1、HDFS Trash 垃圾桶
1.1 垃圾桶概述
回收站(垃圾桶)是微软Windows操作系统里的系统文件夹。主要用来存储用户临时删除的文件

HDFS文件系统,有没有垃圾桶。默认情况下是没有的,删除之后,直接删除。
执行删除命令
[root@node1 ~]# hadoop fs -rm /tmp/12.tbt
Deleted /tmp/12.tbt
[root@node1 ~]#
垃圾桶功能:HDFS trash,目的是防止无意中删除某些东西,默认不开启,文件不会立即被删除,将文件移动到current目录中(/user/${username}/.Trash/current)
.Trash中的文件在用户可配置的时间延后删除。
Trash checkpoint:检查点是用户垃圾桶下的一个目录,用于存储在创建检查点之前删除的所有文件和目录。目录(/user/${username}/.Trash/timestap_of_checkpoint_creation)文件在垃圾桶下按照时间进行管理
1.2垃圾桶使用
第一步:关闭集群
stop-dfs.sh
第二步:修改配置文件,
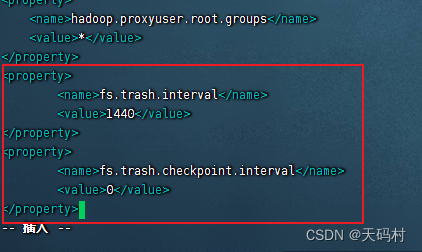
在core-site.xml中配置,fs.trash.interval 单位分钟
fs.trash.checkpoint.interval前后两次检查点创建的时间间隔(分钟),配置为0,新检查点创建之后,随之就的检查点就会被删除
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
第三步:配置文件同步到其他节点
scp -r core-site.xml root@node3:$PWD
scp -r core-site.xml root@node2:$PWD
第四步:启动hdfs
start-dfs.sh
功能更使用,删除文件
[root@node1 hadoop]# hadoop fs -rm /tmp/small/1.txt
2022-11-27 12:40:17,369 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/tmp/small/1.txt' to trash at: hdfs://node1:8020/user/root/.Trash/Current/tmp/small/1.txt
查看回收站中的数据
[root@node1 hadoop]# hadoop fs -ls /user/root/.Trash/Current/tmp/small/
Found 1 items
-rw-r--r-- 3 root supergroup 14 2022-11-21 18:01 /user/root/.Trash/Current/tmp/small/1.txt
恢复
[root@node1 hadoop]# hadoop fs -mv /user/root/.Trash/Current/tmp/small/ /tmp/small
[root@node1 hadoop]# hadoop fs -ls /user/root/.Trash/Current/tmp/small/
ls: `/user/root/.Trash/Current/tmp/small/': No such file or directory
[root@node1 hadoop]# hadoop fs -ls /tmp/small
Found 3 items
-rw-r--r-- 3 root supergroup 7 2022-11-21 17:41 /tmp/small/2.txt
-rw-r--r-- 3 root supergroup 7 2022-11-21 17:41 /tmp/small/3.txt
drwx------ - root supergroup 0 2022-11-27 12:40 /tmp/small/small
直接删除
[root@node1 hadoop]# hadoop fs -rm -skipTrash /tmp/small/small
rm: `/tmp/small/small': Is a directory
[root@node1 hadoop]#
清空回收站
除了fs.trash.interval参数控制到期自动删除之外。可以手动删除垃圾桶中的文件
[root@node1 hadoop]# hadoop fs -rm /tmp/small/2.txt
2022-11-27 12:48:50,600 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/tmp/small/2.txt' to trash at: hdfs://node1:8020/user/root/.Trash/Current/tmp/small/2.txt
[root@node1 hadoop]# hadoop fs -ls /user/root/.Trash/Current/tmp/small/
Found 1 items
-rw-r--r-- 3 root supergroup 7 2022-11-21 17:41 /user/root/.Trash/Current/tmp/small/2.txt
[root@node1 hadoop]# hadoop fs -rm /user/root/.Trash/Current/tmp/small/2.txt
