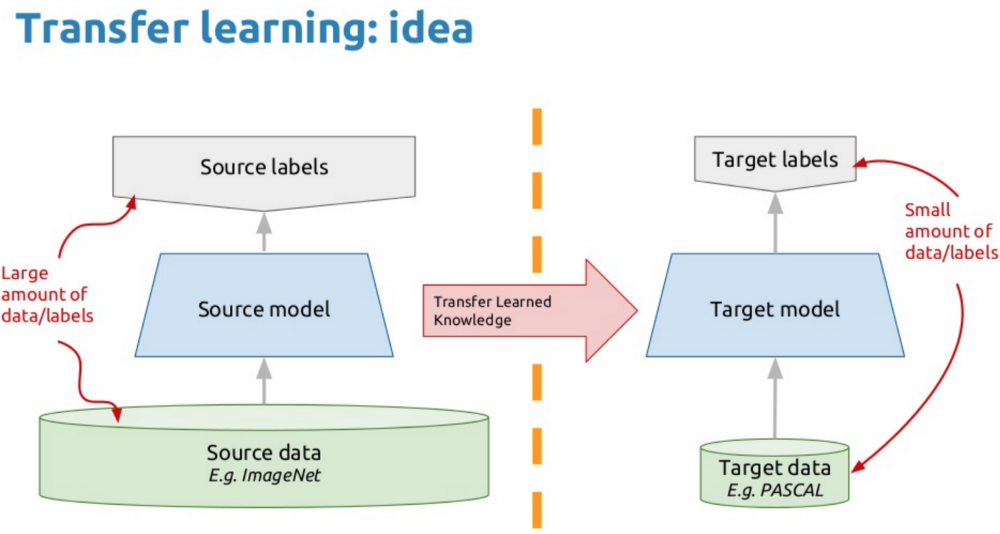
迁移学习是什么?
即:举一反三。即将已经训练好的模型稍加调整(fine-turning)即可应用于一个新的领域或者任务。主要流程如上图。
迁移学习为什么重要?
- 机器学习的默认假设,训练样本和测试样本满足独立同分布的前提是训练样本足够。
- 数据的稀缺性。如在想要做医学领域的图像处理,所能得到的样本是极端的不平衡,重要的样本太少,无法训练出一个效果好的网络。
- 标记的困难性。大数据时代动辄亿万数据,标记起来太费时费力。(题外话,半标签问题可以使用伪标签技术,即将test的数据加到train数据集中,其对应的标签为原数据集训练得到的。这种方法具有一定的泛化增强能力,最好是在网络迭代几轮后再将已有标签和无标签一起训练。一般会在batch有1/4-1/3的伪标签数据。)
- 框架太难训练。想要得到复杂有效的框架都需要长时间的训练,设备、时间、人力都成问题。
- 任务的扩展性。在实际中如果有些应用需要添加新的模块,或者收集到的数据发生了变化,那么重新训练一次?没有更轻松快捷的方法吗?
在前一篇文章–目标检测中,就使用过Tensorflow Object Detection API里面所自带的模型训练了自己的数据集。这篇再整理用TF-slim和keras完成任务。
TF-slim
它是TensorFlow(tensorflow.contrib.slim)的一个轻量级高级API,用于定义,训练和评估复杂模型。包含常用的网络架构模型如VGG, AlexNet,可以让从头开始训练模型,也可以利用预先训练好的网络权重对其进行微调(fine-turn)。
安装:
python -c "import tensorflow.contrib.slim as slim; eval = slim.evaluation.evaluate_once"
但是它的出现本身其实是为了–代码瘦身,即在不用keras,tensorlayer,tflearn这些高级库的条件下就可以写出简单优美的代码。如定义变量它的写法是:
# Model Variables
weights = slim.model_variable('weights',
shape=[10, 10, 3 , 3],
initializer=tf.truncated_normal_initializer(stddev=0.1),
regularizer=slim.l2_regularizer(0.05),
device='/CPU:0')
model_variables = slim.get_model_variables()#返回模型变量
# Regular variables
my_var = slim.variable('my_var',
shape=[20, 1],
initializer=tf.zeros_initializer())
regular_variables_and_model_variables = slim.get_variables()#返回所有变量,包括局部变量
定义网络层则是一行代码:
net1 = slim.conv2d(input, 128, [3, 3], scope='conv1')
net2 = slim.repeat(net1, 3, slim.conv2d, 256, [3, 3], scope='conv3')#repeat可以直接搭3个卷积层
net3 = slim.max_pool2d(net2, [2, 2], scope='pool2')
#stack和repert是不同是,它可以处理卷积核或者全连接层输出不一样的情况
slim.stack(x, slim.conv2d, [(32, [3, 3]), (32, [1, 1]), (64, [3, 3]), (64, [1, 1])], scope='core')
slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')
用arg_scope来完成参数共享,整个VGG都十分轻松:
def vgg16(inputs):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):#共享的参数写到一起
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')#其他的单独再搭
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
net = slim.fully_connected(net, 4096, scope='fc6')
net = slim.dropout(net, 0.5, scope='dropout6')
net = slim.fully_connected(net, 4096, scope='fc7')
net = slim.dropout(net, 0.5, scope='dropout7')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8')
return net
