Caffeine是一款基于Java8开发的,高性能的,接近最优的本地缓存库
2.1 淘汰策略(Size-Based)
缓存命中率是衡量缓存系统优劣的重要指标,缓存通过保存最近使用或经常使用的数据于速度较快的介质中以提高数据的访问速度,缓存空间被填满后,会面临如何选择丢弃数据为新数据腾出空间的问题,因此选择合适的缓存淘汰算法会直接影响缓存的命中率。常用的缓存算法有:
-
First in first out (FIFO) 顾名思义,就是一个FIFO队列,先进入缓存的先被淘汰,忽略数据访问频率和次数信息。较为原始,命中率很低。
-
Least recently used (LRU) 最近最少被使用算法,其核心思想是【如果数据最近被访问过,那么将来被访问的概率也更大】,忽略了数据的访问次数,最常见的实现是维护一个链表,新数据插入到链表尾部,命中缓存的数据重新移至队尾,队列满后移出队首元素。LRU算法在有热点数据的情况下效率很好,但是如果面临突然流量或者周期性的数据访问是命中率会急剧下降。
-
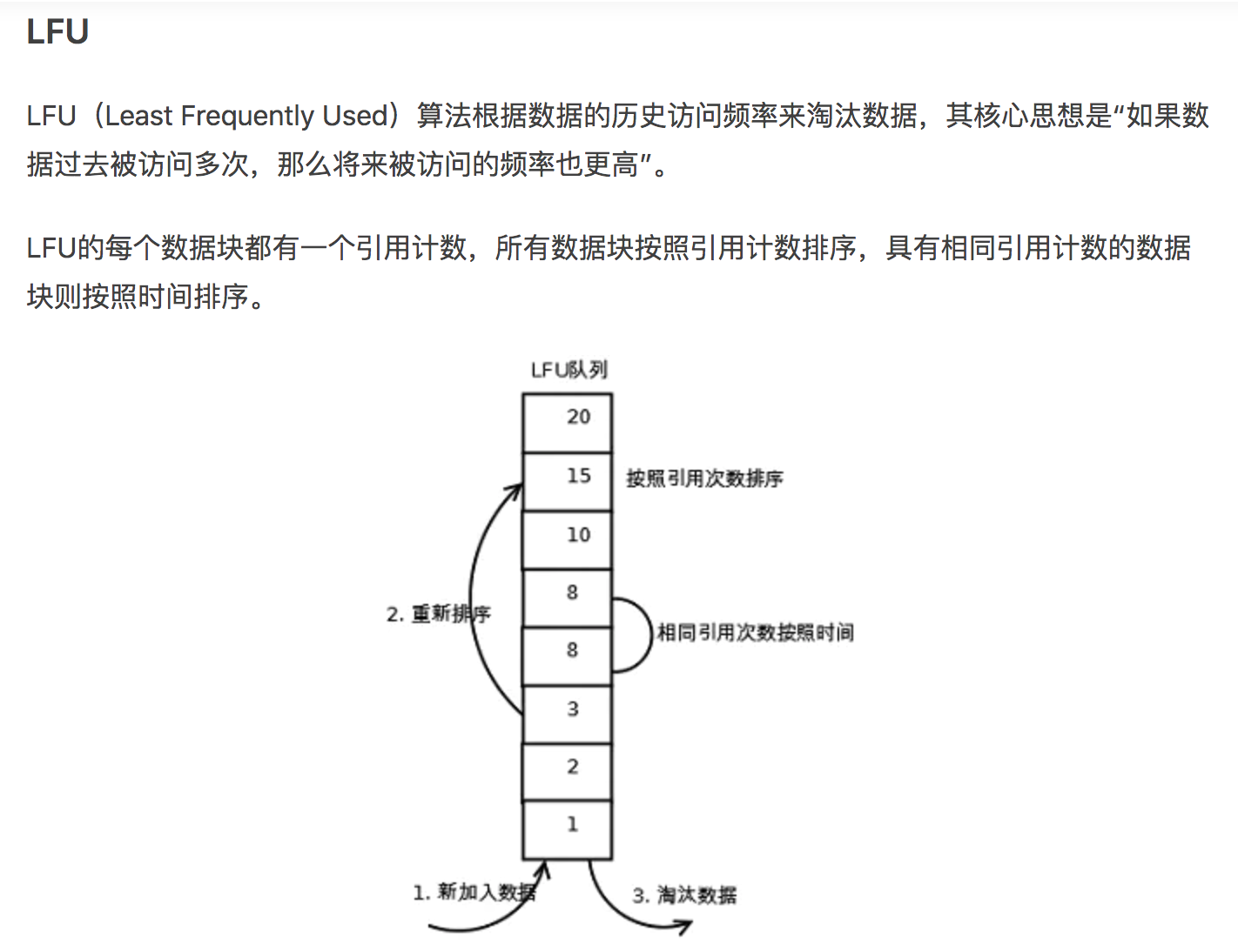
Least frequently used (LFU) 最近最少频率使用,他的核心思想是【如果数据过去被多次访问,那么将来被访问的概率也更大】,LFU的实现需要为每个缓存数据维护一个引用计数,最后基于访问数量进行数据淘汰操作,因此实现较为复杂。LFU算法的效率通常高于LRU,能较好的介君突发流量或周期性访问问题,但是由于LFU需要一定时间累积自己的访问频率,因此无法应对数据访问方式的改变。
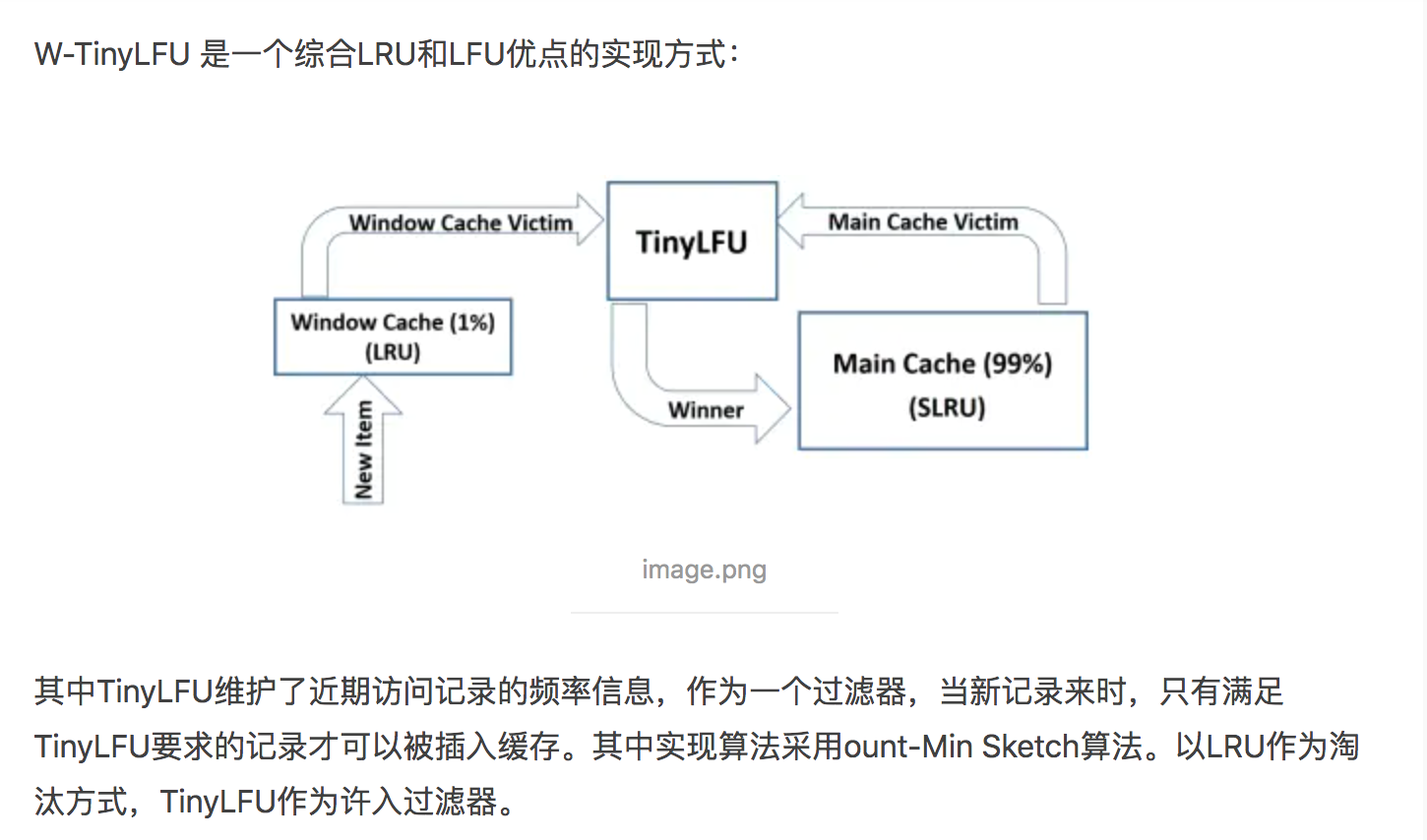
Caffeine的缓存淘汰是通过一种叫做W-TinyLFU的数据结构实现的,这是一种对LRU和LFU进行了组合优化的算法,下图给出了W-TinyLFU相对其他几种算法的表现,可以看出W-TinyLFU在数据查询、搜索、分析等场景均有优异的表现.
