Go和Java作为在世界上影响巨大的两门开发语言,在语言特点和应用领域上都存在共通和相似之处。Go从2009年开源至今,在docker、K8s、企业后台等领域都取得了非凡的影响。本文以Golang的主要feature为研究对象,共分为6个章节,在学习这些特性的同时,给出其在Java中对应的实现方式,并会详细分析其中的原理和差异。
1.接口
在面向对象语言中,接口是一个绕不开的话题和特性,我们首先通过一段代码来看一下Go中的接口是如何设计和使用的。
go的实现代码
1、在代码中定义了两个结构体:Teacher和Student;
2、定义了一个接口:Person,接口中声明了一个方法:notice();
3、在Teacher和Student中都存在notice()方法的实现,并且方法签名与Person中的notice()一致;
4、main包中的全局函数sendMsg(p Person) ,通过输入参数为Person的接口,来调用实现Person接口的notice方法;
5、函数sendMsg(p Person),是一个通过接口实现的多态应用;
package main
import "fmt"
type Teacher struct {
Name string
}
type Student struct {
Name string
}
type Person interface {
notice()
}
func (t Teacher) notice() {
fmt.Println(t.Name, "hello")
}
func (s Student) notice() {
fmt.Println(s.Name, "hello")
}
//sendMsg接收一个实现了Person接口的struct
func sendMsg(p Person) {
p.notice()
}
func main() {
t := Teacher{"Teacher Liu"}
s := Student{"Student Li"}
sendMsg(t)
sendMsg(s)
}
Java的实现代码
1、Java中至少需要3个文件来实现;
2、Java使用interface关键字来定义接口;
3、Java在类中使用implements关键字来显式的实现接口;
4、Java中的方法是定义在Class里面的;
5、Person.java中定义Person接口代码;
6、Teacher.java中定义Teacher类;
7、Student.java中定义Student类和main方法等;
public interface Person {
public void notice();
}
public class Teacher implements Person{
public String name;
public Teacher(String name){
this.name = name;
}
@Override
public void notice() {
System.out.println(name+" hello");
}
}
public class Student implements Person{
public String name;
public Student(String name){
this.name = name;
}
@Override
public void notice() {
System.out.println(name+" hello");
}
public static void sendMsg(Person p){
p.notice();
}
public static void main(String[] args){
Teacher t = new Teacher("Teacher Liu");
Student s = new Student("Student Li");
sendMsg(t);
sendMsg(s);
}
}
接口小结
1、Go中使用 type interface方式定义,Java使用interface关键字来定义接口;
2、Go的接口是隐式实现,没有类似于Java中implements的明确方式,只要struct中的方法覆盖了接口的所有方法,便可以认定struct实现了接口;
3、Go支持空接口,任何类都默认实现了空接口;
4、Go的接口实现更加灵活;
5、Java中的方法是定义在Class里面的;
2.继承
下面的内容是wikipedia关于继承概念的解释:
继承(英语:inheritance)是面向对象软件技术当中的一个概念。如果一个类别B“继承自”另一个类别A,就把这个B称为“A的子类”,而把A称为“B的父类别”也可以称“A是B的超类”。继承可以使得子类具有父类别的各种属性和方法,而不需要再次编写相同的代码。在令子类别继承父类别的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类别的原有属性和方法,使其获得与父类别不同的功能。另外,为子类追加新的属性和方法也是常见的做法。一般静态的面向对象编程语言,继承属于静态的,意即在子类的行为在编译期就已经决定,无法在运行期扩展。有些编程语言支持多重继承,即一个子类可以同时有多个父类,比如C++编程语言;而在有些编程语言中,一个子类只能继承自一个父类,比如Java编程语言,这时可以透过实现接口来实现与多重继承相似的效果。现今面向对象程序设计技巧中,继承并非以继承类别的“行为”为主,而是继承类别的“类型”,使得组件的类型一致。另外在设计模式中提到一个守则,“多用合成,少用继承”,此守则也是用来处理继承无法在运行期动态扩展行为的遗憾。
在Go中其实是没有继承的,但是我们可以通过匿名组合来实现继承的效果。下面的Go代码中通过匿名组合的方式来实现了继承的效果。
1、定义了两个“父类”,Person和Job;
2、定义了一个“子类”,Teacher;
3、Person中有一个方法ShowName(),Job中有一个方法ShowJob(),Teacher中也有一个ShowName方法;
4、在Struct Teacher中,通过匿名组合的方法,实现了Teacher继承自Person和Job;
package main
import (
"fmt"
)
type Person struct{}
type Job struct{}
func (p *Person) ShowName() {
fmt.Println("I'm a person.")