不过不需要,slim里面有已经训练完成了的模型,可以直接用来预测。完整的tf-slim使用手册:https://github.com/tensorflow/models/blob/master/research/slim/slim_walkthrough.ipynb
import tensorflow as tf
vgg = tf.contrib.slim.nets.vgg#vgg模型
images, labels = ...#载入图像和标签
predictions, _ = vgg.vgg_16(images)#预测
loss = slim.losses.softmax_cross_entropy(predictions, labels)#损失函数
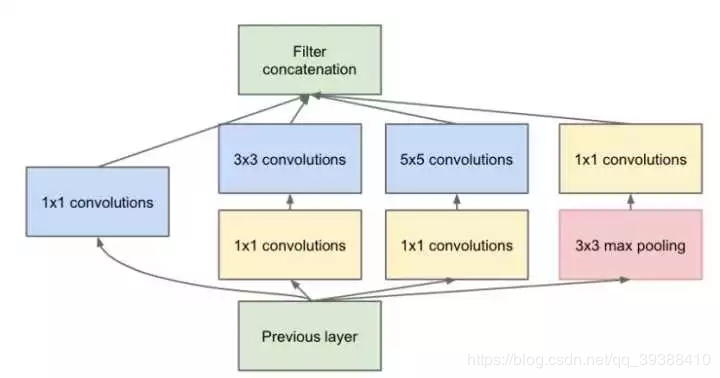
fine-turn新模型
以下都是基于inception进行微调,inception是一个组合的卷积核,能够让网络进行自行选择,同时又加入了1X1的卷积减少参数。对它进行微调可以理解为是把前面的卷积层一起当成一个特征提取器,将后面的全卷积换成掉训练新的数据集如下图(毕竟新的数据集无论从种类数量等等都还是不一样的),便可以使它完成新的任务(比如可以拿普通的图像识别网络在数据少的医学图像上进行迁移学习)。所以操作时往往先会冻结前面卷积的权重,只需要fine-turn后面的参数就可以了。当然可以基于它的权重进行全网络的微调。
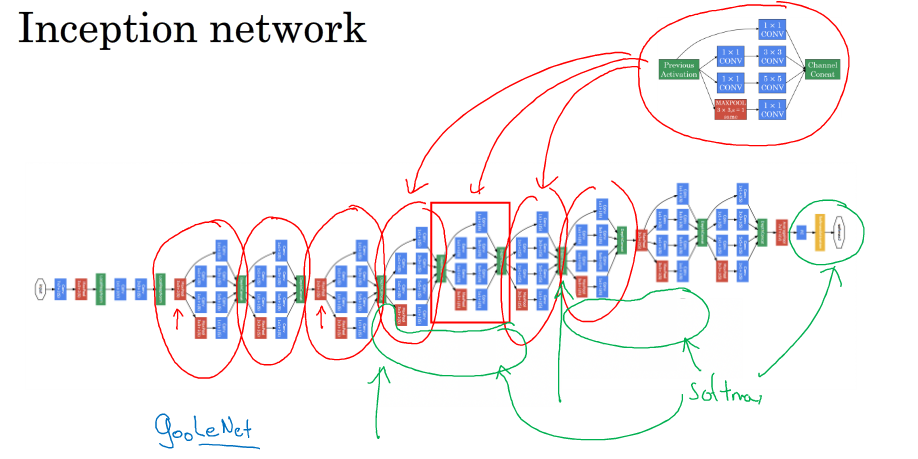
先下载tf-slim完整的图像模型库:
git clone https://github.com/tensorflow/models/
由于Tensorflow的训练集需要是tfrecord模式,如果使用现成的数据集ImageNet等就不需要转换,如果是自己的数据集需要先做处理。如有一个叫A的数据集,通过下来命令使用 download_and_convert_data.py可以转换。
$ DATA_DIR=/tmp/data/A
$ python download_and_convert_data.py
--dataset_name=flowers
--dataset_dir="${DATA_DIR}"
由于slim本身有MNIST,CIFAR-10 ,Flowers ,ImageNet数据集,如果要加入自己的数据,需要在数据集datasets里面注册一下。便可以导入了。
import tensorflow as tf
from datasets import A
slim = tf.contrib.slim
dataset = A.get_split('validation', DATA_DIR)
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])
下载模型并解压,比如inception_v3
$ CHECKPOINT_DIR=/tmp/checkpoints
$ mkdir ${CHECKPOINT_DIR}
$ wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
$ tar -xvf inception_v3_2016_08_28.tar.gz
$ mv inception_v3.ckpt ${CHECKPOINT_DIR}
$ rm inception_v3_2016_08_28.tar.gz
然后开始fine-turn。其中–checkpoint_exclude_scopes会阻止某些变量被加载。当使用与训练模型不同数量的分类任务进行微调时,新模型将具有最终的“分类”层,其尺寸与预先训练的模型不同。标志–checkpoint_path和–checkpoint_exclude_scopes期间仅用于模型初始化。通常情况下,微调只需要训练一组子层,因此该标志–trainable_scopes允许指定层的哪些子层应该训练,其余的将保持冻结。
$ python train_image_classifier.py
--train_dir=${TRAIN_DIR}
--dataset_dir=${DATASET_DIR}
--dataset_name=A #训练数据集
--dataset_split_name=train
--model_name=inception_v3
--checkpoint_path=${CHECKPOINT_PATH}
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits #调参范围,只对输出层做调整
--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits #若不设定此项,将全参数调整
--max_number_of _steps=10000 #其他的学习参数控制
--batch size=64
--learning_rate=0.001
--learning_rate_decay_type=fixed #学习率是否递减
--save_interval secs=300 #保存模型的时间间隔
--save_summaries_secs=2 用tensorboard的更新时间
