一版本
版本实现根据访问的的方式有以下几种
a : https://127.0.0.1:8000/users?version=v1 ---->基于url的get方式
#settings.py
REST_FRAMEWORK = { 'DEFAULT_VERSION': 'v1', # 默认版本 'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本 'VERSION_PARAM': 'version' # URL中获取值的key }
#urls.py
urlpatterns = [ url(r'^users/', views.UserView.as_view(),name='xxx'), ]
# views.py
from django.shortcuts import render, HttpResponse
from rest_framework.views import APIView
from rest_framework.versioning import QueryParameterVersioning
from django import forms
from django.urls import reverse
class UserView(APIView):
versioning_class = QueryParameterVersioning
def get(self, request, *args, **kwargs):
print(request.version)
print(request.versioning_scheme) #<rest_framework.versioning.URLPathVersioning object at 0x000001330C3135F8>
u1=request.versioning_scheme.reverse(viewname='xxx',request=request)
print(u1) #http://127.0.0.1:8000/api/users/?version=v1
return HttpResponse('用户列表')
b: https://127.0.0.1:8000/api/v1/users/ ---》基于url的正则方式(常用)
#urls.py
from django.conf.urls import url
from api import views
urlpatterns=[ url(r'^(?P<version>[v1|v2]+)/users/$', views.UserView.as_view(),name="uuu"), ]
#views.py
from django.shortcuts import render, HttpResponse
from rest_framework.views import APIView
from rest_framework.versioning import URLPathVersioning
from django import forms
from django.urls import reverse
class UserView(APIView):
versioning_class = URLPathVersioning
def get(self, request, *args, **kwargs):
print(request.version)
print(request.versioning_scheme) #<rest_framework.versioning.URLPathVersioning object at 0x000001330C3429320>
u1=request.versioning_scheme.reverse(viewname='uuu',request=request)
print(u1) #http://127.0.0.1:8000/api/v1/users/
return HttpResponse('用户列表')
上面的reverse的方法可以通过使用django本身的reverse方法去做
#views.py from django.urls import reverse
class UserView(APIView):
def get(self, request, *args, **kwargs):
u2=reverse(viewname='uuu',kwargs={'version':1}) #使用django内置的reverse,需要传参version,他就不会去url里面找,而是在参数里面找版本
print(u2) #/api/1/users/
它解析出来的结果没有前面的地址
return HttpResponse('用户列表')
c:rest framework还有三种方式:不太常用
AcceptHeaderVersioning ,NamespaceVersioning ,HostNameVersioning
d: 综合写入全局配置
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'api.apps.ApiConfig',
'rest_framework',
]
REST_FRAMEWORK = { 'DEFAULT_VERSIONING_CLASS':"rest_framework.versioning.URLPathVersioning", #使用哪种版本类 'DEFAULT_VERSION': 'v1', #默认的版本号 'ALLOWED_VERSIONS': ['v1', 'v2'], #允许使用的版本列表 'VERSION_PARAM': 'version' #版本关键字 }
二 解析器 Parser,使用request.data时触发
Parser是根据content-type选择对应的解析器就请求内容进行处理
下面是不同的解析器处理对应的content-type
JSONParser | 处理请求头content-type为application/json的请求体 |
FormParser | 处理请求头content-type为application/x-www-form-urlencoded 的请求体 |
MultiPartParser | 处理请求头content-type为multipart/form-data的请求体 |
