增的。
缺点
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况
在MP中配置主键策略
- 要想主键自增需要配置如下主键策略
- 需要在创建数据表的时候设置主键自增
- 实体字段中配置
@TableId(type = IdType.AUTO)
@TableId(type = IdType.NONE) private Long id; - 以下,介绍MP 内部的所有可选的策略
public enum IdType { AUTO(0), // 自动递增,也就是在sql语句中不设置,让数据库自己递增 NONE(1), // 默认为ID_WORKER INPUT(2), // 用户必须自己输入一个id,否则就报异常 ID_WORKER(3), // snowflake算法,生成long类型 UUID(4), // UUID策略,id必须为str类型 ID_WORKER_STR(5); // snowflake算法,生成str类型 private int key; private IdType(int key) { this.key = key; } public int getKey() { return this.key; } } - 要想直接设置所有java bean的id配置策略,也可以直接在配置文件中设置
#全局设置主键生成策略 mybatis-plus.global-config.db-config.id-type=auto
update
根据Id更新操作
@Test
public void testUpdateById() {
User user = new User();
user.setId(2L);
user.setName("gsfgfgs");
int row = userMapper.updateById(user);
System.out.println(row);
}

- 应该是通过动态SQL生成的,user里面有什么值,就设置哪些。
自动填充
- 项目中经常会遇到一些数据,每次都使用相同的方式填充,例如记录的创建时间,更新时间等。
- 如果需要每次更新都自己设置,就很麻烦。MP提供了一个方便的解决方案。可以在每次插入数据、修改数据的时候,自动填充这些值。
- 以下为实现步骤
添加注解
- 添加
@TableField注解,填写fill属性。@Data public class User { ...... @TableField(fill = FieldFill.INSERT) private Date createTime; //@TableField(fill = FieldFill.UPDATE) @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime; } fill属性有以下几个选项,表示属性在什么时候需要被填充。public enum FieldFill { DEFAULT, // 默认,应该没有什么用吧 INSERT, // 插入的时候,需要被填充 UPDATE, // 更新的时候需要被填充 INSERT_UPDATE; // 插入、更新的时候都需要被填充 private FieldFill() { } }
实现 MetaObjectHandler
- 写一个处理方法,即声明在插入、更新的时候,需要在对象中填充的内容。
MetaObject应该就是我们在调用mapper方法时,传入的对象。调用setFieldValByName方法,设置该对象的指定字段的值即可。@Component public class MyMetaObjectHandler implements MetaObjectHandler { private static final Logger LOGGER = LoggerFactory.getLogger(MyMetaObjectHandler.class); @Override public void insertFill(MetaObject metaObject) { LOGGER.info("start insert fill ...."); this.setFieldValByName("createTime", new Date(), metaObject); this.setFieldValByName("updateTime", new Date(), metaObject); } @Override public void updateFill(MetaObject metaObject) { LOGGER.info("start update fill ...."); this.setFieldValByName("updateTime", new Date(), metaObject); } }
效果
@Test
public void testUpdate() {
UpdateWrapper<User> wrapper = new UpdateWrapper<>();
wrapper.gt("id", 2);
User user = new User();
user.setAge(20);
int row = userMapper.update(user, wrapper);
System.out.println(row);
}

- 应该是利用aop的方法,在调用该方法之后,还额外添加了一些操作。
乐观锁
- 数据库有可能面对并发的情况,两个人同时修改同一个数据库的同一条数据。
- 当要更新一条记录的时候,希望这条记录没有被别人更新,也就是说实现线程安全的数据更新。(就是,不会覆盖别人刚修改好的数据)
- 可以使用乐观锁实现。
步骤
- 取出记录时,获取当前version
- 更新时,带上这个version
- 执行更新时, set version = newVersion where version = oldVersion
- 如果version不对,就更新失败
添加注解
- 在
version字段中,添加一个注解Version。(为了保证版本有初值,也可以添加一个填充的注解)@Version @TableField(fill = FieldFill.INSERT) private Integer version; - 特别说明
- 支持的数据类型只有 int,Integer,long,Long,Date,Timestamp,LocalDateTime
- 整数类型下
newVersion = oldVersion + 1 newVersion会回写到 entity 中- 仅支持
updateById(id)与update(entity, wrapper)方法 - 在
update(entity, wrapper)方法下, wrapper 不能复用
注册 optimisticLockerInterceptor 组件
- 在配置类中注册
@Bean public OptimisticLockerInterceptor optimisticLockerInterceptor() { return new OptimisticLockerInterceptor(); }
测试
- 需要先查询,再修改
@Test public void testLock() { User user = userMapper.selectById(1); user.setName("lock"); userMapper.updateById(user); }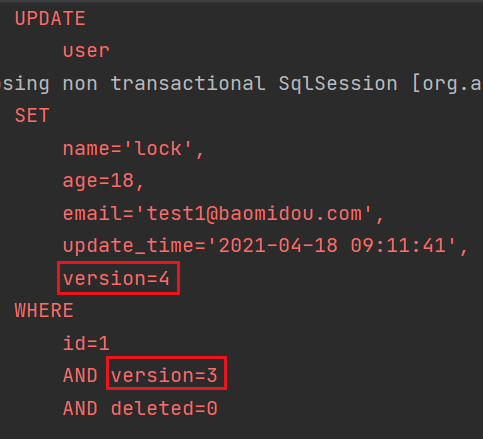
select
根据id查询记录
@Test
public void testSelectById(){
User user = userMapper.selectById(1L);
System.out.println(user);
}
通过多个id批量查询
@Test
public void testSelectBatchIds(){
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
users.forEach(System.out::println);
}

