
曾有人问我,为什么要去干解析 dex 文件这种麻烦的事?
我想说的是写个解析脚本不是为了模仿着 apktools 造轮子,而是在解析过程中寻找逆向的道路,方法会变,工具会变,但一切都建立在 dex 上的安卓不会变
一、什么是 Dex 文件
dex 文件是 Android 平台上可执行文件的一种文件类型。它的文件格式可以下面这张图概括:
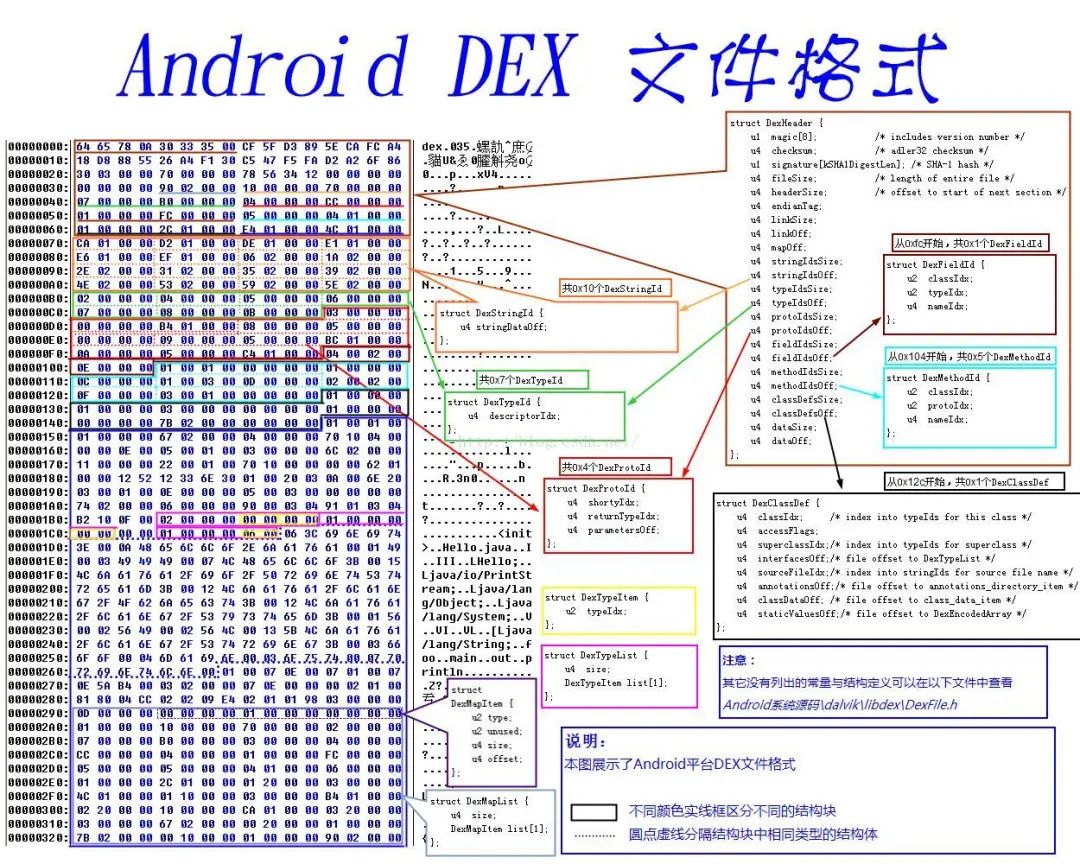
二、文件头解析
1、文件头简介
dex 文件头一般固定为 0x70 个字节大小,包含标志、版本号、校验码、sha-1 签名以及其他一些方法、类的数量和偏移地址等信息。如下图所示:
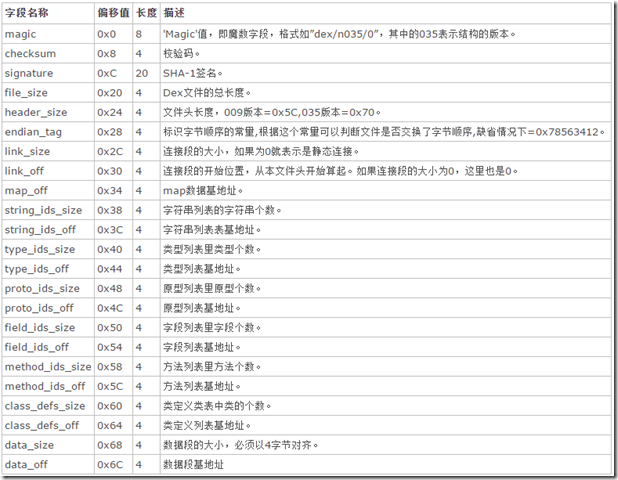
2、dex 文件头各字段解析
dex 文件头包含以下各个字段:
magic: 包含了 dex 文件标识符以及版本,从 0x00 开始,长度为 8 个字节
checksum: dex 文件校验码,偏移量为: 0x08,长度为 4 个字节。
signature: dex sha-1 签名,偏移量为 0x0c, 长度为 20 个字节
file_szie: dex 文件大小,偏移量为 0x20,长度为 4 个字节
header_size: dex 文件头大小,偏移量为 0x24,长度为 4 个字节,一般为 0x70
endian_tag: dex 文件判断字节序是否交换,偏移量为 0x28,长度为 4 个字节,一般情况下为 0x78563412
link_size: dex 文件链接段大小,为 0 则表示为静态链接,偏移量为 0x2c,长度为 4 个字节
link_off: dex 文件链接段偏移位置,偏移量为 0x30,长度为 4 个字节
map_off: dex 文件中 map 数据段偏移位置,偏移位置为 0x34,长度为 4 个字节
string_ids_size: dex 文件包含的字符串数量,偏移量为 0x38,长度为 4 个字节
string_ids_off: dex 文件字符串开始偏移位置,偏移量为 0x3c,长度为 4 个字节
type_ids_size: dex 文件类数量,偏移量为 0x40,长度为 4 个字节
type_ids_off: dex 文件类偏移位置,偏移量为 0x44,长度为 4 个字节
photo_ids_size: dex 文件中方法原型数量,偏移量为 0x48,长度为 4 个字节
photo_ids_off: dex 文件中方法原型偏移位置,偏移量为 0x4c,长度为 4 个字节
field_ids_size: dex 文件中字段数量,偏移量为 0x50,长度为 4 个字节
field_ids_off: dex 文件中字段偏移位置,偏移量为 0x54,长度为 4 个字节
method_ids_size: dex 文件中方法数量,偏移量为 0x58,长度为 4 个字节
method_ids_off: dex 文件中方法偏移位置,偏移量为 0x5c,长度为 4 个字节
class_defs_size: dex 文件中类定义数量,偏移量为 0x60,长度为 4 个字节
class_defs_off: dex 文件中类定义偏移位置,偏移量为 0x64,长度为 4 个字节
data_size: dex 数据段大小,偏移量为 0x68,长度为 4 个字节
data_off: dex 数据段偏移位置,偏移量为 0x6c,长度为 4 个字节
3、dex 文件头代码解析示例 (python)
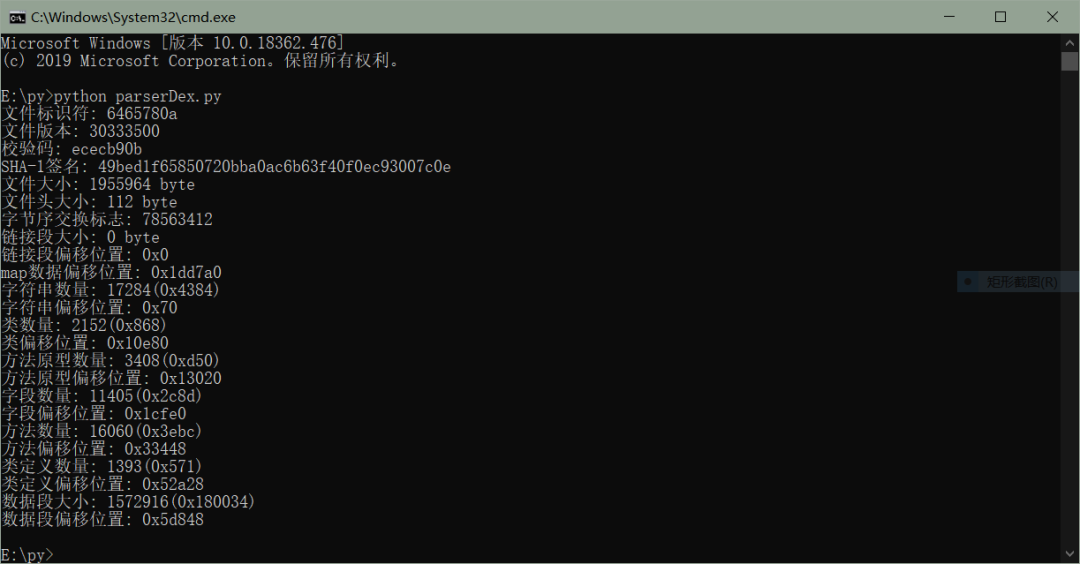
dex 使用 open 函数以二进制打开文件,然后使用 seek 函数移动文件指针,例如 magic 就是f.seek(0x00),然后读取相应信息的字节数即可,例如读取版本号f.seek(0x04) f.read(4),然后做相应打印操作就行,dex 文件头较简单,不涉及编码等,所以解析起来感觉脑子都不用带。。。。。具体代码可以看下面或者 github,下面附上代码运行图:
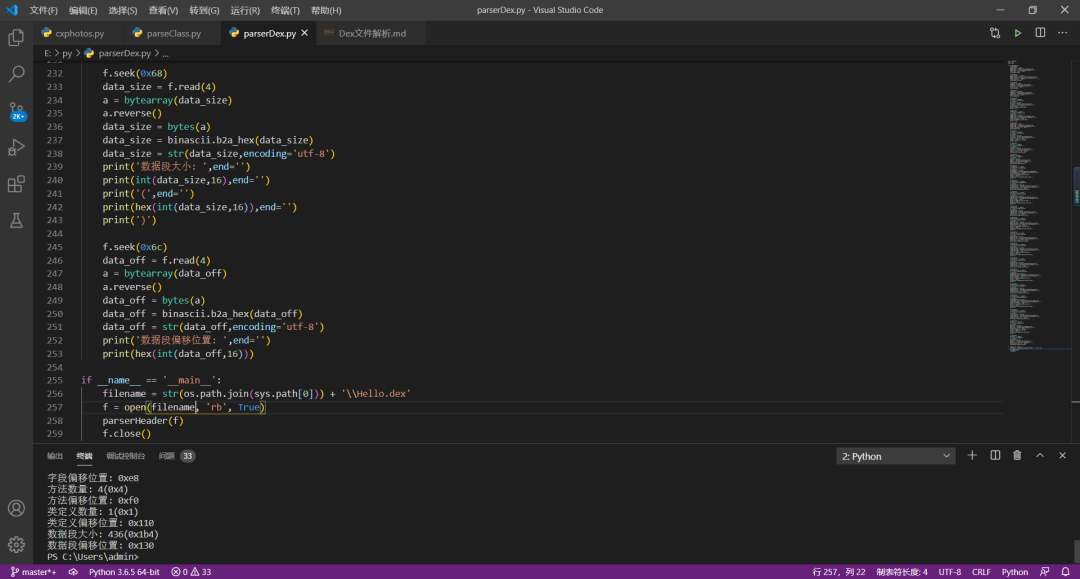
4、dex 文件头解析实现代码(python 实现)
ps:只截取关键代码,完整代码请参考文末 github 链接或网盘链接
三、checksum (校验和)解析
1、checksum 介绍
checksum(校验和)是 DEX 位于文件头部的一个信息,用来判断 DEX 文件是否损坏或者被篡改,它位于头部的0x08偏移地址处,占用 4 个字节,采用小端序存储。
在 DEX 文件中,采用Adler-32校验算法计算出校验和,将 DEX 文件从0x0C处开始读取到文件结束,将读取到的字节数组使用Adler-32 校验算法计算出结果即是校验和即 checksum 字段!!!