Deleted /user/root/.Trash/Current/tmp/small/2.txt
[root@node1 hadoop]# hadoop fs -ls /user/root/.Trash/Current/tmp/small/
[root@node1 hadoop]#
2、HDFS Snapshot快照
2.1 快照介绍
可以理解为瞬间的投影,是数据存储在某一时刻的状态记录,与备份区别,备份数据存储的某一时刻的副本
HDFS Snapshot快照是整个文件系统或某个目录在某个时刻的镜像,该镜像不会随着源目录的改变而动态变化。
快照作用:数据恢复,对重要目录进行创建snapshot的操作;数据备份,整个集群、某些目录、文件备份不同备份之间差异性,增量备份。
数据测试:某些重要数据进行测试或者实验在快照上进行。
2.2HDFS快照功能的实现
HDFS快照不是数据的简单拷贝,只是差异的记录。对于大多不变的数据,你所看到的数据其实是当前物理路径所指的内容,而发生变更的inode数据才会被快照额外拷贝,也就是差异拷贝
inode指索引节点,用来存放文件及目录的基本信息,包含时间、名称、所有者、所在组。
hdfs快照不会复制datanode中的块,只记录块列表和文件大小,HDFS快照不会对常规HDFS操作产生不利影响,修改记录按照逆时针顺序进行,因此可以直接访问当前数据,通过从当前数据中减去来修改快照计算数据
2.3快照命令
HDFS可以针对整个文件系统或者某个目录创建快照,创建快照的前提是相应的目录开启快照功能。
开启快照
hdfs dfsadmin -allowSnapshot /allenwoon
禁用快照(禁用快照的前提是该目录所有的快照已经删除)
hdfs dfsadmin -disallowSnapshot /allenwoon```
快照操作
- 创建快照 createSnapshot
- 删除快照 deleteSnapshot
- 重命名快照 renameSnapshot
- 列出可以快照目录列表 lsSnapshottableDir
- 获取快照差异报告 snapshotDiff
案例
第一步:创建一个目录
hadoop fs -mkdir /allenwoon
测试:直接创建快照(提示这个目录不是一个快照目录)
[root@node1 ~]# hdfs dfs -createSnapshot /allenwoon
createSnapshot: Directory is not a snapshottable directory: /allenwoon

第二步:准备数据
```bash
[root@node1 ~]# echo "hello hadoop" >> 1.txt
[root@node1 ~]# cat 1.txt
hello hadoop
[root@node1 ~]# hadoop fs -put 1.txt /allenwoon
[root@node1 ~]# hadoop fs -ls /allenwoon
Found 1 items
-rw-r--r-- 3 root supergroup 13 2022-11-27 14:36 /allenwoon/1.txt
第三步:启用快照
hdfs dfsadmin -allowSnapshot /allenwoon

第四步:创建快照
# 不指定名字
hdfs dfs -createSnapshot /allenwoon
# 指定名字
hdfs dfs -createSnapshot /allenwoon mysnaps


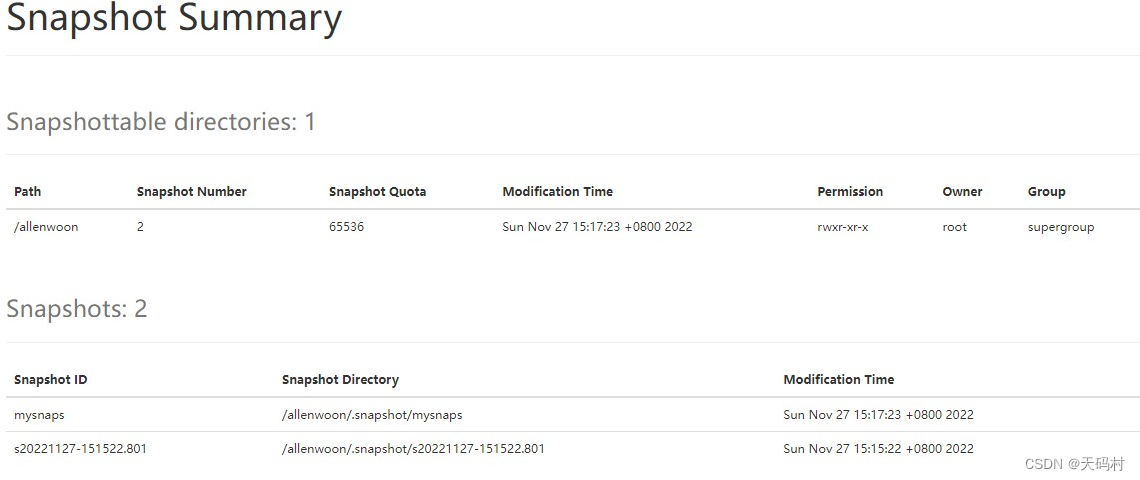
快照重命名
hdfs dfs -renameSnapshot /allenwoon mysnaps mysnap2
列出所有快照开启的目录
hdfs lsSnapshottableDir

第五步:快照差异比较
准备
# 创建文件
echo 222 > 2.txt
# 追加到原来文件
hadoop fs -appendToFile 2.txt /allenwoon/1.txt
# 创建快照
hdfs dfs -createSnapshot /allenwoon mysnap3
# Created snapshot /allenwoon/.snapshot/mysnap3
# 上传任意文件
# hadoop fs -put anaconda-ks.cfg /allenwoon
# 创建快照
hdfs dfs -createSnapshot /allenwoon mysnap4
# Created snapshot /allenwoon/.snapshot/mysnap4
快照差异比较
hdfs snapshotDiff /allenwoon mysnap2 mysnap3
#Difference between snapshot mysnap2 and snapshot mysnap3 under directory /allenwoon:
# M ./1.txt
hdfs snapshotDiff /allenwoon mysnap2 mysnap4
#Difference between snapshot mysnap2 and snapshot mysnap4 under directory /allenwoon:
#M .
