目录
Day20学习内容
1.剑指Offer
面试题15:二进制中1的个数
面试题52:两个链表的第一个公共节点
2.Leetcode
例1:单词划分
例2:数组中只出现一次的数字
3.2018年校招编程题
例1:安排机器
4.2017年阿里巴巴秋招笔试题
例21:问答题-利用互斥设计删除堆元素的接口
5.蘑菇街2019届校招算法笔试题
6.专项训练-机器学习
1.剑指Offer
面试题15:二进制中1的个数
题目描述:输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
方法1:高效方法,循环次数是二进制中1的个数
思路:把一个整数减1再和原来的数做位与操作,相当于把这个数的二进制表示中最右边的1变成0
class Solution {
public:
int NumberOf1(int n) {
int count=0;
while(n){
++count;
n=(n-1)&n;
}
return count;
}
};方法2:常规解法,循环次数是二进制的位数
思路:把n与1做位与,判断最低位是否为1,接着把1左移1位变成2,再和n做位与,判断其次低位是否为1,反复左移....
class Solution {
public:
int NumberOf1(int n) {
int count=0;
unsigned int flag=1;
while(flag){
if(n&flag)
++count;
flag=flag<<1;
}
return count;
}
};补充:
一、正整数的原码、反码、补码完全一样,即符号位固定为0,数值位相同
二、负整数的符号位固定为1,由原码变为补码时,规则如下:
1、原码符号位1不变,整数的每一位二进制数位求反,得到反码
2、反码符号位1不变,反码数值位最低位加1,得到补码
三、求二进制:该数模2得到的余数从后往前排列。
面试题52:两个链表的第一个公共节点
题目描述:输入两个链表,找出它们的第一个公共结点。
代码:
class Solution {
public:
ListNode* FindFirstCommonNode(ListNode* pHead1, ListNode* pHead2) {
unsigned int len1=GetListLength(pHead1);
unsigned int len2=GetListLength(pHead2);
int lendiff=len1-len2;
ListNode* pHeadLong=pHead1;
ListNode* pHeadShort=pHead2;
if(len2>len1){
lendiff=len2-len1;
pHeadLong=pHead2;
pHeadShort=pHead1;
}
for(int i=0;i<lendiff;i++){
pHeadLong=pHeadLong->next;
}
while((pHeadLong!=nullptr)&&(pHeadShort!=nullptr)&&(pHeadLong!=pHeadShort)){
pHeadLong=pHeadLong->next;
pHeadShort=pHeadShort->next;
}
ListNode* pFirstCommonNode=pHeadLong;
return pFirstCommonNode;
}
unsigned int GetListLength(ListNode* pHead){
int len=0;
while(pHead){
++len;
pHead=pHead->next;
}
return len;
}
};
2.Leetcode
例1:单词划分
题目描述:
Given a string s and a dictionary of words dict, determine if s can be segmented into a space-separated sequence of one or more dictionary words.
For example, given
s ="leetcode",
dict =["leet", "code"].
Return true because"leetcode"can be segmented as"leet code".