2.1.1 W-TinyLFU
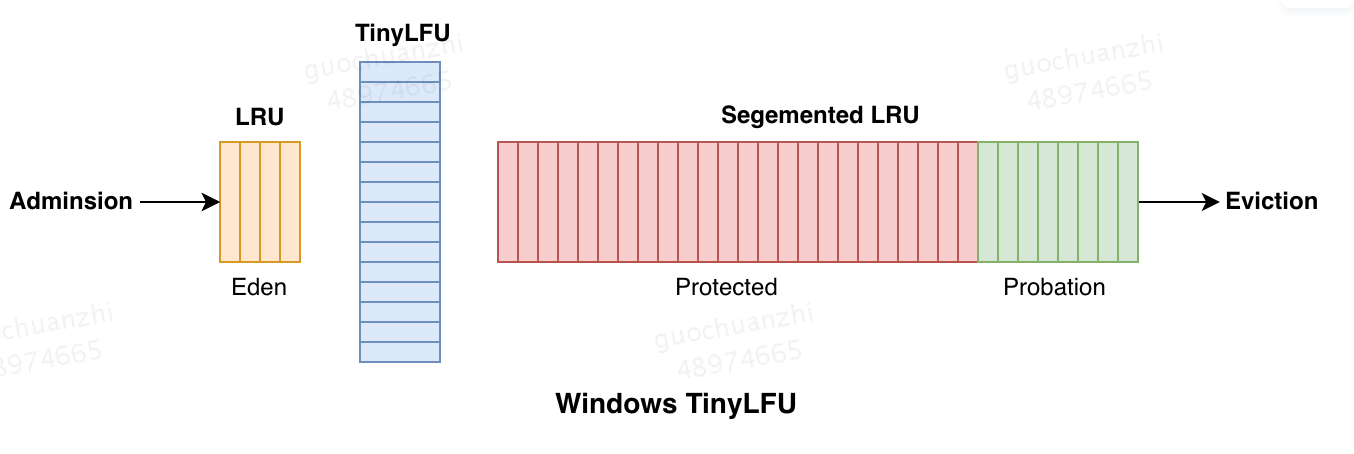
Window TinyLFU主要由以下三个部分组成:
-
准入窗口(Admission Window)也称伊甸区,是一个较小的LRU队列,其容量只有缓存大小的1%,这个窗口的作用主要是为了保护一些新进入缓存的数据,给他们一定的成长时间来积累自己的使用频率,避免被快速淘汰掉,同时这个窗口也可以过滤掉一些突发流量。
-
频次过滤器(TinyLFU)是Caffeine数据淘汰策略的核心所在,他依赖CountMin Sketch非精确的记录数据的历史访问次数,从而决定主缓存区数据的淘汰策略,这个数据结构用很小的成本完成了缓存数据访问频次的记录和查找。
-
主缓存区(Main region)用于存放大部分的缓存数据,数据结构为一个分段LRU队列(SLRU),包括ProtectedDeque和ProbationDeque两部分,其中ProtectedDeque的大小占总容量的80%,该部分使用TinyLFU的Adminsion策略进行数据的淘汰,一些访问频次很低的数据可以被快速淘汰掉,避免了主缓存区被新缓存污染。
2.1.2 CountMin Sketch
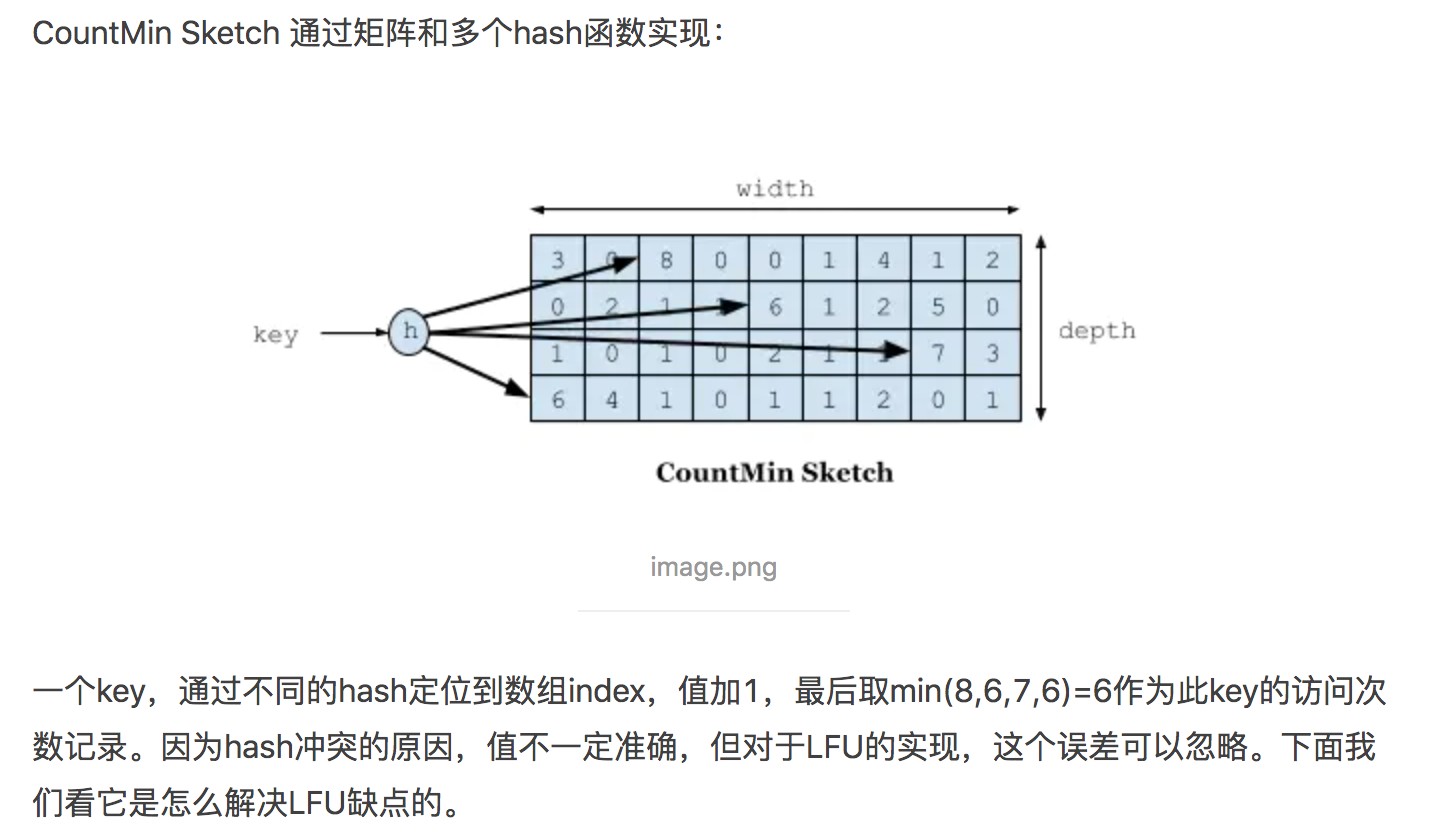
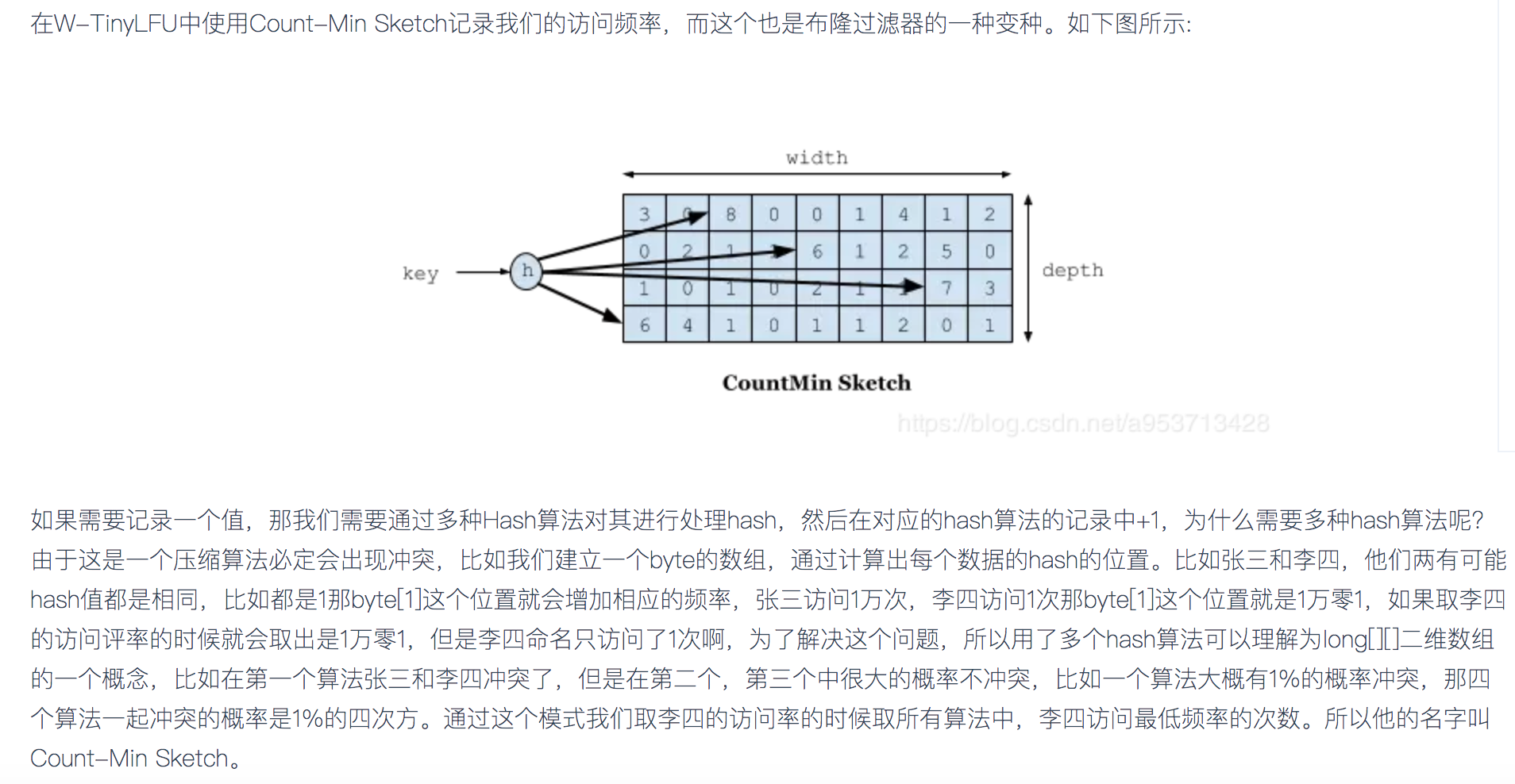
LFU算法实现的关键在于如何能高效的保存和读取数据最近的访问频次信息,通常的做法是使用popularity sketch(一种概率数据结构)来识别数据的"命中"事件,从而记录数据的访问次数。CountMin-Sketch便是其中的一种,他是通过一个计数矩阵和多个哈希算法实现的,如图所示:
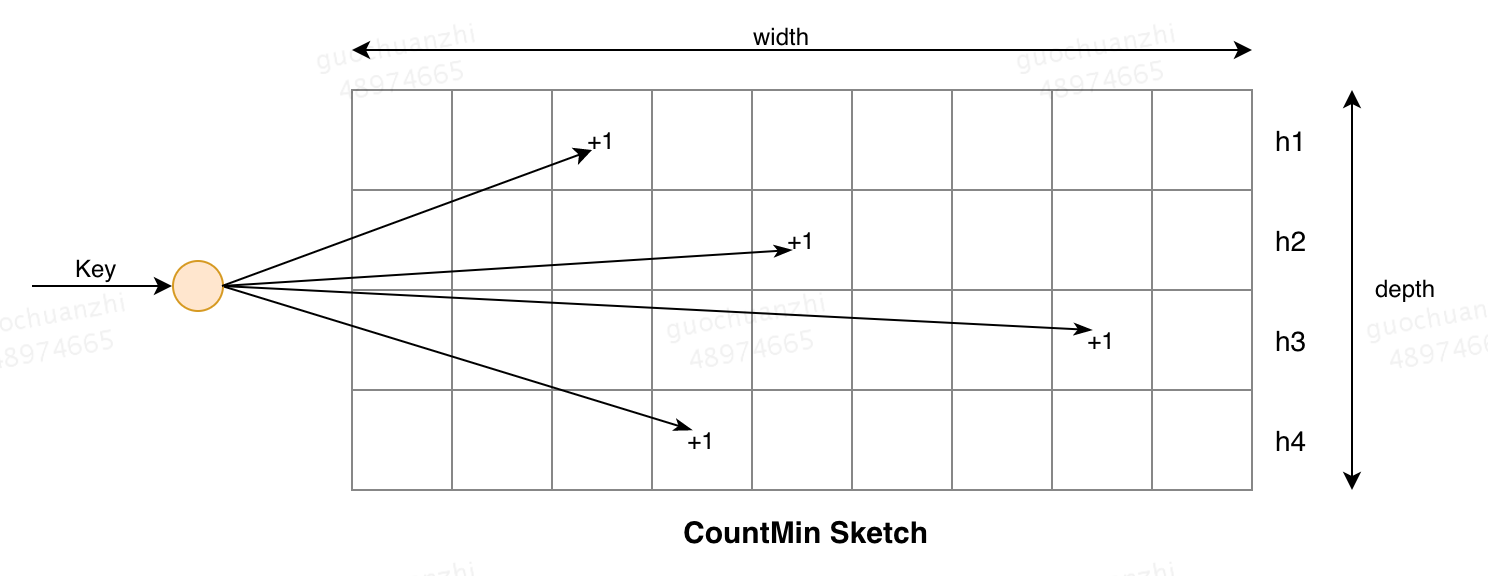
CountMin Sketch的原理类似于布隆过滤器,也是一种概率型的数据结构。其中不同的row对应着不同的哈希算法,depth大小代表着哈希算法的数量,width则表示数据可哈希的范围。当记录某个指定key的访问次数时,分别使用不同的哈希算法在其对应的row上做哈希操作,如果命中了某一个数据格,则将该数据格的引用计数+1。当查询某个指定key的访问次数时,经过哈希定位到具体的多个数据格后,返回最小的数量计为该数据的访问次数。使用多个哈希算法可以降低哈希碰撞带来的数据不准确的概率,宽度上的增加可以提高key的哈希范围,减少碰撞的概率,因此我们可以通过调整矩阵的width和depth达到算法在空间、效率和哈希碰撞产生的错误率之间平衡的目的。Caffeine中的CountMin Sketch是通过四种哈希算法和一个long型数组实现的,具体的实现方法可以参考咖啡拿铁大神的文章——深入解密来自未来的缓存-Caffeine,这里就不再赘述了
淘汰过程
-
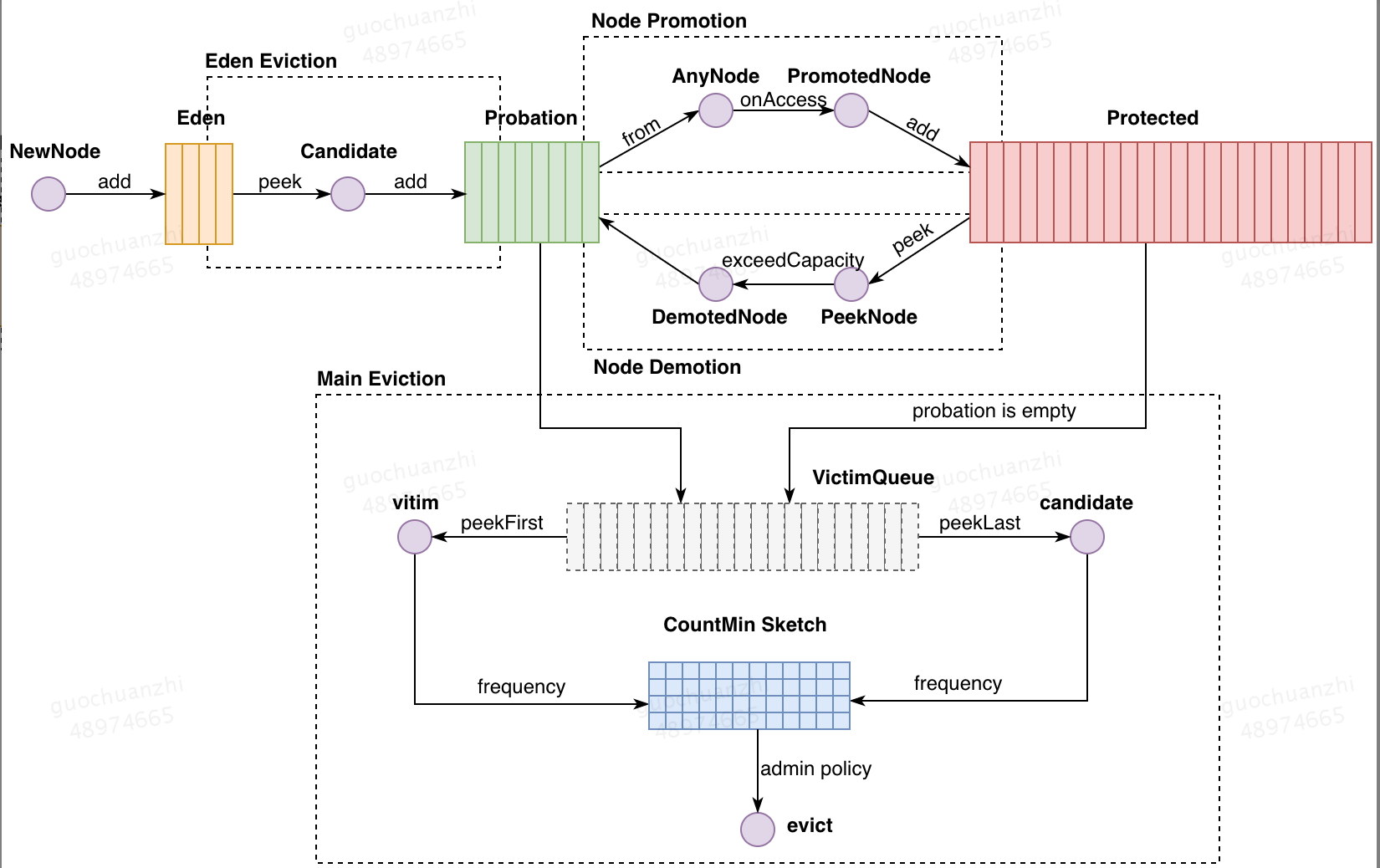
所有进入缓存区的数据会首先被add进Eden区,当该队列长度达到容量限制后,会触发Eden区的淘汰操作,超出的entries会被下放至主缓存区的Probation队列,这些数据被称为Candidate。
-
进入Probation队列的数据如果在没有被主缓存区淘汰之前获得了一次access,该节点会被add进Protected队列,这个过程称之为Node Promotion。
-