#+ ./anaconda-ks.cfg
#M ./1.txt
快照差异释义
+ The file/directory has been created.
- The file/directory has been deleted.
M The file/directory has been modified.
R The file/directory has been renamed.
第六步:删除快照文件夹路径
如果有快照存在,不让删除
hadoop fs -rm -r /allenwoon
# rm: Failed to move to trash: hdfs://node1:8020/allenwoon: The directory /allenwoon cannot be deleted since /allenwoon is snapshottable and already has snapshots
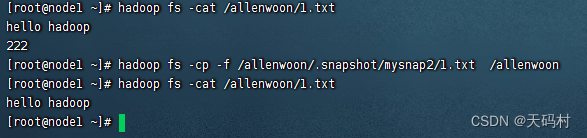
第七步:从快照拷贝文件
hadoop fs -cp -f /allenwoon/.snapshot/mysnap2/1.txt /allenwoon
第八步:删除快照
hdfs dfs -deleteSnapshot /allenwoon mysnap4
3、HDFS权限管理
3.1 权限管理概述(3A)
认证(Authentication)、授权(Authorization)、审计(Accounting)是计算机安全领域的一个架构模式。缩写为3A。用书先证明自己是谁;然后授予权限,你能干什么;同时操作被记录,你干了什么。
身份:如何通过一个标识区分实体、用户和服务。
案例分析:使用普通用户登录Linux(认证),提示输入密码。
使用sudo命令执行某些管理员权限命令(授权,发现没有权限),使用root授予相应的权限,发先可以访问
通过secure日志查看操作记录(审计)
HDFS权限管理概述:客户端的操作首先通过用户身份验证机制获得“凭证”,HDFS根据此“凭证”分辨出合法用户,然后HDFS查看用户是否已经授权。
3.2HDFS UGO权限管理
每个文件和目录都与一个拥有者和组相关联
USER(文件所有者):一般是创建该文件的用户,对该文件具有完全的权限
Group(拥有者所在的组):和文件所有者同一组的用户。
OTHER:其他用户组的用户
权限:读权限(r)、写权限(w)、执行权限(x)
HDFS中,对于文件需要r权限才能读取文件,而w权限才能写入或者追加文件,没有x权限的概念
对于目录:需要r权限才能列出目录,需要w权限才能创建或删除文件或目录,需要x权限才能访问目录的子集。
读——4,写——2,执行——1,每一个用户对文件或文件夹的权限可以用数字表示。
权限掩码:与Linux系统类似,用于设置在HDFS中默认新建的文件和目录权限限位。默认umask值有属性fs.permissions.umask-mode指定,默认值022。
创建文件和目录的时候使用umask,默认权限就是
目录:777-022=755,
文件:777-022=755,因为HDFS中没有x的概念,所以是-rw-r–r–
UGO权限相关命令
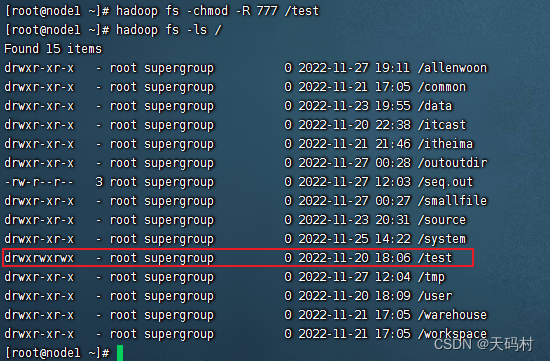
#变更目录或文件的权限 可以使用数字 也可以使用字母 u g o a + - r w x