思路:动态规划,分解成若干子问题的最优解
代码:
class Solution {
public:
bool wordBreak(string s, unordered_set<string> &dict) {
int len=s.length();
vector<bool> v(len+1,false);
v[0]=true;
for(int i=1;i<=len;i++){
for(int j=i-1;j>=0;j--){
if(v[j]&&dict.find(s.substr(j,i-j))!=dict.end()){
v[i]=true;
break;
}
}
}
return v[len];
}
};
例2:数组中只出现一次的数字
题目描述:
Given an array of integers, every element appears twice except for one. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
思路:使用二进制和异或操作,原理是一个数字异或它本身是等于零的。
代码:
class Solution {
public:
int singleNumber(int A[], int n) {
int a=0;
for(int i=0;i<n;i++){
a^=A[i];
}
return a;
}
};
3.2018年校招编程题
例1:安排机器
题目描述:
小Q的公司最近接到m个任务, 第i个任务需要xi的时间去完成, 难度等级为yi。
小Q拥有n台机器, 每台机器最长工作时间zi, 机器等级wi。
对于一个任务,它只能交由一台机器来完成, 如果安排给它的机器的最长工作时间小于任务需要的时间, 则不能完成,如果完成这个任务将获得200 * xi + 3 * yi收益。
对于一台机器,它一天只能完成一个任务, 如果它的机器等级小于安排给它的任务难度等级, 则不能完成。
小Q想在今天尽可能的去完成任务, 即完成的任务数量最大。如果有多种安排方案,小Q还想找到收益最大的那个方案。小Q需要你来帮助他计算一下。
输入描述:
输入包括N + M + 1行, 输入的第一行为两个正整数n和m(1 <= n, m <= 100000), 表示机器的数量和任务的数量。 接下来n行,每行两个整数zi和wi(0 < zi < 1000, 0 <= wi <= 100), 表示每台机器的最大工作时间和机器等级。 接下来的m行,每行两个整数xi和yi(0 < xi < 1000, 0 <= yi<= 100), 表示每个任务需要的完成时间和任务的难度等级。
输出描述:
输出两个整数, 分别表示最大能完成的任务数量和获取的收益。
输入例子1:
1 2 100 3 100 2 100 1
输出例子1:
1 20006
思路:先对机器和任务进行从大到小的贪心排序(先按照时间和等级进行贪心排序,因为时间的影响力比等级大,所以把时间作
为第一排序选择),然后贪心的找符合条件的任务。怎么贪心呢?以任务出发循环,先找出时间大于任务的机器,然后将机器的等级放入cnt[]中,接着以任务的等级为起点,循环找到最近是否有大于此等级的机器。
代码:
#include <bits/stdc++.h>
using namespace std;
const int maxn = 100005;
struct node {
int time, priority;
}machine[maxn], task[maxn];
int cnt[105];
int cmp(node a ,node b){
if(a.time == b.time)return a.priority > b.priority;
return a.time > b.time;
}
int main(){
int n,m;
scanf("%d%d",&n,&m);
for(int i = 0;i < n;i++) scanf("%d%d",&machine[i].time, &machine[i].priority);
for(int i = 0;i < m;i++) scanf("%d%d",&task[i].time, &task[i].priority);
sort(machine, machine + n,cmp);
sort(task, task + m,cmp);
int num = 0;
long long ans = 0;
memset(cnt,0,sizeof(cnt));
int i,j,k;
for(i = 0,j = 0;i < m;i++){
while(j < n && machine[j].time >= task[i].time){
cnt[machine[j].priority]++;
j++;
}
for(k = task[i].priority;k <= 100;k++){
if(cnt[k]){
num++;
cnt[k]--;
ans = ans + 200 * task[i].time +3 * task[i].priority;
break;
}
}
}
printf("%d %lldn",num,ans);
return 0;
}
4.2017年阿里巴巴秋招笔试题
例21:问答题-利用互斥设计删除堆元素的接口
题目描述:设计接口并且实现一个多线程安全的堆,并且要求可以删除堆中任意元素(非堆顶元素),要求尽量高效,假设已有标准的mutex实现可以使用。
代码:
deleteElement(int[] heap, int index, int len){
mutex.lock();