Protecte队列如果达到其容量限制会触发Node Demotion过程,队列首部的元素会被peek出并下放到Probation队列。
-
主缓存区的大小(Probation的大小 + Protected的大小)达到了其容量限制会触发主缓存区的数据淘汰,Probation会被优先选择为淘汰队列,如果Probation为空,则选择Protected为淘汰队列。
-
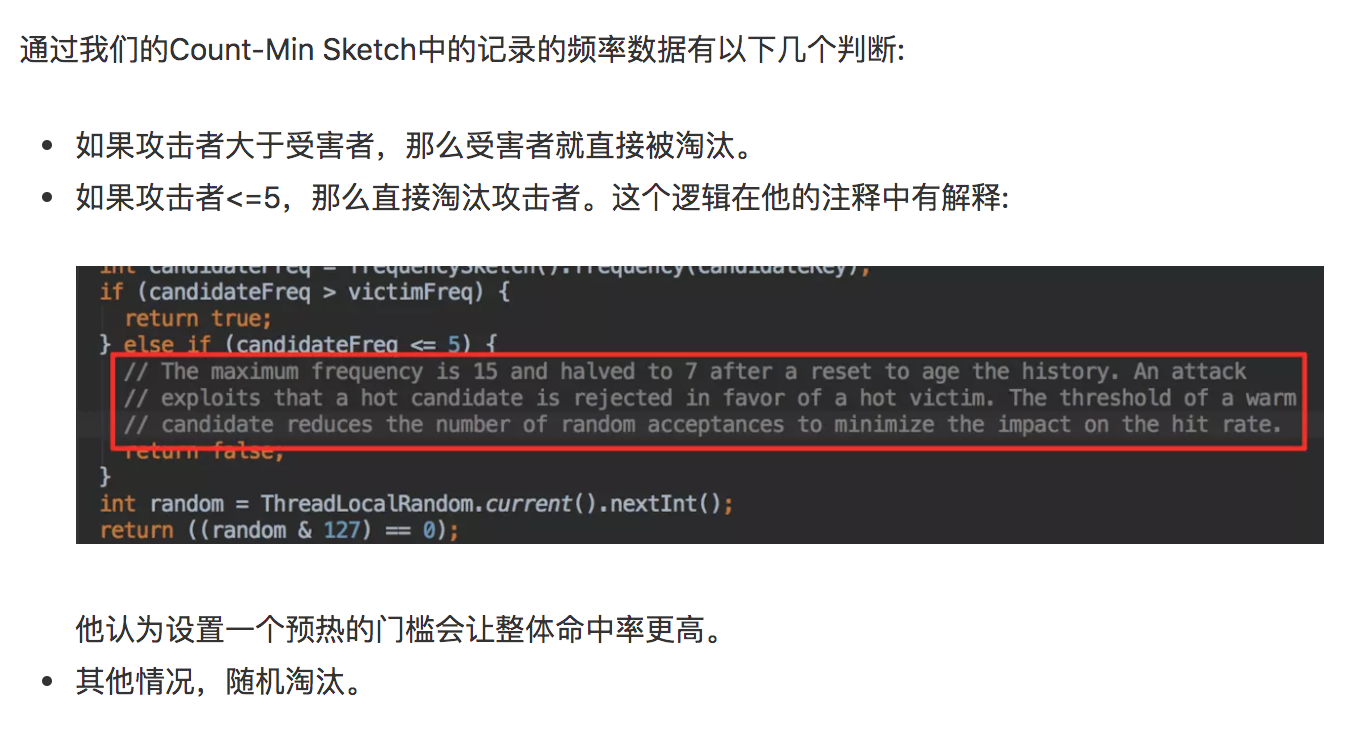
分别选取淘汰队列的首部元素作为受害者(victim),尾部元素作为竞争者(candidate),通过对比两者的访问频次选择最终的淘汰者,其中访问频次通过CountMin Sketch获得。
这里Caffeine对于竞争者的淘汰并不只是简单的判断其访问频次小于或等于受害者,而是加入了以下逻辑:
-
如果竞争者的访问频次大于5且小于或等于受害者频次,随机淘汰,这么做的原因主要是为了一定程度的避免哈希碰撞引起的受害者访问频次非自然增长,从而导致新数据无法被写入主缓存区。
-
如果竞争者的访问频次小于等于5则直接淘汰竞争者,这是因为TinyLFU中记录数据的访问频次最大值为15,当超过这个最大值触发全局的reset后只有7,因此如果不加一个数据预热的过程,可能会导致一个频率较低的攻击者因为随机淘汰策略挤掉了热点数据。
2.2 过期策略(Time-Based)
缓存数据过期清理的必要性和重要性不仅仅体现在应用场景的要求上,对于缓存本身,及时清理掉过期数据可以节省空间,降低缓存的维护成本,提高缓存性能,缓存过期清理的方式可以分为以下两种(是我按照自己的理解分的,没有资料依据,有不当之处望大家指正):
-
访问清理,即每次访问某个具体的缓存数据时判断其是否过期然后执行相应的操作。这种策略的优点就是实现简单,缺点是缓存的过期依赖于缓存的访问,会造成过期数据污染缓存区现象的发生,如果一个数据过期后没有被再次访问,那么他可能会长期存在于缓存中,直到淘汰策略将其移除。
-
全局清理,即在某些特定的时期全局性的扫描缓存区,清理掉过期数据。这种方式的优点是可以及时清理掉一些过期的数据,不必依赖数据的访问。缺点是实现成本高,需要使用额外的数据结构去维护一个过期队列,实现复杂,除此之外全局清理的发生时间也是一个棘手的问题。
2.2.1 清理策略
Caffeine中的对于访问清理和全局清理都有支持,对于访问清理的实现方式如下图所示,因为Caffeine缓存区的实现是一个LRU队列,本身就维护了数据访问的时间顺序,因此不必使用额外的数据结构进行存储,每次只用peek出缓存队列的首部元素对其进行过期判断即可。

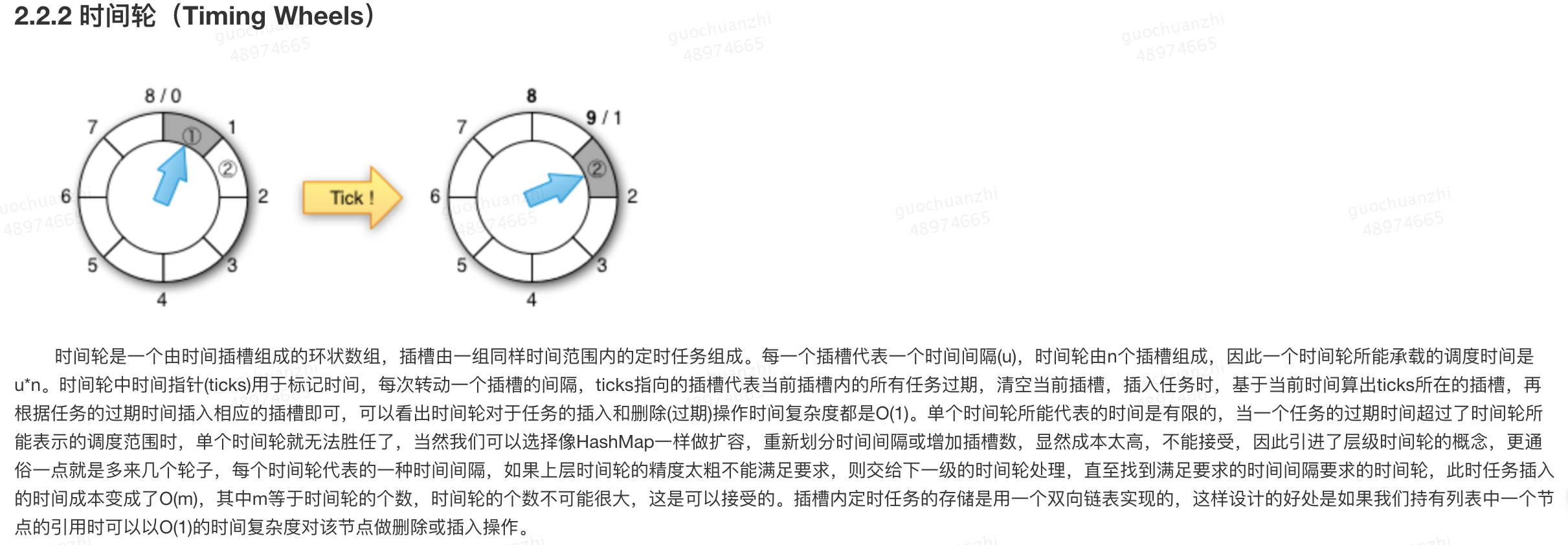
对于全局清理而言主要有两个要解决的问题点,即如何选择清理时间和如何快速找到过期数据并移除。我们首先来看第一个问题,通常来讲有两种方式,一是依赖缓存的淘汰策略,缓存区达到容量限制后发生缓存淘汰时触发一次缓存过期清理,二是开启一个清理线程定期的执行过期清理工作。Caffeine中选择的第二种方式,不同的是这里的实现并不是通过一个轮询线程定期执行,而是由缓存的读写触发的,具体的触发方式和触发规则将在下一节【并发控制】里详细讲解。解决了如何选择清理时间的问题我们再来看如何能快速找到过期数据,通常的做法是维护一个基于过期时间的优先队列,这样做的复杂度是O(logn),Caffeine中采用的是Kafka中的时间轮(hierarchical timing wheels)方法,他的插入删除时间复杂度都为O(1),相信做过定时任务调度的同学对这个数据结构一定不陌生,这里只做一点简单的介绍