# [-R]递归其下所有文件夹和文件
hadoop fs -chmod [-R] 777 /user/itcast/foo
hadoop fs -chmod [-R] u+x,o-x /user/itcast/foo
#变更目录或文件的属主或用户组
hadoop fs -chown [-R] itcast /user/itcast/foo
hadoop fs -chown [-R] itcast:ogroup /user/itcast/foo
#变更用户组
hadoop fs -chgrp [-R] group1 /user/itcast/foo
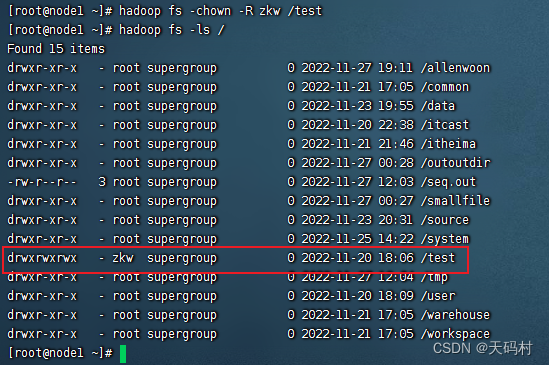
hadoop3.0 提供了WebUI页面的UGO权限修改。
3.3 用户身份认证
在HDFS中,用户身份认证独立于HDFS项目之外,也就是说HDFS不负责用户身份合法性检查,但HDFS汇通过获取相关用户身份,然后用于后续权限管理,
用户是否合法,完全取决于集群使用认证体系,目前社区支持两种身份认证,即简单认证(Simple)和(Kerberos)
Simple认证:
基于HDFS客户端所在的Linux系统登录的用户名来进行认证,只要用户能登录就认证成功,客户端与NN交互时会将用户的登录账号(通过类似whoami的命令来获取)作为合法用户名传递至NN。
弊端:
在多租户条件这种认证会导致权限混淆;
同时恶意用户也可以伪造其他人的用户名非法获得相应的权限,对数据安全造成极大的隐患。
线上生产环境一般不会使用。
Simple认证时,HDFS想法时:防止好人误做坏事,不防止坏人做坏事,当客户端提交给Hadoop一个用户名时,Hadoop会相信客户端所说的一切,并保证整个集群的所有机器也相信。
Kerberos介绍
kerberos源于希腊语,是一只守护地狱的三头巨犬,麻绳理工学院开发的一种网络身份认证协议,通过密钥加密技术为服务端、服务器应用程序提供身份强认证。https://kerberos.org/
角色:
访问服务的clinet
提供服务的server
KDC(Key DIStribution Center) 密钥分发中心。
域概念:client、server、kdc都位于一个域中,为域内的用户提供服务client 是否有权限访问server由kdc发放的票据判定。
域:
票据:合法、权限,
Kerberos-KDC
- Authentication Server:验证Client端的身份
- Ticket Granting Server: 通过AS发送给Client的票(TGT)换取访问Server端的票。
组映射:用户组映射服务获取该用户对应的用户组列表。使用系统自带的方案,NameNode上的,利用Linux系统上的组
Linux用户和用户组保存在/etc/passwd和/etc/group,HDFS通过外部调用shell命令获取用户的所有组列表。
/etc/passwd 一行记录对应一个用户,每行七个字段,冒号分隔
用户名:口令:用户标识号:组标时号:注释性描述:主目录:登录shell
/etc/group一行记录对应一个用户,每行四个字段,冒号分隔
组名:密码:GID:该用户组中的用户列表
优点:服务稳定,不易受外部服务影响
缺点:用户和用户组管理需要root权限,在服务器上生成大量用户组,后续管理(自动化运维)压力较大
HDFS ACL权限管理