2、Adler-32 算法
Adler-32算法如下步骤实现:
a、定义两个变量varA、varB,其中varA初始化为1,varB初始化为0。
b、 读取字节数组的一个字节(假设该字节变量名为byte),计算varA = (varA + byte) mod 65521,然后可以计算出varB = (varA + varB) mod 65521。
c. 重复步骤,直到字节数组全部读取完毕,得到最终varA、varB两个变量的结果。
d. 根据第三步得到的varA、varB两个变量,可得到最终校验和checksum =(varB << 16)+ varA。
下面是官方 WIKI 给的例子:
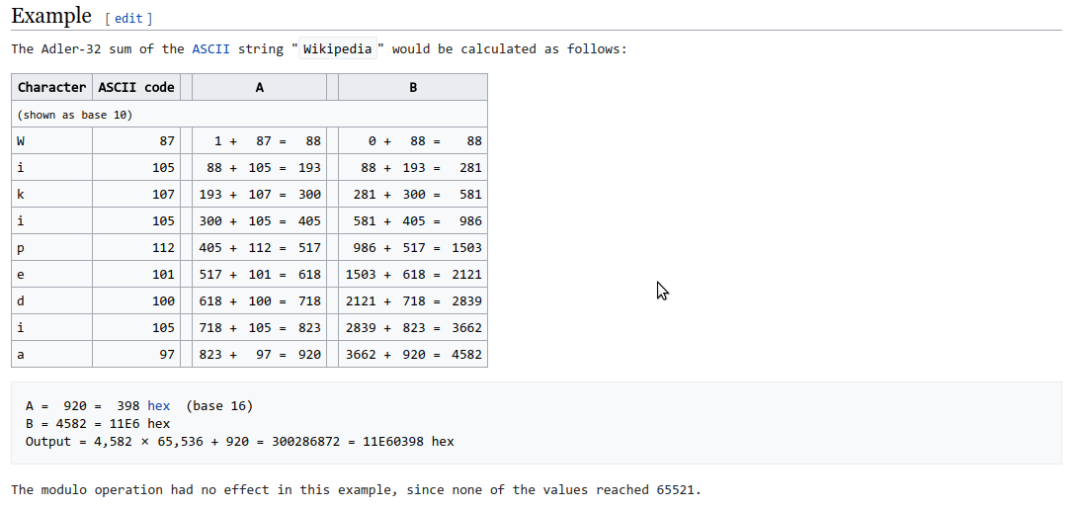
3、python 实现 Adler-32 算法
先给出 Dex 文件头部信息以及代码跑出的结果
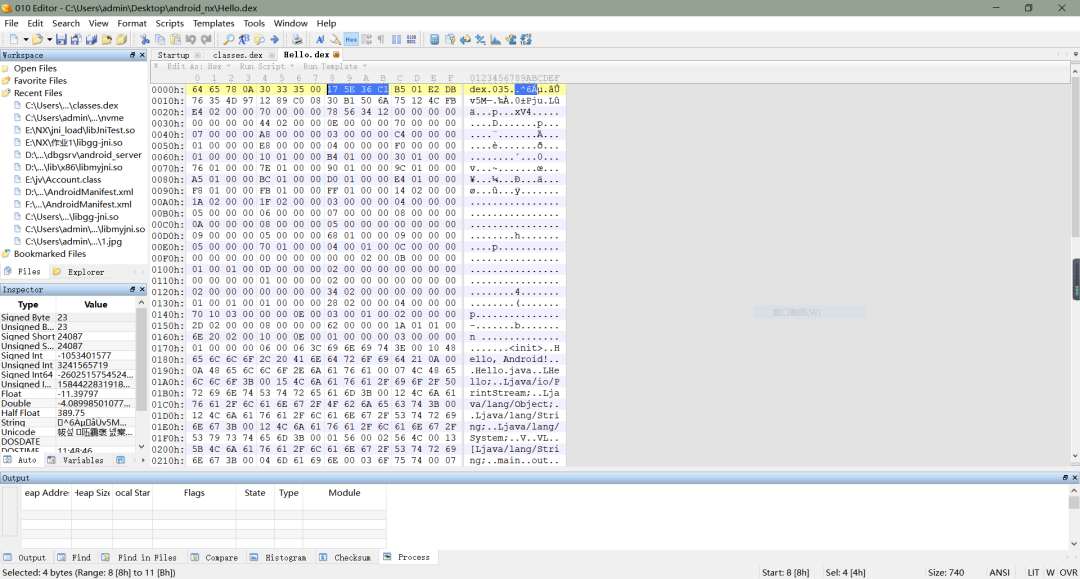
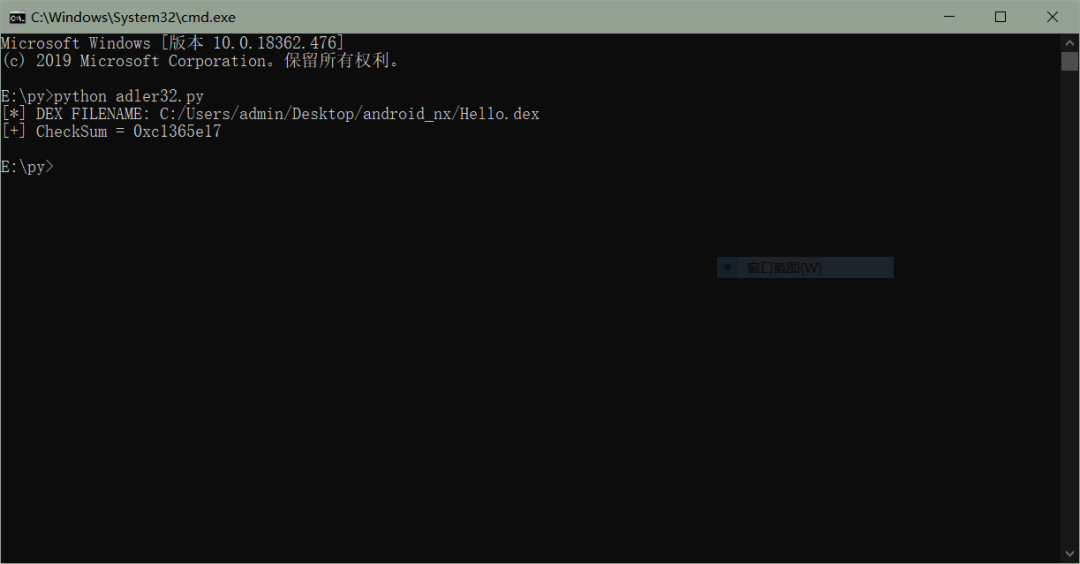
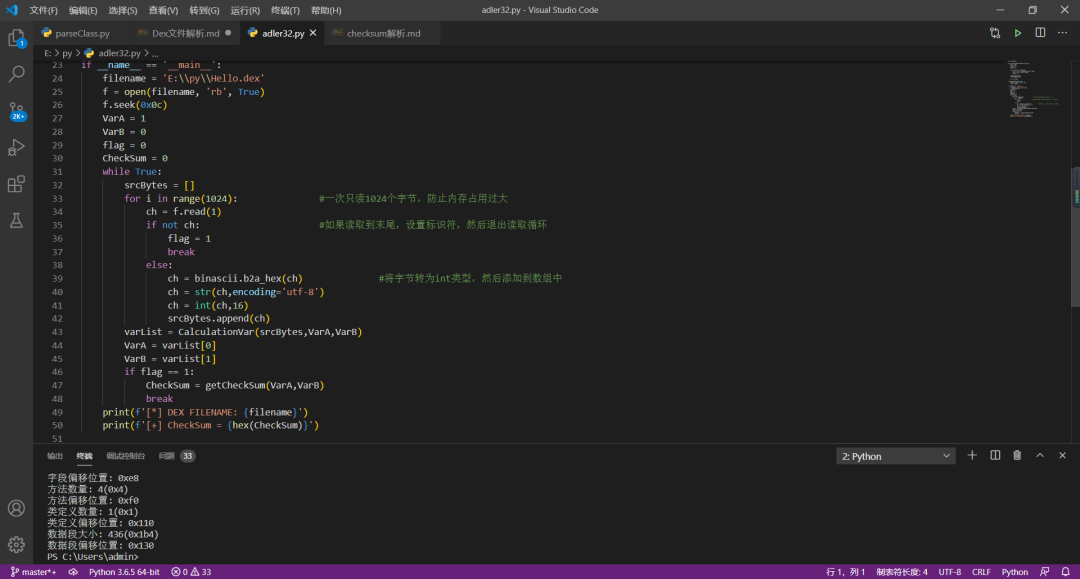
python 代码实现如下(python 3.6 版本):
四、字符串解析
1、DEX 文件中的字符串
a、DEX 文件大致上可以粗略的分为 3 个部分:文件头、索引区以及数据区。而文件头一般来说占了整个 DEX 文件 0x70 个字节(还不了解 DEX 文件头的可以看一下我前面两篇文章),在文件头中,关于字符串的相关信息一共有 8 个字节,分别位于 0x38(4 Bytes) 和 0x3c(4 Bytes) 处,前者说明了该 DEX 文件包含了多少个字符串,后者则是字符串索引区的起始地址,但是需要注意的是,DEX 存储是以小端序存储的(通俗一点的说就是从后往前读),如下所示:
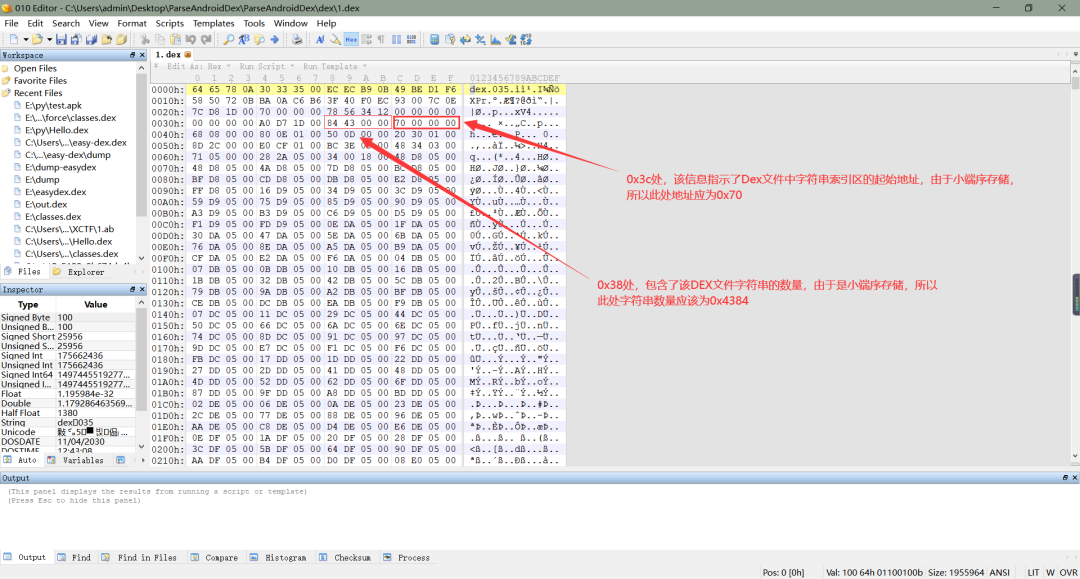
