我时常在想,为什么别人这么优秀呢?原来我在玩、发呆的时候别人都陪着女朋友在学习。
长文预警
推荐打开方式:收藏->滑到页尾点赞留言点广告->转发->闲下来的时候一个一个消化->-MySql->Redis->MongoDB。
边学习,边敲哦,多复习,知识就是你的啦。
前言
本系列转载自公众号:咸鱼普拉思,一个优秀的大佬,本系列一共三篇,详细介绍了三大数据库---MySql、Redis、MongoDB基本操作,全都是干货哈。
一、MySql 篇
安装与启动
安装:sudo apt-get install mysql-serverps ajx | grep mysqlsudo service mysql stopsudo service mysql startsudo service mysql restartmysql -uroot -p后输入密码select version();
常见数据库语句
查看数据库:show database;create database 库名 [charset = UTF8];show create database 库名;use 库名;drop 库名;
常见数据表语句
查看表:show table;desc 表名;
CREATE TABLE table_name(
column1 datatype contrai,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY(one or more columns)
);
创建表常用属性字段:
-- auto_inorement 表示自动增长
-- not null 表示不为空
-- primary key 表示为主键
-- defaul 表示默认值
删除表:drop table;
添加字段:alter table 表名 add 列名 类型;
修改字段(重命名):alter table 表名 change 原名 新名 类型及约束;
修改字段(不重命名):alter table 表名 modify 列名 类型及约束;
删除字段:alter table 表名 drop 列名;
常用增删改查
基本查询
查看所有列:select * from 表名;select 列1,列2,... from 表名;
新增
全列插入:insert into 表名 values(...); --需要给主键留下占位符,用0或null皆可。insert into 表名(列1,...) values(值1,...);insert into 表名 values(...),(...)...;insert into 表名(列1,...) values(值1,...),(值1,...)...;
更新
更新操作:update 表名 set 列1=值1,列2=值2... where 条件;
删除
删除操作(不推荐):delete from 表名 where 条件;update 字段名 set isvalid=0 where id=1; --设置删除字段,执行删除字段的操作即对该字段更新。
mysql查询详解
查询消除重复行:select distinct 列1,... from 表名;
条件查询
where条件查询:select * from 表名 where 条件;
比较运算符
等于: =
大于: >
大于等于: >=
小于: <
小于等于: <=
不等于: != 或 <>
举个栗子:
select * from students where id > 1;
select * from students where id <= 2;
select * from students where name != '咸鱼';
select * from students where is_delete=0;
逻辑运算符
and
or
not
举个栗子:
select * from students where id > 3 and gender=0;
select * from students where id < 4 or is_delete=0;
select * from students where id not 4;
模糊查询
like
% 表示任意多个任意字符
_ 表示一个任意字符
rlike
举个栗子:
select * from students where name like '咸%'; --查询以咸字开头的内容
select * from students where name like '咸_'; --查询以咸字开头且后面只有一个字的内容
select * from students where name like '咸%' or name like '%鱼'; -- 查询以咸字开头或以鱼字结尾的内容
范围查询
in 表示在一个非连续的范围内
no in 表示不在一个非连续的范围内
between ... and ... 表示在一个连续的范围内
rlike 表示正则查询,可以使用正则表达式查询数据
举个栗子:
select * from students where id in(1,3,8); -- 查询 id 在 1,3,8 当中的内容
select * from students where id not in(1,3,8); -- 查询 id 不在 1,3,8 当中的内容
select * from students where id between 3 and 8; -- 查询 id 在3到8之间的内容
select * from students where name rlike "^咸"; -- 查询 name 是以咸字开头的内容
空判断
判断是否为空 is null
举个栗子:
select * from students where height is null;
以上几种预算符优先级为:
排序
asc 升序
desc 降序
举个栗子:
select * from students order by age desc,height desc; --显示所有的学生信息,先按照年龄从大到小排序,当年龄相同时 按照身高从高到矮排序
聚合函数
count(*)查询总数
max(列)表示求此列的最大值
min(列)表示求此列的最小值
sum(列)表示求此列的和
avg(列)表示求此列的平均值
举个栗子:
select count(*) from students;
select max(id) from students where gender=2;
select min(id) from students where is_delete=0;
select sum(age) from students where gender=1;
select sum(age)/count(*) from students where gender=1; --求平均年龄