2.3 并发控制(Concurrency-Control)
缓存的并发控制是一个比较头疼的问题,因为缓存的淘汰策略、过期策略等等都会涉及到了对同一块缓存区内容的修改,最简单省事的办法无非就是给缓存区加锁,分段锁是一种比较通用的解决方案,ConcurrentyHashMap的实现(Java8之前)就是基于分段锁,然而由于缓存中锁的竞争主要发生在一些热点数据上,因此分段锁带来的收益也是有限的。Caffeine中采用了缓冲队列回放机制来减轻并发带来的锁竞争问题,同时对于缓存而言读操作是远远大于写操作的,因此Caffeine中对于读写的缓冲队列也采用了不同的实现思路和方式,下面详细讨论。
2.3.1 缓冲队列——读
Caffeine中缓存每次的读操作都会先被写入缓冲队列,其底层的数据结构是一个striped ring buffer,这里的striped是指一种通过哈希获取锁的算法,对于同一个key(Java中可能对象地址不同)哈希后获得的将是同一个锁对象,Caffeine基于striped hash后的key分配相应的ring buffer,值得注意的是这里的key并不是缓存数据的key,而是线程本身,这样设计的好处是可以对热点数据访问引起的激增流量起到削峰作用。写入缓存成功后会基于一定的条件判断是否需要触发一个异步的缓存区调度任务,代码如下。可以看到当ring buffer满了之后并且调度状态满足一定的条件才会触发,如果当前ring buffer满之后,后续写入该队列的读操作会被直接被丢弃,这种信息的缺失并不会产生很大的影响,因为TinyLFU可以记录哪些是热点数据,这里状态机之间的流转如图所示,具体的状态机转移过程情况较多比较复杂
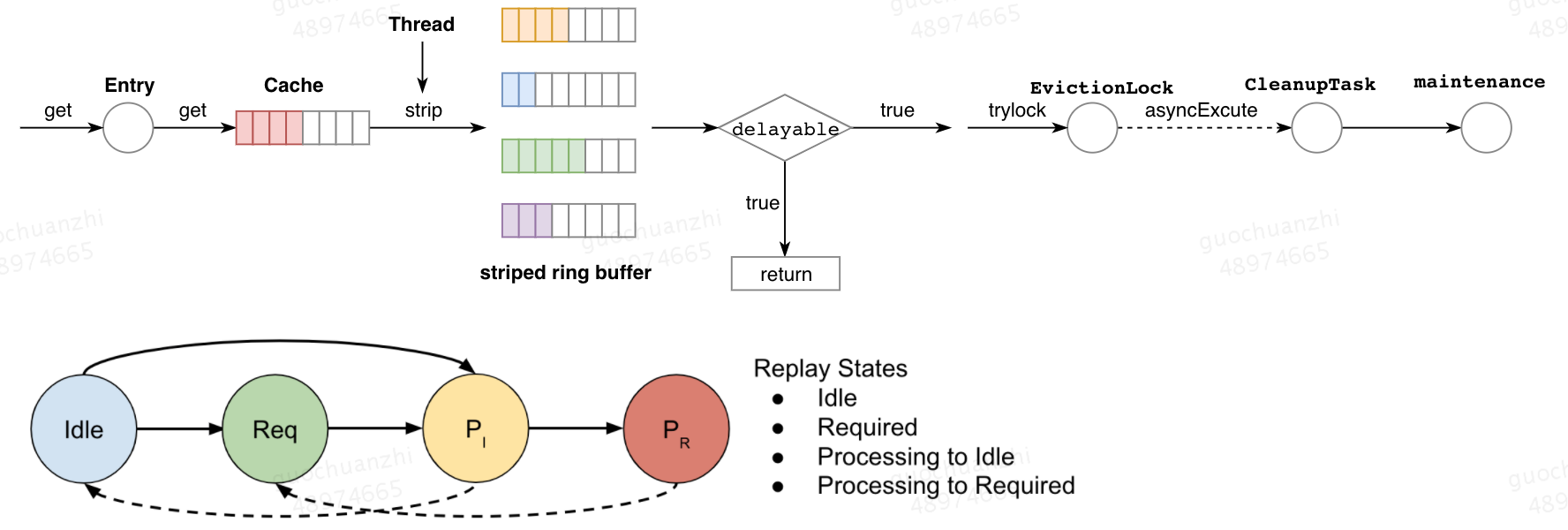
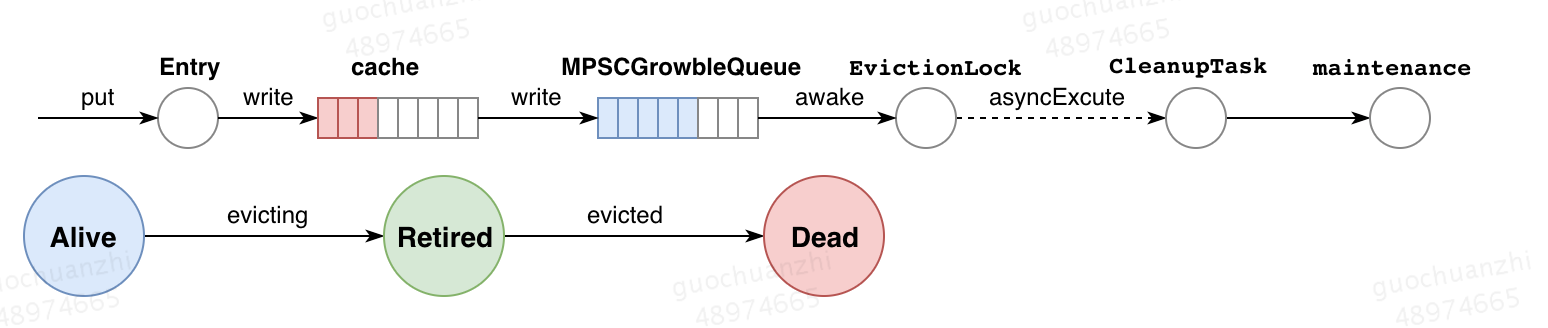
2.3.2 缓冲队列——写
Caffeine认为写的操作远小于读,因此所有的写操作共享同一个缓冲队列,这里的队列一个多生产者单消费者模型,具体的实现是用了JCtools里的无锁MPSC(Multi Producer Single Consumer)自动扩容队列,由于没有锁因此效率很高。写操作的丢失是不能被容许的,因此Caffeine中每次写操作都会触发一次缓存区调度任务。缓存区的任务回放(读和写都有)和缓存数据的写入会产生竞态条件,可能会导致对某个缓存数据的增删改查操作不能被有序的执行,从而产生悬空索引的问题,Caffenie通过引入了状态机定义节点的生命周期来解决这个问题。Alive状态代表该节点还在缓存中,Retired状态代表节点不在缓存中但是正在被淘汰策略清除,Dead状态代表该节点已经被移出缓存区了。
2.3.1 缓冲队列任务调度(Maintenance Work)
上面提到读写操作都会触发缓存区的任务调度,那这个任务调度到底是干了那些事情呢,上代码。可以看到Caffeine中的缓存区任务调度(scheduleDrainBuffers)实际上是异步执行了一个叫做执行清理的任务(PerformCleanupTask),这里的线程池采用了ForkJoinPool实现。继续往下可以看到清理任务其实最终执行的是maintenance方法中的内容,执行之前会获取一个叫做evictionLock的锁,这里其实已经可以猜到这部分的主要工作肯定是和缓存淘汰有关,查看maintenance内容也验证了前面的猜想。至此可以总结出Caffeine中引用淘汰、容量限制淘汰、缓存过期淘汰是由缓存的读写操作经过一定规则计算后触发的,这也解释了上述遗留的缓存过期淘汰发生时间问题。