b、前面我们通过文件头知道了字符串数量和字符串索引区起始地址等信息,接下来我们就来具体看一下字符串索引区。字符串索引区存储的是字符串真正存储在数据区的偏移地址,以 4 个字节为一组,表示一个字符串在数据区的偏移地址,所以索引区一个占字符串数量 X 4个字节那么多,同样的,索引区也采用的是小端序存储,所以我们在读取地址时,需要与小端序的方式来读取真正的地址,如下所示:
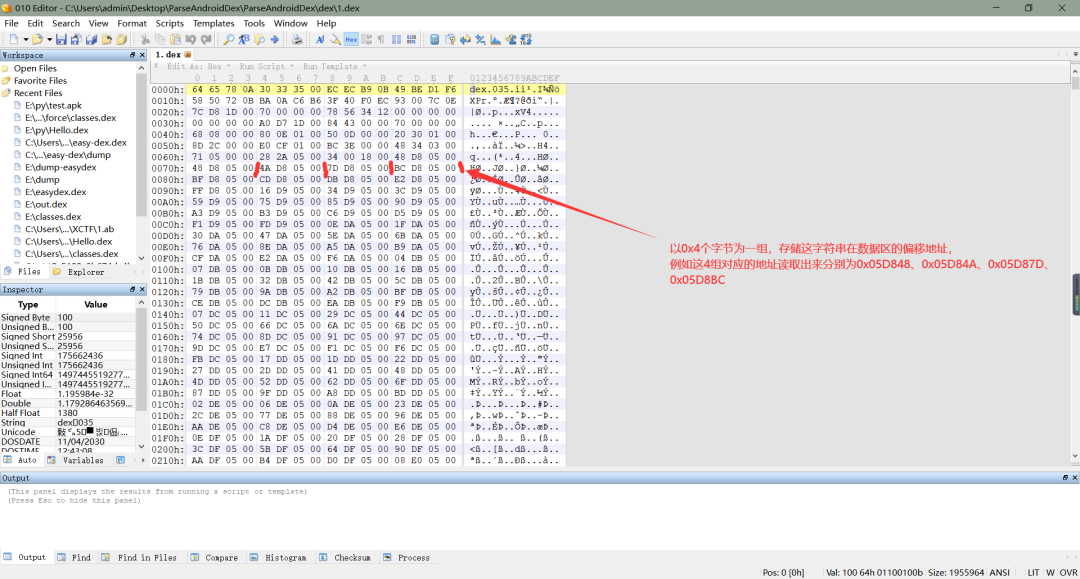
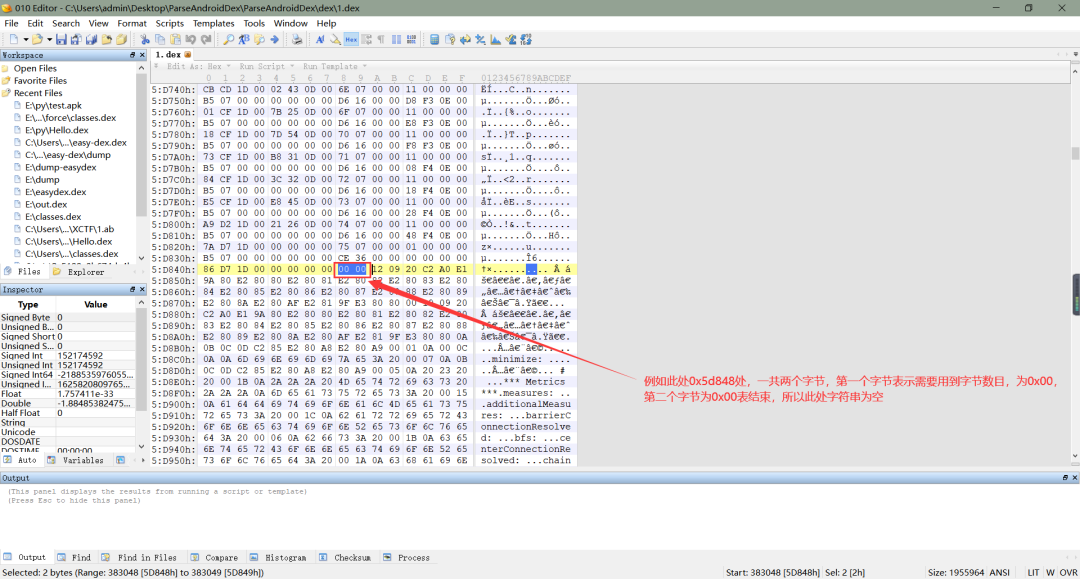
c、从上面我们已经知道了如何找到字符串在数据区的偏移地址,接下来我们需要做的就是解析这些数据区的字节。通过偏移地址我们可以在数据区找到代表字符串的这些字节,在 DEX 文件中,字符串是通过MUTF-8编码而成的(至于 mutf-8 是什么编码,我会将一些相关博客链接贴在文末),在MUTF-8编码中,第一个字节代表了这个字符串所需要用到的字节数目(不包括最后一个代表终结的字节),最后一个字节为0x00,表示这个字符串到此结束,跟 c 语言有点类似,中间部分才是一个字符串的具体内容,如下所示:(PS:mutf-8第一个字节还经过uleb128编码,所以简单的进行进制换算得到的字节数很多人奇怪对不上,由于比较复杂,就不过多解释了,想进一步了解更深的可以去看一下安卓源码中对 DEX 文件解析出字符串这一部分)
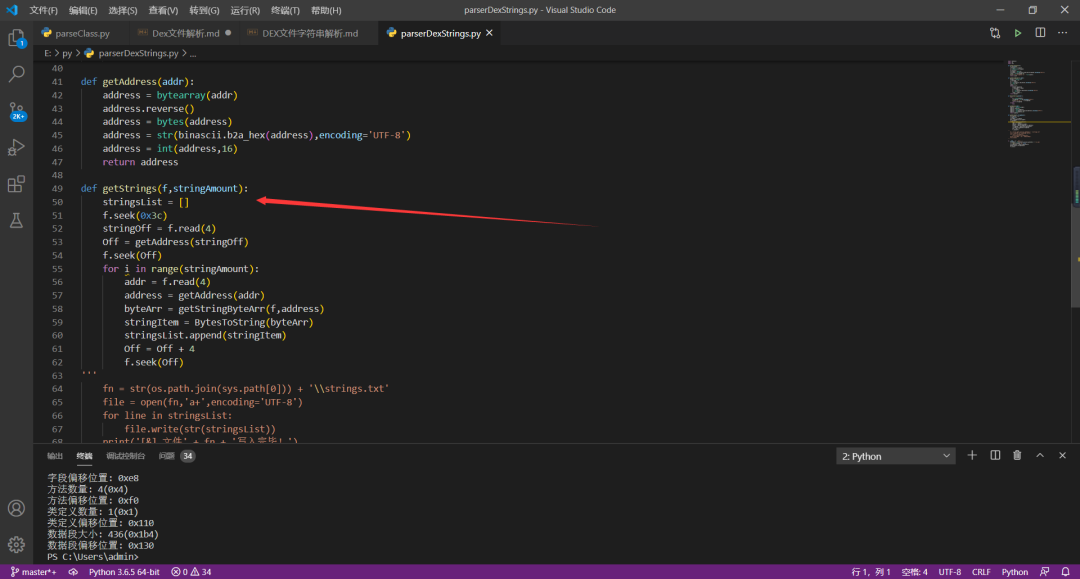
2、解析代码:
PS:我电脑运行环境-- python3.6
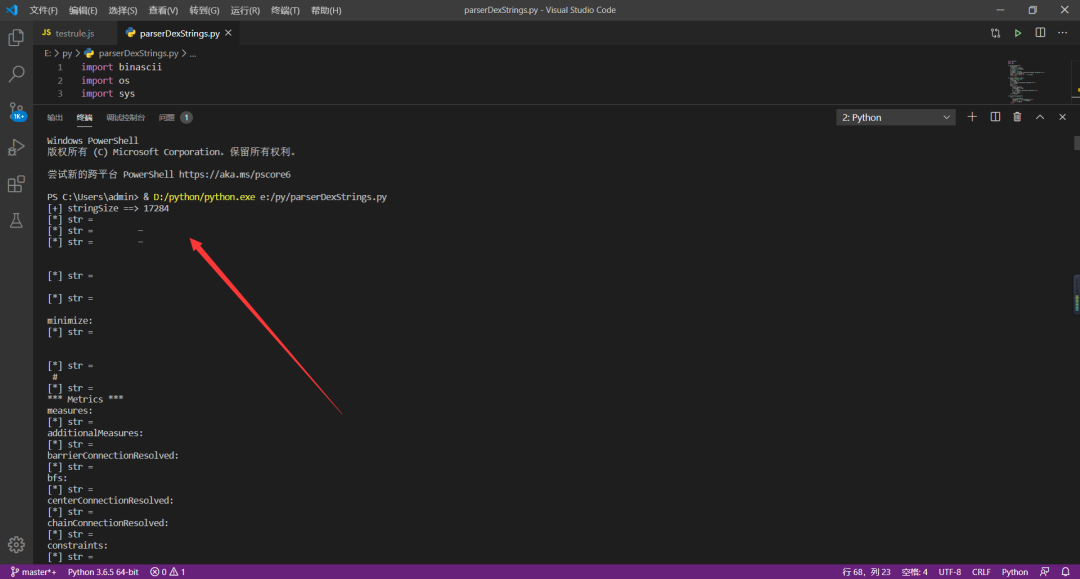
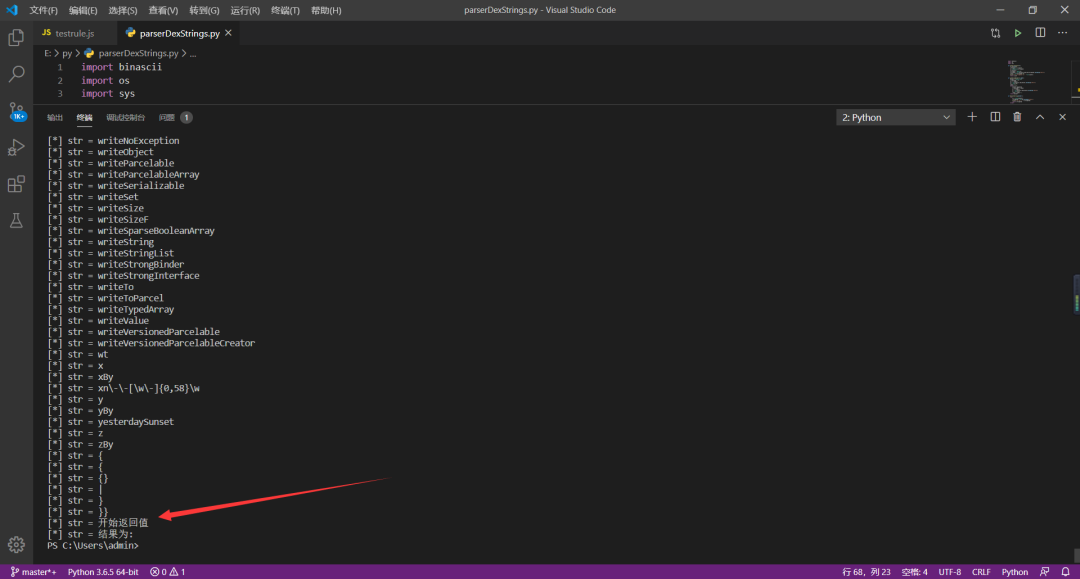
代码关键截图如下:
运行截图:
五、类的类型解析
1、DEX 文件中的类的类型
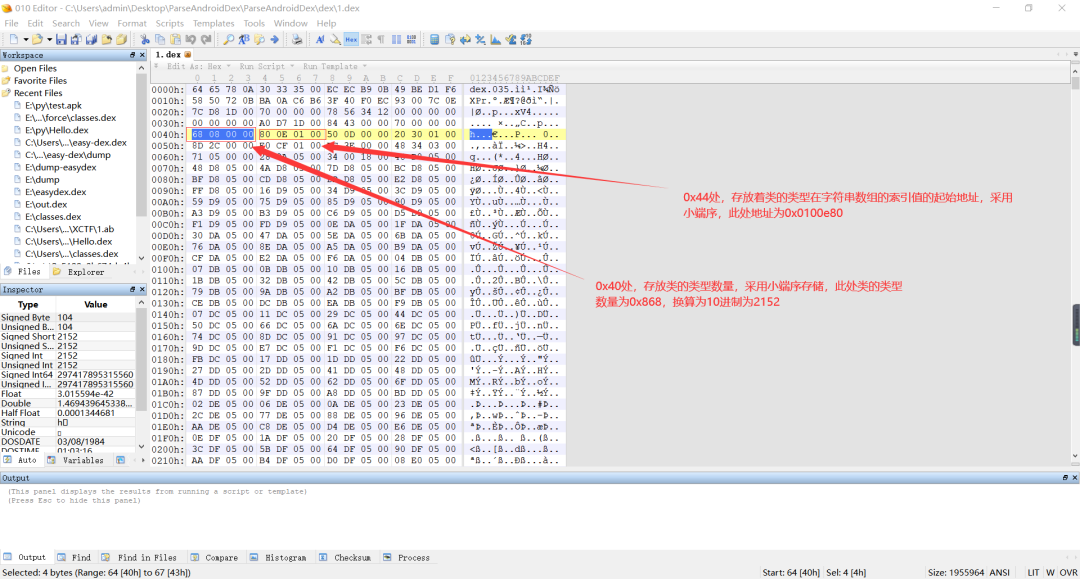