select avg(id) from students where is_delete=0 and gender=2;
分组
group by 将查询结果按照1个或多个字段进行分组,字段值相同的为一组
group_concat 表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
举个栗子:
select gender from students group by gender; -- 将学生按照性别分组
输出结果:
+--------+
| gender |
+--------+
| 男 |
| 女 |
| 中性 |
| 保密 |
+--------+
select gender,group_concat(name) from students group by gender;
输出结果:
+--------+-----------------------------------------------------------+
| gender | group_concat(name) |
+--------+-----------------------------------------------------------+
| 男 | 小彭,小刘,小周,小程,小郭 |
| 女 | 小明,小月,小蓉,小贤,小菲,小香,小杰 |
| 中性 | 小金 |
| 保密 | 小凤 |
+--------+-----------------------------------------------------------+
分页
select * from 表名 limit start,count
举个栗子:
select * from students where gender=1 limit 0,3; --查询前三行的数据
连接查询
语法:
select * from 表1 inner/left/right join 表2 on 表1.列 = 表2.列
其中:
inner join(内连接查询):查询的结果为两个表匹配到的数据
right join(右连接查询):查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充
left join(左连接查询):查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充
举个栗子:
select * from students inner join classes on students.cls_id = classes.id;
select * from students as s left join classes as c on s.cls_id = c.id;
select * from students as s right join classes as c on s.cls_id = c.id;
子查询
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句。
主查询 where 条件 in (子查询)
数据库的备份与恢复
数据库备份
mysqldump –uroot –p 数据库名 > 备份文件名.sql;
数据库恢复
mysql -uroot –p 新数据库名 < 备份文件名.sql
Python与mysql交互

安装与导入
安装相关库:pip install pymysqlfrom pymysql import *
创建connection对象
connection = connect(host, port, database, user, password, charset)
其中参数如下:
host:连接的mysql主机,如果本机是'localhost'
port:连接的mysql主机的端口,默认是3306
database:数据库的名称
user:连接的用户名
password:连接的密码
charset:通信采用的编码方式,推荐使用utf8
connection对象方法如下:
close()关闭连接
commit()提交
cursor()返回Cursor对象,用于执行sql语句并获得结果
获取cursor
cursor=connection.cursor()
其中常用方法:
close():关闭cursor
execute(operation [, parameters ]):执行语句,返回受影响的行数,主要用于执行insert、update、delete语句,也可以执行create、alter、drop等语句。
fetchone():执行查询语句时,获取查询结果集的第一个行数据,返回一个元组
fetchall():执行查询时,获取结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回
举个栗子:
from pymysql import *
def main():
conn = connect(host='localhost',port=3306,database='xianyuplus',user='root',password='mysql',charset='utf8')
cs1 = conn.cursor()
count = cs1.execute('insert into xianyufans(name) values("666")')
conn.commit()
cs1.close()
conn.close()
if __name__ == '__main__':
main()
mysql视图
什么是视图?
视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据。
视图语句
创建视图:create view 视图名称 as select语句; --建议视图以v_开头
查看视图:show tables;
使用视图:select * from 视图名称;
删除视图:drop view 视图名称;
视图作用
提高了重用性,就像一个函数
对数据库重构,却不影响程序的运行
提高了安全性能,可以对不同的用户
让数据更加清晰
mysql事务
什么是事务?
事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
事务有什么特点?
原子性,一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
一致性,数据库总是从一个一致性的状态转换到另一个一致性的状态。
隔离性,一个事务所做的修改在最终提交以前,对其他事务是不可见的。
持久性,一旦事务提交,则其所做的修改会永久保存到数据库。
事务相关命令
开启事务:start transaction; 或者 begin;
提交事务:commit;
回滚事务:rollback;
mysql索引
什么是索引?