FileUploadParser | 上传文件 |
下面来举个例子
#urls.py from django.conf.urls import url from api import views urlpatterns = [ url(r'^(?P<version>[v1|v2]+)/parser/$', views.ParserView.as_view()), ]
#views.py from rest_framework.parsers import JSONParser,FormParser class ParserView(APIView): parser_classes = [JSONParser,FormParser] ''' JSONParser:表示只能解析content-type:application/json头 FormParser:表示只能解析content-type:application/x-www-form-urlencoded头 ''' def post(self,request,*args,**kwargs): ''' 允许用户发送JSON数据 content-type:application/json {'name':'dawn'} :param request: :param args: :param kwargs: :return: ''' #获取解析后的结果 print(request.data) return HttpResponse('ParserView')
写入全局配置
# settings.py REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES':[ 'rest_framework.parsers.JSONParser' 'rest_framework.parsers.FormParser' 'rest_framework.parsers.MultiPartParser' ] }
三 序列化
对用户请求数据进行验证和数据进行序列化,系列化对象可以时queryset和model对象
参数:many=True代表系列化的是QuerySet,其默认为False
num 1:数据的序列化
1 最原始的使用
#views.py from rest_framework import serializers class RolesSerializer(serializers.Serializer): id=serializers.IntegerField() title=serializers.CharField() class RolesView(APIView): def get(self,request,*args,**kwargs): #方式一 # roles=models.Role.objects.all().values('id','title') # roles=list(roles) # ret=json.dumps(roles,ensure_ascii=False) #ensure_ascii 让页面显示中文 #方式二,对多个对象进行序列化 # roles = models.Role.objects.all() # ser=RolesSerializer(instance=roles,many=True) # ret=json.dumps(ser.data,ensure_ascii=False) #对单个对象进行序列化 roles = models.Role.objects.all().first() ser=RolesSerializer(instance=roles,many=False) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
2 使用 serializers.Serializer自定义字段
#views.py from rest_framework import serializers class UserInfoSerializer(serializers.Serializer): user_type_1=serializers.CharField(source="user_type") user_type_2=serializers.CharField(source="get_user_type_display") username=serializers.CharField() password=serializers.CharField() gp=serializers.CharField(source="group.title") rls=serializers.SerializerMethodField() #自定义显示 def get_rls(self,row): role_obj_list=row.roles.all() ret=[] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret class UserInfoView(APIView): def get(self,request,*args,**kwargs): users=models.UserInfo.objects.all() ser=UserInfoSerializer(instance=users,many=True) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
3 通过serializers.ModelSerializer的方式自动生成字段,避免了上面写各个字段的情况
from rest_framework import serializers
class UserInfoSerializer(serializers.ModelSerializer): user_type=serializers.CharField(source="get_user_type_display") rls=serializers.SerializerMethodField() #自定义显示 class Meta: model=models.UserInfo fields=['id','username','password','user_type','rls',] def get_rls(self,row): role_obj_list=row.roles.all() ret=[] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret class UserInfoView(APIView): def get(self,request,*args,**kwargs): users=models.UserInfo.objects.all() ser=UserInfoSerializer(instance=users,many=True) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