a、Dex 文件中关于类的类型需要知道字符串是怎么解析的,如果不知道的,可以看一下前面部分。好了,切入正题,关于类的类型,就是一个对象的所属的类(大概这么理解吧。。。),例如在 java 中一个字符串,它的类型就是java/lang/String。在 Dex 文件头中,跟类的类型有关的一共有八个字节,分别是位于0x40处占四个字节表示类的类型的数量和位于0x44处占四个字节表示类的类型索引值的起始偏移地址,如下所示:
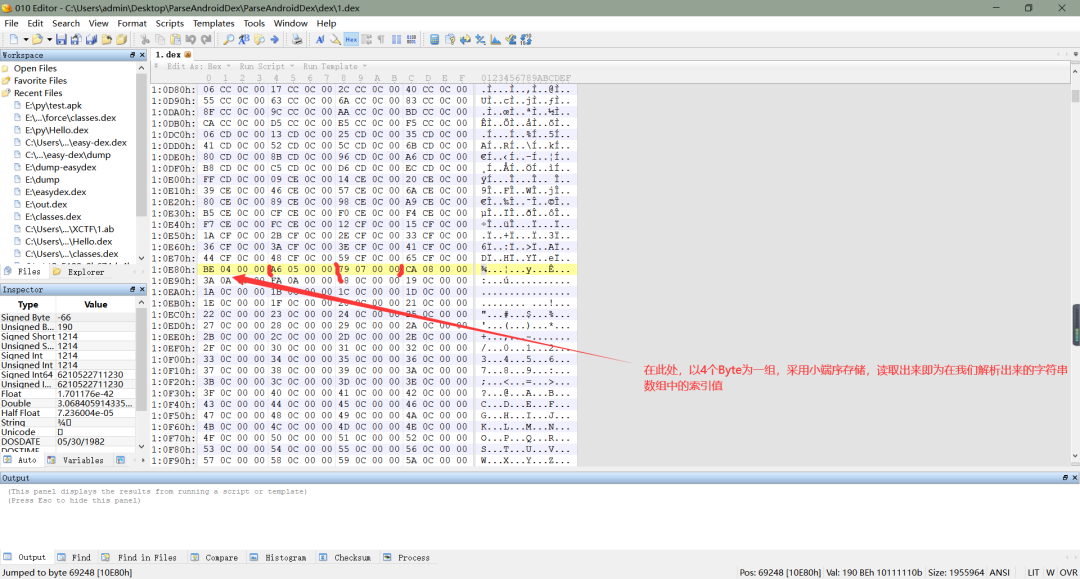
b、关于类的类型数量,没什么好说的,只需要注意它是以小端序存储的,读取的时候注意即可。对于类的类型偏移地址,找到偏移地址后,它是以四个字节为一组,对应了在解析出来的字符串数组中的索引值,例如下图中的第一组,它的数据是BE 04 00 00,我们读取出来就是0x04BE(同样采用的小端序存储),对应的类的类型就是字符串数组 [0x04be]。
2、解析脚本
PS:我电脑上脚本运行环境 python3.6
运行效果:
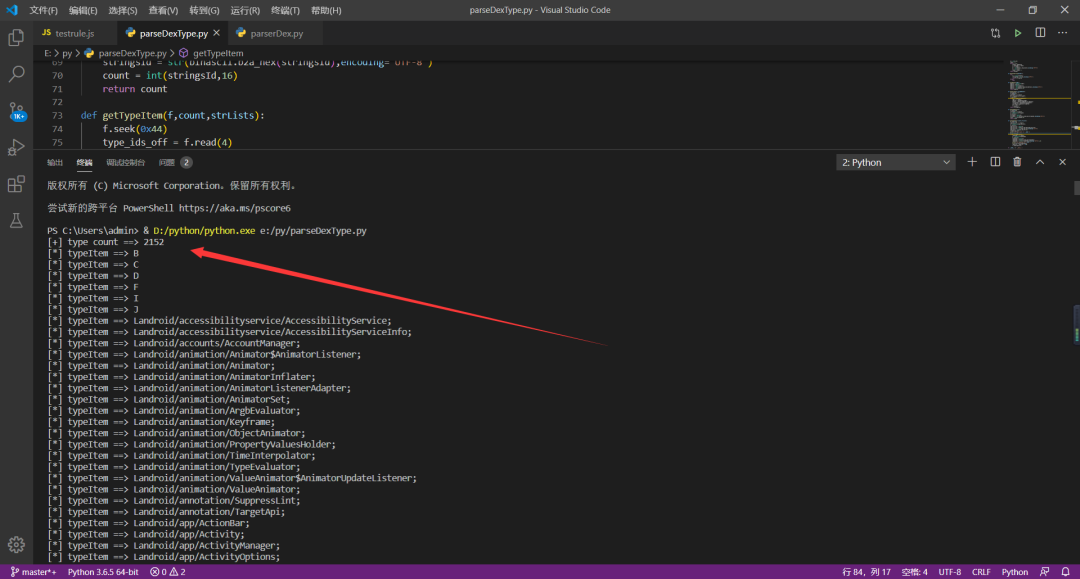
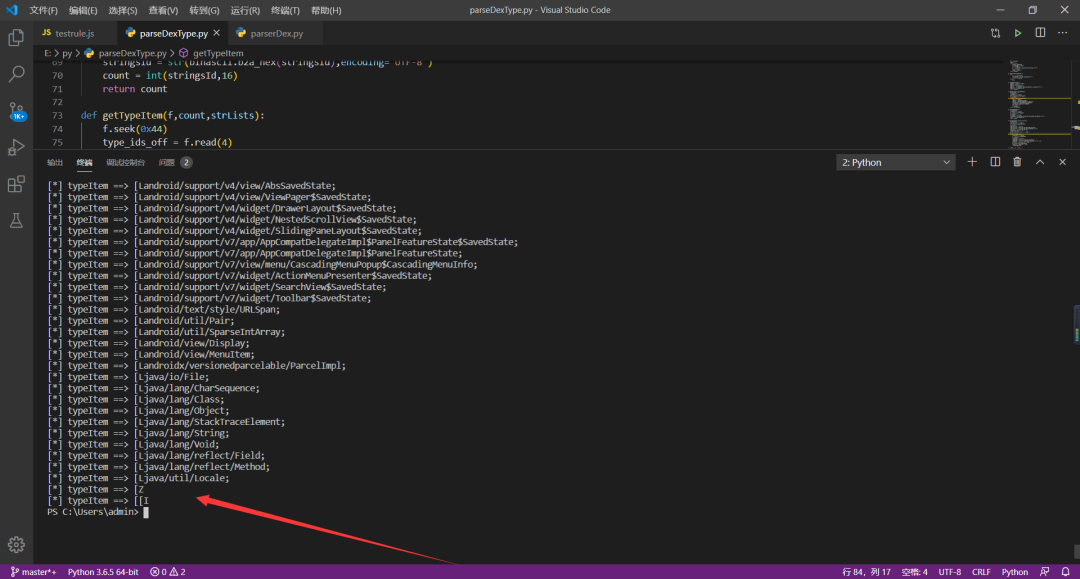
代码关键截图如下:
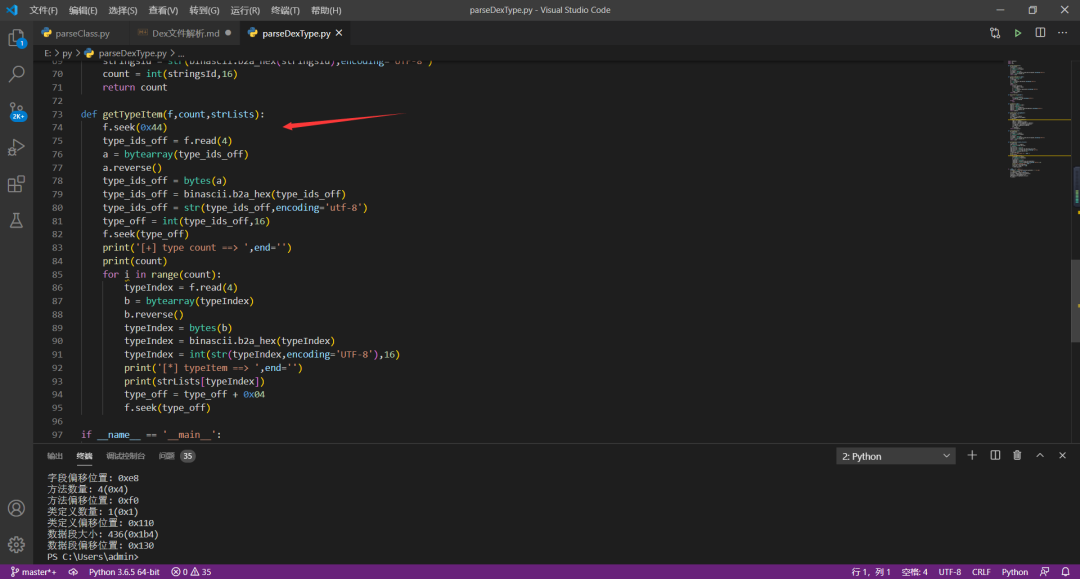
六、方法原型解析
1、DEX 文件中的方法原型
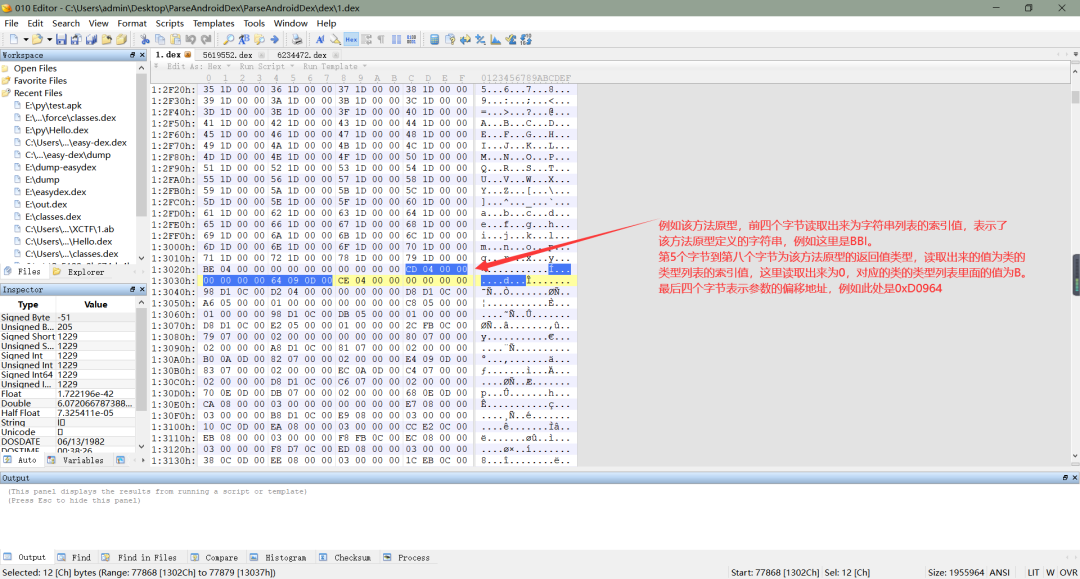
a、关于 dex 文件中方法原型的解析,需要知道怎么解析出字符串和类的类型,不明白的可以看前面解析。DEX 文件中的方法原型定义了一个方法的返回值类型和参数类型,例如一个方法返回值为void,参数类型为int,那么在 dex 文件中该方法原型表示为V(I)(smali中V表示void,I表示int)。在 dex 文件头部中,关于方法原型有两处,第一处位于0x48处,用 4 个字节定义了方法原型的数量,在0x4C处用 4 个字节定义了方法原型的偏移地址,如下所示:
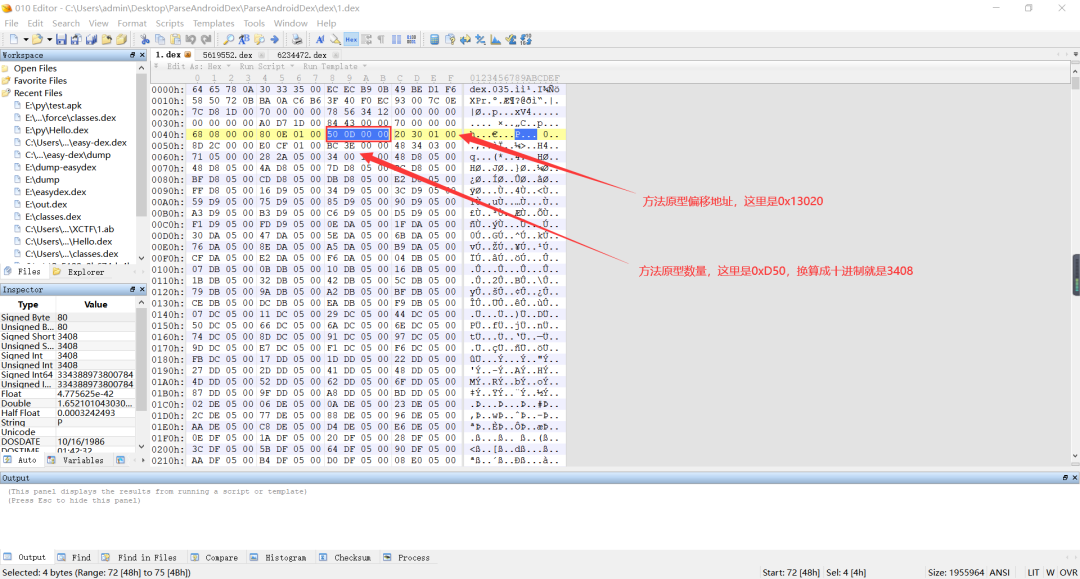
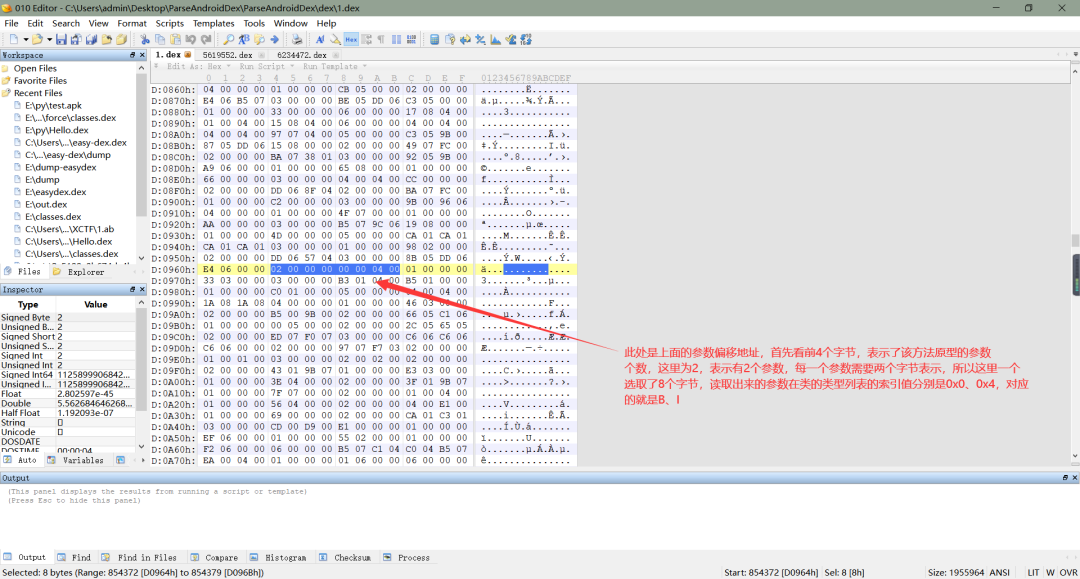
