文章目录
- 一、分段常数衰减 tf.train.piecewise_constan()
- 二、指数衰减 tf.train.exponential_decay()
- 三、自然指数衰减 tf.train.natural_exp_decay()
- 四、多项式衰减 tf.train.polynomial_decay()
- 五、余弦衰减 tf.train.cosine_decay()
- 线性余弦衰减 tf.train.linear_cosine_decay()
- 噪声线性余弦衰减 tf.train.noisy_linear_cosine_decay()
- 六、反时限学习率衰减(倒数)衰减 tf.train.inverse_time_decay()
在TensorFlow训练一个模型时,我们需要通过优化函数来使得我们训练的模型损失值达到最小。
常用的优化算法有随机梯度下降、批量梯度下降等( 更多详情请点击)。在使用优化算法的时候,我们都需要设置一个学习率(learning rate)。我这里总结了一些博主的方法。
学习率 的设置在训练模型的时候也是非常重要的,因为学习率控制了每次更新参数的幅度。(更多详情请点击)
-
学习率太大:就会导致更新的幅度太大,就有可能会跨过损失值的极小值(该极小值有可能是局部的最小值,也可能是全局最小值),最后可能参数的极优值会在参数的极优值之间徘徊,而取不到参数的极优值。
-
学习率太小,就会导致的更新速度太慢,模型收敛慢,从而需要消耗更多的资源来保证获取到参数的极优值。
一、分段常数衰减 tf.train.piecewise_constan()
tf.train.piecewise_constant(x, # 标量,指代训练次数
boundaries, # 学习率参数应用区间列表
values, # 学习率列表,values长度比boundaries长度多一
name=None # 名称
)
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
num_epoch = tf.Variable(0, name='global_step', trainable=False)
boundaries = [10, 20, 30]
learing_rates = [0.1, 0.07, 0.025, 0.0125]
y = []
N = 40
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
learing_rate = tf.train.piecewise_constant(num_epoch, boundaries=boundaries, values=learing_rates)
lr = sess.run([learing_rate])
y.append(lr)
x = range(N)
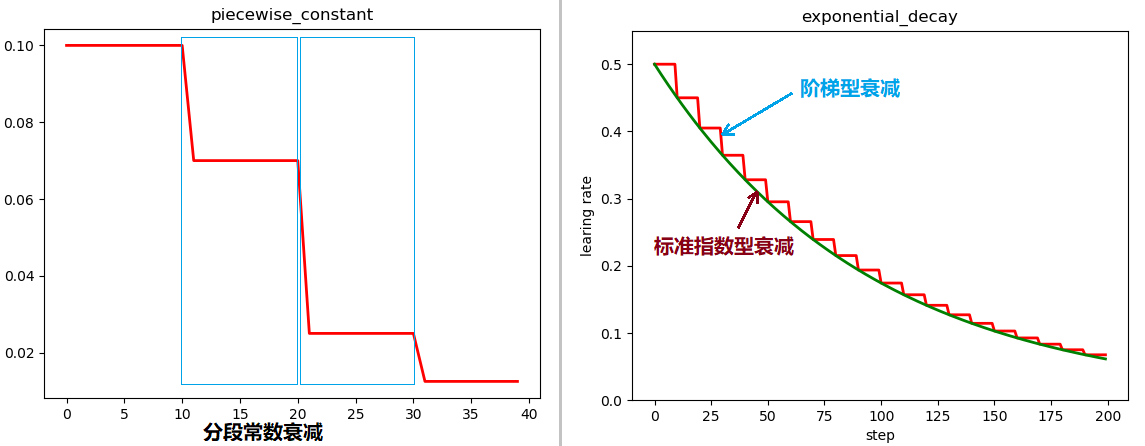
plt.plot(x, y, 'r-', linewidth=2)
plt.title('piecewise_constant')
plt.show() # 展示结果如下图左
二、指数衰减 tf.train.exponential_decay()
指数衰减是比较常用的衰减方法,学习率是跟当前的训练轮次指数相关的。
tf.train.exponential_decay(
learning_rate, # 初始学习率
global_step, # 当前训练轮次,epoch
decay_steps, # 定义衰减周期,跟参数staircase配合,可以在decay_step个训练轮次内保持学习率不变
decay_rate, # 衰减率系数
staircase=False, # 定义(阶梯型衰减 /连续衰减),默认是False,即连续衰减(标准的指数型衰减)
name=None # 操作名称
)
函数返回学习率数值,计算公式是:
d e c a y e d _ l e a r n i n g _ r a t e = l e a r n i n g _ r a t e ∗ d e c a y _ r a t e ( g l o b a l _ s t e p / d e c a y _ s t e p s ) sf decayed_learning_rate = learning_rate *decay_rate ^{ (global_step / decay_steps)} decayed_learning_rate=learning_rate∗decay_rate(global_step/decay_steps)
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
num_epoch = tf.Variable(0, name='global_step', trainable=False)
y = []
z = []
N = 200
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
# 阶梯型衰减
learing_rate1 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=True)