heap[index]=heap[len-1];
--len;
while(index*2+1<len&&(heap[index]>heap[index*2+1]||heap[index]>heap[index*2+2])){
int swapi=heap[index*2+1]<heap[index*2+2]?index*2+1:index*2+2;
swap(heap, index,swapi);
index=swapi;
}
mutex.unlock();
}
5.蘑菇街2019届校招算法笔试题
例1:恰有两个小孩的家庭,若已知一家有一个男孩,则这家小孩都是男孩的概率为?(A)正确答案: A 你的答案: D (错误)
A.1/3 B.1/4 C.1/6 D.1/2
解析:逆概公式;
P(全男|一男)=P(全男)P(一男|全男)/P(一男);
2个孩子的情况有四种可能:男男、男女、女男、女女;
全部男孩的情况下有一个男孩的概率是1;
而P(一男)=;3/4;带进去就可以;得1/3;
例2:操作系统实现内存管理的常使用的数据结构为?(D)正确答案: D 你的答案: D (正确)
A.栈 B.队列 C.数组 D.链表
例3:正负样本采样比从1:1 到1:5, auc的变化会: (D). 正确答案: D 你的答案: B (错误)
A.变大 B.变小 C.不确定 D.不变
解析:ROC相对于PR的优势就是不受正负样本比例的影响,AUC是ROC下的面积
例4:下列哪个优化算法适合稀疏数据:(D)正确答案: D 你的答案: D (正确)
A.sgd+ momentum B.nesterov C.LBFGS D.Adagrad
解析:数据稀疏的话使用自适应的优化算法更好
例5:以下带正则的线性回归模型:
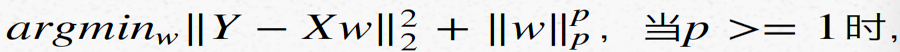
增加会对bias和variance带来什么影响(假设所有weights都大于1)? (B)正确答案: B 你的答案: C (错误)
A.bias增加,variance增加
B.bias增加,variance减小
C.bias减小,variance增加
D.bias减小,variance减小
E.信息不充分,无法判断
解析:p增大则w受抑制程度增大,b相应变大,总体方差变小
6.专项训练-机器学习
例1:一监狱人脸识别准入系统用来识别待进入人员的身份,此系统一共包括识别4种不同的人员:狱警,小偷,送餐员,其他。下面哪种学习方法最适合此种应用需求:(B)。正确答案: B 你的答案: B (正确)
A.二分类问题 B.多分类问题 C.层次聚类问题 D.k-中心点聚类问题 E.回归问题 F.结构分析问题
例2:下列不是SVM核函数的是:(B)正确答案: B 你的答案: B (正确)
A.多项式核函数 B.logistic核函数 C.径向基核函数 D.Sigmoid核函数
解析:
支持向量机是建立在统计学习理论基础之上的新一代机器学习算法,支持向量机的优势主要体现在解决线性不可分问题,它通过引入核函数,巧妙地解决了在高维空间中的内积运算,从而很好地解决了非线性分类问题。
构造出一个具有良好性能的SVM,核函数的选择是关键.核函数的选择包括两部分工作:一是核函数类型的选择,二是确定核函数类型后相关参数的选择.因此如何根据具体的数据选择恰当的核函数是SVM应用领域遇到的一个重大难题,也成为科研工作者所关注的焦点,即便如此,却依然没有得到具体的理论或方法来指导核函数的选取.
1、经常使用的核函数
核函数的定义并不困难,根据泛函的有关理论,只要一种函数 K ( x i , x j ) 满足Mercer条件,它就对应某一变换空间的内积.对于判断哪些函数是核函数到目前为止也取得了重要的突破,得到Mercer定理和以下常用的核函数类型:
(1)线性核函数
K ( x , x i ) = x ⋅ x i
(2)多项式核
K ( x , x i ) = ( ( x ⋅ x i ) + 1 ) d
(3)径向基核(RBF)
K ( x , x i ) = exp ( − ∥ x − x i ∥ 2 σ 2 )
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数 σ 的增大而减弱。多项式形式的核函数具有良好的全局性质。局部性较差。
(4)傅里叶核
K ( x , x i ) = 1 − q 2 2 ( 1 − 2 q cos ( x − x i ) + q 2 )
(5)样条核
K ( x , x i ) = B 2 n + 1 ( x − x i )
(6)Sigmoid核函数
K ( x , x i ) = tanh ( κ ( x , x i ) − δ )
采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。
2、核函数的选择
在选取核函数解决实际问题时,通常采用的方法有:一是利用专家的先验知识预先选定核函数;二是采用Cross-Validation方法,即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数.如针对傅立叶核、RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅立叶核的SVM要比采用RBF核
的SVM误差小很多.三是采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构造核函数的又一开创性的工作.将不同的核函数结合起来后会有更好的特性,这是混合核函数方法的基本思想.