结果显示
[{"id": 1, "username": "liu", "password": "123", "user_type": "普通用户", "rls": [{"id": 1, "title": "医生"}, {"id": 2, "title": "老师"}, {"id": 3, "title": "园"}]}, {"id": 2, "username": "ming", "password": "123", "user_type": "VIP", "rls": [{"id": 1, "title": "医生"}]}]
4 最后出现了depth 的参数,上面可以更简单了,depth = num (0<=num<=10)
class UserInfoSerializer(serializers.ModelSerializer):class Meta: model=models.UserInfo # fields=['id','username','password','user_type','rls',] fields = "__all__" depth = 1
class UserInfoView(APIView): def get(self,request,*args,**kwargs): users=models.UserInfo.objects.all() ser=UserInfoSerializer(instance=users,many=True) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
depth =0的结果,它只停留在数字层面,也就是说,它关联的表不会显示


[ { "id": 1, "user_type": 1, "username": "liu", "password": "123", "group": 1, "roles": [ 1, 2, 3 ] }, { "id": 2, "user_type": 2, "username": "ming", "password": "123", "group": 1, "roles": [ 1 ] } ]
depth = 1 的结果
[ { "id": 1, "user_type": 1, "username": "liu", "password": "123", "group": { "id": 1, "title": "A组" }, "roles": [ { "id": 1, "title": "医生" }, { "id": 2, "title": "老师" }, { "id": 3, "title": "园" } ] }, { "id": 2, "user_type": 2, "username": "ming", "password": "123", "group": { "id": 1, "title": "A组" }, "roles": [ { "id": 1, "title": "医生" } ] } ]
总结:depth深度,就是将它关联的表一层一层剥离,根据数字的不同剥离的层级不同,针对foreignkey 和manytomany
5 在上一篇文章的api规范中第十条是这么说的:Hypermedia API,返回结果提供可以连向其他api的方法,让用户直接使用
我们通过序列化对其进行配置,下面我们通过给group制定url,使它可以连上其他的url,得知group的详细信息
# urls.py urlpatterns = [ url(r'^(?P<version>[v1|v2]+)/group/(?P<num>d+)$', views.GroupView.as_view(),name='gp'), ]
#views.py class UserInfoSerializer(serializers.ModelSerializer): group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id',lookup_url_kwarg='num') class Meta: model=models.UserInfo fields=['id','username','password','group','roles',] # fields = "__all__" depth = 1 class UserInfoView(APIView): def get(self,request,*args,**kwargs): users=models.UserInfo.objects.all() ser=UserInfoSerializer(instance=users,many=True,context={'request':request}) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret) ################################################################################################### class GroupSerializer(serializers.ModelSerializer): class Meta: model = models.UserGroup fields='__all__' class GroupView(APIView): def get(self,request,*args,**kwargs): pk=kwargs.get('num') obj=models.UserGroup.objects.filter(pk=pk).first() ser=GroupSerializer(instance=obj,many=False) ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret)