--log_every_n_steps=10 #打印信息的步长间隔
--optimizer=rmsprop
--weight_decay=0.00001 #正则化参数
tensorboard --logdir=${TRAIN_DIR}查看训练情况。
测试性能:
CHECKPOINT_FILE = ${CHECKPOINT_DIR}/inception_v3.ckpt
$ python eval_image_classifier.py
--alsologtostderr
--checkpoint_path=${CHECKPOINT_FILE}
--dataset_dir=${DATASET_DIR}
--dataset_name=A
--dataset_split_name=validation
--model_name=inception_v3
TF-slim代码实现fine-turn
不采用上面的命令方法可以通过代码的方式完成:
import os
from datasets import flowers#使用它自己的flowers,如果是A同样需要设置一下
from nets import inception
from preprocessing import inception_preprocessing
from tensorflow.contrib import slim
image_size = inception.inception_v1.default_image_size
#得到原网络权重
def get_init_fn():
#前面提过的checkpoint_exclude_scopes确定fine-turn范围
checkpoint_exclude_scopes=["InceptionV1/Logits", "InceptionV1/AuxLogits"]
exclusions = [scope.strip() for scope in checkpoint_exclude_scopes]
variables_to_restore = []
for var in slim.get_model_variables():
for exclusion in exclusions:
if var.op.name.startswith(exclusion):
break
else:
variables_to_restore.append(var)
return slim.assign_from_checkpoint_fn(
os.path.join(checkpoints_dir, 'inception_v1.ckpt'),
variables_to_restore)
#训练集
train_dir = '/tmp/inception_finetuned/'
with tf.Graph().as_default():
tf.logging.set_verbosity(tf.logging.INFO)#日志
dataset = flowers.get_split('train', flowers_data_dir)#切分数据
images, _, labels = load_batch(dataset, height=image_size, width=image_size)
# 创建模型,使用默认的参数范围配置参数。
with slim.arg_scope(inception.inception_v1_arg_scope()):
logits, _ = inception.inception_v1(images, num_classes=dataset.num_classes, is_training=True)
#损失函数
one_hot_labels = slim.one_hot_encoding(labels, dataset.num_classes)
slim.losses.softmax_cross_entropy(logits, one_hot_labels)
total_loss = slim.losses.get_total_loss()
tf.summary.scalar('losses/Total Loss', total_loss)#便于显示
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)#优化器
train_op = slim.learning.create_train_op(total_loss, optimizer)
#开始训练
final_loss = slim.learning.train(
train_op,
logdir=train_dir,
init_fn=get_init_fn(),
number_of_steps=2)
print('Finished training. Last batch loss %f' % final_loss)
用keras进行fine-turn
from keras.applications.inception_v3 import InceptionV3 #同样载入v3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