2.4 总结
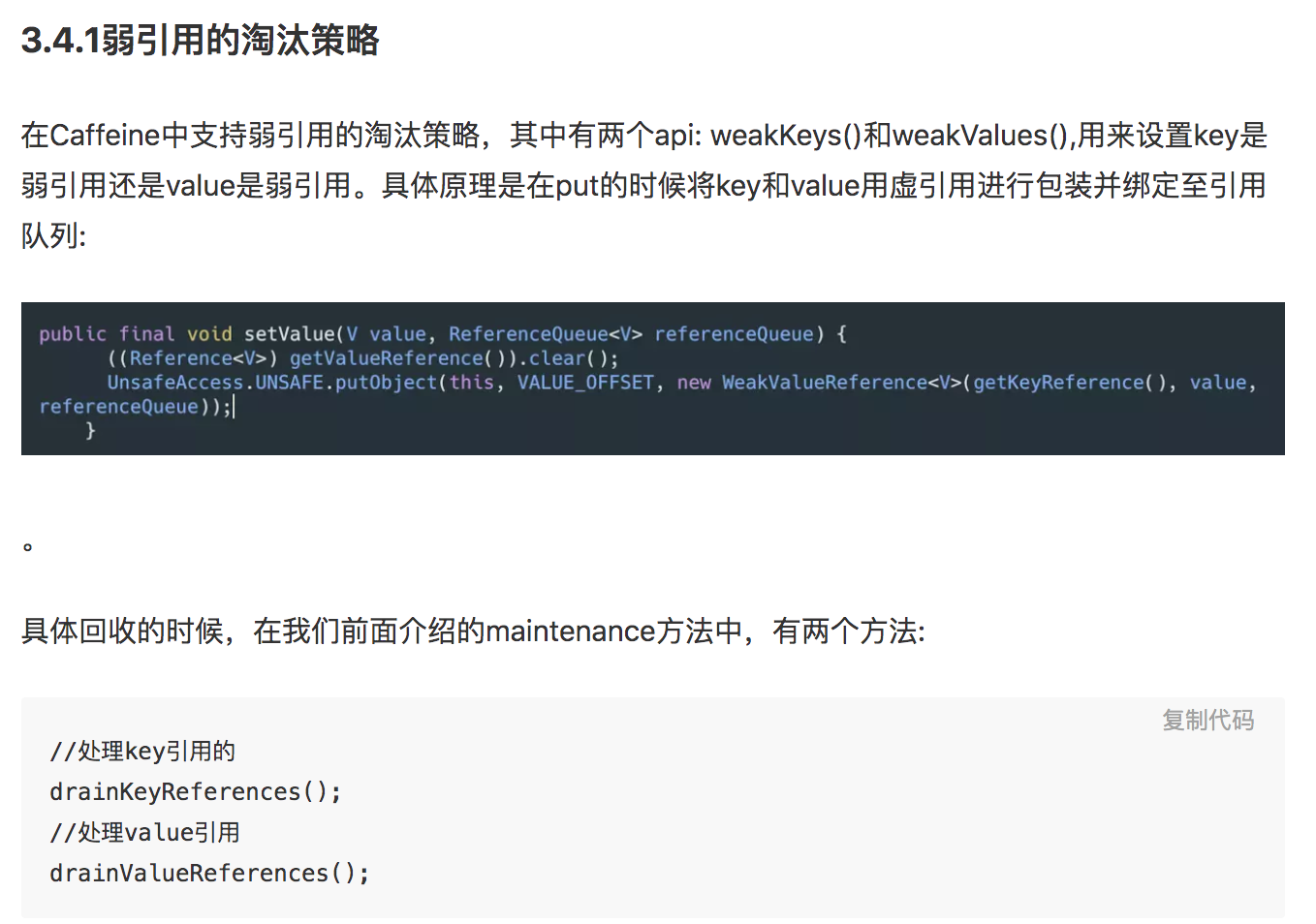
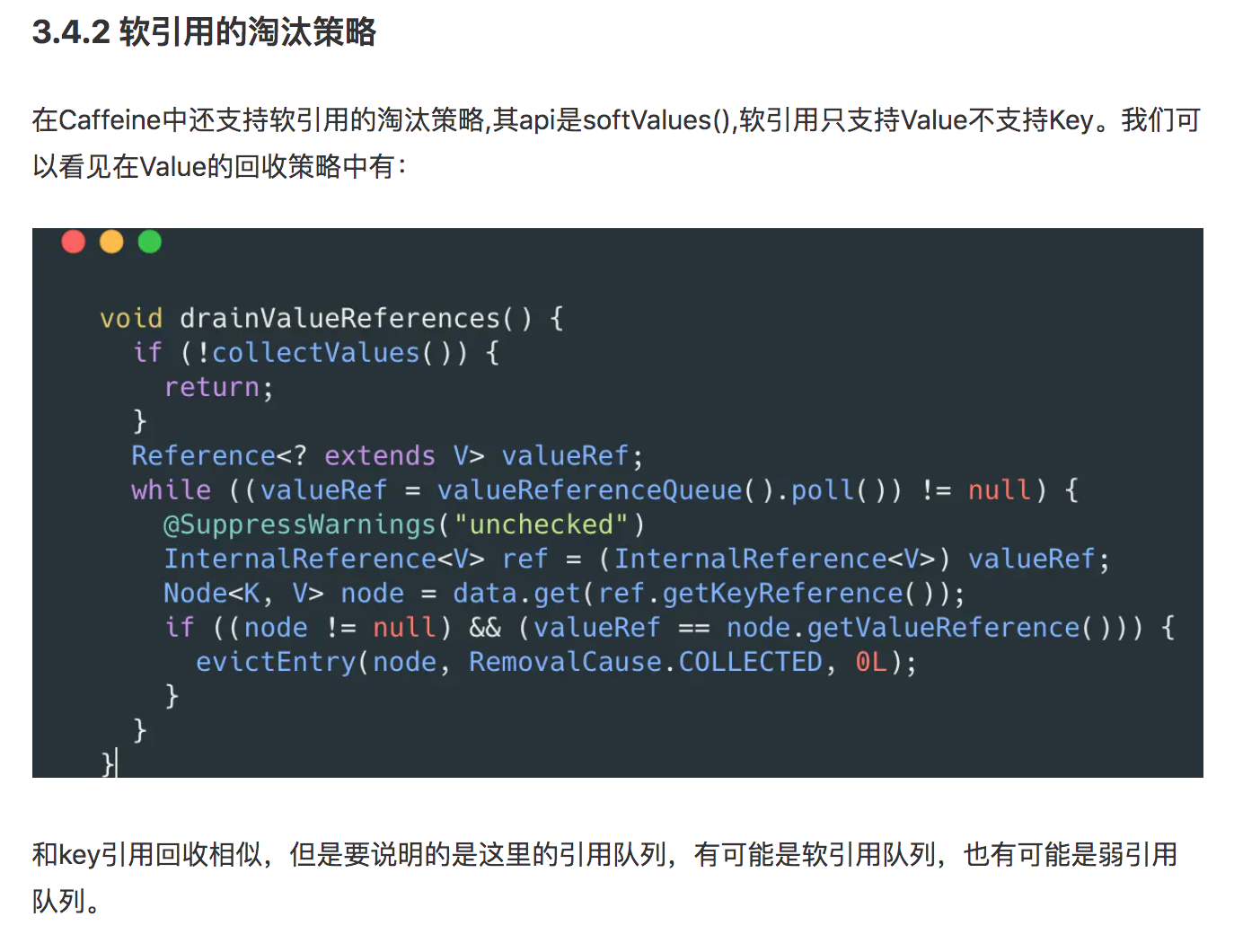
上述章节已经详细的介绍了Caffeine的一些核心能力及其实现原理,除此之外Caffeine还提供了异步刷新、弱引用key、弱软引用value、淘汰监听、打点监控等功能,由于篇幅关系这里也不再多做介绍。说了这么多,那到底Caffeine怎么用呢?是不是还要花时间去熟悉API?我想说这部分大家完全不必担心,因为Caffeine的API是完全参考Google Guava的,如果你有Guava的使用经验切换成本几乎为零,这里贴上一段Caffeine的Cache构建代码,大家可以发现是不是和Guava一模一样。

+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

2.3数据淘汰策略
在caffeine所有的数据都在ConcurrentHashMap中,这个和guava cache不同,guava cache是自己实现了个类似ConcurrentHashMap的结构。在caffeine中有三个记录引用的LRU队列:
-
Eden队列:在caffeine中规定只能为缓存容量的%1,如果size=100,那这个队列的有效大小就等于1。这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰。比如有一部新剧上线,在最开始其实是没有访问频率的,防止上线之后被其他缓存淘汰出去,而加入这个区域。伊甸区,最舒服最安逸的区域,在这里很难被其他数据淘汰。
-
Probation队列:叫做缓刑队列,在这个队列就代表你的数据相对比较冷,马上就要被淘汰了。这个有效大小为size减去eden减去protected。
-
Protected队列:在这个队列中,可以稍微放心一下了,你暂时不会被淘汰,但是别急,如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要把Probation访问一次之后,就会提升为Protected队列。这个有效大小为(size减去eden) X 80% 如果size =100,就会是79。
这三个队列关系如下:
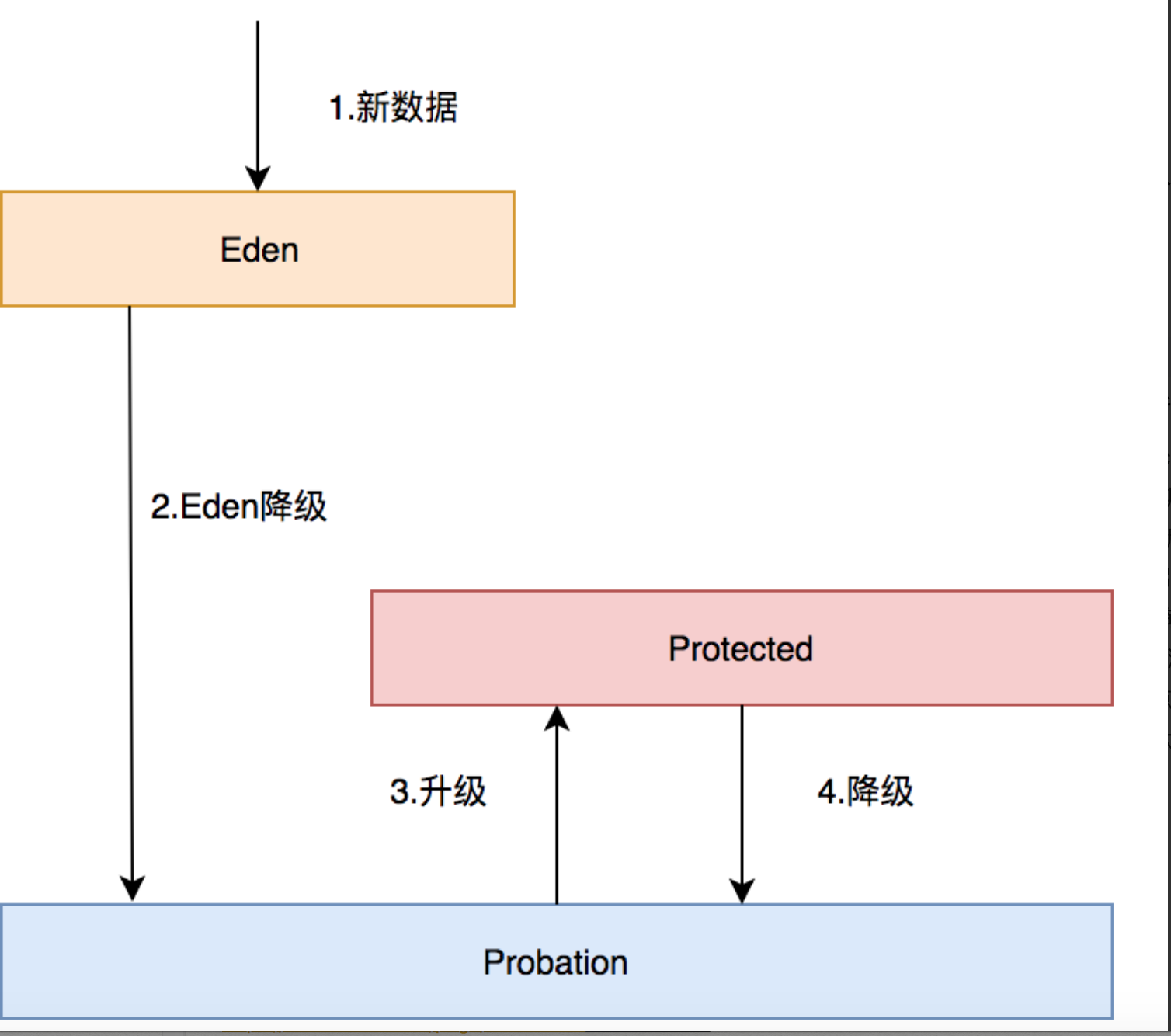
- 所有的新数据都会进入Eden。
- Eden满了,淘汰进入Probation。
- 如果在Probation中访问了其中某个数据,则这个数据升级为Protected。
- 如果Protected满了又会继续降级为Probation。
对于发生数据淘汰的时候,会从Probation中进行淘汰。会把这个队列中的数据队头称为受害者,这个队头肯定是最早进入的,按照LRU队列的算法的话那他其实他就应该被淘汰,但是在这里只能叫他受害者,这个队列是缓刑队列,代表马上要给他行刑了。这里会取出队尾叫候选者,也叫攻击者。这里受害者会和攻击者皇城PK决出我们应该被淘汰的。