ACL(Access Control List)访问控制列表,为特定的用户或组设置不同的权限,而不是文件的所有者和文件的所有组。
ACL Shell命令
#显示文件和目录的访问控制列表(ACL)。如果目录具有默认ACL,则getfacl还将显示默认ACL。
hadoop fs -getfacl [-R] <path>
#设置文件和目录的访问控制列表(ACL)。
hadoop fs [generic options] -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]
#ls的输出将在带有ACL的任何文件或目录的权限字符串后附加一个'+'字符。
hadoop fs -ls <args>
操作案例
使用root在HDFS创建一个文件夹
hadoop fs -mkdir /itheima
创建完成,权限是755
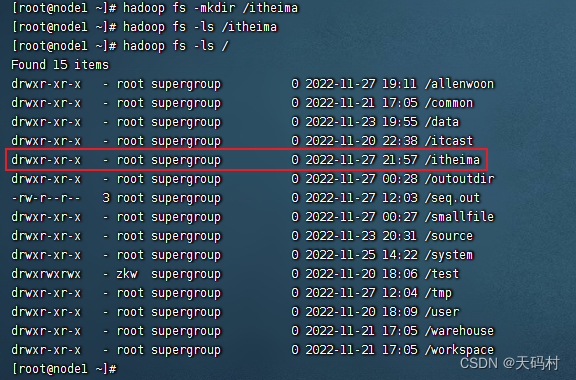
普通用户登录,上传文件,发现没有权限
ssh zkw@node1
#zkw@node1's password:
echo 1>>1.txt
hadoop fs -put 1.txt /itheima
# put: Permission denied: user=zkw, access=WRITE, inode="/itheima":root:supergroup:drwxr-xr-x

为了让zkw用户上传,可以为文件开发其他用户组的写权限
hadoop fs -chmod o+w /itheima
自己不能给自己添加权限

用root用户添加权限
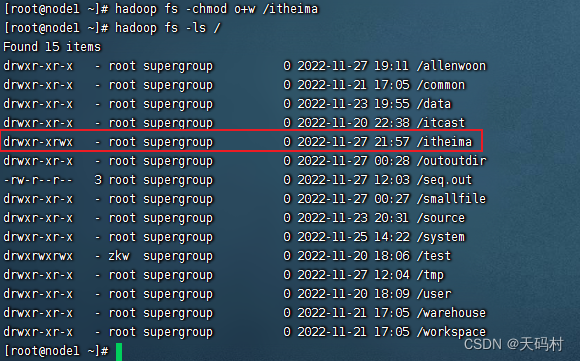
但是所有其他用户都有了写的权限,很恐怖,root现在立刻删除其他用户组的写权限,十分繁琐
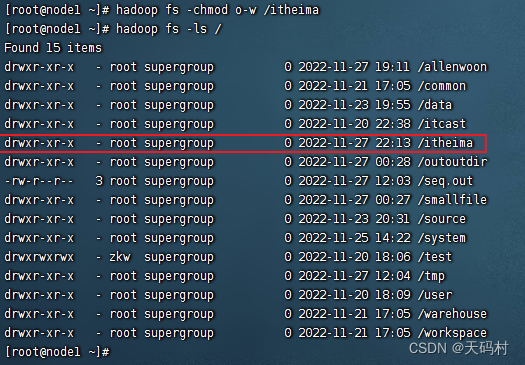
使用ACL给allenwoon用户单独添加权限 而/itheima文件夹本身权限不变
hadoop fs -setfacl -m user:zkw:rwx /itheima
# setfacl: The ACL operation has been rejected. Support for ACLs has been disabled by setting dfs.namenode.acls.enabled to false.
关闭hdfs
stop-dfs.sh
需要在hdfs-site.xml中开启相应配置
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
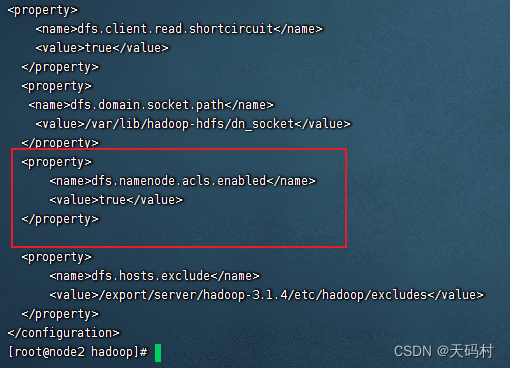
复制到其他节点
scp hdfs-site.xml root@node2:$PWD
启动hdfs
start-dfs.sh
查看acl权限
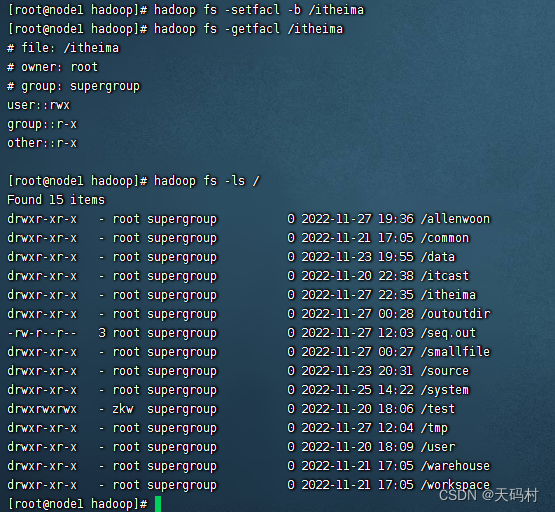
hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
#user::rwx
#group::r-x
#other::r-x
设置zkw的acl
hadoop fs -setfacl -m user:zkw:rwx /itheima
再次查看
hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