import os
import tensorflow as tf
os.environ["CUDA_VISIBLE_DEVICES"] = "6"
gpu_options = tf.GPUOptions(allow_growth=True)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
from keras.utils import plot_model
from matplotlib import pyplot as plt
#InceptionV3模型,加载预训练权重,但是不保留最后的三个全连接层,进行微调
base_model = InceptionV3(weights='imagenet', include_top=False)
print(base_model.summary()) # summary便于显示
plot_model(base_model,to_file = 'InceptionV3.png') # 保存模型结构图
x = base_model.output
x = GlobalAveragePooling2D()(x)#全局平均池化层
x = Dense(1024, activation='relu')(x)
predictions = Dense(2, activation='softmax')(x)#增加两个全连接层
model = Model(inputs=base_model.input, outputs=predictions)#模型合并,得到新模型
print(base_model.summary())
plot_model(model,to_file = 'InceptionV3.png')
for layer in base_model.layers:
layer.trainable = False #冻结层
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')#开始编译
#生成训练数据
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_generator = train_datagen.flow_from_directory(
'.train/',
target_size=(150, 150),
batch_size=32,
class_mode='categorical')
#开始测试
test_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = test_datagen.flow_from_directory(
'./validation/',
target_size=(150, 150),
batch_size=32,
class_mode='categorical')
#新数据开始训练
model.fit_generator(
train_generator,
steps_per_epoch=2000,
epochs=1,
validation_data=validation_generator,
validation_steps=800)
#冻结部分层,然后训练其他层
for i, layer in enumerate(base_model.layers): # 打印出每次的名字
print(i, layer.name)
for layer in model.layers[:249]:
layer.trainable = False
for layer in model.layers[249:]:
layer.trainable = True
#重新训练
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
model.fit_generator(
train_generator,
steps_per_epoch=2000,
epochs=1,
validation_data=validation_generator,
validation_steps=800)
fine-turning效果如何?
一图胜千言。
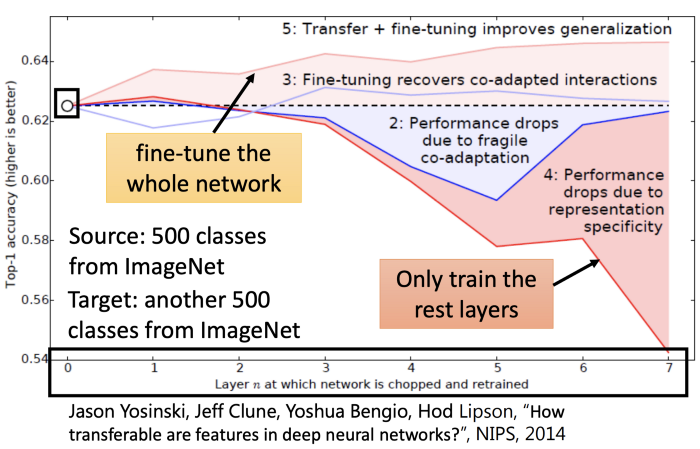
fune-turning技巧
- 只替掉最后一层,改成本任务的类别
- 替到最后一层,freeze backbone到收敛,再开放所有层一起
- 替到最后一层,用差分学习率(discriminative learning)即backbone和最后一层学习率不一样,毕竟backbone已经很好了可以选用比如10倍
- 替到最后一层,freeze浅层,训练深层,以增强泛化,减少过拟合
- 好的学习率(如3e-4是Adam最好学习率)
最后
以上就是眼睛大冬日最近收集整理的关于Fine-turning(Tensorflow-Slim和Keras的迁移学习)的全部内容,更多相关Fine-turning(Tensorflow-Slim和Keras内容请搜索靠谱客的其他文章。








发表评论 取消回复