}
func (j *Job) ShowJob() {
fmt.Println("I'm a job.")
}
type Teacher struct {
Person
Job
}
func (t *Teacher) ShowName() {
fmt.Println("Teacher Liu.")
}
func main() {
t := Teacher{}
t.Person.ShowName()
t.ShowName()
t.ShowJob()
}
输出内容为
I'm a person.
Teacher Liu.
I'm a job.
继承小结
1、Go中使用匿名引入的方式来实现struct继承;
2、Go中“子类”方法如何和“父类”方法重名(匿名对象和外层对象的方法重名),默认优先调用外层方法;
3、Go中可以指定匿名struct以调用内层方法;
4、Go使用组合的方式,实现了多重继承;
3.闭包
维基百科中关于闭包的解释:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是在支持头等函数的编程语言中实现词法绑定的一种技术。闭包在实现上是一个结构体,它存储了一个函数(通常是其入口地址)和一个关联的环境(相当于一个符号查找表)。环境里是若干对符号和值的对应关系,它既要包括约束变量(该函数内部绑定的符号),也要包括自由变量(在函数外部定义但在函数内被引用),有些函数也可能没有自由变量。 闭包跟函数最大的不同在于,当捕捉闭包的时候,它的自由变量会在捕捉时被确定,这样即便脱离了捕捉时的上下文,它也能照常运行。捕捉时对于值的处理可以是值拷贝,也可以是名称引用,这通常由语言设计者决定,也可能由用户自行指定(如C++)。
Java 中的闭包
Java8之前的闭包支持主要是依靠匿名类来实现的
public class ClosureBeforeJava8 {
int y = 1;
public static void main(String[] args) {
final int x = 0;
ClosureBeforeJava8 closureBeforeJava8 = new ClosureBeforeJava8();
Runnable run = closureBeforeJava8.getRunnable();
new Thread(run).start();
}
public Runnable getRunnable() {
final int x = 0;
Runnable run = new Runnable() {
@Override
public void run() {
System.out.println("local varable x is:" + x);
//System.out.println("member varable y is:" + this.y); //error
}
};
return run;
}
Java8对于闭包的支持
public class ClosureInJava8 {
int y = 1;
public static void main(String[] args) throws Exception{
final int x = 0;
ClosureInJava8 closureInJava8 = new ClosureInJava8();
Runnable run = closureInJava8.getRunnable();
Thread thread1 = new Thread(run);
thread1.start();
thread1.join();
new Thread(run).start();
}
public Runnable getRunnable() {
final int x = 0;
Runnable run = () -> {
System.out.println("local varable x is:" + x);
System.out.println("member varable y is:" + this.y++);
};
return run;
}
}
Java闭包小结
1、通过lamda表达式的方式可以实现函数的封装,并可以在jvm里进行传递;
2、lamda表达式,可以调用上层的方法里的局部变量,但是此局部变量必须为final或者是effectively final,也就是不可以更改的(基础类型不可以更改,引用类型不可以变更地址);
3、lamda表达式,可以调用和修改上层方法所在对象的成员变量;
Golang 中的闭包
package main
import "fmt"
func main() {
ch := make(chan int ,1)
ch2 := make(chan int ,1)
fn := closureGet()
go func() {
fn()
ch <-1
}()
go func() {
fn()
ch2 <-1
}()
<-ch
<-ch2
}
func closureGet() func(){
x := 1
y := 2
fn := func(){
x = x +y
fmt.Printf("local varable x is:%d y is:%d n", x, y)
}
return fn
}
代码输出如下:
local varable x is:3 y is:2
local varable x is:5 y is:2
下面的代码中会输出什么?