b、在上面我们知道了方法原型的起始偏移地址,接下来我们根据这个偏移地址找到方法原型,同样的,跟解析类的类型比较类似,一个方法原型所占字节数为 12 个字节,第一个字节到第四个字节表示了定义方法原型的字符串,这四个字节按小端序存储,读取出来为在字符串列表的索引,例如一个方法原型返回值为void,参数为boolean,那么定义该方法原型的字符串即为VZ;第 5 个字节到第八个字节表示该方法原型的返回值类型,读取出来的值为前面解析出来的类的类型列表的索引;第 8 个字节到第十二给字节表示该方法原型的参数,读取出来为一组地址,通过该地址可以找到该方法原型的参数,跳转到该地址去,首先看前 4 个字节,前四个字节按照小端序存储,读取出来的值为该方法原型参数的个数,接着根据参数个数,读取具体的参数类型,每个参数类型占 2 个字节,这两个字节读取出来的值为前面解析出来的类的类型列表的索引,如下所示:
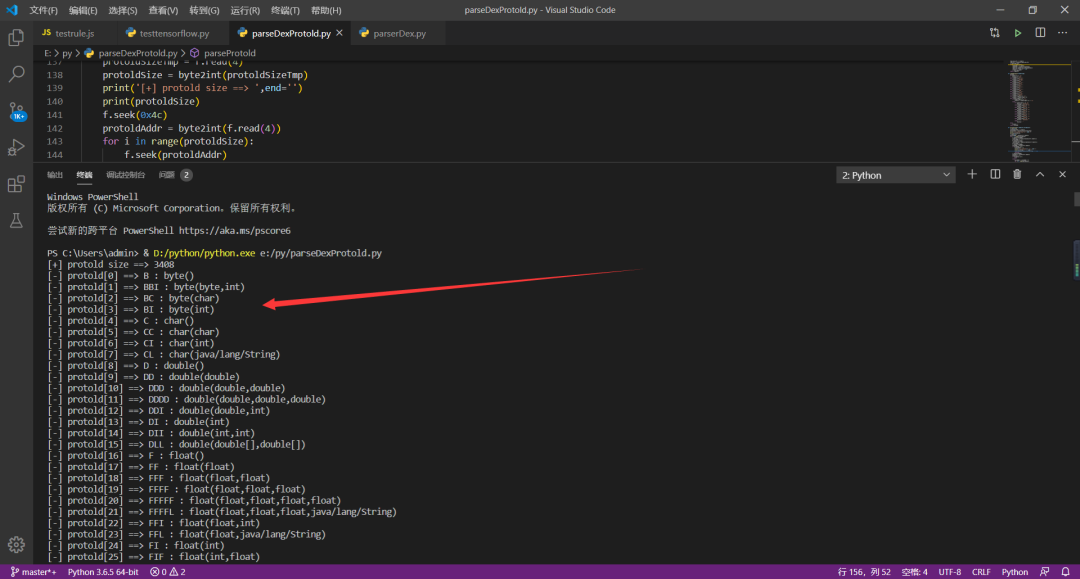
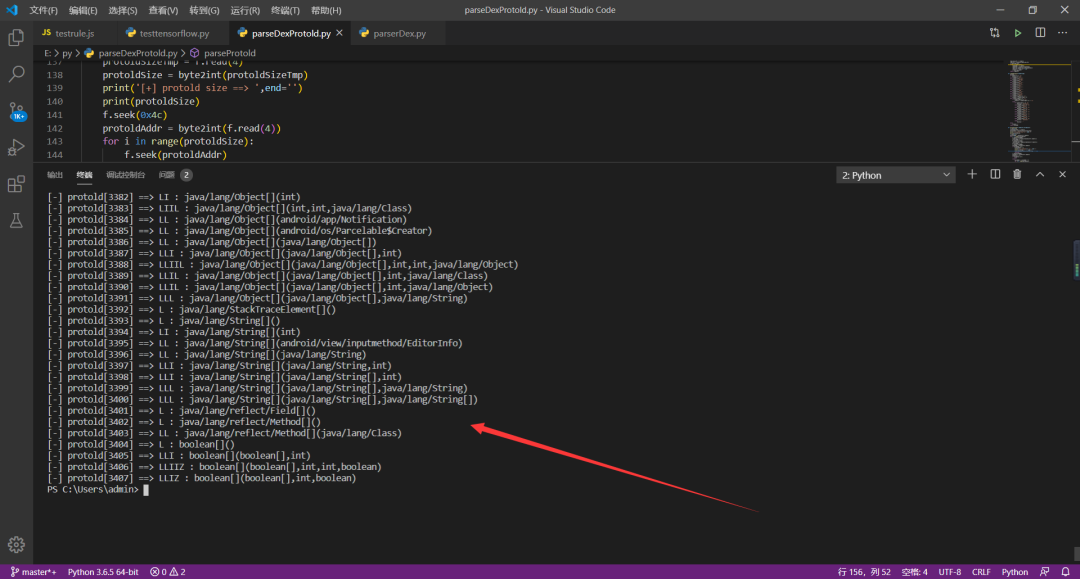
2、解析代码
运行环境:我电脑环境为 python3.6
运行截图:
解析代码关键截图:
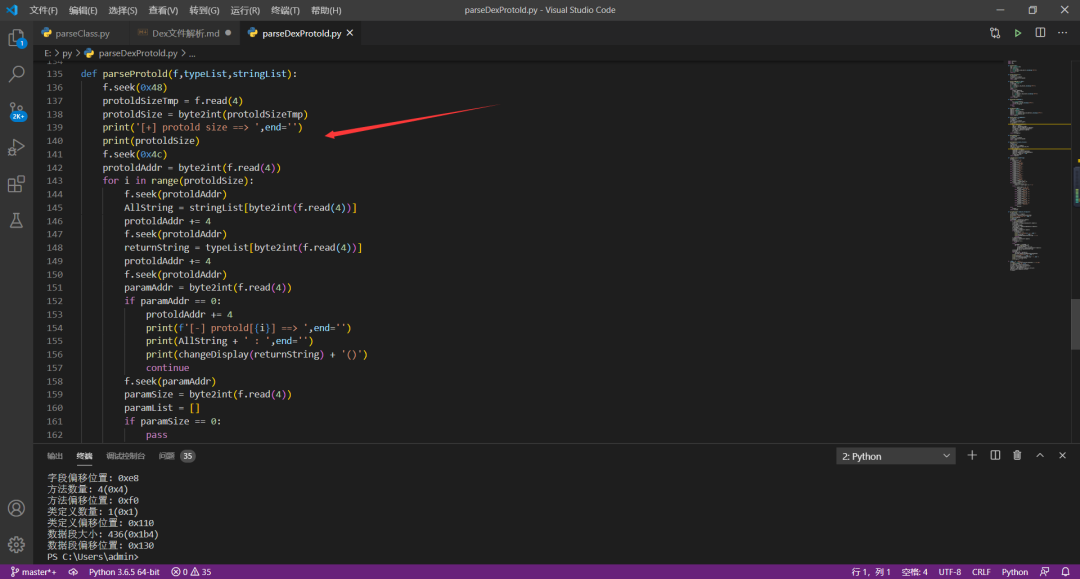
七、字段解析
1、dex 文件中的字段
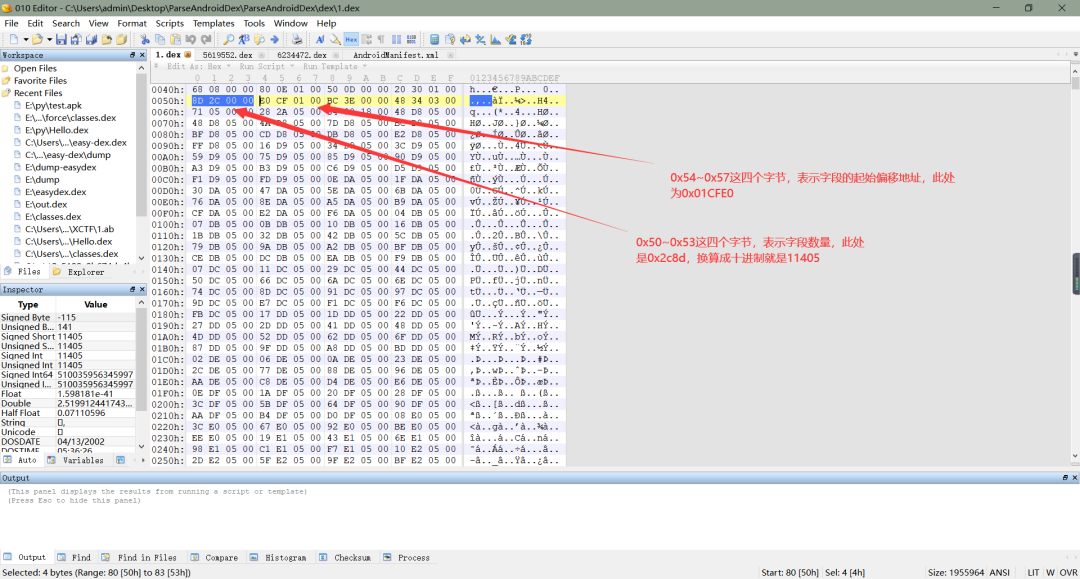
a、在 dex 文件头中,关于字段(ps:字段可以简单理解成定义的变量或者常量)相关的信息有 8 个字节,在0x50~0x53这四个字节,按小端序存储这 dex 文件中的字段数量,在0x54~0x57这四个字节,存储这读取字段的起始偏移地址,如下所示:
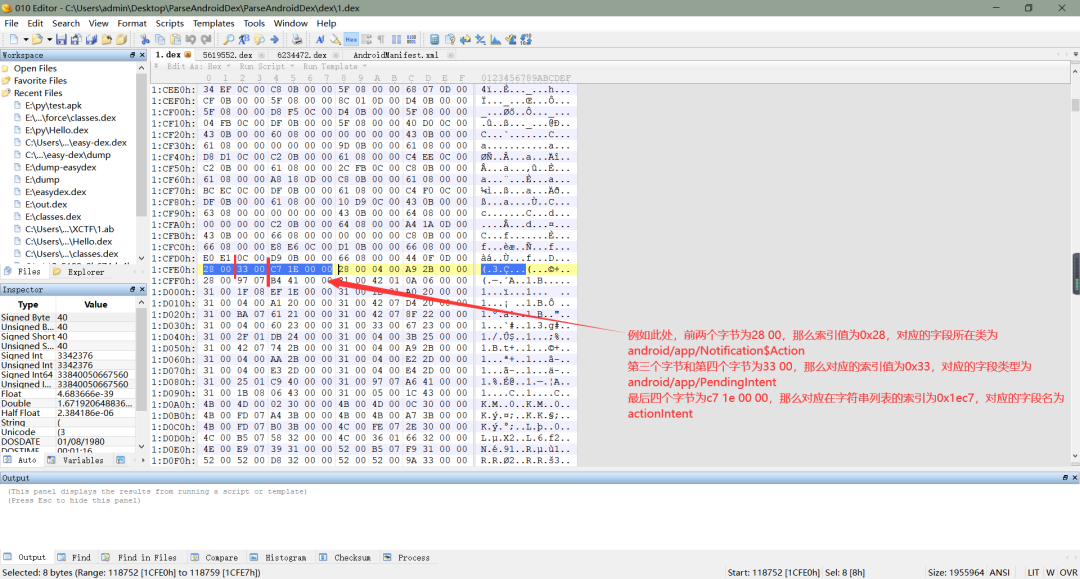