首先我们访问:http://127.0.0.1:8000/api/v1/userinfo/ 我们得到下面的结果
[ { "id": 1, "username": "liu", "password": "123", "group": "http://127.0.0.1:8000/api/v1/group/1", "roles": [ { "id": 1, "title": "医生" }, { "id": 2, "title": "老师" }, { "id": 3, "title": "园" } ] }, { "id": 2, "username": "ming", "password": "123", "group": "http://127.0.0.1:8000/api/v1/group/1", "roles": [ { "id": 1, "title": "医生" } ] } ]
注意上面group后面跟着的url,通过这个url我们可以点击它,得到group的详细信息
http://127.0.0.1:8000/api/v1/group/1 结果: {"id": 1, "title": "A组"}
下面我们来对数据的系列化进行一个总结:
class UserInfoView(APIView): def get(self,request,*args,**kwargs): users=models.UserInfo.objects.all() # 1 实例化,将数据封装到对象 ''' many=True,接下来执行ListSerializer对象的构造方法 __init__ many=False,接下来执行UserInfoSerializer对象的构造方法 ''' ser=UserInfoSerializer(instance=users,many=True,context={'request':request}) #2 调用对象的data属性 #找 to_representation方法 # for field in fields: # try: # attribute=field.get_attribute(instance) # except SkipField: # continue #它去数据库中获取指定字段对应的值,比如:id:attribute=1,pwd:attribute=123 #对于HyperlinkedIdentyField:obj(取的是对象) #接着执行每个字段的to_representation方法,对应charfield,它返回的是return str(value) #对于HyperlinkedIdentyField,它通过查找lookup_field去数据库拿值,在根据view_name 和lookup_url_kwarg #的值反向生成url ret=json.dumps(ser.data,ensure_ascii=False) return HttpResponse(ret) def post(self,request,*args,**kwargs): print(request.data) return HttpResponse('提交数据')
num2:数据的验证
class UserGroupSerializer(serializers.Serializer): title=serializers.CharField(error_messages={'required':'标题不能为空'},validators=[xxxValidator('星s'),]) def validate_title(self,value): #对用户传入的value值做判断 if '苍井空' in value: from rest_framework import exceptions raise exceptions.ValidationError('含有非法字符') return value class UserGroupView(APIView): def post(self,request,*args,**kwargs): # print(request.data) ser=UserGroupSerializer(data=request.data) ret="" if ser.is_valid(): ret=ser.validated_data['title'] else: ret=ser.errors['title'][0] #含有非法字符 print(ret) return HttpResponse(ret)
测试显示
传入 {‘title':'星sxxxxxx'}
--->结果 星sxxxxxx
传入 {'title':'星s苍井空xx'}
--->结果 含有非法字符
传入 {'title':'hhhhhh'}
---->结果 标题必须以 星s 为开头。
四 分页
rest_framework有三种方式:
1 根据第几页,每页显示几条数据,来显示数据 2 在目前的位置,先后查看n条数据 3 根据目前的位置以及给出的前后页的跳转连接,查看数据 此方式因为关键参数加密了,所有人为输入页数将无效
下面我们将一一实现
首先:设置一个路由
urlpatterns=[ url(r'^(?P<version>[v1|v2]+)/mypage/$', views.PageView.as_view()), ]
方式一:PageNumberPagination ,默认参数 page、size
#from api.utils.serializers.page import PagerSerialiser
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination
from rest_framework import serializers
from api import models
class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model=models.Role
fields="__all__"
class MyPageNumberPagination(PageNumberPagination):
page_size=2 #页面默认显示几条
page_size_query_param = 'size' #可以写成 page_size_query_param = '大小'