package main
import (
"fmt"
)
func main() {
res := closure()
fmt.Println(res) //0x49a880 返回内层函数函数体地址
r1 := res() //执行closure函数返回的匿名函数
fmt.Println(r1) //1
r2 := res()
fmt.Println(r2) //2
//普通的函数应该返回1,而这里存在闭包结构所以返回2 。
//一个外层函数当中有内层函数,这个内层函数会操作外层函数的局部变量,并且外层函数把内层函数作为返回值,则这里内层函数和外层函数的局部变量,统称为闭包结构。这个外层函数的局部变量的生命周期会发生改变,不会随着外层函数的结束而销毁。
//所以上面打印的r2 是累计到2 。
res2 := closure() //再次调用则产生新的闭包结构 局部变量则新定义的
fmt.Println(res2)
r3 := res2()
fmt.Println(r3)
}
//定义一个闭包结构的函数 返回一个匿名函数
func closure() func() int { //外层函数
//定义局部变量a
a := 0 //外层函数的局部变量
//定义内层匿名函数 并直接返回
return func() int { //内层函数
a++ //在匿名函数中将变量自增。内层函数用到了外层函数的局部变量,此变量不会随着外层函数的结束销毁
return a
}
}
Go闭包小结
1、Go的闭包在表达形式上,理解起来非常容易,就是在函数中定义子函数,子函数可以使用上层函数的变量;
2、Go的封装函数可以没有限制的使用上层函数里的自由变量,并且在不同的Goroutine里修改的值,都会有所体现;
3、在闭包(fn和fn2)被捕捉时(return fn,fn2),自由变量(x和y)也被确定了,此后不再依赖于被捕捉时的上下文环境(函数closureGet());
4.channel VS BlockingQueue
Go channel
不要通过共享内存来通信,而应该通过通信来共享内存
Go提供一种基于消息机制而非共享内存的通信模型。消息机制认为每个并发单元都是自包含的独立个体,并且拥有自己的变量,但在不同并发单元间这些变量不共享。每个并发单元的输入和输出只有一种,那就是消息。channel是Golang在语言级提供的Goroutine间的通信方式,可以使用channel在两个或多个Goroutine之间传递消息。channel是类型相关的,即一个channel只能传递一种类型的值,需要在声明channel时指定。可以认为channel是一种类型安全的管道。下面是channel的声明和定义的相关代码:
// 声明一个channel
var chanName chan ElementType
// 定义一个无缓冲的channel
chanName := make(chan ElementType)
// 定义一个带缓冲的channel
chanName := make(chan ElementType, n)
// 关闭一个channel
close(chanName)
1、向无缓冲的channel写入数据会导致该Goroutine阻塞,直到其他Goroutine从这个channel中读取数据。
2、向带缓冲的且缓冲已满的channel写入数据会导致该Goroutine阻塞,直到其他Goroutine从这个channel中读取数据。
3、向带缓冲的且缓冲未满的channel写入数据不会导致该Goroutine阻塞。
4、从无缓冲的channel读出数据,如果channel中无数据,会导致该Goroutine阻塞,直到其他Goroutine向这个channel中写入数据。
5、从带缓冲的channel读出数据,如果channel中无数据,会导致该Goroutine阻塞,直到其他Goroutine向这个channel中写入数据。
6、从带缓冲的channel读出数据,如果channel中有数据,该Goroutine不会阻塞。
总结:
无缓冲的channel读写通常都会发生阻塞,带缓冲的channel在channel满时写数据阻塞,在channel空时读数据阻塞。
package main
import "fmt"
import "time"
func main() {
timeout := make(chan bool)
go func() {
time.Sleep(3 * time.Second) // sleep 3 seconds
timeout <- true
}()
// 实现了对ch读取操作的超时设置。
ch := make(chan int)
select {
case <-ch:
case <-timeout:
fmt.Println("timeout!")