数据库索引好比是一本书前面的目录,能加快数据库的查询速度
索引相关命令
创建索引:create index 索引名称 on 表名(字段名称(长度)) --当指定索引的字段类型为字符串时,应填写长度
查看索引:show index from 表名;
删除索引:drop index 索引名称 on 表名;
注意事项
建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立另外的索引。
建立索引会占用磁盘空间。
尾言
以上就是关于mysql的一些用法,其实是比较基础的,重点部分是关于mysql的查询部分,毕竟在业务应用中主要还是查询为主。
二、Redis 篇
nosql与redis介绍
nosql数据库:
不支持SQL语法
存储结构跟传统关系型数据库中的那种关系表完全不同,nosql中存储的数据都是KV形式
NoSQL的世界中没有一种通用的语言,每种nosql数据库都有自己的api和语法,以及擅长的业务场景
NoSQL中的产品种类相当多:Mongodb,Redis,Hbase hadoop,Cassandra hadoop等等。
redis数据库是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
安装与启动
windows:
安装redis:https://github.com/MSOpenTech/redis/releases
安装redis管理客户端:https://redisdesktop.com/download
linux:
安装:sudo apt-get -y install redis-serverredis-cli配置文件位置:/etc/redis/redis.conf
bind ip 绑定ip以配置远程访问
port [num] 绑定端口
daemonize 是否以守护进程运行,推荐设置为yes,不会在命令行阻塞,类似于服务
dbfilename 数据文件名称
dir /xx/xx/redis 设置数据文件存储的位置
log file /xx/xx/xx/redis-server.log 日志文件位置
slaveof ip port 主从复制的ip端口
启动redis:sudo server redis startsudo server redis stopsudo server redis restartsudo redis-server /etc/redis/redis.confps-ef|grep redissudo kill -9 pid
redis数据结构与操作
redis数据结构
redis是key-value的数据结构,每条数据都是一个键值对
键的类型是字符串,且键不能重复
值的类型分为五种:字符串strin,哈希hash,列表list,集合set,有序集合zset
redis数据操作
redis键命令
redis键命令对所有数据类型通用
查找键:keys [正则表达式]keys *exists keytype keydel key1 key2 key3...expire key secondsttl key
string类型相关操作
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
新增与更新
设置键值(当键存在即为更新值):set key value
# 设置键为xianyu值为plus的数据
set xianyu plus
设置键值以及过期时间:setex key seconds value
# 设置键为xianyu值为plus的数据,且3秒后过期
setex xianyu 3 plus
设置多个键值:mset key1 value1 key2 value2...
# 设置键为xianyu[n]值为plus[n]的数据
mset xianyu plus xianyu1 plus1 xianyu2 plus2
向现有的值追加其他值:append key value
# 向键名为xianyu的值中追加值1
append xianyu 1
查看
查看键值:get key
# 查看xianyu的值
get xianyu
查看多个键的值:mget key1 key2 key3...
# 查看xianyu1,xianyu2,xianyu3的值
mget xianyu1 xianyu2 xianyu3
删除
删除键:del key
hash哈希类型相关操作
hash类型的值的类型为string
新增与修改
设置单个值:hset key field value
# 设置键xianyu的name属性的值为xianyuplus
hset xianyu name xianyuplus
设置多个值:hmset key field1 value1 field2 value2 ...
# 设置xianyu的name值为xianyuplus age值为23
hmset xianyu name xianyuplus age 23
获取
获取单个键的所有属性:hkeys key
# 获取xianyu的所有属性
hkeys xianyu
获取单个属性的值:hget key field
# 获取xianyu的name值
hget xianyu name
获取多个属性的值:hmget key field1 field2 ...
# 获取xianyu的name值和age值
hmget xianyu name age
获取所有属性的值:hvals key
hvals xianyu
删除
删除单个键所有属性和值:del keyhdel field1 field2...
# 删除xianyu的name和age
hdel xianyu name age
list列表类型相关操作
list类型的值为string,值按照插入顺序排序
新增
在list左边插入数据:lpush key value1 value2 value3...
#插入1,2,3,4,5,6,
lpush xianyu 1 2 3 4 5 6
在list右边插入数据:rpush key value1 value2 value3...