首先他会进行加锁,如果锁失败说明有人已经在执行调度了。他会使用默认的线程池ForkJoinPool或者自定义线程池,这里的drainBuffersTask其实是Caffeine中PerformCleanupTask。
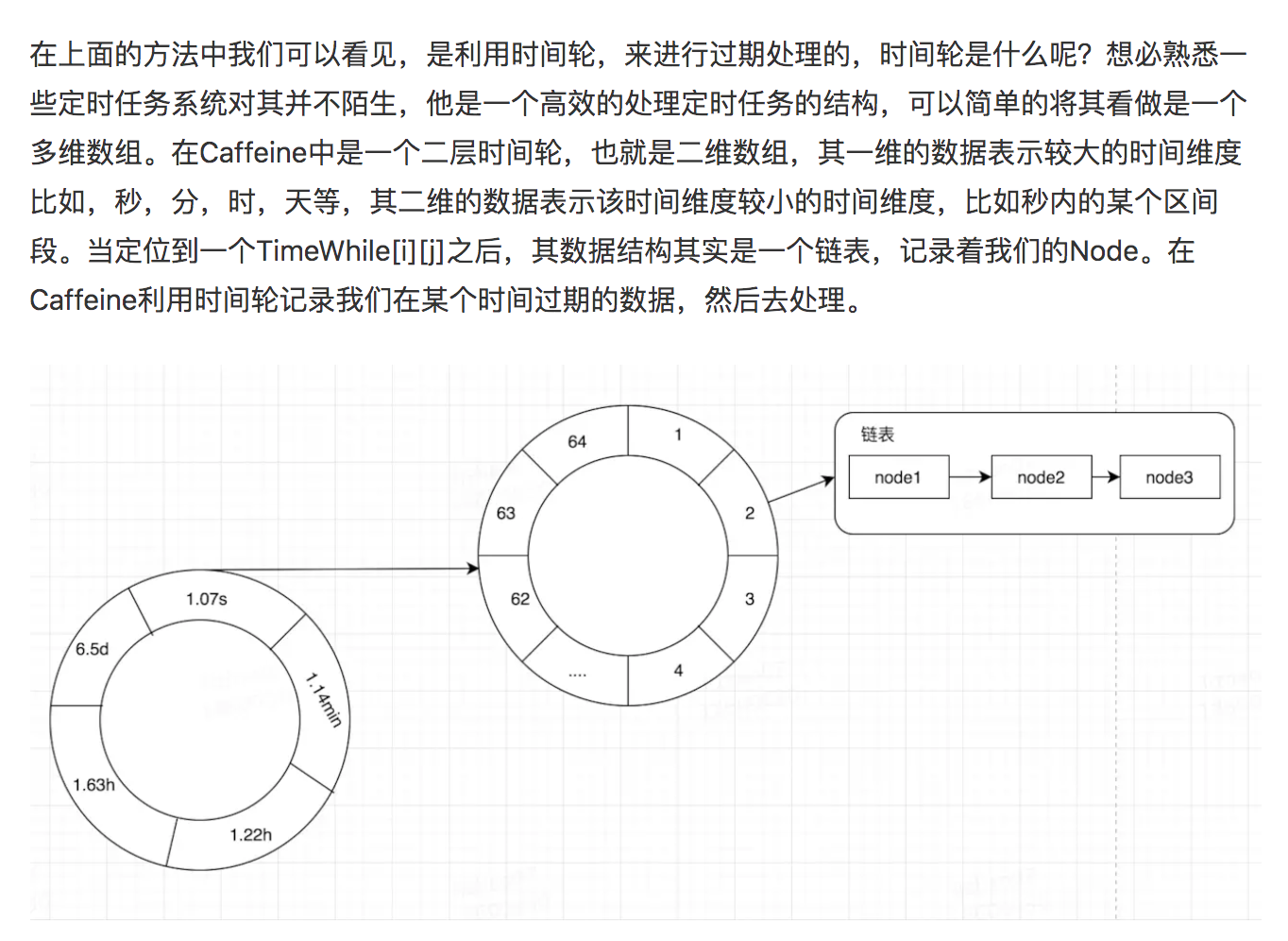
在Caffeine中的时间轮如上面所示。在我们插入数据的时候,根据我们重写的方法计算出他应该过期的时间,比如他应该在1536046571142时间过期,上一次处理过期时间是1536046571100,对其相减则得到42ms,然后将其放入时间轮,由于其小于1.07s,所以直接放入1.07s的位置,以及第二层的某个位置(需要经过一定的算法算出),使用尾插法插入链表。
处理过期时间的时候会算出上一次处理的时间和当前处理的时间的差值,需要将其这个时间范围之内的所有时间轮的时间都进行处理,如果某个Node其实没有过期,那么就需要将其重新插入进时间轮。
3.5知己知彼-打点监控
在Caffeine中提供了一些的打点监控策略,通过recordStats()Api进行开启,默认是使用Caffeine自带的,也可以自己进行实现。 在StatsCounter接口中,定义了需要打点的方法目前来说有如下几个:
- recordHits:记录缓存命中
- recordMisses:记录缓存未命中
- recordLoadSuccess:记录加载成功(指的是CacheLoader加载成功)
- recordLoadFailure:记录加载失败
- recordEviction:记录淘汰数据
通过上面的监听,我们可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后续调整参数。
3.6有始有终-淘汰监听
有很多时候我们需要知道Caffeine中的缓存为什么被淘汰了呢,从而进行一些优化?这个时候我们就需要一个监听器,代码如下所示:
Cache<String, String> cache = Caffeine.newBuilder()
.removalListener(((key, value, cause) -> {
System.out.println(cause);
}))
.build();
复制代码在Caffeine中被淘汰的原因有很多种:
- EXPLICIT: 这个原因是,用户造成的,通过调用remove方法从而进行删除。
- REPLACED: 更新的时候,其实相当于把老的value给删了。
- COLLECTED: 用于我们的垃圾收集器,也就是我们上面减少的软引用,弱引用。
- EXPIRED: 过期淘汰。
- SIZE: 大小淘汰,当超过最大的时候就会进行淘汰。
当我们进行淘汰的时候就会进行回调,我们可以打印出日志,对数据淘汰进行实时监控。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
实践使用例子:
填充策略(Population)
Caffeine 给我们提供了三种填充策略:手动、同步和异步

Cache接口允许显式的去控制缓存的检索,更新和删除。