}
}
1、Golang中的select关键字用于处理异步IO,可以与channel配合使用;
2、Golang中的select的用法与switch语法非常类似,不同的是select每个case语句里必须是一个IO操作;
3、select会一直等待等到某个case语句完成才结束;
在上面的代码中,我们用到了select来实现了读取channel超时的处理,那么,我们能不能使用select来进行发送消息的超时处理呢?
package main
import "fmt"
import "time"
func main() {
timeout := make(chan bool)
go func() {
time.Sleep(3 * time.Second) // sleep 3 seconds
timeout <- true
}()
// 实现了对ch写取操作的超时设置。
ch := make(chan int)
select {
case ch <-1 :
fmt.Println("send message success.")
case <-timeout:
fmt.Println("timeout!")
}
}
switch是可以有default语句的,那么select是否也有default的语句呢?
package main
import "fmt"
import "time"
func main() {
timeout := make(chan bool)
go func() {
time.Sleep(3 * time.Second) // sleep 3 seconds
timeout <- true
}()
// 实现了对ch写取操作的超时设置。
ch := make(chan int)
select {
case ch <-1 :
fmt.Println("send message success.")
case <-timeout:
fmt.Println("timeout!")
default :
fmt.Println("default case.")
}
}
Java BlockingQueue
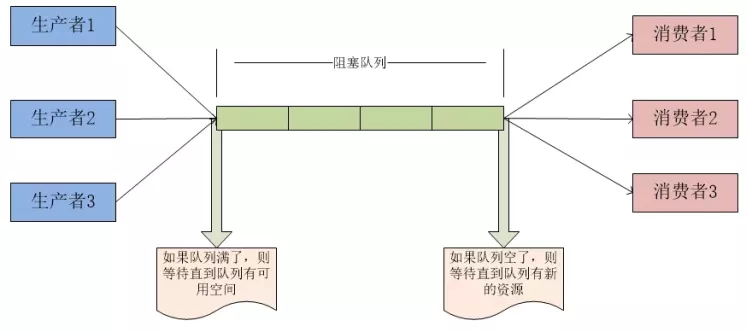
在Java中,BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、 LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等,它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于take与put操作的原理,却是类似的。
生产者:
1、offer(E e):如果队列没满,立即返回true;如果队列满了,立即返回false;
2、put(E e):如果队列满了,一直阻塞,直到队列不满了或者线程被中断;
3、offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,如果队列已满,则进入等待,直到出现以下三种情况:等待时间超时、当前线程被中断、队列中的部分元素被消费;
消费者:
1、poll():如果没有元素,直接返回null;如果有元素,出队。不会阻塞当前线程;
2、take():如果队列空了,一直阻塞,直到队列不为空或者线程被中断;
3、poll(long timeout, TimeUnit unit):如果队列不空,出队;如果队列已空且已经超时,返回null;如果队列已空且时间未超时,则进入等待,直到出现以下三种情况:等待时间超时、当前线程被中断、队列中出现了新的元素;
小结:
1、Go channel 和 Java BlockingQueue 都是实现生产者和消费者模式;
2、channel是在语言层面的实现,BlockingQueue是在sdk层面的支持;
3、Java程序使用线程池,要注意设置队列的大小,否则无界队列容易使得内存被耗光直到程序崩溃;
4、使用put和offer(E e, long timeout, TimeUnit unit)必须要做好防护,防止因为消费慢而造成的阻塞主线程的情况发生;
5.并发数据结构
1、Java 并发数据结构:ConcurrentHashMap、CopyOnWriteArraySet、ConcurrentLinkedQueue、BlockingQueue、ConcurrentSkipListMap...
2、Go 并发数据结构:sync.Map
接下来,我拿两个数据库产品做了一些对比,一个是Golang+rust写的TiDB,另一个是Java写的ElasticSearch。
读写锁
在ES中只有11个地方使用到了读写锁,而TiDB(TiDB的计算模块)和PD(TiDB的调度模块)中有较多的地方使用到了读写锁。下面的代码是PD中在获取当前的region所在的leader store的源码:
// GetLeaderStore returns all Stores that contains the region's leader peer.