简单的条件查询
@Test
public void testSelectByMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("name", "Jack");
List<User> users = userMapper.selectByMap(map);
System.out.println(users);
}

- map中的key对应的是数据库中的列名。例如数据库
user_id,实体类是userId,这时map的key需要填写user_id - key作为筛选条件的字段名,value为值。
分页
- MyBatis Plus自带分页插件,只要简单的配置即可实现分页功能
配置 paginationInterceptor
/**
* 分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
测试
@Test
public void testSelectPage() {
Page<User> page = new Page<>(1, 3);
userMapper.selectPage(page, null);
page.getRecords().forEach(System.out::println);
System.out.println("current: " + page.getCurrent()); // 当前页码
System.out.println("size: " + page.getSize()); // 每页数据个数
System.out.println("pages: " + page.getPages()); // 页数
System.out.println("total: " + page.getTotal()); // 总共的数据个数
System.out.println("hasNext: " + page.hasNext()); // 是否还有下一条
}
delete
根据id删除记录
@Test
public void testDeleteById(){
int result = userMapper.deleteById(8L);
System.out.println(result);
}
批量删除
@Test
public void testDeleteBatchIds() {
int result = userMapper.deleteBatchIds(Arrays.asList(8, 9, 10));
System.out.println(result);
}
简单的条件查询删除
@Test
public void testDeleteByMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("name", "Helen");
map.put("age", 18);
int result = userMapper.deleteByMap(map);
System.out.println(result);
}
逻辑删除
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除数据
- 逻辑删除:假删除,将对应数据中代表是否被删除字段状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
- 默认都是物理删除,删除了该数据就不存在了
- 如果想将修改成逻辑删除也是可以的
实体类添加deleted 字段
@TableLogic表示这是一个逻辑删除字段。添加一个填充字段,保证初始值。@TableLogic @TableField(fill = FieldFill.INSERT) private Integer deleted;
配置文件
- 默认就是这样,被删除了为1,没被删除为0,默认都是0,以下配置可以不写,除非要修改。
mybatis-plus.global-config.db-config.logic-delete-value=1 mybatis-plus.global-config.db-config.logic-not-delete-value=0
配置 sqlInjector
@Bean
public ISqlInjector sqlInjector() {
return new LogicSqlInjector();
}
测试
- 与普通的删除方法一样,只是现在发送的语句,不再是
DELETE FROM,而是UPDATE user SET deleted = 1 ...@Test public void testDeleteById() { int row = userMapper.deleteById(1382983877340983298L); System.out.println(row); }
- 如今,CRUD的时候,都需要添加一个判断条件,
where deleted = 0
性能分析
- 性能分析拦截器,用于输出每条 SQL 语句及其执行时间
- SQL 性能执行分析,开发环境使用,超过指定时间,停止运行。有助于发现问题
配置插件
/**
* SQL 执行性能分析插件
* 开发环境使用,线上不推荐。 maxTime 指的是 sql 最大执行时长
*/
@Bean
@Profile({"dev","test"})// 设置 dev test 环境开启
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();
performanceInterceptor.setMaxTime(100);//ms,超过此处设置的ms则sql不执行
performanceInterceptor.setFormat(true);
return performanceInterceptor;
}
- 参数:
maxTime: SQL 执行最大时长,超过自动停止运行,有助于发现问题。 - 参数:
format: SQL是否格式化,默认false @Profile({"dev","test"})用于指定组件使用的环境,目前指定只在开发、测试环境运行。真正工作的环境为prod- 而Spring也可以设定目前所处的环境
# 环境设置:dev、test、prod spring.profiles.active=dev
条件构造器
- 通过
Wrapper封装过滤条件,MP通过封装的过滤条件,动态生成对应的sql语句
ge、gt、le、lt、isNull、isNotNull
- 分别是大于等于、大于、小于等于、小于、为空、不为空
@Test public void testDelete() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper .isNull("name") .ge("age", 12) .isNotNull("email"); int result = userMapper.delete(queryWrapper); System.out.println("delete return count = " + result); }SQL:UPDATE user SET deleted=1 WHERE deleted=0 AND name IS NULL AND age >= ? AND email IS NOT NULL
eq、ne
- 等于、不等于
@Test public void testSelectOne() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("name", "Tom"); User user = userMapper.selectOne(queryWrapper); System.out.println(user); }SELECT id,name,age,email,create_time,update_time,deleted,version FROM user WHERE deleted=0 AND name = ?
between、notBetween
- 在…之间、不在…之间
@Test public void testSelectCount() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.between("age", 20, 30); Integer count = userMapper.selectCount(queryWrapper); System.out.println(count); }SELECT COUNT(1) FROM user WHERE deleted=0 AND age BETWEEN ? AND ?