例3:有两个样本点,第一个点为正样本,它的特征向量是(0,-1);第二个点为负样本,它的特征向量是(2,3),从这两个样本点组成的训练集构建一个线性SVM分类器的分类面方程是(C) 正确答案: C 你的答案: D (错误)
A.2x+y=4 B.x+2y=5 C.x+2y=3 D.以上都不对
解析:SVM要找到间隔最大的分类平面,这里即求两点(0,-1),(2,3)的垂直平分线。
求斜率:-1/[(y1-y2)/(x1-x2)]=-1/[(3-(-1))/(2-0)]=-1/2
求中点:((x1+x2)/2,(y1+y2)/2)=((0+2)/2, (-1 + 3)/2)=(1, 1)
最后表达式:x+2y=3.
详细解答参考:
https://www.nowcoder.com/questionTerminal/104e95c6a13d464a86eb6b657cc545c0
首先确定这题出错了,应该是(0,-1)是负样本,(2,3)是正样本,因为必须满足约束条件,(看了好多人解析求斜率过中点求出来的都是碰巧的,之前的答案是C选项此时应该将正负样本颠倒就是这个答案:x+2y=3,但不改的话就是D,已提交反馈给官网订正)
于是必须满足:
min 1/2(w12+w22)
s.t. -1*(0*w1-1*w2+b)>=1
1*(2*w1+3*w2+b)>=1
这样联立方程组可以解出w1=1/5,w2=2/5,b= -3/5,所以就是答案三
补充:直线方程有很多种
点斜式:y-y0=k(x-x0),斜率就是k
斜截式:y=kx+b,斜率也是k
两点式:(x-x1)/(x2-x1)=(y-y1)/(y2-y1)斜率为(y2-y1)/(x2-x1)
一般式:Ax+By+C=0,斜率为-a/b,
这些就是常用的直线方程的斜率
例4:以下哪些方法不可以直接来对文本分类?正确答案: A 你的答案: A (正确)
A.Kmeans B.决策树 C.支持向量机 D.KNN
解析:Kmeans是聚类方法,典型的无监督学习方法。分类是监督学习方法,BCD都是常见的分类方法
K-means算法,主要分为赋值阶段和更新阶段。算法步骤:(1)随机选择K个点作为初始的质心(2)将每个点指配到最近的质心(3)重新计算簇的质心,直到质心不再发生变化 。K均值容易陷入局部最小值,无法表示类的形状,大小和宽度,是一种硬分类算法,针对它的这些缺点,提出了二分K均值和软K均值。
例5:关于线性回归的描述,以下正确的有: (BCE)正确答案: B C E 你的答案: A (错误)
A.基本假设包括随机干扰项是均值为0,方差为1的标准正态分布
B.基本假设包括随机干扰项是均值为0的同方差正态分布
C.在违背基本假设时,普通最小二乘法估计量不再是最佳线性无偏估计量
D.在违背基本假设时,模型不再可以估计
E.可以用DW检验残差是否存在序列相关性
F.多重共线性会使得参数估计值方差减小
解析:F.多重共线性会使方差增大
一元线性回归的基本假设有
1、随机误差项是一个期望值或平均值为0的随机变量;
2、对于解释变量的所有观测值,随机误差项有相同的方差;
3、随机误差项彼此不相关;
4、解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
5、解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
6、随机误差项服从正态分布
违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计。
当存在异方差时,普通最小二乘法估计存在以下问题: 参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶 自相关 最常用的方法。
所谓多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。影响
(1)完全共线性下参数估计量不存在
(2)近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
(3)参数估计量经济含义不合理
(4)变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
(5)模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
最后
以上就是勤奋保温杯最近收集整理的关于编程之旅-Day20目录的全部内容,更多相关编程之旅-Day20目录内容请搜索靠谱客的其他文章。








发表评论 取消回复