func (bc *BasicCluster) GetLeaderStore(region *RegionInfo) *StoreInfo {
bc.RLock()
defer bc.RUnlock()
return bc.Stores.GetStore(region.GetLeader().GetStoreId())
}
在TiDB和PD中有较多类似于上面的代码部分,在读的时候用读锁,在写的时候用写锁。根本原因,我觉得是Golang中没有对于并发数据结构的支持,那么这些数据一致性和稳定性的保障都留给了业务开发人员,因此在TiDB这样的底层数据库产品里面,会有很多的读写锁场景出现。
并发场景下使用map
map是我们在编码过程一定会使用到的数据结构,在jdk1.5之前的时代,如果因为HahsMap使用不当,在并发环境下,一定会出现死链的情况,间接的造成了程序的崩溃。同理在Golang中,我们在并发环境下使用普通的map时,一定要加读写锁的,否则会造成程序崩溃退出。下面是PD中获取某个store的代码:
// GetStore searches for a store by ID.
func (bc *BasicCluster) GetStore(storeID uint64) *StoreInfo {
bc.RLock()
defer bc.RUnlock()
return bc.Stores.GetStore(storeID)
}
// GetStore returns a copy of the StoreInfo with the specified storeID.
func (s *StoresInfo) GetStore(storeID uint64) *StoreInfo {
store, ok := s.stores[storeID]
if !ok {
return nil
}
return store
}
// StoresInfo contains information about all stores.
type StoresInfo struct {
stores map[uint64]*StoreInfo
}
这段代码如果在Java中,因为jdk底层有大量的并发数据结构的支持,是可以有一些优化点的:
1、bc.RLock() 表明了这个锁的级别是cluster级别的,当我们对于cluster内的所有操作,都需要使用到这个锁,锁的粒度比较粗,我们可以尝试降低锁的粒度;
2、所有一致性和稳定性有可能出问题的地方,都要加锁处理,程序的复杂度过大;
3、在Java语言里面,可以使用ConcurrentHashMap,实现在业务代码中无锁处理;
下面是ES在RestClient中的一段使用ConcurrentHashMap的代码:
private final ConcurrentMap<HttpHost, DeadHostState> blacklist = new ConcurrentHashMap<>();
static Iterable<Node> selectNodes(NodeTuple<List<Node>> nodeTuple, Map<HttpHost, DeadHostState> blacklist,
AtomicInteger lastNodeIndex, NodeSelector nodeSelector) throws IOException {
...
for (Node node : nodeTuple.nodes) {
DeadHostState deadness = blacklist.get(node.getHost());
...
}
...
private void onResponse(Node node) {
DeadHostState removedHost = this.blacklist.remove(node.getHost());
if (logger.isDebugEnabled() && removedHost != null) {
logger.debug("removed [" + node + "] from blacklist");
}
}
private void onFailure(Node node) {
while(true) {
DeadHostState previousDeadHostState =
blacklist.putIfAbsent(node.getHost(), new DeadHostState(DeadHostState.DEFAULT_TIME_SUPPLIER));
...
}
failureListener.onFailure(node);
}
上面的代码体现了在Java中使用到ConcurrentHashmap时:
1、可以做到业务代码层面完全无锁语法,锁是在map内部实现的,简化代码复杂度;