#插入1,2,3,4,5,6,
rpush xianyu 1 2 3 4 5 6
在指定元素前或后插入数据:linsert key before/after 现有元素 新元素
# 在1的前面插入a
linsert xianyu before 1 a
获取列表元素
获取列表指定范围内的值:lrange key start stop
注意:这里的列表和python中的列表索引方式相同,从左往右以0开始,索引支持负数
# 获取键为xianyu的列表0到6的全部元素
lrange xianyu 0 6
# 获取键为xianyu的列表所有元素
lrange xianyu 0 -1
修改
设置指定索引位置的元素:lset key index value
lset xianyu 0 1
删除
删除指定元素:lrem key count value
将列表中前count次出现的值为value的元素移除
count > 0: 从头往尾移除
count < 0: 从尾往头移除
count = 0: 移除所有
举个栗子:
# 删除从头往尾数的两个1
lrem xianyu 2 1
set集合类型相关操作
无序集合
元素为string类型
元素具有唯一性,不重复
说明:对于集合没有修改操作
新增
添加元素:sadd key member1 member2 ...
# 向键xianyu的集合中添加元素a,b,c
sadd xianyu a b c
获取
获取所有值:smembers key
# 获取键xianyu的集合所有的值
smembers xianyu
删除
删除指定的元素:srem key member
# 删除键xianyu的集合值指定的元素
srem xianyu a
zset有序集合相关操作
sorted set,有序集合
元素为string类型
元素具有唯一性,不重复
每个元素都会关联一个double类型的score,表示权重,通过权重将元素从小到大排序
说明:没有修改操作
新增
新增多个元素:zadd key score1 member1 score2 member2 ...
zadd xianyu 2 name 1 age
查看
这里的有序集合和列表相同都有索引值
查看有序集合的值:zrange key start stop
# 获取xianyu中0-6的值
zrange xianyu 0 6
# 获取xianyu中所有的值
zrange xianyu 0 -1
# 获取xianyu中权重最大最小中间的值
查看集合权重在指定范围内的值:zrangebyscore key min max
zrangebyscore xianyu min max
返回成员member的score值:zscore key member
zscore xianyu a
删除
删除指定元素:zrem key member1 member2 ...
zrem xianyu a
删除权重在指定范围的元素:zrem key min max
zrem xianyu 1 2
python与redis交互
安装与导入
安装:pip install redisfrom redis import *
创建StrictRedis
通过init创建对象,指定参数host、port与指定的服务器和端口连接,host默认为localhost,port默认为6379,db默认为0,默认没有密码。
red = StrictRedis(host='localhost', port=6379, db=0)
方法与操作string实例(其他类型操作类似)
这里不同类型拥有的方法和上面redis中讲解的方法相同,这里不再赘述。
举个栗子:
# 链接redis,创建stricredis对象
from redis import *
if __name__=="__main__":
try:
#创建StrictRedis对象,与redis服务器连接
redis=StrictRedis()
# 新增一个string类型
result=redis.set('name','xianyuplus')
# 成功打印True,失败打印False
print(result)
#获取键name的值
result = redis.get('name')
#输出键的值,如果键不存在则返回None
print(result)
#设置键name的值,如果键已经存在则进行修改,如果键不存在则进行添加
result = redis.set('name','xianyu')
#输出响应结果,如果操作成功则返回True,否则返回False
print(result)
result = redis.delete('name')
#输出响应结果,如果删除成功则返回受影响的键数,否则则返回0
print(result)
#获取所有的键
result=sr.keys()
#输出响应结果,所有的键构成⼀个列表,如果没有键则返回空列表
print(result)
except Exception as e:
print(e)
redis搭建主从服务(ubuntu)
什么是主从服务
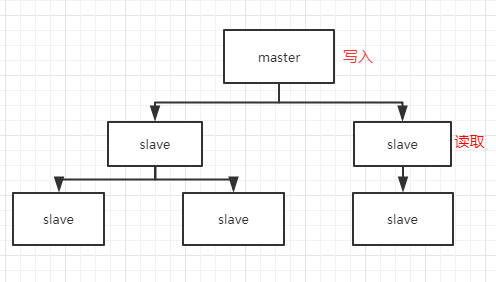
一个master可以拥有多个slave,一个slave可以拥有多个slave,如此下去,形成了多级服务器集群架构
master用来写数据,slave用来读数据,经统计:网站的读写比率是10:1
通过主从配置可以实现读写分离
