类似正则获取字符串匹配内容的简单方法,方法比较简单,使用也很方便,功能还很有限
说明:见代码开始的注释,有不清楚的地方,可以留言给我,欢迎指错,提供好方法
本例是以http://www.3444.cc/List/List_4.htm获取内容页地址为例的
<?php
/*
函数canshujiequ($yuanma,$canshustr,$mubiao)说明:
功能:类似正则获取内容,功能比正则简单,可以说是正则功能的一小部分却经常用的功能,就是实现通配符和自定义的方式获取匹配的内容,放在数组中
参数说明:
$yuanma-----要从中获取内容的字符串;
$canshustr-----根据$yuanma李德内容规律,设置的字符串:可以使用通配符(*),包含[参数],[参数是提取的需要信息;
$mubiao---------组合后的字符串;
类似火车头采集器的自定义时的设置方法,本函数也是参考火车头的那部分的设置
实现方法:不断的查询匹配的位置,以一个为单元,获取后,字符串查询移到器后开始查询,直到字符串尾部
返回类型:数组,包含匹配的字符串
*/
set_time_limit(0);
//循环截取函数定义开始
function canshujiequ($yuanma,$canshustr,$mubiao)
{if($yuanma=='')return array();
if(strpos($canshustr,'[参数]')==false||strpos($mubiao,'[参数1]')==false)
{echo '参数或组合字符串格式不对'; return array();}
$chaxunwz=0;
$canshuarr=array();
$canshuarr=explode('[参数]',$canshustr);
//echo '参数分割后的数组:';
//print_r($canshuarr);
//echo '<br/><br/>';
$len1=count($canshuarr);
$pipeiarr=array();
$tpfarr=array();
$qianks=0;
$qianjs=0;
$nowks=0;
$nowjs=0;
$end=0;
$num=0;
while(($end==0)&&($chaxunwz<strlen($yuanma))){
$mubiaofuben=$mubiao;
$feikong=0;
for($i=0;($end==0)&&($i<$len1);$i++){
if($canshuarr[$i]=='')continue;
$feikong++;
$tpfarr=explode('(*)',$canshuarr[$i]);
$len2=count($tpfarr);
$feikongnum=0;
for($j=0;($j<$len2)&&($end==0);$j++){
if($tpfarr[$j]=='')continue;
$feikongnum++;
if($chaxunwz>=strlen($yuanma)){$end=1;break;}
if(($pipeiwz=strpos($yuanma,$tpfarr[$j],$chaxunwz))!==false){
$chaxunwz=$pipeiwz+strlen($tpfarr[$j]);
if($feikongnum==1)$nowks=$pipeiwz;
$nowjs=$chaxunwz;
}
else{$end=1;break;}
}
if($end==0){if($feikong>1){
$str=substr($yuanma,$qianjs,$nowks-$qianjs);
$mubiaofuben=str_replace('[参数'.($feikong-1).']',$str,$mubiaofuben);
//echo '替换[参数'.($feikong-1).']<br/>';
}
$qianks=$nowks;
$qianjs=$nowjs;
}
else{//echo '没有匹配了<br/>';
break;}
}
if($end==0){
$pipeiarr[]=$mubiaofuben;
//echo '第'.($num+1).'条结果:'.$pipeiarr[$num].'<br/>';
$num++;
}
}
//echo "最后的匹配数组:";
//print_r($pipeiarr);
return $pipeiarr;
}//循环截取函数定义结束
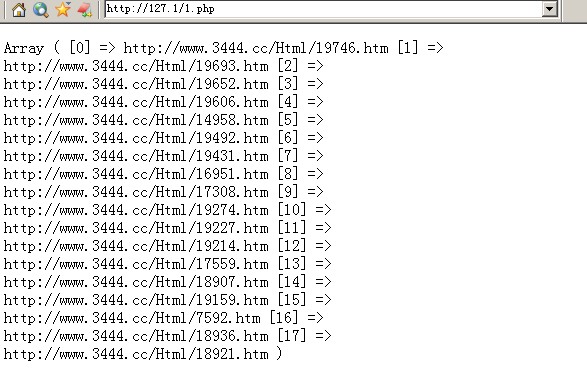
//下面是一个测试的例子,获取网页源码,从中匹配电影的内容页地址
$url='http://www.3444.cc/List/List_4.htm';//获取源码,用上面的匹配函数获得需要的内容页网址
$yuanma=file_get_contents($url);
$canshustr='<li>
<a href="/[参数]" target="_blank">';//函数第1个参数,源码里德地址形式
$mubiaostr='http://www.3444.cc/[参数1]';//第2个参数,组合后的地址
$jieguo=canshujiequ($yuanma,$canshustr,$mubiaostr);//返回匹配的数组
print_r($jieguo);//打印查看获取的效果
?>
最后
以上就是眼睛大薯片最近收集整理的关于php 类似正则获取字符串匹配内容的简单方法的全部内容,更多相关php内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复