# 标准指数型衰减
learing_rate2 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=False)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
y.append(lr1)
z.append(lr2)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_ylim([0, 0.55])
plt.plot(x, y, 'r-', linewidth=2)
plt.plot(x, z, 'g-', linewidth=2)
plt.title('exponential_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show() #展示结果如上图右
红色的是阶梯型指数衰减,在一定轮次内学习率保持一致,绿色的是标准的指数衰减,即连续型指数衰减。
三、自然指数衰减 tf.train.natural_exp_decay()
自然指数衰减是指数衰减的一种特殊情况,学习率也是跟当前的训练轮次指数相关,只不过以 e 为底数。
tf.train.natural_exp_decay(
learning_rate, # 初始学习率
global_step, # 当前训练轮次,epoch
decay_steps, # 定义衰减周期,跟参数staircase配合,可以在decay_step个训练轮次内保持学习率不变
decay_rate, # 衰减率系数
staircase=False, # 定义(阶梯型衰减 /连续衰减),默认是False,即连续衰减(标准的指数型衰减)
name=None # 操作名称
)
自然指数衰减的计算公式是:
d
e
c
a
y
e
d
_
l
e
a
r
n
i
n
g
_
r
a
t
e
=
l
e
a
r
n
i
n
g
_
r
a
t
e
∗
e
x
p
(
−
d
e
c
a
y
_
r
a
t
e
∗
g
l
o
b
a
l
_
s
t
e
p
)
rm decayed_learning_rate = learning_rate * exp(-decay_rate * global_step)
decayed_learning_rate=learning_rate∗exp(−decay_rate∗global_step)
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
num_epoch = tf.Variable(0, name='global_step', trainable=False)
y = []
z = []
w = []
m = []
N = 200
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for num_epoch in range(N):
# 阶梯型衰减
learing_rate1 = tf.train.natural_exp_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=True)
# 标准指数型衰减
learing_rate2 = tf.train.natural_exp_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=False)
# 阶梯型指数衰减
learing_rate3 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=True)
# 标准指数衰减
learing_rate4 = tf.train.exponential_decay(
learning_rate=0.5, global_step=num_epoch, decay_steps=10, decay_rate=0.9, staircase=False)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
lr3 = sess.run([learing_rate3])
lr4 = sess.run([learing_rate4])
y.append(lr1)
z.append(lr2)
w.append(lr3)
m.append(lr4)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_ylim([0, 0.55])
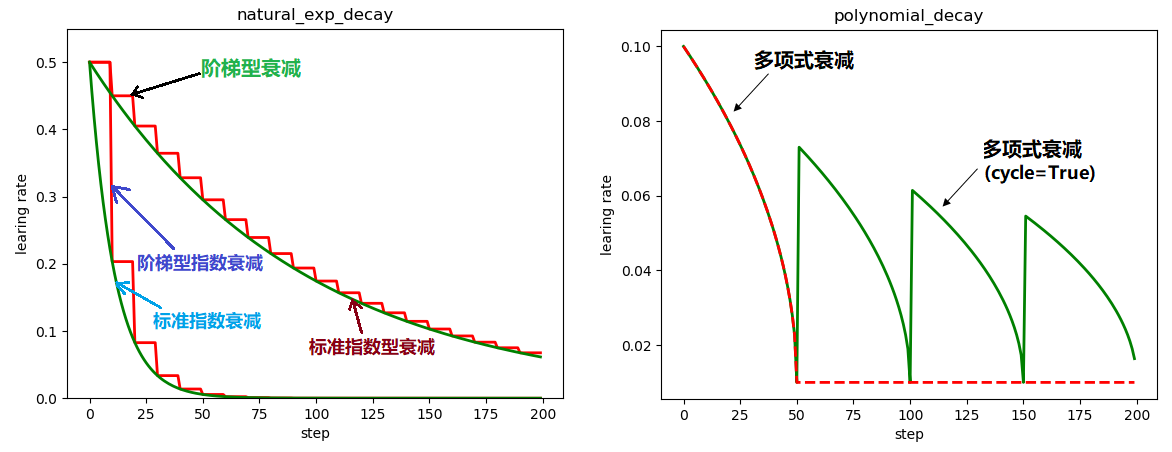
plt.plot(x, y, 'r-', linewidth=2)
plt.plot(x, z, 'g-', linewidth=2)
plt.plot(x, w, 'r-', linewidth=2)
plt.plot(x, m, 'g-', linewidth=2)
plt.title('natural_exp_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show() # 展示结果如下图左
