1.bs4数据解析
数据解析的原理:1.标签定位 2.提取标签、标签属性中存储的数据值
bs4数据解析的原理:
1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
环境安装
pip install bs4 pip install lxml
或者PyCharm中的file—>Settings—>Project Interpreter—>点击【+】—>分别输入bs4和lxml
或者在anaconda prompt中直接输入pip install bs4和pip install lxml
实例化对象
1.将本地的html文档中的数据加载到该对象中
fp=open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
2.将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
bs4属性和方法
fp=open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
1.soup.tagName:返回的是文档中第一次出现的tagName对应的标签
2.soup.find():
find('tagName'):等同于soup.div 如soup.find('div')
属性定位:soup.find('div',class_='song') #这里的是class_ 不是class,表示的是div属性中的class_属性的div属性 如soup.find('div',class_='song')
3.soup.find_all('tagName'):返回符合要求的所有标签(列表)如:soup.find_all('a')
4.select: select('某种选择器(id,class,标签...选择器)') 返回的是一个列表
层级选择器:
soup.select('.tang > ul > li > a') #其中 >表示的是一个层级
soup.select('.tang > ur a') #空格表示的多个层级
获取标签之间的文本数据
fp=open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
# 获取标签之间的文本数据
soup.标签名称.text/string/get_text()
-text/get_text():获取该标签中所有的文本内容
-string:只可以获取该标签下面直系的文本内容
如:soup.find('div',class_='song').text
soup.find('div',class_='song').string
以上运行结果完全不同
获取标签中属性值
fp=open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
soup.标签名称['属性名称']
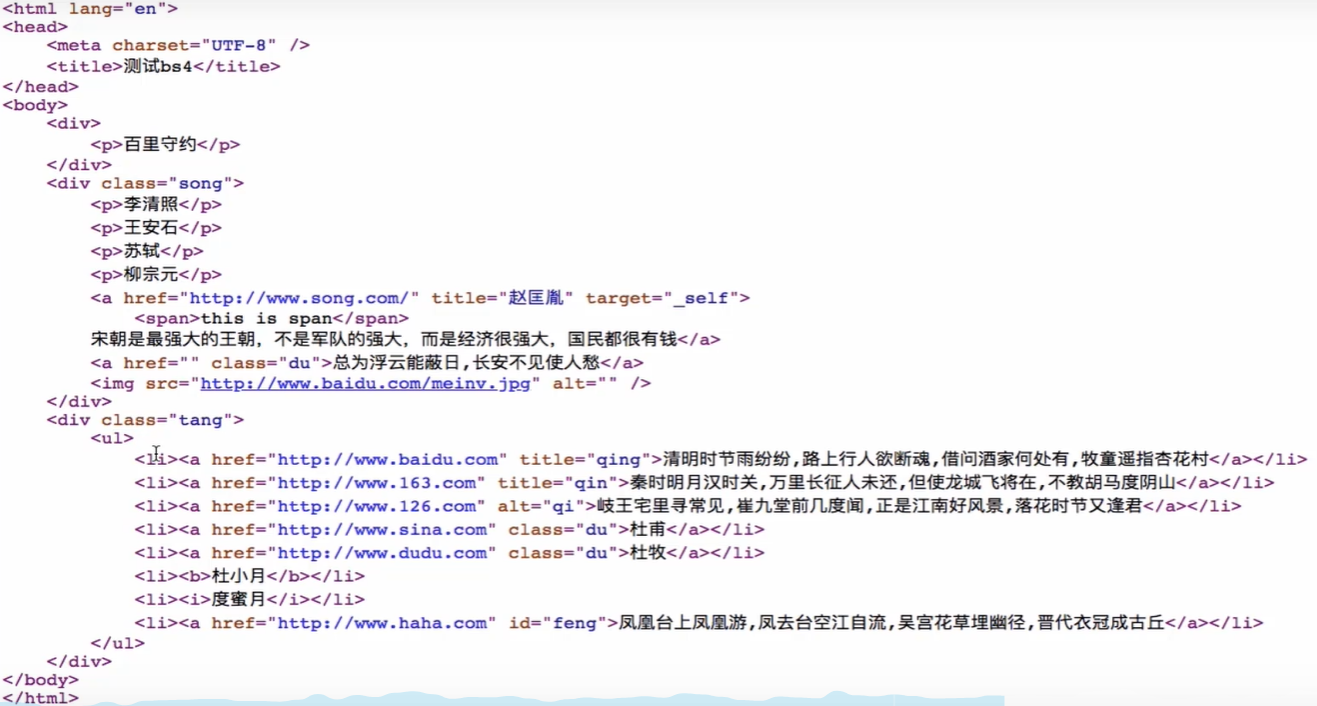
备注:因没有合适的HTML文本,因此本文均没有实战演示,待后期补上
最后
以上就是快乐夕阳最近收集整理的关于python网络爬虫(第五章:bs4之数据解析)1.bs4数据解析环境安装实例化对象bs4属性和方法的全部内容,更多相关python网络爬虫(第五章:bs4之数据解析)1内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复