max_page_size = None
page_query_param='page' #可以写成 page_query_param='页面'
class PageView(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles=models.Role.objects.all().order_by('id')
#创建分页对象
pg=MyPageNumberPagination()
#在数据库中获取分页的数据
page_roles=pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles, many=True)
return Response(ser.data)
此时通过不同的参数得出不同的效果,找不到默认的参数时,显示第一页,两条数据
http://127.0.0.1:8000/api/v1/mypage/?page=2&size=3
----》第二页,每页显示三条数据
http://127.0.0.1:8000/api/v1/mypage/?yemian=2&daxiao=3
[
{
"id": 4, "title": "你" }, { "id": 5, "title": "我" }, { "id": 6, "title": "他" } ]
方式二:LimitOffsetPagination ,关键字 offset, limit ---->offset :相对第一条数据相隔几个,可单纯的认为是索引,从0开始,limit:相当于上面方法的size
from rest_framework.response import Response
from rest_framework.pagination import LimitOffsetPagination
class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit=2
limit_query_param = 'limit'
offset_query_param = 'offset'
max_limit=5
from rest_framework import serializers
from api import models
class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model=models.Role
fields="__all__"
class PageView(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles=models.Role.objects.all().order_by('id')
#创建分页对象
pg=MyLimitOffsetPagination()
#在数据库中获取分页的数据
page_roles=pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles, many=True)
return Response(ser.data)
访问:http://127.0.0.1:8000/api/v1/mypage/?offset=1&limit=3
[
{
"id": 2, "title": "老师" }, { "id": 3, "title": "园" }, { "id": 4, "title": "你" } ]
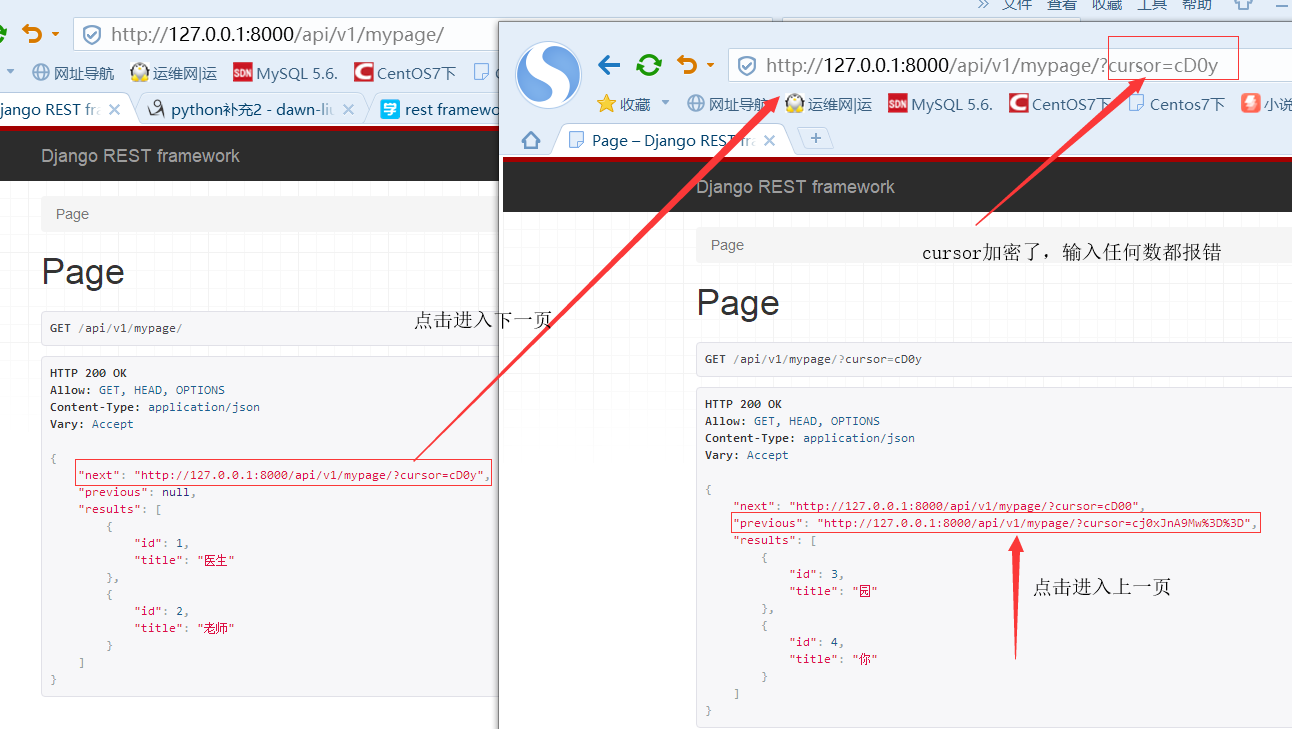
方式三:CursorPagination ,默认关键字 cursor
from rest_framework.pagination import CursorPagination
class MyCursorPagination(CursorPagination):
cursor_query_param='cursor'
page_size = 2
ordering = 'id' #根据某个字段排列
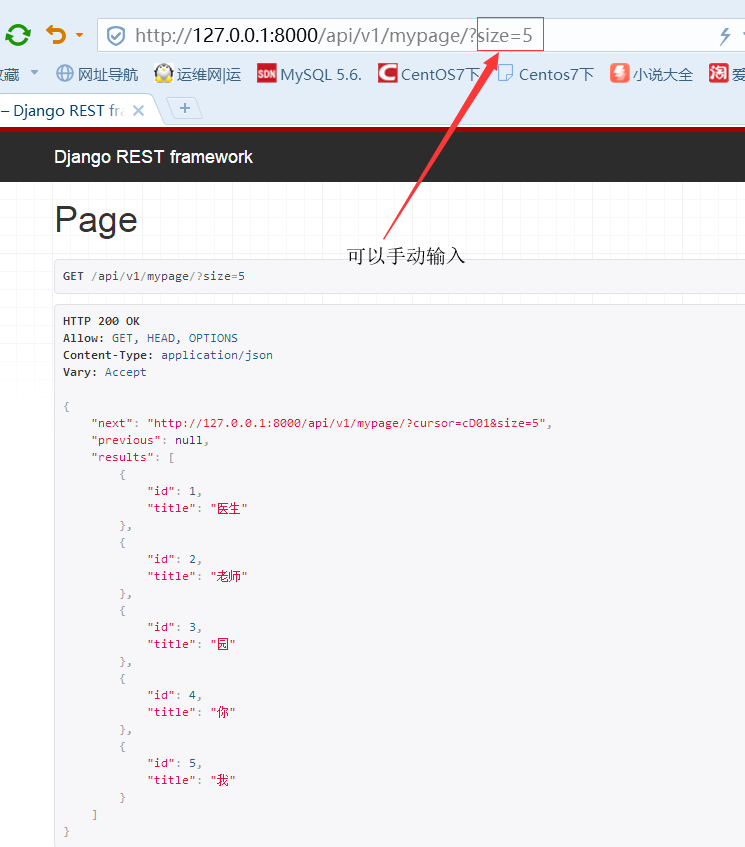
page_size_query_param = 'size' #默认为None,此配置不加密可以设置每页显示几条
max_page_size = None
from rest_framework import serializers
from api import models
class PagerSerialiser(serializers.ModelSerializer):
class Meta:
model=models.Role
fields="__all__"
class PageView(APIView):
def get(self,request,*args,**kwargs):
#获取所有数据
roles=models.Role.objects.all().order_by('id')
#创建分页对象
pg=MyCursorPagination()
#在数据库中获取分页的数据
page_roles=pg.paginate_queryset(queryset=roles,request=request,view=self)
#对数据进行序列化
ser = PagerSerialiser(instance=page_roles, many=True)
# return Response(ser.data)
return pg.get_paginated_response(ser.data) #这里使用不同的方式返回给用户
访问:http://127.0.0.1:8000/api/v1/mypage/
{
"next": "http://127.0.0.1:8000/api/v1/mypage/?cursor=cD0y", #点击可进入下一页 "previous": null, "results": [ { "id": 1, "title": "医生" }, { "id": 2, "title": "老师" } ] }
效果看下图
但是设置好的size可以手动输入
转载于:https://www.cnblogs.com/mmyy-blog/p/10830898.html
最后
以上就是愤怒电源最近收集整理的关于rest framework的框架实现之 (版本,解析器,序列化,分页)的全部内容,更多相关rest内容请搜索靠谱客的其他文章。








发表评论 取消回复