显然:左下部分的两条曲线是自然指数衰减,右上部分的两条曲线是指数衰减,可见自然指数衰减对学习率的衰减程度要远大于一般的指数衰减,一般用于可以较快收敛的网络,或者是训练数据集比较大的场合。
四、多项式衰减 tf.train.polynomial_decay()
多项式衰减是这样一种衰减机制:定义一个初始的学习率,一个最低的学习率,按照设置的衰减规则,学习率从初始学习率逐渐降低到最低的学习率,并且可以定义学习率降低到最低的学习率之后,是一直保持使用这个最低的学习率,还是到达最低的学习率之后再升高学习率到一定值,然后再降低到最低的学习率(反复这个过程)。
tf.train.polynomial_decay(
learning_rate, # 初始学习率
global_step, # 当前训练轮次,epoch
decay_steps, # 定义衰减周期
end_learning_rate=0.0001, # 最小的学习率,默认值是0.0001
power=1.0, # 多项式的幂,默认值是1,即线性的
cycle=False, # 定义学习率是否到达最低学习率后升高,然后再降低,默认False,保持最低学习率
name=None # 操作名称
)
1.多项式衰减的学习率计算公式:
g l o b a l _ s t e p = m i n ( g l o b a l _ s t e p , d e c a y _ s t e p s ) sf global_step = bold {min}(global_step, decay_steps) global_step=min(global_step,decay_steps)
d e c a y e d _ l e a r n i n g _ r a t e = ( l e a r n i n g _ r a t e − e n d _ l e a r n i n g _ r a t e ) ∗ ( 1 − g l o b a l _ s t e p / d e c a y _ s t e p s ) p o w e r + e n d _ l e a r n i n g _ r a t e begin{aligned} sf decayed_learning_rate&=sf (learning_rate - end_learning_rate) * \ &sf (1 - global_step / decay_steps) ^ {power} + end_learning_rate end{aligned} decayed_learning_rate=(learning_rate−end_learning_rate)∗(1−global_step/decay_steps)power+end_learning_rate
2.如果定义 cycle为True,学习率在到达最低学习率后往复升高降低,此时学习率计算公式为:
d e c a y _ s t e p s = d e c a y _ s t e p s ∗ c e i l ( g l o b a l _ s t e p / d e c a y _ s t e p s ) sf decay_steps = decay_steps * bold {ceil} (global_step / decay_steps) decay_steps=decay_steps∗ceil(global_step/decay_steps)
d e c a y e d _ l e a r n i n g _ r a t e = ( l e a r n i n g _ r a t e − e n d _ l e a r n i n g _ r a t e ) ∗ ( 1 − g l o b a l _ s t e p / d e c a y _ s t e p s ) p o w e r + e n d _ l e a r n i n g _ r a t e begin{aligned} sf decayed_learning_rate&=sf (learning_rate - end_learning_rate) * \ &sf (1 - global_step / decay_steps) ^ {power} + end_learning_rate end{aligned} decayed_learning_rate=(learning_rate−end_learning_rate)∗(1−global_step/decay_steps)power+end_learning_rate
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
y = []
z = []
N = 200
global_step = tf.Variable(0, name='global_step', trainable=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for global_step in range(N):
# cycle=False
learing_rate1 = tf.train.polynomial_decay(