b、根据上面的字段起始偏移地址,我们可以找到字段,表示一个字段需要用八个字节,其中,前两个字节为我们在前面解析出来类的类型列表的索引,通过该索引找到的类的类型表示该字段在该类中被定义的(ps:我是这么理解的,如有不对,还请纠正);第三个字节和第四个字节,也是类的类型列表的索引,表示该字段的类型,例如我们在 java 某个类中定义了一个变量int a,那么我们此处解析出来的字段类型就是int;最后四个字节,则是我们前面解析出来字符串列表的索引,通过该索引找到的字符串表示字段的,例如我们定义了一个变量String test;,那么我们在这里解析出来的就是test,如下图所示:
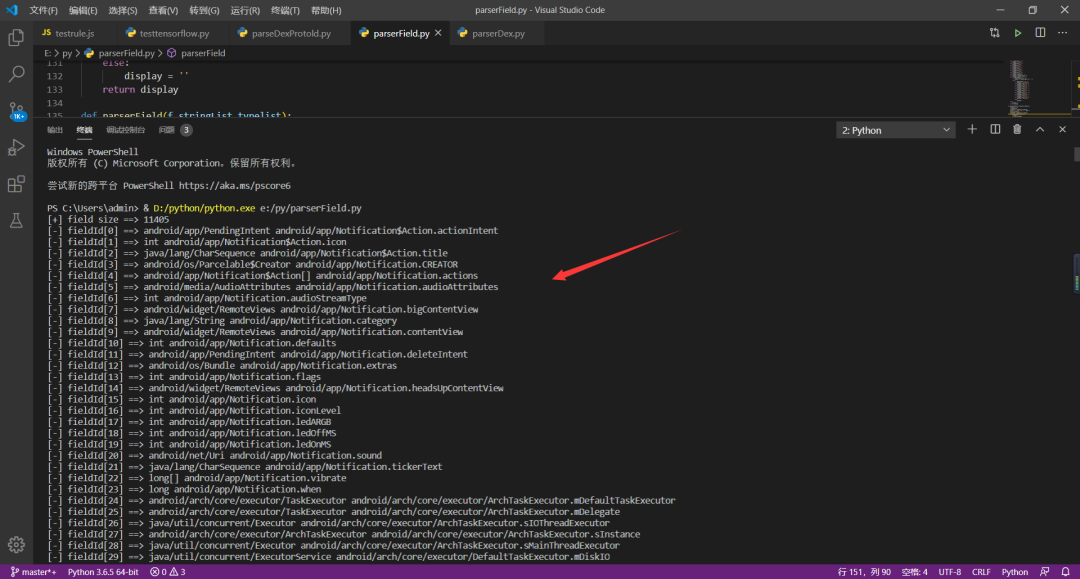
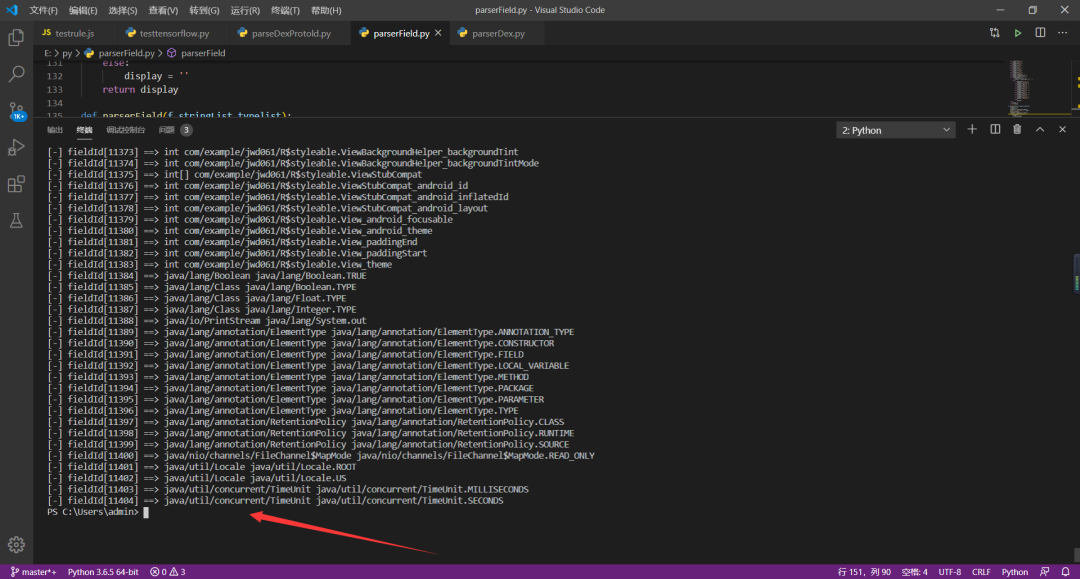
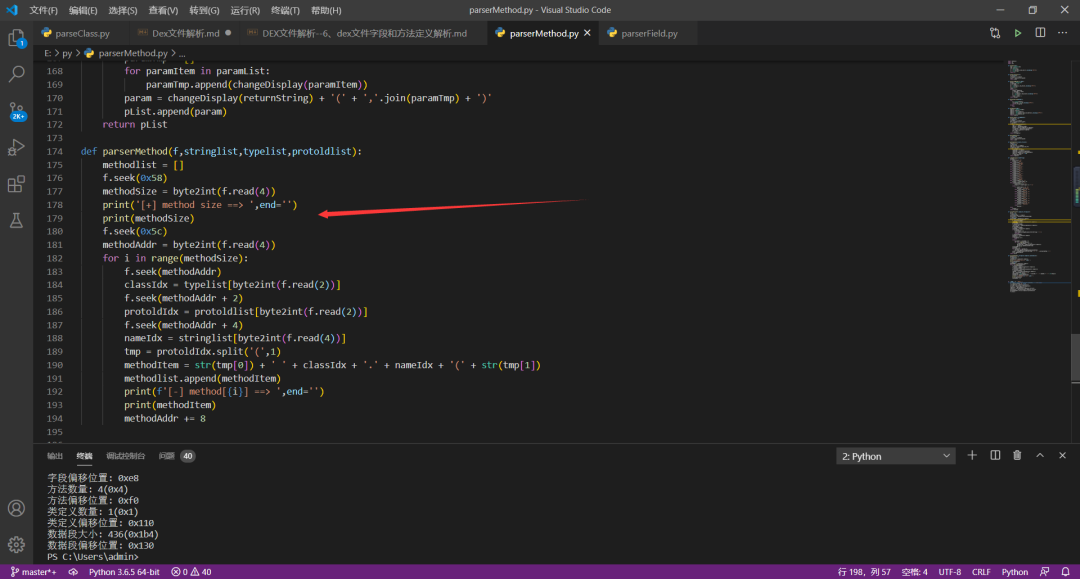
2、解析代码
解析代码运行截图:
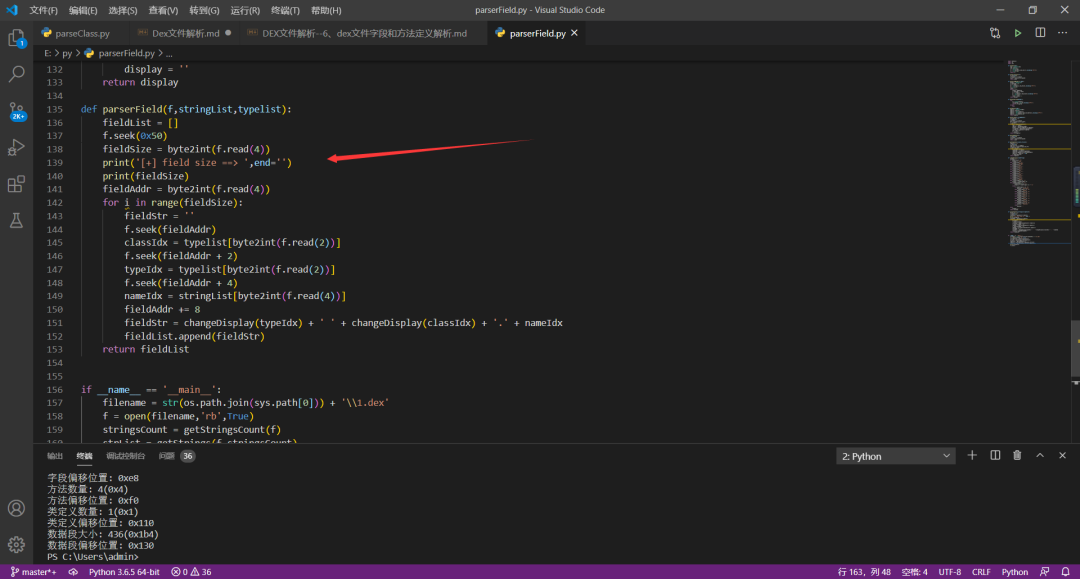
解析代码关键截图:
八、方法定义解析
1、Dex 文件中的方法定义
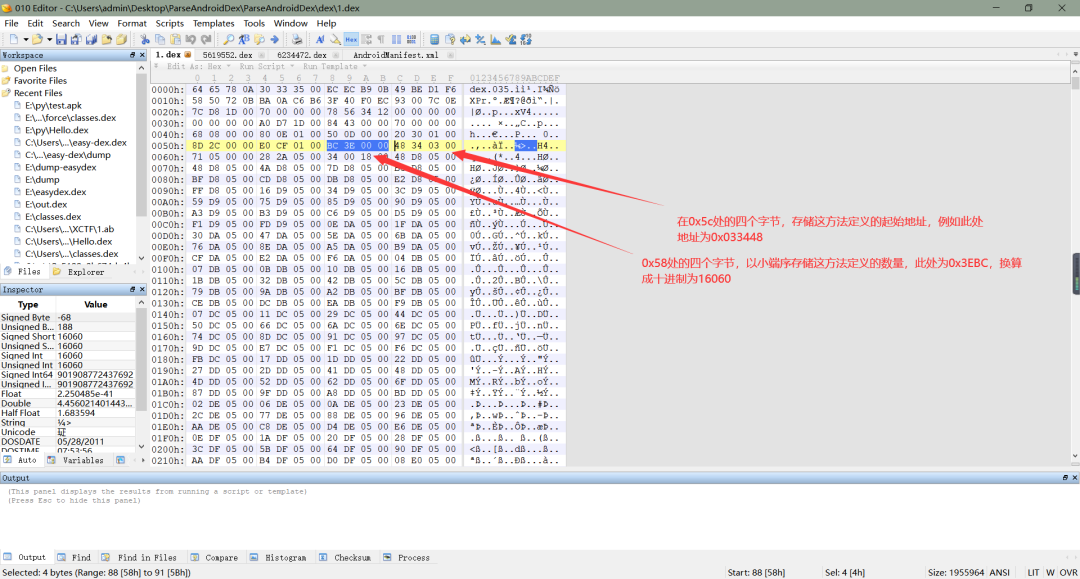
a、在 dex 文件头中,关于方法定义的信息同样是八个字节,分别位于0x58处和0x5c处。在0x58处的四个字节,指明了 dex 文件中方法定义的数量,在0x5c处的四个字节,表明了 dex 文件中的方法定义的起始地址(ps:都是以小端序存储的),如下图所示:
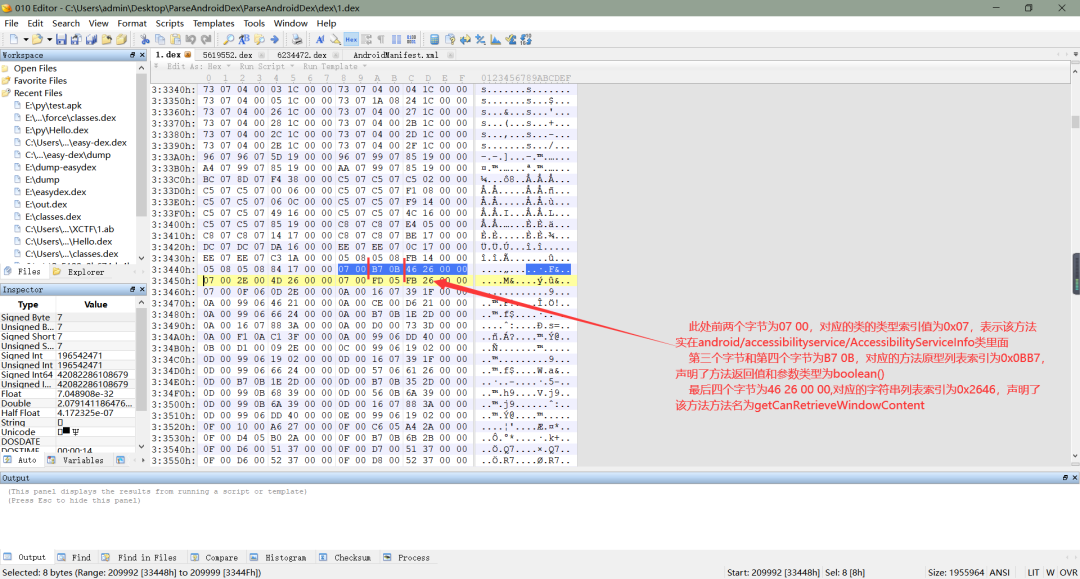
b、在上面的一步以及找到了方法定义的起始地址,跟字段类似的,一个方法定义也需要八个字节。其中,在前两个字节,以小端序存储着解析出来的类的类型列表的索引,表示该方法属于哪个类;第三个字节和第四个字节,以小端序存储这解析出来的方法原型列表的索引,通过该索引值找到的方法原型声明了该方法的返回值类型和参数类型;最后四个字节则以小端序存储着前面解析出来的字符串列表的索引,声明了该方法的方法名。如下图所示:
2、解析代码
解析代码运行截图:
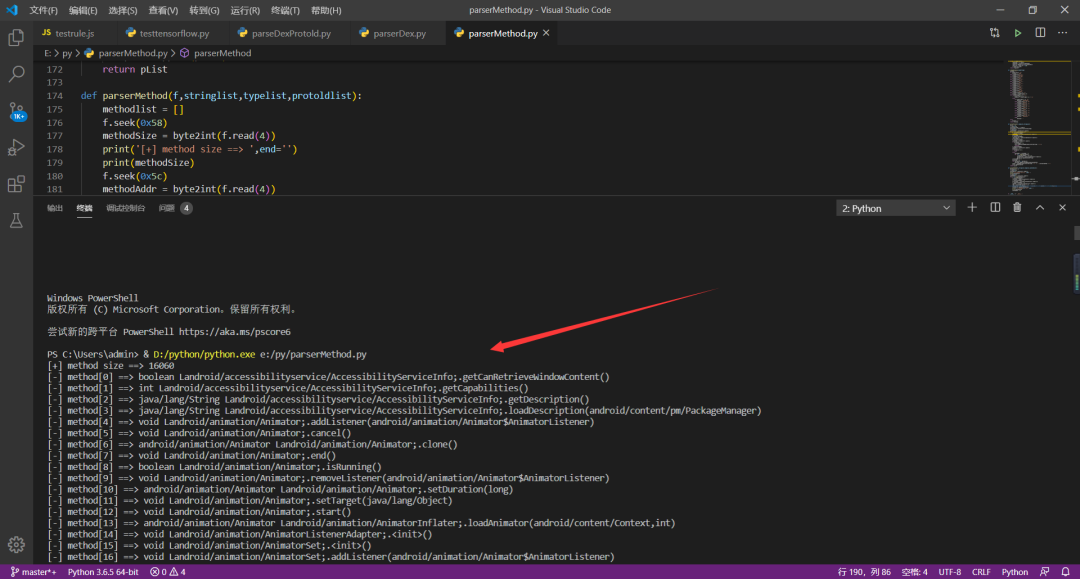
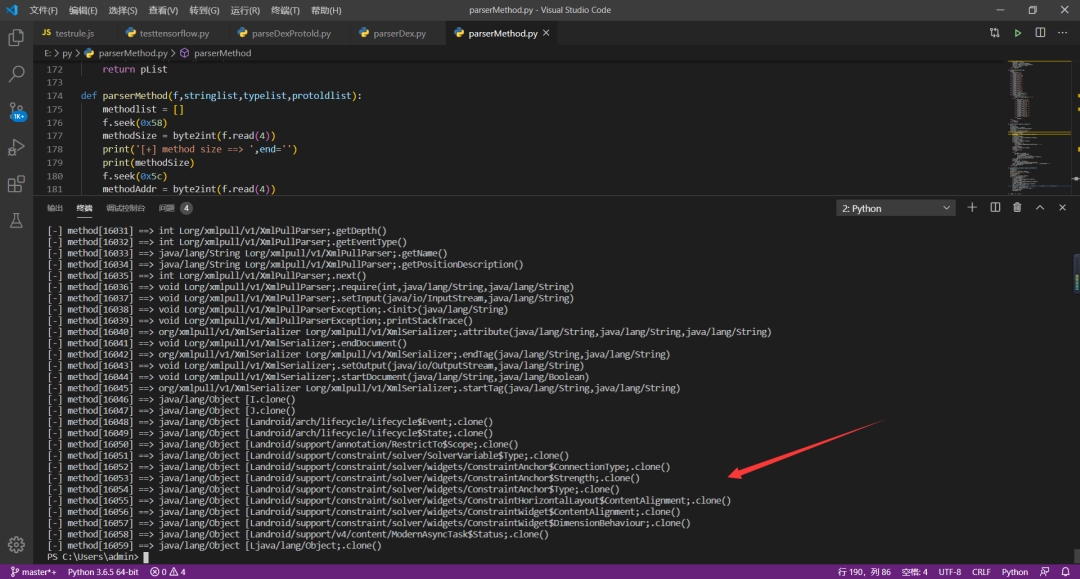