#user::rwx
#user:zkw:rwx
#group::r-x
#mask::rwx
#other::r-x
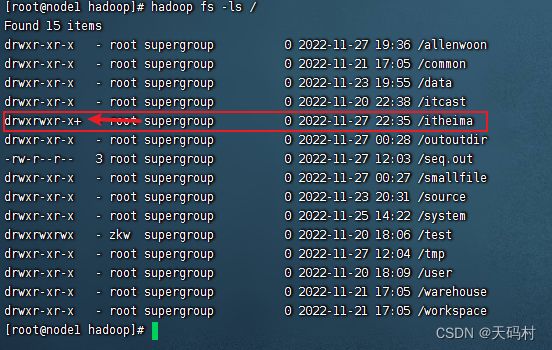
上传文件
hadoop fs -put 1.txt /itheima

删除用户权限
hadoop fs -setfacl -x user:zkw /itheima
删除不干净
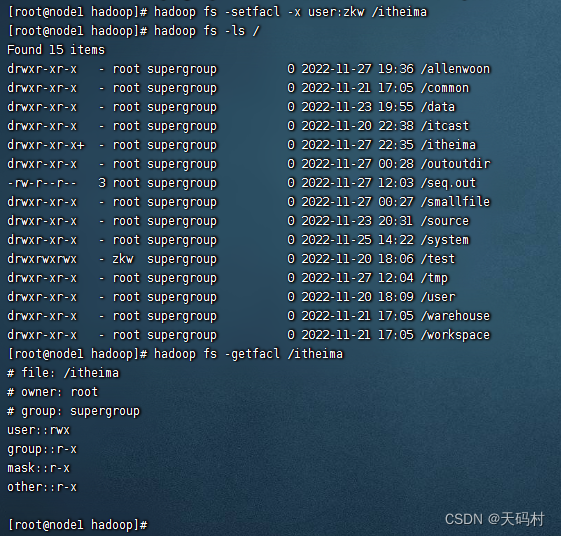
完全删除
4、HDFS Proxy user代理用户
Proxy 代理、委托用来进行事务不想或不能进行的其他操作。
HDFS Proxy user:一个用户如何代表另一个用户进行HDFS操作
常用场景:第三方软件与Hadoop集成的时候用
配置参数:hadoop.proxyuser.$superuser.hosts
hadoop.proxyuser.$superuser.groups
例如:名为super的超级用户只能从host1和host2连接来模拟属于group1和group2的用户。
<!--在core-site中配置-->
<property>
<name>hadoop.proxyuser.super.hosts</name>
<value>host1,host2</value>
</property>
<property>
<name>hadoop.proxyuser.super.groups</name>
<value>group1,group2</value>
</property>
<!--super是代理用户的名-->
宽松配置,使用* 代表任何主机、任何组。
5、HDFS透明加密
HDFS明文存储的弊端
HDFS中的数据以Block的形式存放在数据的本地磁盘上,但是Block都是明文的,对于单个小文件,一个文件为一个block,相对容易字节从linux系统中找到相应数据块。
实验:
文件上传
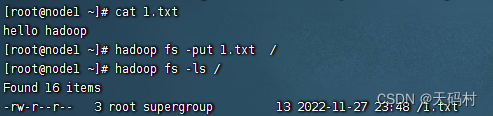
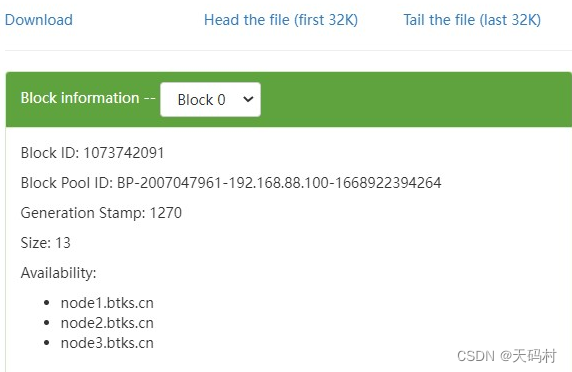
根据block编号和信息直接通过linux找数据。
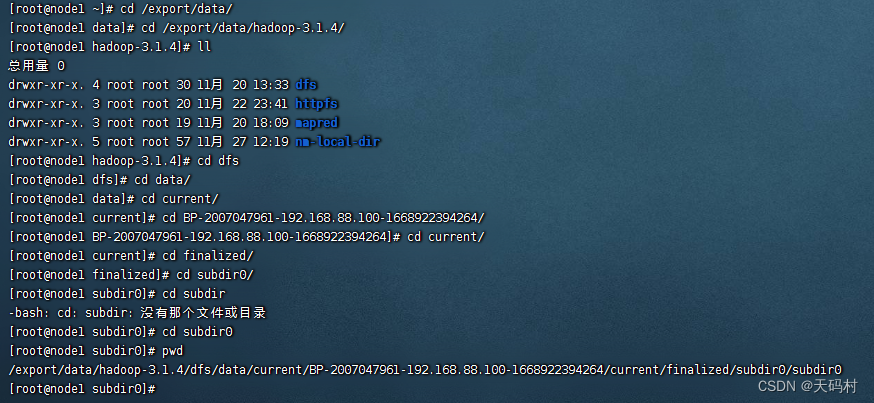
明文存储,直接可以查看到了数据。
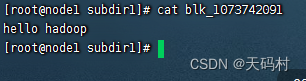
加密技术:加密算法 加密密钥,通过解密算法和密钥解密查看
常见的加密层级 应用层加密,数据库层加密,文件系统加密,磁盘层加密。
HDFS透明加密 端到端的加密和接密只能通过客户端打开。
HDFS保存的是加密后的文件,文件加密的密钥也是加密的。让非法用户从操作系统拷贝文件,看到的是密文,无法解读。
透明加密
只有HDFS客户端可以加密和解密,密钥管理在HDFS外部,HDFS无法访问未加密的数据或加密密钥。数据块以加密形式存储,
加密区域:加密区域就是HDFS上的一个目录,只不过该目录比其他目录特殊。加密区域里写入文件的时候会被透明加密,读取文件的时候又会被透明解密。
密钥:加密区域的密钥(EZK,encryption zone key),数据加密密钥(DEK,data encryption key)
DEK会使用各自的加密区域的EZK密钥进行加密。加密密钥的密钥(EDEK,encryption data encryption key)。