learning_rate=0.1, global_step=global_step, decay_steps=50,
end_learning_rate=0.01, power=0.5, cycle=False)
# cycle=True
learing_rate2 = tf.train.polynomial_decay(
learning_rate=0.1, global_step=global_step, decay_steps=50,
end_learning_rate=0.01, power=0.5, cycle=True)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
y.append(lr1)
z.append(lr2)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(x, z, 'g-', linewidth=2)
plt.plot(x, y, 'r--', linewidth=2)
plt.title('polynomial_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show() # 展示结果如上图右
红色的学习率衰减曲线对应 cycle = False,下降后不再上升,保持不变,绿色的学习率衰减曲线对应 cycle = True,下降后往复升降。
多项式衰减中设置学习率可以往复升降的目的是为了防止神经网络后期训练的学习率过小,导致网络参数陷入某个局部最优解出不来,设置学习率升高机制,有可能使网络跳出局部最优解。
五、余弦衰减 tf.train.cosine_decay()
余弦衰减的衰减机制跟余弦函数相关,形状也大体上是余弦形状。函数如下:
tf.train.cosine_decay(
learning_rate, # 初始学习率
global_step, # 当前训练轮次,epoch
decay_steps, # 衰减步数,即从初始学习率衰减到最小学习率需要的训练轮次
alpha=0.0, # 最小学习率
name=None # 操作的名称
)
余弦衰减学习率计算公式:
g l o b a l _ s t e p = m i n ( g l o b a l _ s t e p , d e c a y _ s t e p s ) sf global_step = min(global_step, decay_steps) global_step=min(global_step,decay_steps)
c o s i n e _ d e c a y = 0.5 ∗ ( 1 + c o s ( p i ∗ g l o b a l _ s t e p / d e c a y _ s t e p s ) ) sf cosine_decay = 0.5 * (1 + cos(pi * global_step / decay_steps)) cosine_decay=0.5∗(1+cos(pi∗global_step/decay_steps))
d e c a y e d = ( 1 − a l p h a ) ∗ c o s i n e _ d e c a y + a l p h a sf decayed = (1 - alpha) * cosine_decay + alpha decayed=(1−alpha)∗cosine_decay+alpha
d e c a y e d _ l e a r n i n g _ r a t e = l e a r n i n g _ r a t e ∗ d e c a y e d sf decayed_learning_rate = learning_rate * decayed decayed_learning_rate=learning_rate∗decayed
改进的余弦衰减方法 如下:
线性余弦衰减 tf.train.linear_cosine_decay()
噪声线性余弦衰减 tf.train.noisy_linear_cosine_decay()
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
y = []
z = []
w = []
N = 200
global_step = tf.Variable(0, name='global_step', trainable=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for global_step in range(N):
# 余弦衰减
learing_rate1 = tf.train.cosine_decay(
learning_rate=0.1, global_step=global_step, decay_steps=50)
# 线性余弦衰减
learing_rate2 = tf.train.linear_cosine_decay(
learning_rate=0.1, global_step=global_step, decay_steps=50,