我们通过cache.getIfPresent(key) 方法来获取一个key的值,通过cache.put(key, value)方法显示的将数控放入缓存,但是这样也会覆盖缓原来key的数据。所以更加推荐使用cache.get(key,k - > value) 的方式,get 方法将一个参数为 key 的 Function (createExpensiveGraph) 作为参数传入。如果缓存中不存在该键,则调用这个 Function 函数,并将返回值作为该缓存的值插入缓存中。get 方法是以阻塞方式执行调用,哪怕再多个线程同时请求该值也只会调用一次Function方法。这样就可以避免了与其他线程的写入竞争,这就是为什么要使用 get 优于 getIfPresent 的原因。
注意:如果调用该方法返回NULL(如上面的 createExpensiveGraph 方法),则cache.get返回null,如果调用该方法抛出异常,则get方法也会抛出异常。
可以使用Cache.asMap() 方法获取ConcurrentMap进而对缓存进行一些更改。
手动加载(Manual)
Cache<String, Object> manualCache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
String key = "name1";
// 根据key查询一个缓存,如果没有返回NULL
graph = manualCache.getIfPresent(key);
// 根据Key查询一个缓存,如果没有调用createExpensiveGraph方法,并将返回值保存到缓存。
// 如果该方法返回Null则manualCache.get返回null,如果该方法抛出异常则manualCache.get抛出异常
graph = manualCache.get(key, k -> createExpensiveGraph(k));
// 将一个值放入缓存,如果以前有值就覆盖以前的值
manualCache.put(key, graph);
// 删除一个缓存
manualCache.invalidate(key);
ConcurrentMap<String, Object> map = manualCache.asMap();
cache.invalidate(key);
Cache接口允许显式的去控制缓存的检索,更新和删除。
我们可以通过cache.getIfPresent(key) 方法来获取一个key的值,通过cache.put(key, value)方法显示的将数控放入缓存,但是这样子会覆盖缓原来key的数据。更加建议使用cache.get(key,k - > value) 的方式,get 方法将一个参数为 key 的 Function (createExpensiveGraph) 作为参数传入。如果缓存中不存在该键,则调用这个 Function 函数,并将返回值作为该缓存的值插入缓存中。get 方法是以阻塞方式执行调用,即使多个线程同时请求该值也只会调用一次Function方法。这样可以避免与其他线程的写入竞争,这也是为什么使用 get 优于 getIfPresent 的原因。
注意:如果调用该方法返回NULL(如上面的 createExpensiveGraph 方法),则cache.get返回null,如果调用该方法抛出异常,则get方法也会抛出异常。
可以使用Cache.asMap() 方法获取ConcurrentMap进而对缓存进行一些更改。

批量查找可以使用getAll方法。默认情况下,getAll将会对缓存中没有值的key分别调用CacheLoader.load方法来构建缓存的值。我们可以重写CacheLoader.loadAll方法来提高getAll的效率。