密钥库,存储密钥的叫密钥库,将HDFS与外部企业级密钥库集成是部署透明加密的第一步。
KMS(密钥管理服务为,Key Management Server),
透明加密的过程:
写数据:
提前动作:创建加密区,设置加密区密钥
- Client向NN请求在HDFS某个加密区新建文件;
- NN从缓存中取出一个新的EDEK(后台不断从KMS拉取新的EDEK到缓存中);
- 获取到EDEK会被NN保存到文件的元数据中;
- 然后NN将EDEK发送给Client;
- Client发送EDEK给KMS,KMS用对应的EZ key将EDEK解密出DEK发送给Client;
- Client用DEK加密文件内容发送给datanode进行存储。

读数据:
读流程与写流程类型,区别就是NN直接读取加密文件元数据里的EDEK返回给客户端,客户端一样把EDEK发送给KMS获取DEK。再对加密内容解密读取。
EDEK的加密和解密完全在KMS上进行。更重要的是,请求创建或解密EDEK的客户端永远不会处理EZ密钥。仅KMS可以根据要求使用EZ密钥创建和解密EDEK。
Hodoop KMS 配置
第一步:关闭集群
stop-dfs.sh
第二部:keystone密钥库,此处使用JavaKeyStoreProvider作为keystore,其他参考密钥库参考地址
keytool -genkey -alias 'itcast_keystore'

第三步:修改kms配置文件
cd /export/servers/hadoop-3.1.4/etc/hadoop/
# 创建密码文件
vim kms.keystore.password
[root@node1 hadoop]# cat kms.keystore.password
123456
# 修改配置文件
[root@node1 hadoop]# vim kms-site.xml
[root@node1 hadoop]# vim kms-env.sh
[root@node1 hadoop]# vim core-site.xml
[root@node1 hadoop]# vim hdfs-site.xml
<!-- kms-site.xml-->
<configuration>
<property>
<name>hadoop.kms.key.provider.uri</name>
<value>jceks://file@/${user.home}/kms.jks</value>
</property>
<property>
<name>hadoop.security.keystore.java-keystore-provider.password-file</name>
<value>kms.keystore.password</value>
</property>
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@node1:16000/kms</value>
</property>
<property>
<name>hadoop.kms.authentication.type</name>
<value>simple</value>
</property>
</configuration>
<!-- core-site.xml -->
<property>
<name>hadoop.security.key.provider.path</name>