num_periods=0.2, alpha=0.5, beta=0.2)
# 噪声线性余弦衰减
learing_rate3 = tf.train.noisy_linear_cosine_decay(
learning_rate=0.1, global_step=global_step, decay_steps=50,
initial_variance=0.01, variance_decay=0.1, num_periods=0.2, alpha=0.5, beta=0.2)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
lr3 = sess.run([learing_rate3])
y.append(lr1)
z.append(lr2)
w.append(lr3)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
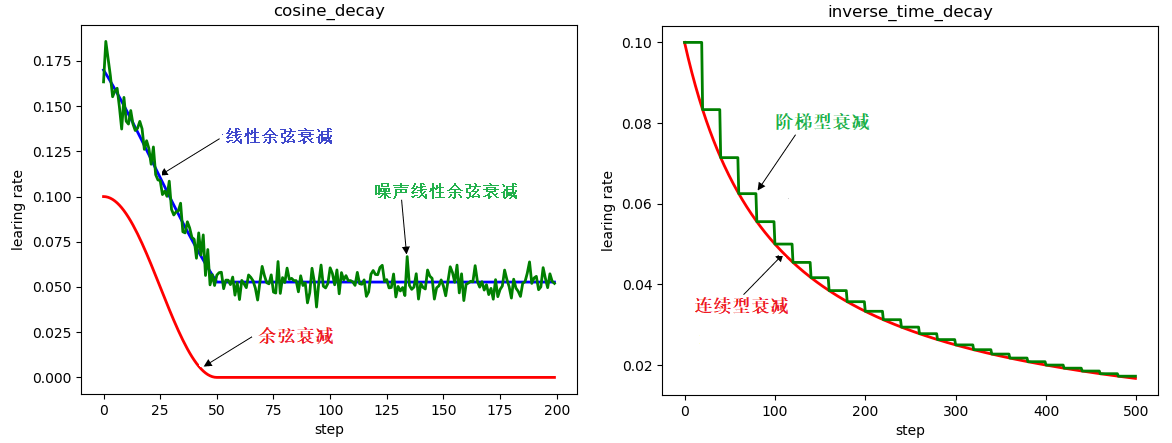
plt.plot(x, z, 'b-', linewidth=2)
plt.plot(x, y, 'r-', linewidth=2)
plt.plot(x, w, 'g-', linewidth=2)
plt.title('cosine_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show() # 展示结果如下图左
六、反时限学习率衰减(倒数)衰减 tf.train.inverse_time_decay()
反时限学习率衰减指的是一个变量的大小与另一个变量的大小成反比的关系,具体到神经网络中就是学习率的大小跟训练次数有一定的反比关系。
tf.train.inverse_time_decay(
learning_rate, # 初始学习率
global_step, # 用于衰减计算的全局步数
decay_steps, # 衰减步数
decay_rate, # 衰减率
staircase=False, # 是否应用离散阶梯型衰减(否则为连续型)
name=None # 操作的名称
)
反时限学习率衰减(倒数)衰减的计算公式:
d e c a y e d _ l e a r n i n g _ r a t e = l e a r n i n g _ r a t e 1 + d e c a y _ r a t e ∗ ( g l o b a l _ s t e p / d e c a y _ s t e p ) sf decayed_learning_rate = frac{learning_rate}{1+decay_rate* (global_step/decay_step)} decayed_learning_rate=1+decay_rate∗(global_step/decay_step)learning_rate
# coding:utf-8
import matplotlib.pyplot as plt
import tensorflow as tf
y = []
z = []
N = 200
global_step = tf.Variable(0, name='global_step', trainable=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for global_step in range(N):
# 阶梯型衰减
learing_rate1 = tf.train.inverse_time_decay(
learning_rate=0.1, global_step=global_step, decay_steps=20,
decay_rate=0.2, staircase=True)
# 连续型衰减
learing_rate2 = tf.train.inverse_time_decay(
learning_rate=0.1, global_step=global_step, decay_steps=20,
decay_rate=0.2, staircase=False)
lr1 = sess.run([learing_rate1])
lr2 = sess.run([learing_rate2])
y.append(lr1)
z.append(lr2)
x = range(N)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(x, z, 'r-', linewidth=2)
plt.plot(x, y, 'g-', linewidth=2)
plt.title('inverse_time_decay')
ax.set_xlabel('step')
ax.set_ylabel('learing rate')
plt.show() # 展示结果如上图右
倒数衰减不固定最小学习率,迭代次数越多,学习率越小。
最后一个小例子:
import tensorflow as tf
from numpy.random import RandomState
"""
这里关于w1,w2,x初始化的数据形状(维度)多说一句:(矩阵相乘:前一矩阵的行数与后一矩阵的列数相同)