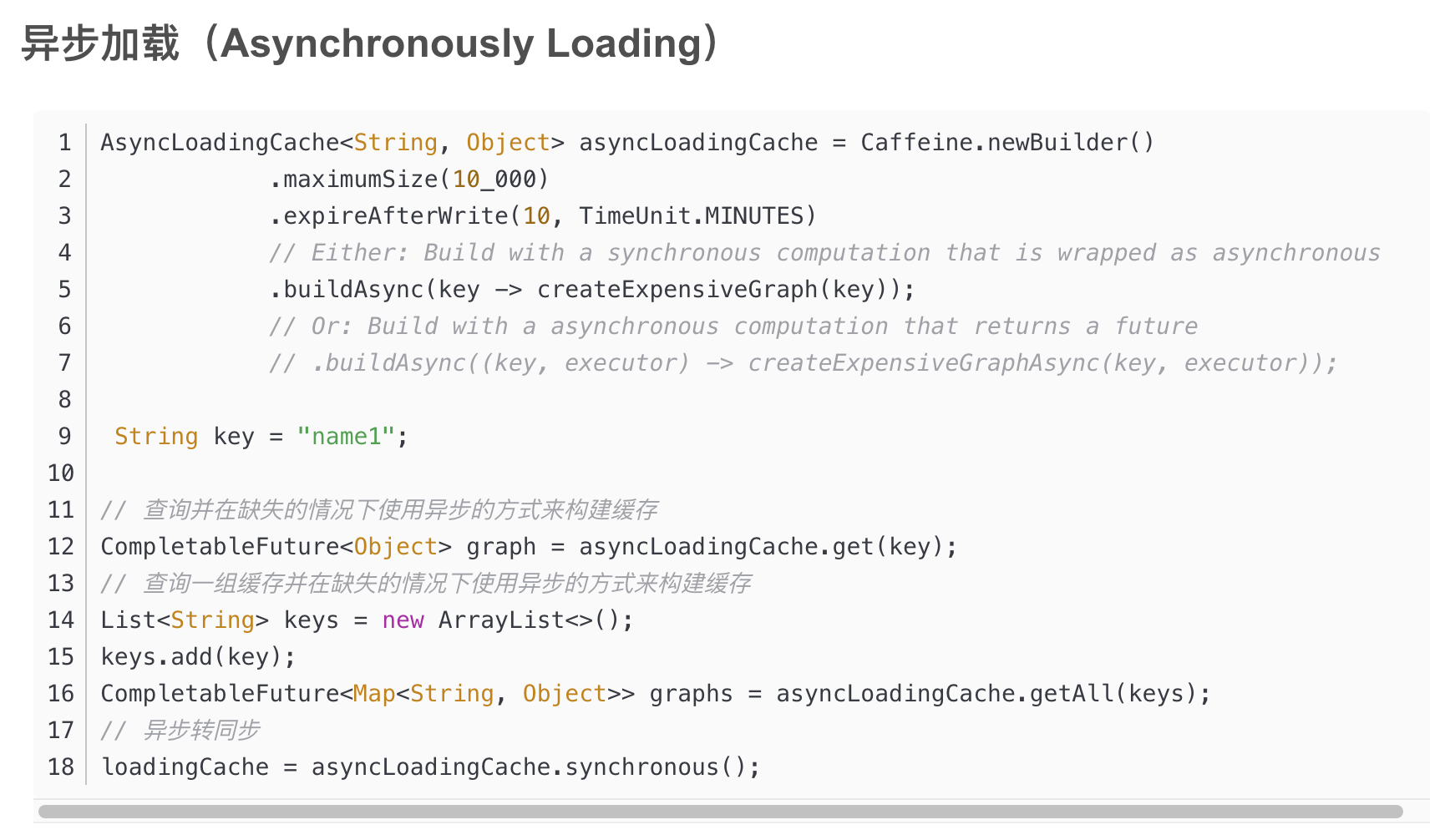
AsyncLoadingCache是继承自LoadingCache类的,异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
synchronous()这个方法返回了一个LoadingCacheView视图,LoadingCacheView也继承自LoadingCache。调用该方法后就相当于你将一个异步加载的缓存AsyncLoadingCache转换成了一个同步加载的缓存LoadingCache。
默认使用ForkJoinPool.commonPool()来执行异步线程,但是我们可以通过Caffeine.executor(Executor) 方法来替换线程池。
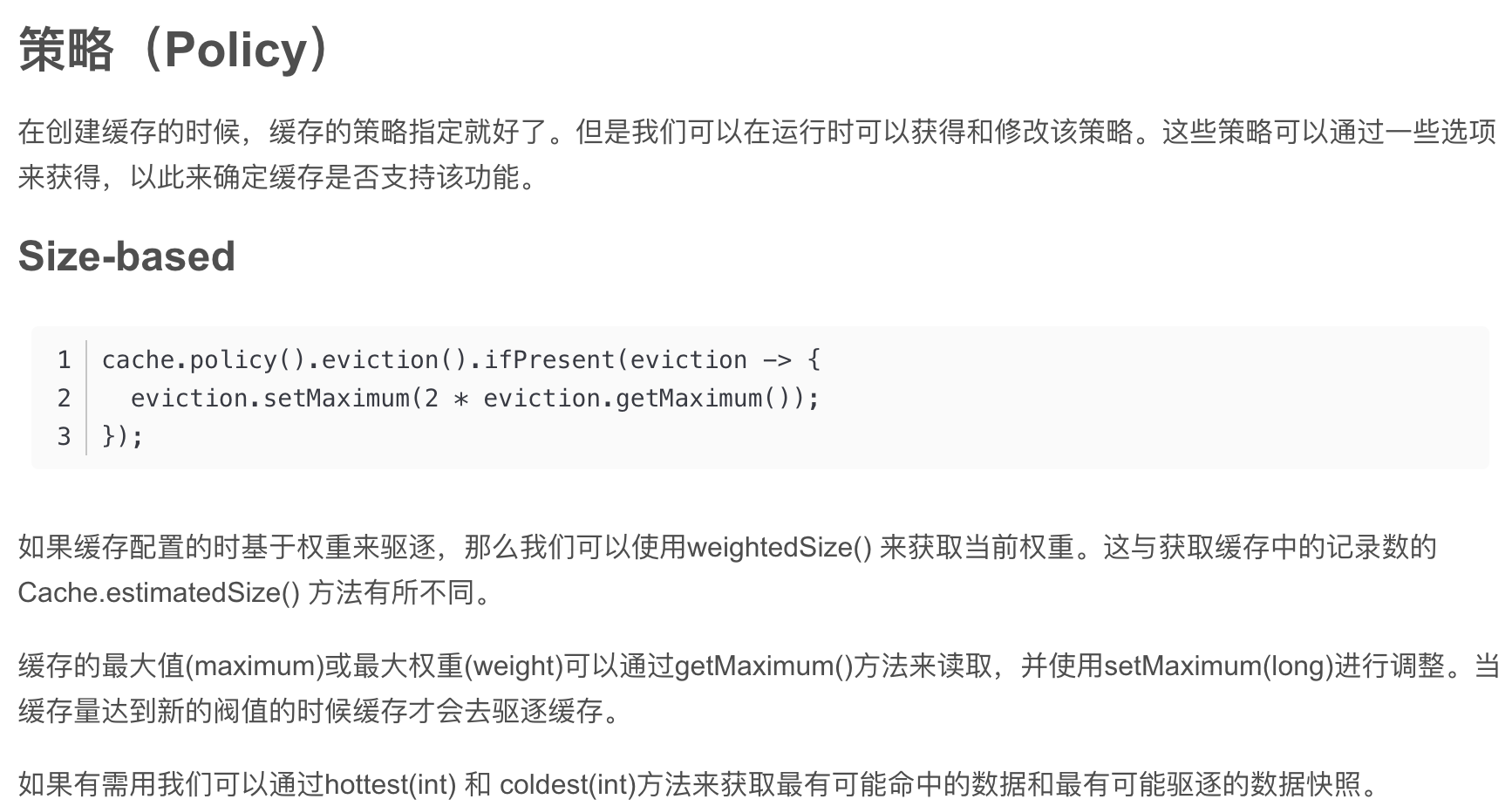
驱逐策略(eviction)
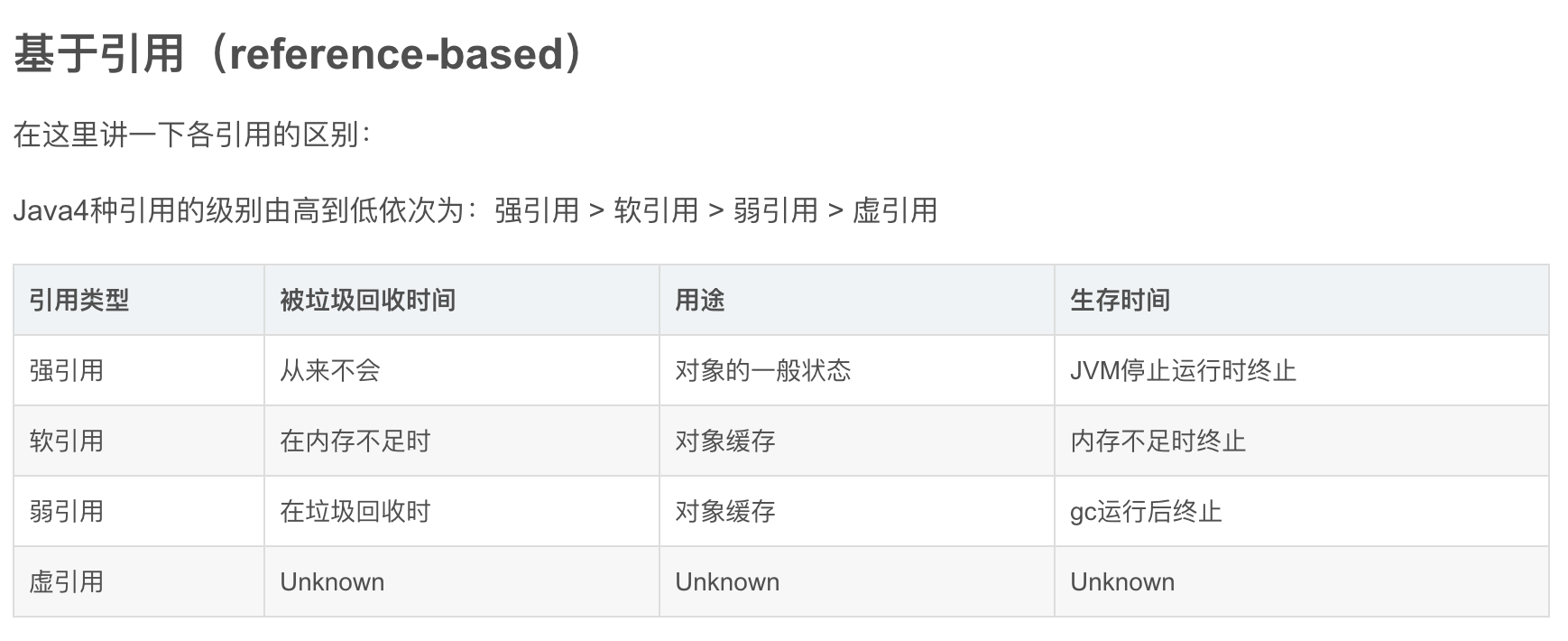
Caffeine提供三类驱逐策略:基于大小(size-based),基于时间(time-based)和基于引用(reference-based)
基于大小(size-based)
基于大小驱逐,有两种方式:一种是基于缓存大小,一种是基于权重。

我们可以使用Caffeine.maximumSize(long)方法来指定缓存的最大容量。当缓存超出这个容量的时候,会使用Window TinyLfu策略来删除缓存。
我们也可以使用权重的策略来进行驱逐,可以使用Caffeine.weigher(Weigher) 函数来指定权重,使用Caffeine.maximumWeight(long) 函数来指定缓存最大权重值。
maximumWeight与maximumSize不可以同时使用。
基于时间(Time-based)

Caffeine提供了三种定时驱逐策略:
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry): 自定义策略,过期时间由Expiry实现独自计算。
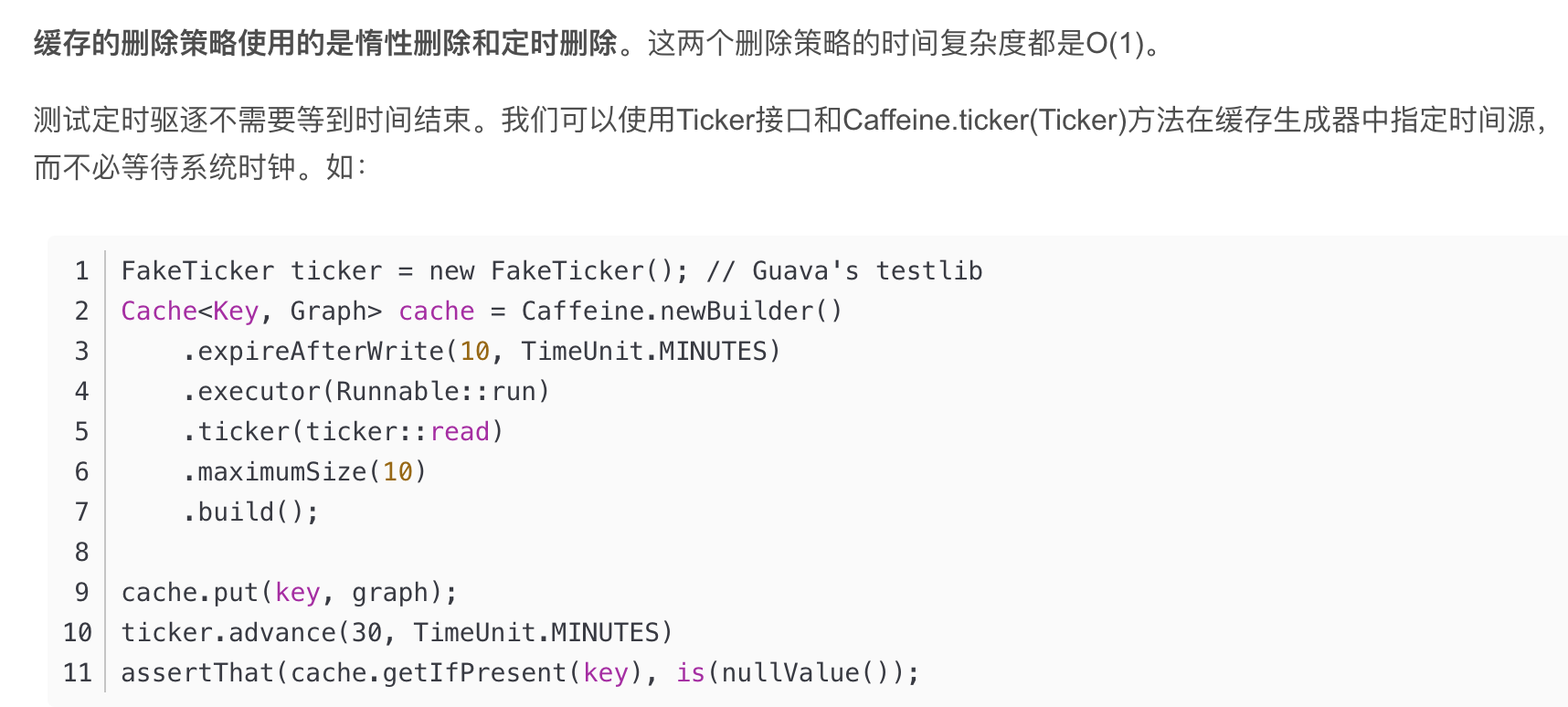

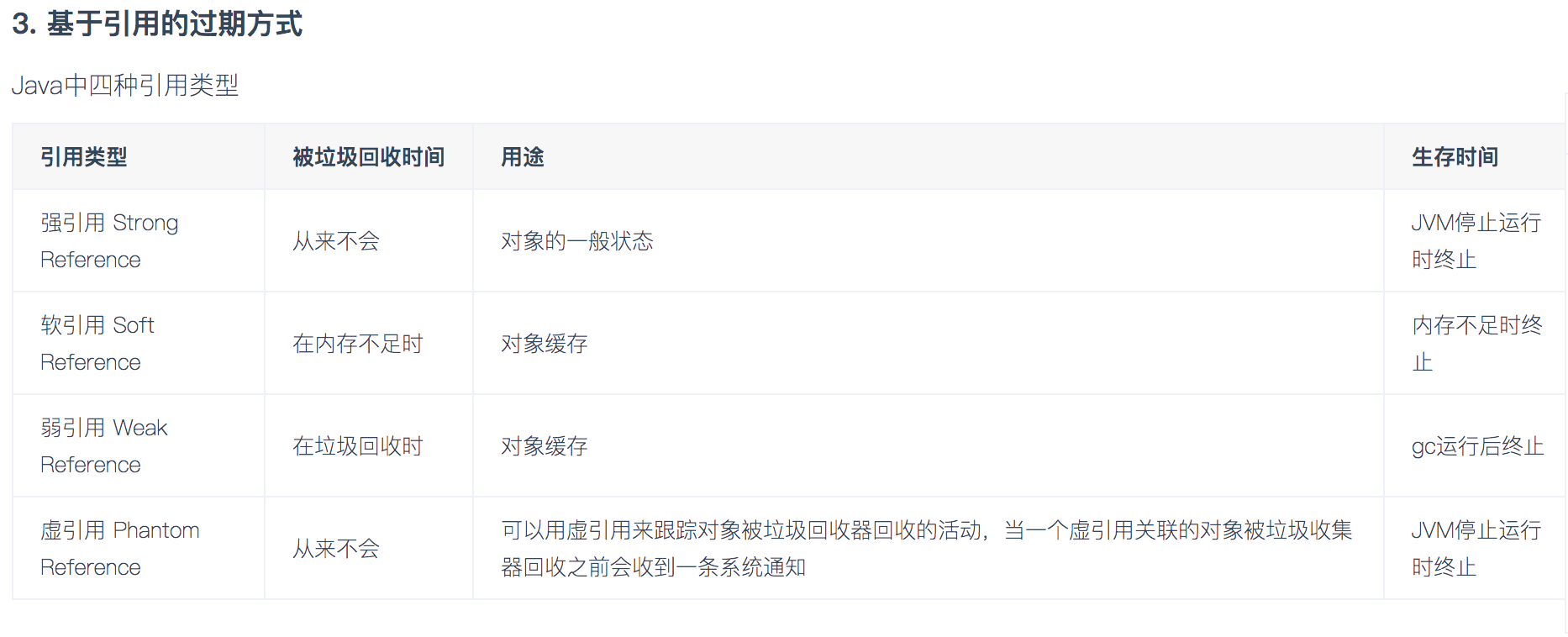
注意:Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。 弱引用和软引用不能一起使用

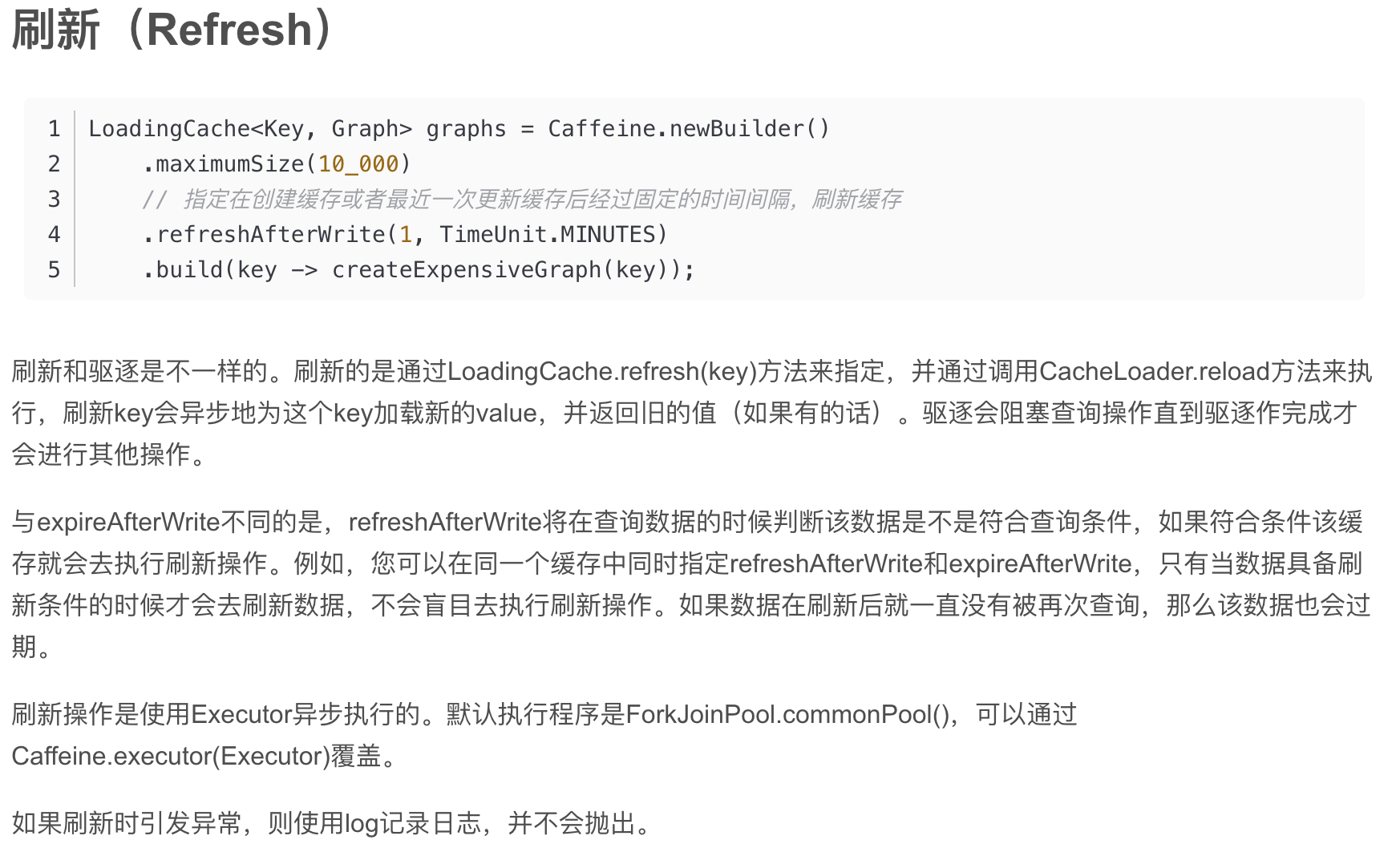
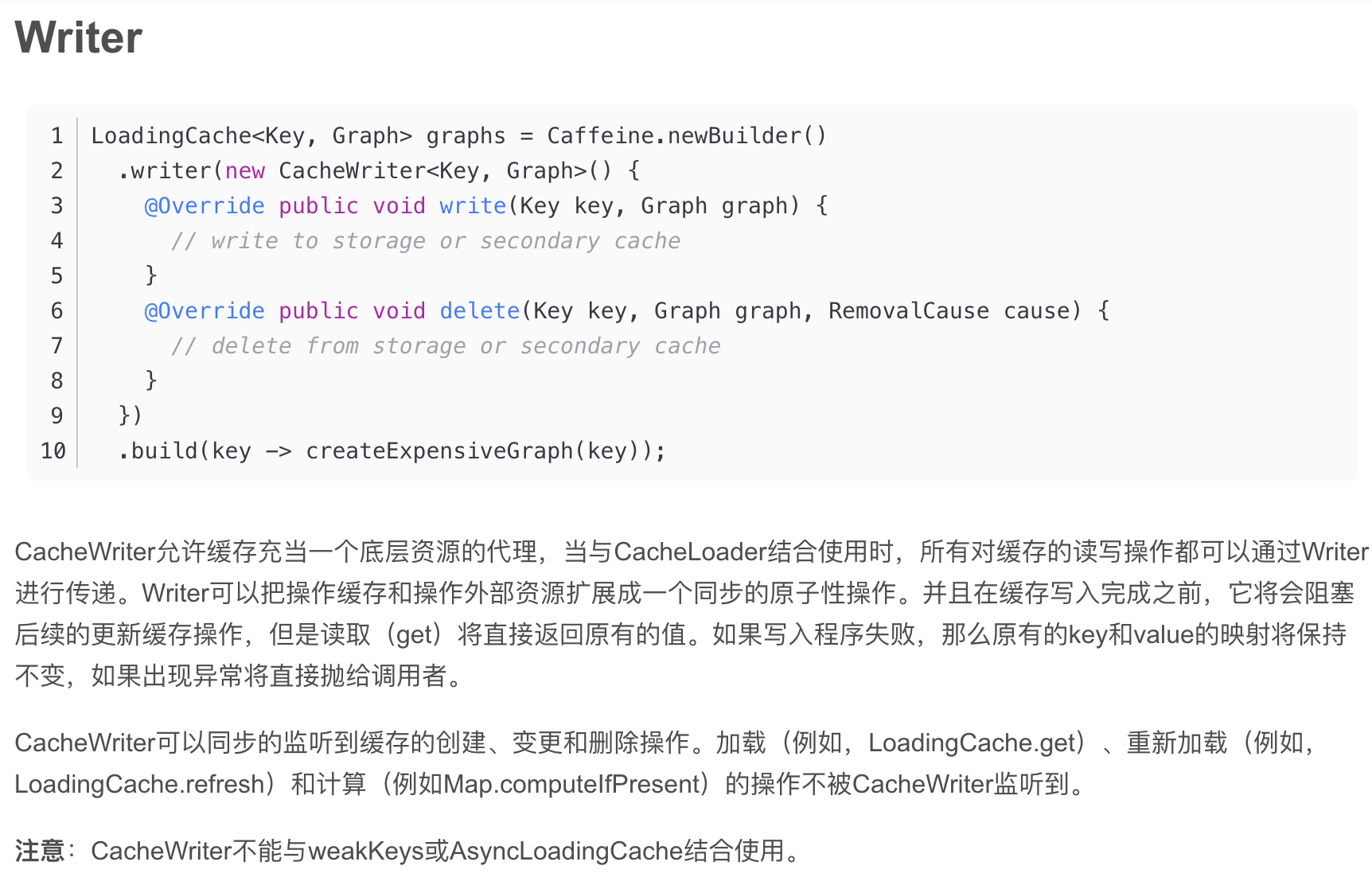







++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++



TinyLFU采用了一种基于滑动窗口的时间衰减设计机制,借助于一种简易的reset操作:每次添加一条记录到Sketch的时候,都会给一个计数器上加1,当计数器达到一个尺寸W的时候,把所有记录的Sketch数值都除以2,该reset操作可以起到衰减的作用



最后
以上就是乐观荔枝最近收集整理的关于Caffeine cache 学习01填充策略(Population)手动加载(Manual)驱逐策略(eviction)的全部内容,更多相关Caffeine内容请搜索靠谱客的其他文章。








发表评论 取消回复