2、ConcurrentHashmap的分段锁机制减少锁的粒度,提升并发性能;
3、通过putIfAbsent方法可以实现如果map中不存在key时,则加入value,否则不进行替换的原子操作;
小结:
1、并发数据结构的支持是在sdk层面的差异,而非语言本身;
2、Java因为有并发大师Doug Lea的concurrent包,在并发数据结构的支持上,是领先于Go等其它语言的;
3、Go中在底层数据结构上实现同样并发性能的程序,对于业务开发程序员的技能要求更高;
4、在Golang中使用底层数据结构,经常需要使用到读写锁,Java中用的比较少;
5、Go中由于在业务代码中经常使用到读写锁,很容易扩大锁的粒度,造成性能的下降;
6.Goroutine VS thread
Go GPM 调度模型
本章节内容,主要来源于Golang布道师 Bill的 Scheduling In Go : Part II - Go Scheduler 当 Go 程序启动时,它会为主机上标识的每个虚拟核心提供一个逻辑处理器(P)。如果处理器每个物理核心可以提供多个硬件线程(超线程),那么每个硬件线程都将作为虚拟核心呈现给 Go 程序。为了更好地理解这一点,下面实验都基于如下配置的 MacBook Pro 的系统。

package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU 返回当前可用的逻辑处理核心的数量
fmt.Println(runtime.NumCPU())
}
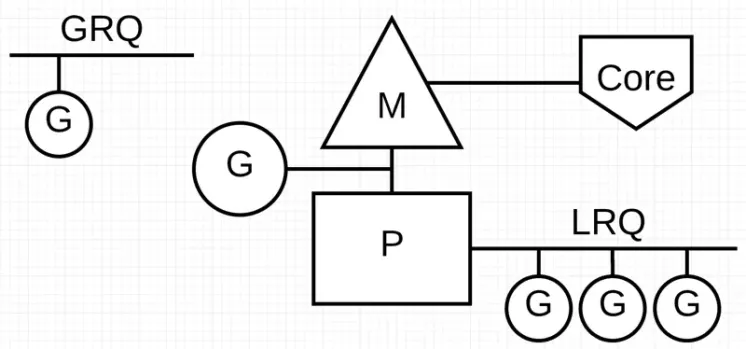
每个 P 都被分配一个系统线程 M 。M 代表机器(machine),它仍然是由操作系统管理的,操作系统负责将线程放在一个核心上执行。这意味着当在我的机器上运行 Go 程序时,有 16 个线程可以执行我的工作,每个线程单独连接到一个P。
每个 Go 程序都有一个初始 G。G 代表 Go 协程(Goroutine),它是 Go 程序的执行路径。Goroutine 本质上是一个 Coroutine,但因为是 Go 语言,所以把字母 “C” 换成了 “G”,我们得到了这个词。你可以将 Goroutines 看作是应用程序级别的线程,它在许多方面与系统线程都相似。正如系统线程在物理核心上进行上下文切换一样,Goroutines 在 M 上进行上下文切换。
最后一个重点是运行队列。Go 调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)。每个 P 都有一个LRQ,用于管理分配给在P的上下文中执行的 Goroutines,这些 Goroutine 轮流被和P绑定的M进行上下文切换。GRQ 适用于尚未分配给P的 Goroutines。其中有一个过程是将 Goroutines 从 GRQ 转移到 LRQ。Go最新的1.14版本中又对GPM调度模型进行了优化,增加了抢占式调度的安全点。
我个人觉得GPM调度模型是Go最精华的内容之一,Java社区对于协程已经呼唤了很多年,但是现在还没有看到能可以在语言层面落地的迹象。
Java thread
在这里,我也列举一些在Java中使用thread的一些小细节:
1、Java线程栈的空间大小默认是1M,从内存的角度讲,jvm也很难管理大量的线程,Goroutine栈空间大小可以做到几k;
2、Java可以使用threadlocal来存储和当前线程关联的内容,例如:log4j、pinpoint、skywalking等框架;
3、Java是有threadid的,Golang是不提供Goroutineid的;
4、因为Java的线程模型,所以我们在编写并发的网络编程时,需要借助netty这样的网络框架;
5、每一个多线程的Java服务,后面一定有各式各样的线程池为它服务;
7.总结
本文通过接口、继承、闭包、Go channel、并发数据结构和协程等6个方面来分别对比分析了Go和Java中对于不同特性的实现方法。并针对闭包、并发数据结构等进行了详细的使用场景和在不同情况下的优缺点进行了对比分析。在Go和Java的语言差异上,肯定不止这6个方面,本文只是选择了在开发过程中,经常遇到的几个方面进行了对比分析。希望能给到对于其中一种语言比较熟悉,但是想要快速学习另一种语言的同学,起到一个思路启发的作用。
参考文章:
https://mp.weixin.qq.com/s/2zSqBAzEqwsCAQitsXycBQ
最后
以上就是俊逸大雁最近收集整理的关于java与go对比(go与java语言区别)1.接口2.继承3.闭包4.channel VS BlockingQueue5.并发数据结构6.Goroutine VS thread7.总结的全部内容,更多相关java与go对比(go与java语言区别)1.接口2.继承3.闭包4.channel内容请搜索靠谱客的其他文章。








发表评论 取消回复