解析代码关键截图:
九、类解析
PS:Dex 文件解析到现在,终于到了最重要也是结构最复杂的部分了,这里分析的 dex 样本来自一个复杂 apk 的 dex 文件,但是代码运行时使用的样本是一个在网上找的很简单的 dex 样本,原因很简单,分析使用的 dex 涉及的 smali 指令太多了,大概有 200 多个,挨个解析起来工作量太大了,有时间我会写一个通用的 python 解析模块,完成了我会上传到 github 仓库,有兴趣的完成后可以看一下,用简单的 dex 只涉及到 5 个指令,代码写起来就没那么麻烦了!!!(tips:Dex 类数据这里解析起来有种俄罗斯套娃的感觉,多看几篇就很容易理解了。)
1、uleb128 编码
PS:本来关于 uleb128 编码网上一大堆,没必要写这个,但是网上的你抄我的我抄你的,能找的的相关资料基本都一样。。。。或者干脆贴个官方代码,官方代码的位运算写的很巧妙,但是直接去看的化,反正我是没看懂到底是怎么解码出来的。
uleb128 编码,是一种可变长度的编码,长度大小为1-5字节,uleb128 通过字节的最高位来决定是否用到下一个字节,如果最高位为 1,则用到下一个字节,直到某个字节最高位为 0 或已经读取了 5 个字节为止,接下来通过一个实例来理解 uleb128 编码。
假设有以下经过 uleb128 编码的数据(都为 16 进制)--81 80 04,首先来看第一个字节81,他的二进制为10000001,他的最高位为1,则说明还要用到下一个字节,它存放的数据则为0000001;再来看第二个字节80,它的二进制为10000000,它的最高位为1,则说明还需要用到第三个字节,存放的数据为0000000;再来看第三个字节04,它的二进制为00000100,最高位为0,说明一共使用了三个字节,它存放的数据为0000100;通过上面的数据我们已经获取了存放的数据,接下来就是把这些 bit 组合起来获取解码后的数据,dex 文件里面的数据都是采用的小端序的方式,uleb128 也不例外,在这三个字节,也不例外,第三个字节04存放的数据0000100作为解码后的数据的高 