master和slave都是一个redis实例(redis服务)
配置主
vim etc/redis/redis.conf
bind [本机ip]
sudo service redis stop
redis-server redis.conf
配置从
sudo cp redis.conf ./slave.conf
vim slave.conf
bind [主配置的ip]
slaveof [主配置的ip 端口号]
port 6378 --这个端口号不能和主配置的相同
sudo redis-server slave.conf
查看主从关系
redis-cli -h [主配置的ip] info Replication
主从测试
主配置上写入数据:set xianyu xianyuplus
从配置上读取数据:get xianyu
尾言
以上就是关于redis的一些用法,重点部分还是各个数据类型的操作,一定要照着敲一次才能记得住哦。
三、MangoDB 篇
前言
本篇为mongodb篇,包含实例演示,mongodb高级查询,mongodb聚合管道,python交互等内容。
mongoDB的优势
易扩展
大数据量,高性能
灵活的数据模型
安装与启动
安装mongodb:sudo apt-get install -y mongodb-orghttps://robomongo.org/download
查看帮助:mongod –helpsudo service mongod startsudo service mongod stopsudo service mongod restartps ajx|grep mongod
配置文件的位置:/etc/mongod.conf/var/log/mongodb/mongod.log
mongodb数据库操作
数据库操作
查看当前的数据库:dbshow dbs /show databasesuse db_namedb.dropDatabase()
集合操作
当集合不存在时,插入任何一条数据集合自动创建。db.createCollection(name,[options])
参数capped: 默认值为false表示不设置上限,值为true表示设置上限
参数size: 当capped值为true时,需要指定此参数,表示上限大小,当文档达到上限时,会将之前的数据覆盖,单位为字节
当集合存在时:show collectionsdb.集合名称.drop()
mongodb数据类型
Object ID:文档ID
String: 字符串,最常使用,必须是有效的UTF-8
Boolean: 存储一个布尔值,true或false
Integer: 整数可以是32位或64位,这取决于服务器
Double: 存储浮点值
Arrays: 数组或列表, 多个值存储到一个键
Object: 用于嵌入式的文档, 即一个值为一个文档
Null: 存储Null值
Timestamp: 时间戳,表示从1970-1-1到现在的总秒数
Date: 存储当前日期或时间的UNIX时间格式
注意点:
创建日期语句如下 :参数的格式为YYYY-MM-DD
new Date('2017-12-20')
每个文档都有一个属性,为_id,保证每个文档的唯一性
可以自己去设置_id插入文档,如果没有提供,那么MongoDB为每个⽂档提供了一个独特的_id,类型为objectID
objectID是一个12字节的十六进制数:
前4个字节为当前时间戳
接下来3个字节的机器ID
接下来的2个字节中MongoDB的服务进程id
最后3个字节是简单的增量值
mongodb数据操作
新增
插入数据(字段_id存在就报错):db.集合名称.insert(document)
插入数据(字段_id存在就更新):db.集合名称.save(document)
举个栗子:
#插入文档时,如果不指定_id参数,MongoDB会为文档分配一个唯一的ObjectId
db.xianyu.insert({name:"xianyuplus",age:"3"})
#插入文档时,可以指定_id参数
db.xianyu.insert({_id:"10001",name:"xianyuplus",age:"30"})
#更新了上面_id为1001的文档
db.xianyu.save({_id:"10001",name:"xianyuplus",age:"40"})
查询
查询数据:db.集合名称.find()
举个栗子:
db.xianyu.find()
更新
更新数据:db.集合名称.update(<query> ,<update>,{multi: <boolean>})
参数query:查询条件
参数update:更新操作符
参数multi:可选,默认是false,表示只更新找到的第一条记录,值为true表示把满足条件的文档全部更新
举个栗子:
原有内容:
{
"_id" : ObjectId("5b66f05f1194e110103bc283"),
"name": "xianyuplus",
"age": "40"
}
# 将name为xianyuplus的值替换为xianyuplus1
db.xianyu.update({name:"xianyuplus"},{name:"xianyuplus1"})
操作后内容:
{
"_id" : ObjectId("5b66f05f1194e110103bc283"),
"name": "xianyuplus1"
