最近在做问答系统,用CNN深度学习模型分别对问题、正答案和负答案提取特征,得到各自的特征向量。正答案与问题之间的距离比负答案与问题之间的距离要近,距离用夹角的cos值来表示,目标函数是由此确定的。模型出自《Applying Deep Learning To Answer Selection: A Study And An Open Task》,如图1所示。
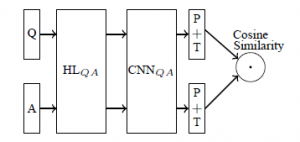
图 1
用tensorflow架构实现该模型,然而做模型优化时,5步以内模型的loss就为0了,精度达到了1,如图2所示。‘
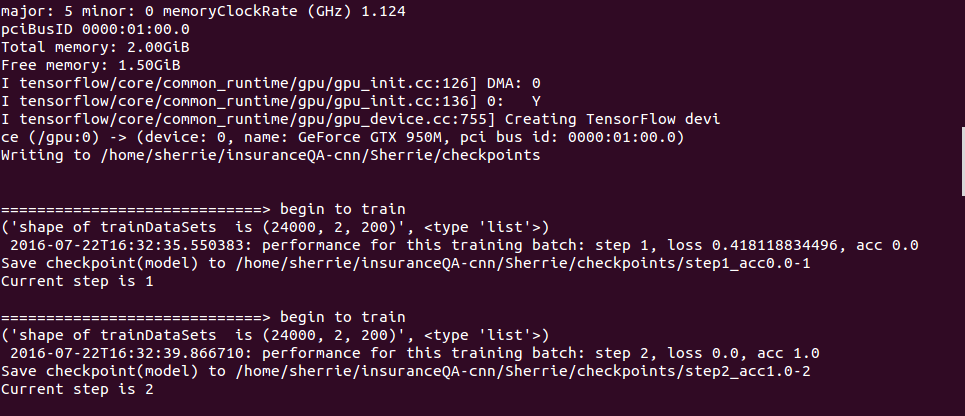
图 2
迷糊了一个星期,才找到问题点。
原来是因为在用CNN做特征提取时,我对三个输入(问题、正答案、负答案)分别做了模型weight初始化,相当于建立了三个CNN分别对问题、正答案、负答案做特征抽取。代码如下,调用了conv函数三遍,初始化了W三次,建立了三个CNN模型。
# define a convolution function
def conv(input_data):
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(input_data, W, strides=[1, 1, 1, 1],
padding="VALID", name="conv")
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
# shape of pooled is [batch_size,1,1,num_filters]
pooled_outputs.append(pooled)
return pooled_outputs
pooled_outputs1=conv(self.embedded_chars1_expanded) # conv-pool outputs
pooled_outputs2=conv(self.embedded_chars2_expanded)
pooled_outputs3=conv(self.embedded_chars3_expanded) 为什么用三个CNN模型做QA系统的答案选择不行呢?此时的模型相当于如下图3的结构。
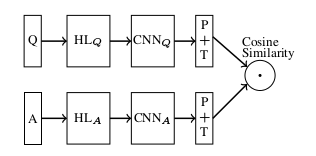
图 3
三个CNN模型分别做特征提取,导致模型对负答案失去约束力,也就是说负答案的卷积神经网络模型使它始终离问题很远(夹角的cos值小),即使此负答案CNN模型的输入是正答案,距离仍然会远(夹角仍然会小)。打个形象的比喻,就像是让负答案乘以0,无论输入怎么变,输出都是零,这样的约束没有了意义。
对代码进行如下修改。
pooled_outputs1 = []
pooled_outputs2 = []
pooled_outputs3 = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(self.embedded_chars1_expanded, W, strides=[1, 1, 1, 1],
padding="VALID", name="conv")
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
# shape of pooled is [batch_size,1,1,num_filters]
pooled_outputs1.append(pooled)
conv = tf.nn.conv2d(self.embedded_chars2_expanded, W, strides=[1, 1, 1, 1],
padding="VALID", name="conv")
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
# shape of pooled is [batch_size,1,1,num_filters]
pooled_outputs2.append(pooled)
conv = tf.nn.conv2d(self.embedded_chars3_expanded, W, strides=[1, 1, 1, 1],
padding="VALID", name="conv")
# print('n--- shape of cov is {}'.format(conv.get_shape()))
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Max-pooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
# shape of pooled is [batch_size,1,1,num_filters]
pooled_outputs3.append(pooled)改过的程序可以正常运行了,准确率和论文描述的相当。
最后
以上就是活泼手套最近收集整理的关于纠错: 深度学习模型优化时快速收敛的全部内容,更多相关纠错:内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复