也就是w1[2, 6]与x[None, 2]这两个维度要对应
"""
w1 = tf.Variable(tf.truncated_normal([2, 6], seed=1))
w2 = tf.Variable(tf.truncated_normal([6, 1], seed=1))
x = tf.placeholder(dtype=tf.float32, shape=[None, 2])
y_real = tf.placeholder(dtype=tf.float32, shape=[None, 1])
a = tf.nn.relu(tf.matmul(x, w1)) # 激活函数为 relu
y_pre = tf.nn.relu(tf.matmul(a, w2))
sample_size = 20000 # 训练样本总数
batch = 500 # 使用mini-batch(批梯度下降)。
rds = RandomState(0)
X = rds.rand(sample_size, 2)
Y = [[int(20 * x1 + 30 * x2)] + rds.rand(1) for (x1, x2) in X]
global_step = tf.Variable(0)
# --------------学习速率的设置(学习速率呈指数下降)----- # 将 global_step/decay_steps 强制转换为整数
learning_rate = tf.train.exponential_decay(1e-2, global_step, decay_steps=sample_size/batch,
decay_rate=0.98,staircase=True)
MSE = tf.reduce_mean(tf.square(y_real - y_pre)) # 使用均方误差(MSE)作为损失函数
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(MSE, global_step=global_step)
step = 20000 # 训练的总次数
start = 0
end = batch
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(step):
sess.run(train_step, feed_dict={x: X[start:end], y_real: Y[start:end]})
if not i % 20:
H = sess.run(MSE, feed_dict={x: X[start:end], y_real: Y[start:end]})
lr = sess.run(learning_rate)
print("MSE: ", H, "t", "learning_rate: ", lr)
if H < 1e-1: # 采用stop early 的方法防止过拟合,节省训练时间。
break
strat = end if end < sample_size else 0
end = start + batch
y1 = sess.run(y_pre, feed_dict={x: X[start:end]})
y2 = Y[start:end]
# 训练结果的部分展示
for i in range(100):
print(y1[i], y2[i])
输出:
MSE: 543.05066 learning_rate: 0.01
MSE: 2.118717 learning_rate: 0.01
MSE: 0.25453076 learning_rate: 0.0098
MSE: 0.16074152 learning_rate: 0.0098
MSE: 0.15586866 learning_rate: 0.0096040005
MSE: 0.15555921 learning_rate: 0.0096040005
MSE: 0.15548062 learning_rate: 0.00941192
MSE: 0.15541694 learning_rate: 0.00941192
MSE: 0.15535907 learning_rate: 0.009223682
MSE: 0.15530446 learning_rate: 0.009223682
... ...
鸣谢
https://blog.csdn.net/dcrmg/article/details/80017200
https://blog.csdn.net/u012560212/article/details/72986812
https://blog.csdn.net/sinat_29957455/article/details/78387716
https://blog.csdn.net/sxlsxl119/article/details/85006202
最后
以上就是机智煎蛋最近收集整理的关于TensorFlow之二—学习率 (learning rate)的全部内容,更多相关TensorFlow之二—学习率内容请搜索靠谱客的其他文章。








发表评论 取消回复