1 背景
- 方便快速从不同的数据源(json,parquet、rdbms),经过混合处理(json join parquet),再将处理结果以特定的格式(json,parquet) 写回到指定的系统(HDFS,S3)
spark.read.format(format),(1) 内置的 format: json,parquet,jdbc,csv(v2+); (2) packages:外部的,https://spark-packages.org/- 写
people.write.format("parquet").save("path")
2 操作 Parquet 文件数据
数据目录 /home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet
2.1 启动spark
[hadoop@node1 ~]$ /home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out
2.2 启动 spark shell
[hadoop@node1 spark-2.1.3-bin-2.6.0-cdh5.7.0]$ ./bin/spark-shell --master local[2] --jars /home/hadoop/mysql-connector-java-5.1.44-bin.jar
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/11/12 15:23:38 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/11/12 15:23:38 WARN SparkConf:
SPARK_WORKER_INSTANCES was detected (set to '1').
This is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with --num-executors to specify the number of executors
- Or set SPARK_EXECUTOR_INSTANCES
- spark.executor.instances to configure the number of instances in the spark config.
Spark context Web UI available at http://192.168.30.131:4040
Spark context available as 'sc' (master = local[2], app id = local-1542007418777).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.1.3
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
2.4 读取数据
标准写法 spark.read.format("parquet").load
scala> val userDF = spark.read.format("parquet").load("file:///home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet")
18/11/12 15:25:07 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/11/12 15:25:07 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
18/11/12 15:25:08 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
userDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> userDF.printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
scala> userDF.show
18/11/12 15:26:32 WARN ParquetRecordReader: Can not initialize counter due to context is not a instance of TaskInputOutputContext, but is org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
2.5 写出
scala> userDF.select("name","favorite_color").show
+------+--------------+
| name|favorite_color|
+------+--------------+
|Alyssa| null|
| Ben| red|
+------+--------------+
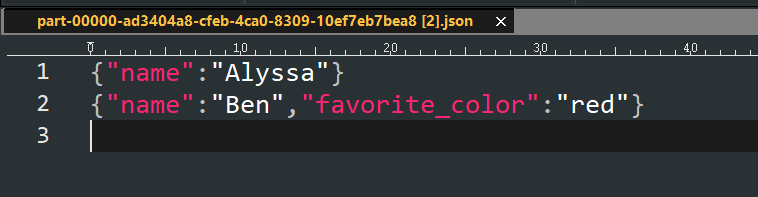
2.6 读取数据(简化写法)
scala> spark.read.load("file:///home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet").show
18/11/12 15:35:42 WARN ParquetRecordReader: Can not initialize counter due to context is not a instance of TaskInputOutputContext, but is org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
Spark 默认数据源
val DEFAULT_DATA_SOURCE_NAME = SQLConfigBuilder("spark.sql.sources.default")
.doc("The default data source to use in input/output.")
.stringConf
.createWithDefault("parquet")
2.7 用 SQL 方式处理
2.7.1 启动 spark sql
[hadoop@node1 spark-2.1.3-bin-2.6.0-cdh5.7.0]$ ./bin/spark-sql --master local[2] --jars /home/hadoop/mysql-connector-java-5.1.44-bin.jar
2.7.2 读取数据
https://spark.apache.org/docs/2.1.3/sql-programming-guide.html#parquet-files
spark-sql> CREATE TEMPORARY VIEW parquetTable
> USING org.apache.spark.sql.parquet
> OPTIONS (
> path "/home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet"
> );
2.8 另一种读取方式
spark.read.format("parquet")
.option("path","file:///home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet")
.load.show
scala> spark.read.format("parquet").option("path","file:///home/hadoop/apps/spark-2.1.3-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet").load.show
18/11/12 17:12:31 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
18/11/12 17:12:33 WARN ParquetRecordReader: Can not initialize counter due to context is not a instance of TaskInputOutputContext, but is org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
最后
以上就是温婉玫瑰最近收集整理的关于Spark SQL 笔记(9)—— 外部数据源(1) parquet1 背景2 操作 Parquet 文件数据的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复