我是靠谱客的博主 完美悟空,这篇文章主要介绍二八论文 - TextRank: Bringing Order into Texts 论文解读论文标题发表日期方向、领域、解决问题论文重点摘要(只看了关键词提取部分)论文中的符号顶点得分的计算公式算法步骤,现在分享给大家,希望可以做个参考。
二八论文系列是指让以后的自己或者读者可以花百分之二十的时间读懂该论文的百分之八十。
论文标题
TextRank: Bringing Order into Texts
发表日期
2004.12
方向、领域、解决问题
使用无向有权的方法,对文本中的词构建图,实现关键词抽取、句子相似度匹配、句子提取等任务
论文重点摘要(只看了关键词提取部分)
- TextRank 是一种基于无向图的无监督文本关键词抽取和文本相似度计算模型
- 基于图的排序算法本质上是一种决定图中顶点重要性的方法,它基于从整个图中递归地提取的全局信息。基于图的排名模型所实现的基本思想是**“投票”或“推荐”**。当一个顶点链接到另一个顶点时,它基本上是在为另一个顶点进行投票。投给一个顶点的投票次数越高,这个顶点的重要性就越高与一个顶点相关联的分数是根据为它所投下的投票以及投下这些投票的顶点的分数来确定的。
- TextRank 的一个优点是对文本大小不受限制
- 图中的边由两个顶点在最大为N的窗口中的共现情况表示,N通常为2-10
- 添加到图中的顶点可以通过语法过滤器进行限制,该过滤器只选择某一词性部分的词汇单位。例如,我们可以只考虑名词和动词来添加到图中,因此只能根据名词和动词之间可以建立的关系来绘制潜在的边。我们实验了各种句法过滤器,包括:所有开放类词、名词和动词等,仅对名词和形容词的效果最好
- 算法通常为20-30次迭代,阈值为0.0001
论文中的符号
- G=(V, E)表示有向图
- V表示顶点的集合
- E表示边的集合,也就是两个点的连接
- In(Vi)是指向顶点Vi的顶点集合
- Out(Vi)是顶点Vi指向的顶点集合
顶点得分的计算公式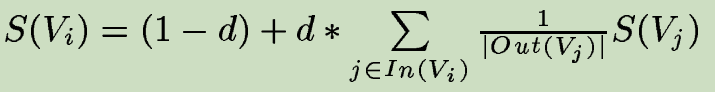
- d是阻尼因子,位于0-1之间,作用是对给定顶点跳到另一个随机顶点的概率做积分,解决了dead ends的问题,通常被设置为0.85
- 从分配给图中每个节点的任意值开始,计算不断迭代,直到收敛到低于给定的阈值
- 运行算法后,每个顶点都有一个分数,它表示图中顶点的“重要性”,TextRank运行到完成后获得的最终值不受初始值选择的影响,只有收敛的迭代次数可能不同。
- 对于松散连接的图,由于边数与顶点数成正比,无向图往往具有更渐进的收敛曲线。
- 不同规格的内容都可以作为顶点,例如单词、单词集合、句子
算法步骤
- 识别最能定义手头任务的文本单位,并将它们添加为图中的顶点
- 识别连接这些文本单元的关系,并使用这些关系来绘制图中顶点之间的边。可以是定向的或无向的、加权的或非加权的
- 迭代基于图的排序算法,直到收敛
- 根据它们最终的分数对顶点进行排序
最后
以上就是完美悟空最近收集整理的关于二八论文 - TextRank: Bringing Order into Texts 论文解读论文标题发表日期方向、领域、解决问题论文重点摘要(只看了关键词提取部分)论文中的符号顶点得分的计算公式算法步骤的全部内容,更多相关二八论文内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复