}
可以看到单单使用update更新数据会导致原有数据被新数据替换,所以我们应该搭配$set使用,指定更新对应的键值。
举个栗子:
原有内容:
{
"_id" : ObjectId("5b66f05f1194e110103bc283"),
"name": "xianyuplus",
"age": "40"
}
# 将name为xianyuplus的值更新为xianyuplus1
db.xianyu.update({name:"xianyuplus"},{$set:{name:"xianyuplus1"}})
操作后内容:
{
"_id" : ObjectId("5b66f05f1194e110103bc283"),
"name": "xianyuplus1",
"age": "40"
}
更新多条数据:使用参数multi:true
举个栗子:
# 更新全部数据的name值为xianyuplus1
db.stu.update({},{$set:{name:"xianyuplus1"}},{multi:true})
注意:multi update only works with $ operators 即multi只要和$搭配使用时才能起效。
删除
删除数据:db.集合名称.remove(<query>,{justOne: <boolean>})
参数query:可选,删除的文档的条件
参数justOne:可选,如果设为true或1,则只删除一条,默认fals,表示删除多条
举个栗子:
# 把name值为xianyuplus的数据全部删掉
db.xianyu.remove({name:"xianyuplus"})
mongodb高级查询
mongodb查询方法
查询文档:db.集合名称.find({条件文档})db.集合名称.findOne({条件文档})db.集合名称.find({条件文档}).pretty()
举个栗子:
# 查询name为xianyuplus的数据
db.xianyu.find({name:"xianyuplus"})
# 查询一条name为xianyuplus的数据
db.xianyu.findOne({name:"xianyuplus"})
mongodb的比较运算符
等于:如上述栗子$gt ( greater than )$gte ( greater than equal )$lt ( less than )$lte ( less than equal )$nt ( not equal )
举个栗子:
# 查询age大于20的数据
db.xianyu.find({age:{$gt:20}})
# 查询age大于等于20的数据
db.xianyu.find({age:{$gte:20}})
# 查询age小于20的数据
db.xianyu.find({age:{$lt:20}})
# 查询age小于等于20的数据
db.xianyu.find({age:{$lte:20}})
# 查询age不等于20的数据
db.xianyu.find({age:{$ne:20}})
mongodb逻辑运算符
and:在find条件文档中写入多个字段条件即可$or
举个栗子:
#查找name为xianyuplus且age为20的数据
db.xianyu.find({name:"xianyuplus",age:20})
#查找name为xianyuplus或age为20的数据
db.xianyu.find({$or:[{name:"xianyuplus"},{age:20}]})
#查找name为xianyuplus或age大于20的数据
db.xianyu.find({$or:[{age:{$gt:20}},{name:"xianyuplus"}]})
#查找age大于等于20或gender为男并且name为xianyuplus的数据
db.xianyu.find({$or:[{gender:"true"},{age:{$gte:18}}],name:"xianyuplus"})
mongodb范围运算符
使用$in与$nin判断是否在某一范围内
举个栗子:
#查询年龄为18、28的数据
db.xianyu.find({age:{$in:[]18,28}})
mongodb使用正则表达式
使用//或$regex编写正则表达式
举个栗子:
# 查询name以xian开头的数据
db.xianyu.find({name:/^xianyu/})
db.xianyu.find({name:{$regex:'^xianyu'}})
mongodb分页与跳过
查询前n条数据:db.集合名称.find().limit(NUMBER)
跳过n条数据:db.集合名称.find().skip(NUMBER)
举个栗子:
#查询前3条数据
db.xianyu.find().limit(3)
#查询3条后的数据
db.xianyu.find().skip(3)
#skip和limit可以搭配使用,查询4,5,6条数据
db.xianyu.find().skip(3).limit(3)
mongodb自定义查询
使用$where自定义查询,这里使用的是js语法
举个栗子:
//查询age大于30的数据
db.xianyu.find({
$where:function() {
return this.age>30;}
})
mongodb投影
投影:在查询结果中只显示你想要看到的数据字段内容。