<value>kms://http@node1:16000/kms</value>
</property>
<!-- hdfs-site.xml -->
<property>
<name>hadoop.security.key.provider.path</name>
<value>kms://http@node1:16000/kms</value>
</property>
# kms-env.sh
export KMS_HOME=/export/servers/hadoop-3.1.4
export KMS_LOG=${KMS_HOME}/logs/kms
export KMS_HTTP_PORT=16000
export KMS_ADMIN_PORT=16001
同步到其他节点
scp kms-site.xml kms-env.sh core-site.xml hdfs-site.xml root@node2:$PWD
scp kms-site.xml kms-env.sh core-site.xml hdfs-site.xml root@node3:$PWD
启动HDFS集群
start-dfs.sh
启动kms
hadoop --daemon start kms
关闭
hadoop --daemon stop kms
透明加密使用
第一步:创建与查看key
hadoop key create ezk
hadoop key list -metadata
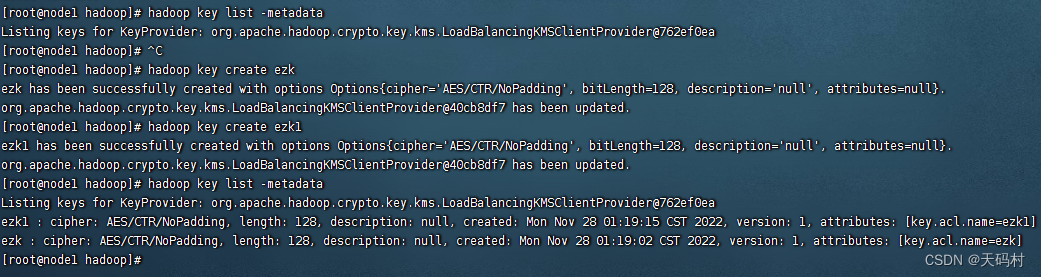
第二步:创建加密区,一个目录,
普通文件夹创建
hadoop fs -mkdir /zone
设置为加密区
hdfs crypto -createZone -keyName ezk -path /zone

文件创建与上传
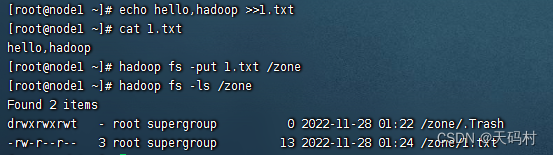
echo hello,hadoop >>1.txt
cat 1.txt
# hello,hadoop
hadoop fs -put 1.txt /zone
hadoop fs -ls /zone
#Found 2 items
#drwxrwxrwt - root supergroup 0 2022-11-28 01:22 /zone/.Trash
#-rw-r--r-- 3 root supergroup 13 2022-11-28 01:24 /zone/1.txt
验证
客户端查看
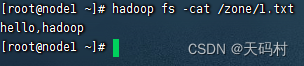
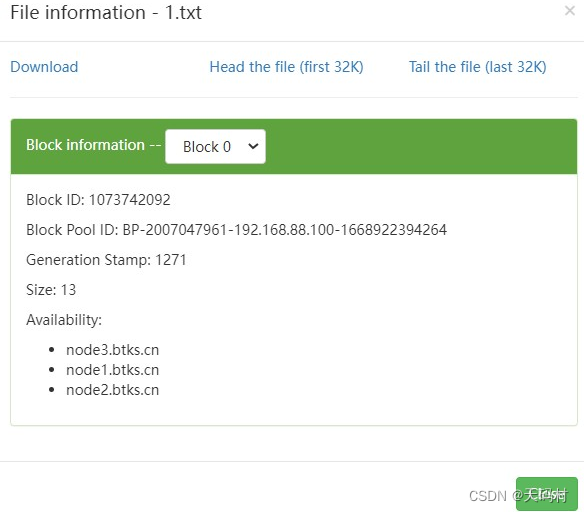
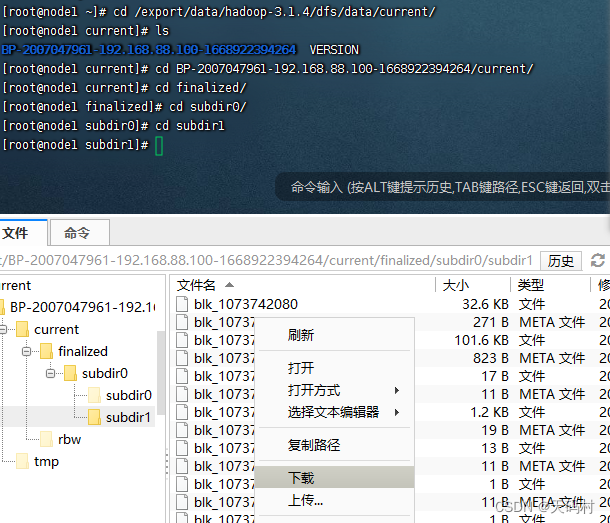
linux文件系统直接打开
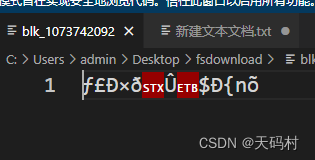

最后
以上就是鳗鱼香菇最近收集整理的关于大数据学习笔记-HDFS(五)——数据安全与隐私保护1、HDFS Trash 垃圾桶2、HDFS Snapshot快照3、HDFS权限管理4、HDFS Proxy user代理用户5、HDFS透明加密的全部内容,更多相关大数据学习笔记-HDFS(五)——数据安全与隐私保护1、HDFS内容请搜索靠谱客的其他文章。








发表评论 取消回复