allEq
- 全等于,输入一个map,表示map里面的键值对都需要相等
@Test public void testSelectList() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); Map<String, Object> map = new HashMap<>(); map.put("id", 2); map.put("name", "Jack"); map.put("age", 20); queryWrapper.allEq(map); List<User> users = userMapper.selectList(queryWrapper); users.forEach(System.out::println); }SELECT id,name,age,email,create_time,update_time,deleted,version FROM user WHERE deleted=0 AND name = ? AND id = ? AND age = ?
like、notLike、likeLeft、likeRight
- 模糊匹配、模糊匹配取反、左边模糊匹配、右边模糊匹配
@Test public void testSelectMaps() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper .notLike("name", "e") .likeRight("email", "t"); List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);//返回值是Map列表 maps.forEach(System.out::println); }SELECT id, name, age, email, create_time, update_time, version, deleted FROM user WHERE deleted=0 AND name NOT LIKE ‘%e%’ AND email LIKE ‘t%’
in、notIn、inSql、notinSql、exists、notExists
- 在区间内、不在区间内、在sql语句结果中、不在sql语句结果中、存在、不存在
notIn("age",{1,2,3})—>age not in (1,2,3)notIn("age", 1, 2, 3)—>age not in (1,2,3)- inSql、notinSql 可以实现子查询
inSql("age", "1,2,3,4,5,6")—>age in (1,2,3,4,5,6)inSql("id", "select id from table where id < 3")—>id in (select id from table where id < 3)
or、and
- 多条件之间,默认使用
and连接,而如果需要可以选择通过or连接@Test public void testUpdate1() { //修改值 User user = new User(); user.setAge(99); user.setName("Andy"); //修改条件 UpdateWrapper<User> userUpdateWrapper = new UpdateWrapper<>(); userUpdateWrapper .like("name", "h") .or() .between("age", 20, 30); int result = userMapper.update(user, userUpdateWrapper); System.out.println(result); }UPDATE user SET name=?, age=?, update_time=? WHERE deleted=0 AND name LIKE ? OR age BETWEEN ? AND ?
嵌套or、嵌套and
- 这里使用了lambda表达式,or中的表达式最后翻译成sql时会被加上圆括号
@Test public void testUpdate2() { //修改值 User user = new User(); user.setAge(99); user.setName("Andy"); //修改条件 UpdateWrapper<User> userUpdateWrapper = new UpdateWrapper<>(); userUpdateWrapper .like("name", "h") .or(i -> i.eq("name", "李白").ne("age", 20)); // OR ( name = ? AND age <> ? ) int result = userMapper.update(user, userUpdateWrapper); System.out.println(result); }UPDATE user SET name=?, age=?, update_time=?
WHERE deleted=0 AND name LIKE ?
OR ( name = ? AND age <> ? )
orderBy、orderByDesc、orderByAsc
- 排序
@Test public void testSelectListOrderBy() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.orderByDesc("id"); List<User> users = userMapper.selectList(queryWrapper); users.forEach(System.out::println); }SELECT id,name,age,email,create_time,update_time,deleted,version FROM user WHERE deleted=0 ORDER BY id DESC
last
- 直接拼接到 sql 的最后
- 注意:只能调用一次,多次调用以最后一次为准 有sql注入的风险,请谨慎使用
@Test public void testSelectListLast() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.last("limit 1"); List<User> users = userMapper.selectList(queryWrapper); users.forEach(System.out::println); }SELECT id,name,age,email,create_time,update_time,deleted,version FROM user WHERE deleted=0 limit 1
指定要查询的列
@Test
public void testSelectListColumn() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "name", "age");
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
}
set、setSql
- 最终的sql会合并
user.setAge(),以及userUpdateWrapper.set()和setSql()中 的字段@Test public void testUpdateSet() { //修改值 User user = new User(); user.setAge(99); //修改条件 UpdateWrapper<User> userUpdateWrapper = new UpdateWrapper<>(); userUpdateWrapper .like("name", "h") .set("name", "老李头")//除了可以查询还可以使用set设置修改的字段 .setSql(" email = '123@qq.com'");//可以有子查询 int result = userMapper.update(user, userUpdateWrapper); }UPDATE user SET age=?, update_time=?, name=?, email = ‘123@qq.com’ WHERE deleted=0 AND name LIKE ?
最后
以上就是老迟到睫毛膏最近收集整理的关于MyBatis Plus的使用入门CURD接口selectdelete性能分析条件构造器的全部内容,更多相关MyBatis内容请搜索靠谱客的其他文章。








发表评论 取消回复