db.集合名称.find({},{字段名称:1,...})
想显示的字段设置为1,不想显示的字段不设置,而_id这个字段比较特殊,想要他不显示需要设置_id为0。
#查询结果中只显示name字段,不显示age
db.xianyu.find({},{name:1})
mongodb排序
排序:db.集合名称.find().sort({字段:1,...})
将需要排序的字段设置值:升序为1,降序为-1
举个栗子:
#先按照性别降序排列再按照年龄升序排列
db.xianyu.find().sort({gender:-1,age:1})
mongodb计数
统计数目:db.集合名称.find({条件}).count()db.集合名称.count({条件})
举个栗子:
#查询age为20的数据个数
db.xianyu.find({age:20}).count()
#查询age大于20,且性别为nan的数据个数
db.xianyu.count({age:{$gt:20},gender:true})
mongodb去重
去重:db.集合名称.distinct('去重字段',{条件})
举个栗子:
#去除家乡相同,且年龄大于18的数据
db.xianyu.distinct('hometown',{age:{$gt:18}})
mongodb管道与聚合
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
用法:db.集合名称.aggregate({管道:{表达式}})
常用管道:
$group: 将集合中的文档分组, 可用于统计结果
$match: 过滤数据, 只输出符合条件的文档
$project: 修改输出文档的结构, 如重命名、 增加、 删除字段、 创建计算结果
$sort: 将输出文档排序后输出
$limit: 限制聚合管道返回的文档数
$skip: 跳过指定数量的文档, 并返回余下的文档
$unwind: 将数组类型的字段进行拆分
常用表达式:表达式:"列名"
$sum: 计算总和, $sum:1 表示以一倍计数
$avg: 计算平均值
$min: 获取最小值
$max: 获取最大值
$push: 在结果文档中插入值到一个数组中
$first: 根据资源文档的排序获取第一个文档数据
$last: 根据资源文档的排序获取最后一个文档数据
聚合之$group
group:将文档进行分组以便于统计数目
用法:_id表示分组依据,_id:"$字段名"
举个栗子:
#按照hometown分组,并计数
db.xianyu.aggregate({$group:{_id:"$hometown", count:{$sum:1}}})
#将集合中所有的内容分为一组,统计个数
db.xianyu.aggregate({$group:{_id:null, count:{$sum:1}}})
聚合之$project
project:修改输入文档的结构,如:重命名,增加、删除字段等
举个栗子:
#按照hometown分组,并计数
#分组输出,只显示count字段
db.xianyu.aggregate(
{$group:{_id:"$hometown", count:{$sum:1}}},
{$project:{_id:0,count:1}}
)
聚合之$match
match:用于过滤数据,只输出符合条件的文档,功能和find类似,但是match是管道命令,能将结果交给后一个管道,但是find不可以。
举个栗子:
#查询age大于20
#按照hometown分组,并计数
#分组输出,只显示count字段
db.xianyu.aggregate(
{$match:{age:{$gte:20}}},
{$group:{_id:"$hometown", count:{$sum:1}}},
{$project:{_id:0,count:1}}
)
聚合之$sort
sort:将输入文档排序后输出
举个栗子:
#查询age大于20
#按照hometown分组,并计数
#分组输出,只显示count字段
#按照计数升序排序
db.xianyu.aggregate(
{$match:{age:{$gte:20}}},
{$group:{_id:"$hometown", count:{$sum:1}}},
{$project:{_id:0,count:1}},
{$sort:{count:1}}
)
聚合之$limit与$skip
limit:限制聚合管道返回的文档数
skip:跳过指定数量的文档数,返回剩下的文档
举个栗子:
#查询age大于20
#按照hometown分组,并计数
#按照计数升序排序
#跳过前一个文档,返回第二个
db.xianyu.aggregate(
{$match:{age:{$gte:20}}},
{$group:{_id:"$hometown", count:{$sum:1}}},
{$sort:{count:1}},
{$skip:1},
{$limit:1}
)
聚合之$unwind
unwind:将文档中的某一个数组类型字段拆分成多条, 每条包含数组中的一个值
db.集合名称.aggregate({$unwind:'$字段名称'})
举个栗子:
db.xianyu.insert({_id:1,item:'t-shirt',size:['S','M','L']})
db.xianyu.aggregate({$unwind:'$size'})