7 位,第二个字节80存放的数据0000000作为解码后的数据的中 7 位,第一个字节81存放的数据0000001作为解码后的数据的低 7 位;那么解码后的数据二进制则为0000100 0000000 0000001,转换为 16 进制则为0x10001。其他使用 5 个字节、4 个字节照此类推即可,下面是 python 读取 uleb128 的代码(ps:该代码是最终类数据解析代码的一共函数,无法单独运行,仅供参考,采用的是官方提供的位运算算法):
def readuleb128(f,addr): result = [-1,-1] n = 0 f.seek(addr) data = oneByte2Int(f.read(1)) if data > 0x7f: f.seek(addr + 1) n = 1 tmp = oneByte2Int(f.read(1)) data = (data & 0x7f) | ((tmp & 0x7f) << 7) if tmp > 0x7f: f.seek(addr + 2) n = 2 tmp = oneByte2Int(f.read(1)) data |= (tmp & 0x7f) << 14 if tmp > 0x7f: f.seek(addr + 3) n = 3 tmp = oneByte2Int(f.read(1)) data |= (tmp & 0x7f) << 21 if tmp > 0x7f: f.seek(addr + 4) n = 4 tmp = oneByte2Int(f.read(1)) data |= tmp << 28 result[0] = data result[1] = addr + n + 1 return result
最后
以上就是痴情小熊猫最近收集整理的关于wav文件头字节数和文件实际字节不一致_一文读懂 DEX 文件格式解析的全部内容,更多相关wav文件头字节数和文件实际字节不一致_一文读懂内容请搜索靠谱客的其他文章。








发表评论 取消回复