输出:
{ "_id" : 1, "item" : "t-shirt", "size" : "S" }
{ "_id" : 1, "item" : "t-shirt", "size" : "M" }
{ "_id" : 1, "item" : "t-shirt", "size" : "L" }
聚合使用注意事项
$group对应的字典中有几个键,结果中就有几个键分组依据需要放到
_id后面取不同的字段的值需要使用$,
$gender,$age取字典嵌套的字典中的值的时候
$_id.country能够同时按照多个键进行分组
{$group:{_id:{country:"$字段",province:"$字段"}}}
mongodb索引
用法:db.集合.ensureIndex({属性:1}),1表示升序, -1表示降序
创建唯一索引:db.集合.ensureIndex({"属性":1},{"unique":true})db.集合.ensureIndex({"属性":1},{"unique":true,"dropDups":true})
建立联合索引:db.集合.ensureIndex({属性:1,age:1})db.集合.getIndexes()db.集合.dropIndex('索引名称')
mongodb数据备份与恢复
mongodb数据备份
备份:mongodump -h dbhost -d dbname -o dbdirectory
-h: 服务器地址,也可以指定端口号
-d: 需要备份的数据库名称
-o: 备份的数据存放位置,此目录中存放着备份出来的数据
mongodb数据恢复
恢复:mongorestore -h dbhost -d dbname --dir dbdirectory
-h: 服务器地址
-d: 需要恢复的数据库实例
--dir: 备份数据所在位置
mongodb与python交互
安装与导入
安装:pip install pymongofrom pymongo import MongoClient
实例化
实例化对象以链接数据库,连接对象有host,port两个参数。
from pymongo import MongoClient
class clientMongo:
def __init__(self):
client = MongoClient(host="127.0.0.1", port=27017)
#使用[]括号的形式选择数据库和集合
self.cliention = client["xianyu"]["xianyuplus"]
插入数据
插入单条数据:返回ObjectId
def item_inser_one(self):
ret = self.cliention.insert({"xianyu":"xianyuplus","age":20})
print(ret)
插入多条数据:
def item_insert_many(self):
item_list = [{"name":"xianyuplus{}".format(i)} for i in range(10000)]
items = self.cliention.insert_many(item_list)
查询数据
查询单条数据:
def item_find_one(self):
ret = self.cliention.find_one({"xianyu":"xianyuplus"})
print(ret)
查询多条数据:
def item_find_many(self):
ret = self.cliention.find({"xianyu":"xianyuplus"})
for i in ret:
print(i)
更新数据
更新一条数据:
def item_update_one(self):
self.cliention.update_one({"xianyu":"xianyuplus"},{"$set":{"xianyu":"xianyu"}})
更新全部数据:
def item_update(self):
self.cliention.update_many({"xianyu":"xianyuplus"},{"$set":{"xianyu":"xianyu"}})
删除数据
删除一条数据:
def item_delete_one(self):
self.cliention.delete_one({"xianyu":"xianyuplus"})
删除符合条件的数据:
def item_delete_many(self):
self.cliention.delete_many({"xianyu":"xianyuplus"})
尾言
以上就是关于mongodb的一些用法,重点部分还是mongo高级查询以及聚合管道,一定要review几遍才记得住,本篇是python数据库交互的最后一篇,希望对你有所帮助。
版权声明:本文最终解释权及版权为公众号:咸鱼普拉思 所有,欢迎大家关注咸鱼普拉思,共同学习,一起进步。
往期精彩
进学习交流群
扫码加X先生微信进学习交流群


温馨提示
欢迎大家转载,转发,留言,点赞支持X先生。
文末广告点一下也是对X先生莫大的支持。
做知识的传播者,随手转发。

最后
以上就是喜悦银耳汤最近收集整理的关于教科书式数据库学习:带你学会三大主流数据库的全部内容,更多相关教科书式数据库学习内容请搜索靠谱客的其他文章。








发表评论 取消回复